In June of 2022 we intended to run the curl up 2022 curl conference in person, in California.
Unfortunately, I had the bad taste of catching covid exactly when I was about to use my new US visa for the first time, so I had to remain at home and because of that we cancelled the whole event.
Try again
Now we try again. The curl up 2022 take 2 will be an all-virtual event that is going to be a long Zoom-session with a number of presentations and discussion slots. Feel free to join in for what you want and stay away from the sessions that don’t interest you. We will make our best to keep the schedule, and the agenda will be available ahead of time for you to plan your attendance around.
On September 15, 2022 we will start the show at 15:00 CEST and we have a program that is a full day. Join when you want, leave, come back. You decide.
The Agenda is almost complete. The presentations will be done live or be provided prerecorded. The prerecorded talks will still be discussed and have Q&As live afterwards.
Speak!
There is still room left to add some speakers. If you use curl/libcurl somewhere and want to tell us about things you’ve learned and things libcurl devs should learn, come do it! Or anything else that is related to curl or Internet transfers. Big or small – even just 5 minutes works!
This is a day for sharing info, spreading knowledge and having fun.
Attend!
Yeah, sign up and come hang out with us and watch a range of curl related talks. I think you will learn things and I think it will be a lot of fun.
The curl up hours spelled out in different time zones:
PDT 6:00 – 15:00 (US west coast)
EDT 9:00 – 18:00 (US east coast)
UTC 13:00 – 22:00
CEST 15:00 – 00:00 (central Europe)
IST 18:30 – 03:30 (India)
CST 21:00 – 06:00 (China)
JST 22:00 – 07:00 (Japan)
AEST 23:00 – 08:00 (Sidney, Autralia)
NZST 01:00 – 09:00 (New Zealand) (This is on the 16th)
I get this question fairly often. How would the projects I run manage if I took off? And really, the primary project people think of then is of course curl.
How would the curl project manage if I took a forever vacation starting now?
Of course I don’t know that. We can’t really know for sure until the day comes (in the distant future) when I actually do this. Then you can come back to this post and see how well I anticipated what would happen.
Let me be clear: I do not have any plans to leave the curl project or in any way stop my work on it, neither in the short nor long term. I hope to play this game for a long time still. I am living the dream after all.
Busfactor
Traditionally we talk about the busfactor in various projects as a way to see how many key people a particular project has. The idea being that if there is only one, the project would effectively die if that single person goes away. A busfactor of one is considered bad.
The less morbid name sometimes used for this number is the holiday factor.
There is also the eternal difficult religious question of how to calculate the busfactor, but let’s ignore that today.
I would maybe argue differently
The theory of the busfactor is the idea that the main contributors of a project are irreplaceable and that the lack of other more active involvement are because of a lack of knowledge or ability or something.
It very well might be. A challenge is that there is no way to tell. It could also be that because one or more of the top active developers do a good enough job, the others do not see a need or a reason for them to step up, join in and work. They can very well keep lingering in the background because everything seems to work well enough from their perspective. And if things work well enough in project X, surely lots of people can then rather find interesting work elsewhere. Perhaps in project Y that may not work as well.
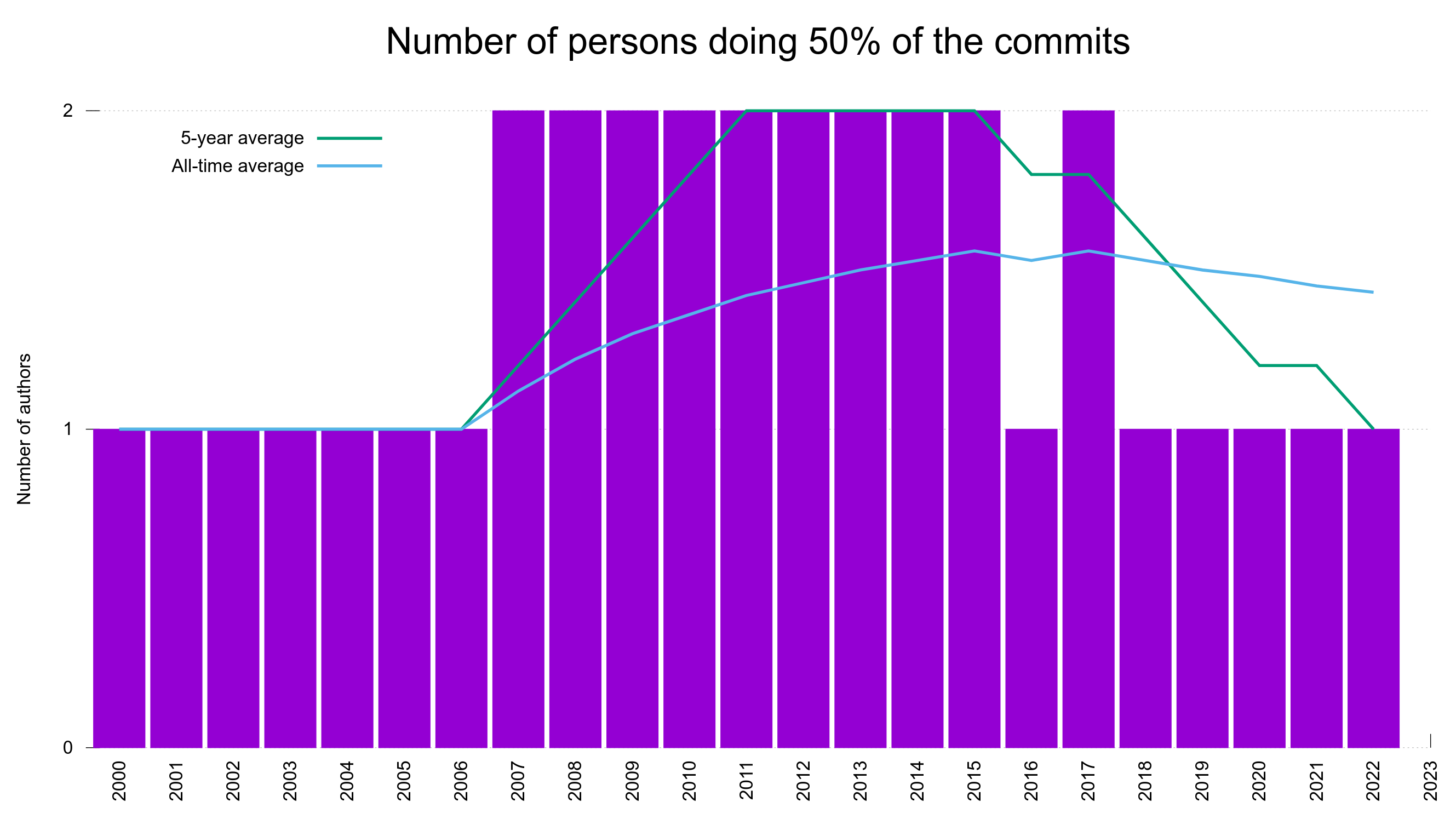
I prefer to think and I actually believe that curl is a project in this second category. It runs pretty well, even if I do a really large chunk of the work in the project. I am not sure curl actually counts as a busfactor one project, but the exact number is not important me. At least I regularly do more than 50% of the commits on an average year.
Graph for the curl source code repository
A safety net
I think an important part of the job for me in the project is to make sure that everything is documented. The code of course, the APIs, the way we build things, how to run tests, how to write tests etc. But also some of the softer things: how we do releases, what the different roles are the project, how we decide merging features, how we work on security issues, how did the project start, how do we want contributions and much much more.
This is the safety net for the day I vanish.
There are no secrets, no hidden handshakes and no surprises. No procedures or ways of working that is not written down and shared with the team.
If you know me and my work in curl, you know that I work fiercely on documentation.
Maybe there is only a single bus driver, but there are wannabe potential drivers following along that can take over the wheel should the seat become empty.
Contingency
There is no designated crown prince/princess or heir who inherits the throne after me. I don’t think that is a valuable thing to even discuss. I am convinced that when the day comes, someone will step up to do what is necessary. If the project is still relevant and in use. Heck, it could even be a great chance to change the way the project is run…
Unless of course the project has already ran out of its use by then, and then it doesn’t matter if someone steps up or not.
Most (95%) of the copyrights in the project are mine. But I have decided to ship the code under a liberal license, so while successors cannot change the copyright situation easily, there should be very little or no reason for doing that.
The keys
If I vanish, the only vital thing you (the successors) will really miss to run and manage the curl project exactly as I have done, is the keys to the building. The passwords and the logins to the various machines and services we use that I can login to, to manage whatever I need to for the project.
If I vanish willingly, I will of course properly hand these over to someone who is willing to step up and take the responsibility. If I instead suddenly get abducted by aliens with no chance for a smooth transition, I have systems setup so that people left behind know what to do and can get access to them.
Recently I have received curious questions from users, customers and bystanders.
Can you explain the seemingly increased CVE activity in curl over like the last year or so?
(data and stats for this post comes mostly from the curl dashboard)
Pointless but related poll I ran on Twitter
Frequency
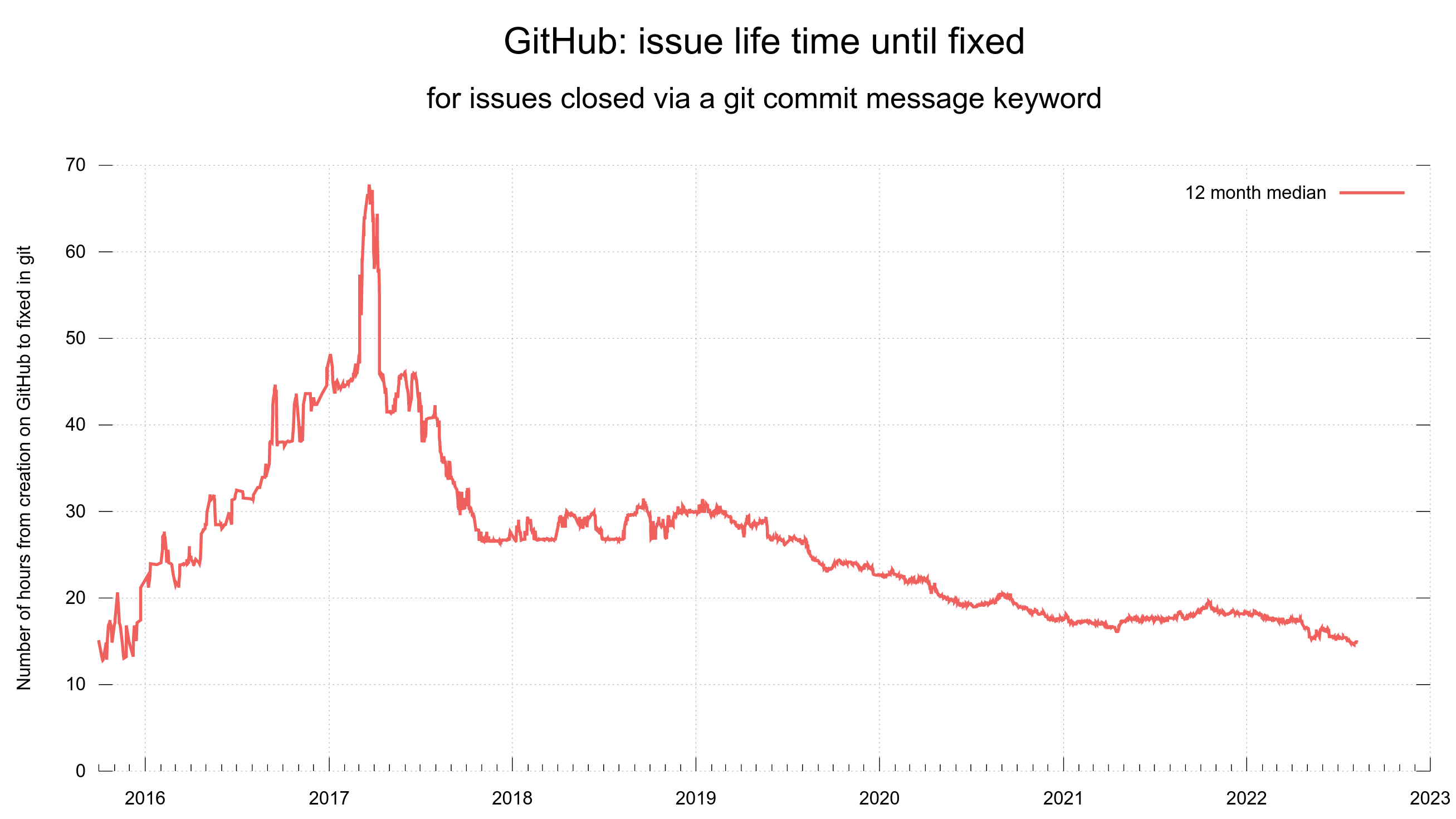
In 2022 we have already had 14 CVEs reported so far, and we will announce the 15th when we release curl 7.85.0 at the end of August. Going into September 2022, there have been a total of 18 reported CVEs in the last 12 months.
During the whole of 2021 we had 13 CVEs reported – and already that was a large amount and the most CVEs in a single year since 2016.
There has clearly been an increased CVE issue rate in curl as of late.
Finding and fixing problems is good
While every reported security problem stings my ego and makes my soul hurt since it was yet another mistake I feel I should have found or not made in the first place, the key take away is still that it is good that they are found and reported so that they can be fixed properly. Ideally, we also learn something from each such report and make it less likely that we ever introduce that (kind of) problem again.
That might be the absolutely hardest task around each CVE. To figure out what went wrong, detect a pattern and then lock it down. It’s almost amusing how all bugs look a like a one-off mistake with nothing to learn from…
Ironically, the only way we know people are looking really hard at curl security is when someone reports security problems. If there was no reports at all, can we really be sure that people are scrutinizing the code the way we want?
Who is counting?
Counting the amount of CVEs and giving that a meaning, or even comparing the number between projects, is futile and a bad idea. The number does not say much and comparing two projects this way is impossible and will not tell you anything. Every project is unique.
Just counting CVEs disregards the fact that they all have severity levels. Are they a dozen “severity low” or are they a handful of critical ones? Even if you take severity into account, they might have gotten entirely different severity for virtually the same error, or vice versa.
Further, some projects attract more scrutinize and investigation because they are considered more worthwhile targets. Or perhaps they just pay researchers more for their findings. Projects that don’t get the same amount of focus will naturally get fewer security problems reported for them, which does not necessarily mean that they have fewer problems.
Incentives
The curl bug-bounty really works as an incentive as we do reward security researchers a sizable amount of money for every confirmed security flaw they report. Recently, we have handed over 2,400 USD for each Medium-severity security problem.
In addition to that, finding and getting credited for finding a flaw in a widespread product such as curl is also seen as an extra “feather in the hat” for a lot of security-minded bug hunters.
Over the last year alone, we have paid about 30,000 USD in bug bounty rewards to security researchers, summing up a total of over 40,000 USD since the program started.
Accumulated bug-bounty rewards for curl CVEs over time
Who’s looking?
We have been fortunate to have received the attention of some very skilled, patient and knowledgeable individuals. To find security problems in modern curl, the best bug hunters both know the ins and outs of the curl project source code itself while at the same time they know the protocols curl speaks to a deep level. That’s how you can find mismatches that shouldn’t be there and that could lead to security problems.
The 15 reports we have received in 2022 so far (including the pending one) have been reported by just four individuals. Two of them did one each, the other two did 87% of the reporting. Harry Sintonen alone reported 60% of them.
Hardly any curl security problems are found with source code analyzers or even fuzzers these days. Those low hanging fruits have already been picked.
We care, we act
Our average response time for security reports sent to the curl project has been less than two hours during 2022, for the 56 reports received so far.
We give each report a thorough investigation and we spend a serious amount of time and effort to really make sure we understand all the angles of the claim, that it really is a security problem, that we produce the best possible fix for it and not the least: that we produce a mighty fine advisory for the issue that explains it to the world with detail and accuracy.
Less than 8% of the submissions we get are eventually confirmed actual security problems.
As a general rule all security problems we confirm, are fixed in the pending next release. The only acceptable exception would be if the report arrives just a day or two from the next release date.
We work hard to make curl more secure and to use more ways of writing secure code and tools to detect mistakes than ever, to minimize the risk for introducing security flaws.
Judge a project on how it acts
Since you cannot judge a project by the number of CVEs that come out of it, what you should instead pay more focus on when you assess the health of a software project is how it acts when security problems are reported.
Most problems are still very old
In the curl project we make a habit of tracing back and figuring out exactly in which release each and every security problem was once introduced. Often the exact commit. (Usually that commit was authored by me, but let’s not linger on that fact now.)
One fun thing this allows us to do, is to see how long time the offending code has been present in releases. The period during which all the eyeballs that presumably glanced over the code missed the fact that there was a security bug in there.
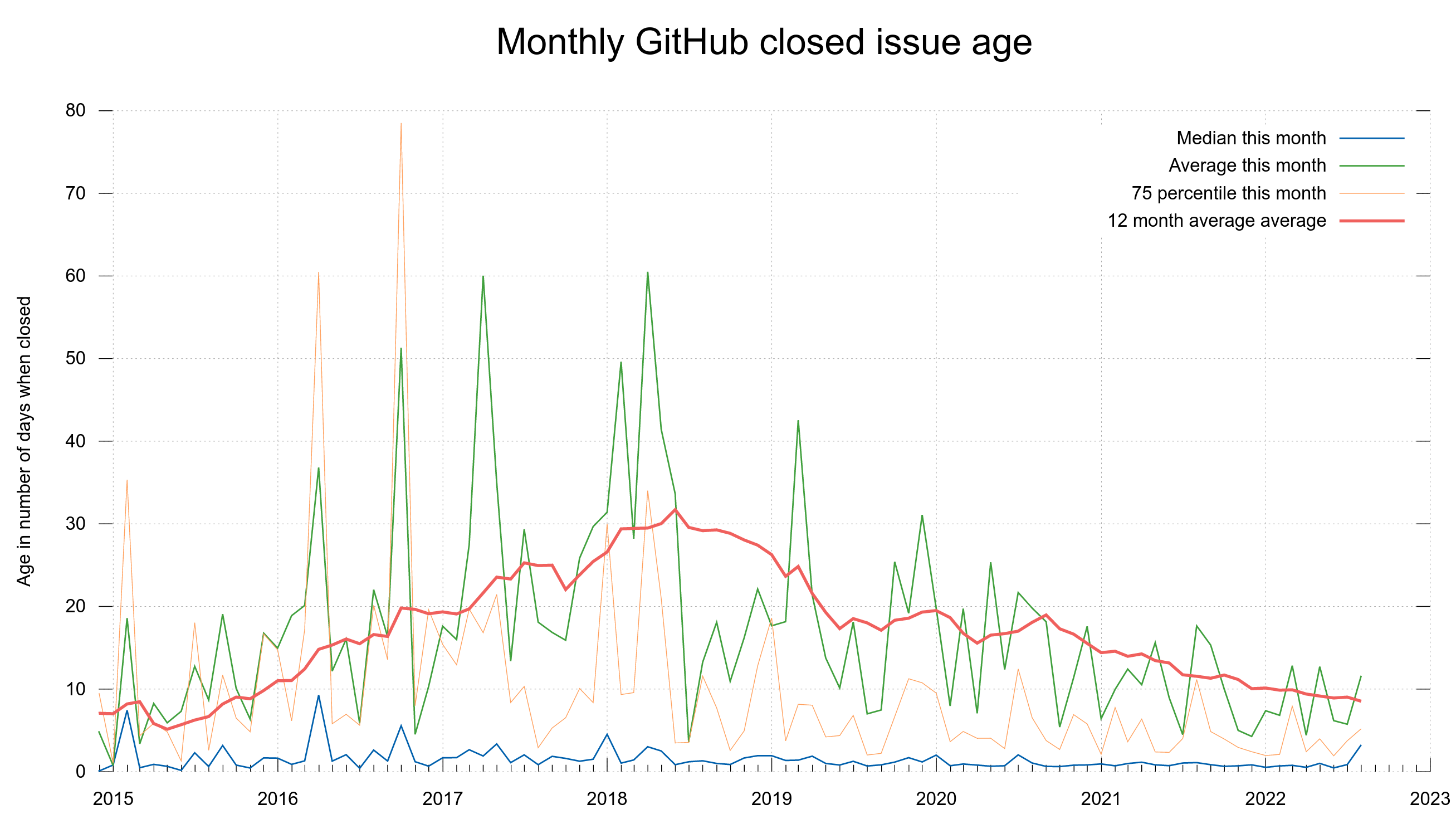
On average, curl security problems have been present an extended period of time before there are found and reported.
On average for all CVEs: 2,867 days
The average time bugs were present for CVEs reported during the last 12 months is a whopping 3,245 days. This is very close to nine years.
How many people read the code in those nine years?
The people who find security bugs do not know nor do they care about the age of a source code line when they dig up the problems. The fact that the bugs are usually old could be an indication that we introduced more security bugs in the past than we do now.
Finding vs introducing
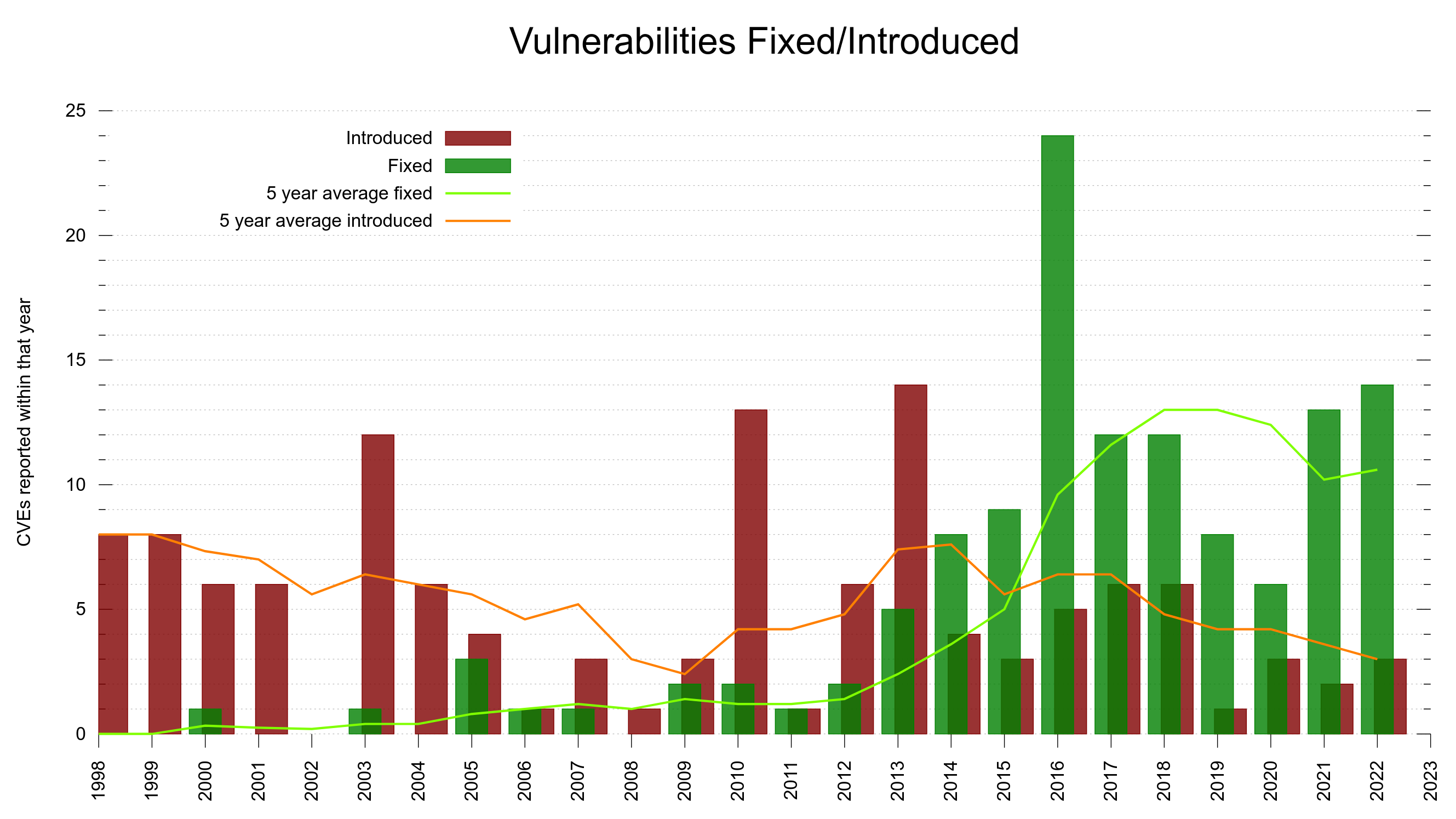
Enough about finding issues for a moment. Let’s talk about introducing security problems. I already mentioned we track down exactly when security flaws were introduced. We know.
All CVEs in curl, green are found, red are introduced
With this, we can look at the trend and see if we are improving over time.
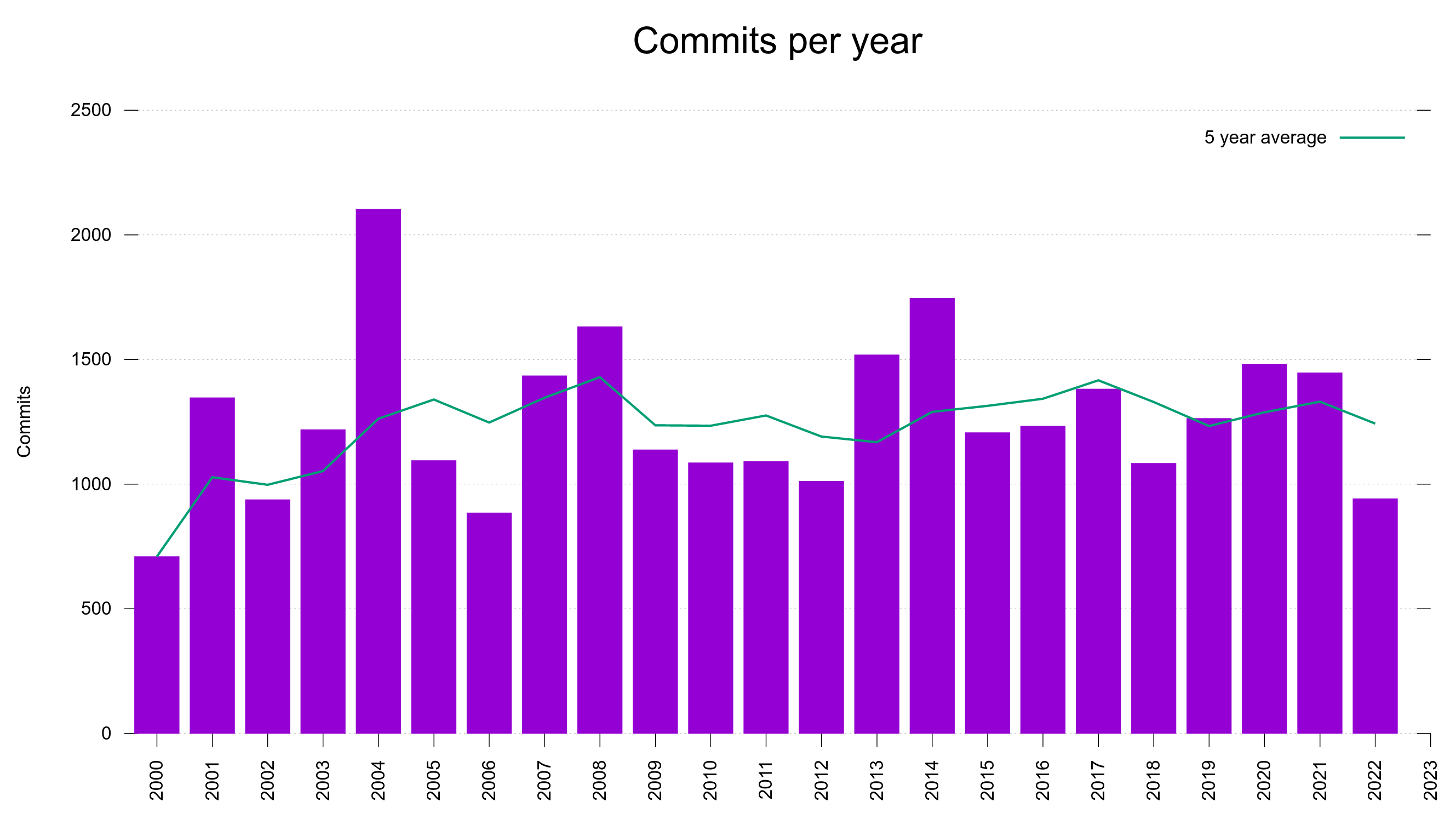
The project has existed for almost 25 years, which means that if we introduce problems spread out evenly over time, we would have added 4% of them every year. About 5 CVE problems are introduced per year on average. So, being above or below 5 introduced makes us above or below an average year.
Bugs are probably not introduced as a product of time, but more as a product of number of lines of code or perhaps as a ratio of the commits.
75% of the CVE errors were introduced before March 2014 – and yet the code base “only” had 102,000 lines of code at the end of that period. At that time, we had done 61% of the git commits (17684). One CVE per 189 commits.
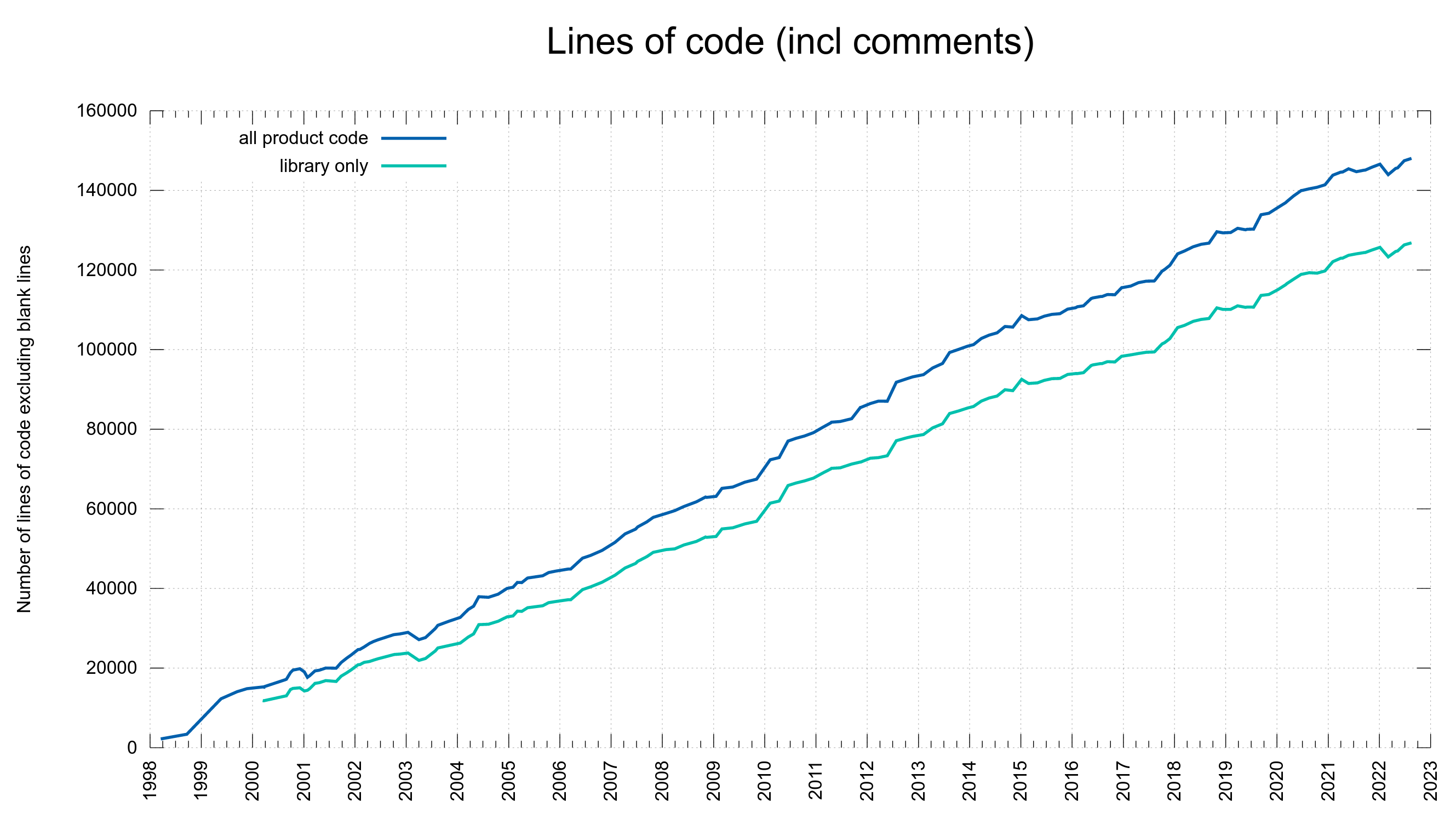
15% of the security problems were introduced during the last five years and now we are at 148,000 lines of code. Finding needles in a growing haystack. With more code than ever before, we introduce bugs at a lower-than average rate. One CVE per 352 commits. This probably is also related to the ever-growing number of tests and CI jobs that help us detect more problems before we merge them.
Number of lines of code. Includes comments, excludes blank lines
The commit rate has remained between 1,100 and 1,700 commits per year since 2007 with ups and downs but no obvious growing or declining trend.
Number of commits per year
Harry Sintonen
Harry reported a large amount of the recent curl CVEs as mentioned above, and is credited for a total of 17 reported curl CVEs – no one else is even close to that track record. I figured it is apt to ask him about the curl situation of today, to make sure this is not just me hallucinating things up. What do you think is the reason for the increased number of CVEs in curl in 2022?
Harry replied:
The news of good bounties being paid likely has been attracting more researchers to look at curl.
I did put considerable effort in doing code reviews. I’m sure some other people put in a lot of effort too.
When a certain before unseen type of vulnerability is found, it will attract people to look at the code as a whole for similar or surrounding issues. This quite often results in new, similar CVEs bundling up. This is kind of a clustering effect.
It’s worth mentioning, I think, that even though there has been more CVEs found recently, they have been found (well most of them at least) as part of the bug bounty program and get handled in a controlled manner. While it would be even better to have no vulnerabilities at all, finding and handling them in controlled manner is the 2nd best option.
This might be escaping a random observer who just looks at the recent amount of CVEs and goes “oh this is really bad – something must have gone wrong!”. Some of the issues are rather old and were only found now due to the increased attention.
Conclusion
We introduce CVE problems at a slower rate now than we did in the past even though we have gotten problems reported at a higher than usual frequency recently.
The way I see it, we are good. I suppose the future will tell if I am right.
With just a month left until its seventh birthday, everything curl has now surpassed this amazing milestone. The book now contains more than 100,000 words. Distributed over 883 sections. All written in glorious markdown.
Two years ago when we celebrated its 5th birthday, it was still this measly thin “pamphlet” of 72,000 words. It has grown by almost 40% over the last two years.
The average word length in the book is now 5.25 characters and all this is spread out over 14,900 lines (in the source markdowns).
63 individuals have had their commits merged. I have great help from people to polish off weird language and wrong English.
My ambition with this book remains the same: to document everything there is to tell about curl and libcurl from every aspect. Code, use, development, project, background, future, philosophy and more.
CI
News from the last year for everything curl is that we have several CI jobs now that verify new contributions to make sure we don’t degrade too much. They check that:
we avoid some words (contractions and some other things) – basically my most common mistakes
spellcheck
markdown heading level sanity check
The spellcheck part can of course be a bit tedious for such a technical document but I realized that since I am such a sloppy writer I need that check. This has really reduced the inflow of PRs with spelling fixes.
These CI jobs makes the quality of the book much better even though it is a highly moving target.
Keeping up
As curl is a constantly evolving project that adds new features and changes things every now and then, there is also a constant stream of new things to add or update in the book.
Since I also want the book to work for readers that may very well run curl versions from several years ago, we need to keep that in mind and make sure to keep “old behavior” and details around for a while.
In the curl project we do timed releases and we try to do them planned and scheduled long in advance. The dates are planned. The content is not.
I have been the release manager for every single curl release done. 209 releases at current count. Having this role means I make sure things are in decent shape for releases and I do the actual mechanic act of running the release scripts etc on the release days.
Since 2014, we make releases on Wednesdays, every eight weeks. We sometimes adjust the date slightly because of personal events (meaning: if I have a vacation when the release is about to happen, we can move it), and we have done several patch releases within a shorter time when the previous release proved to have a serious enough problem to warrant an out-of-schedule release. Even more specifically, I make the releases available at or around 8 am (central euro time) on the release days.
The main objective is to stick to the 56 day interval.
It probably goes without saying but let me be clear: curl is a software project that quite evidently will never be done or complete. It will keep getting fixes, improvements and features for as long as it lives, and as long as it lives we keep making new releases.
Timed releases
We decided to go with a fixed eight weeks release frequency quite arbitrarily (based on past release history and what felt “right”) but it has over time proved to work well. It is short enough for everyone to never have to wait very long for the next release, and yet it is long enough to give us time for both merging new features and having a period of stabilization.
Timed releases means that we ship releases on the predetermined release date with all the existing features and bugfixes that have landed in the master branch in time. If a change is not done in time and it is not merged before the release, it will simply not be included in the release but will get a new opportunity to get included and shipped in the next release. Forever and ever.
I am a proponent of timed releases compared to feature based ones for projects like curl. For the simplicity of managing the releases, for long term planning, for user communication and more.
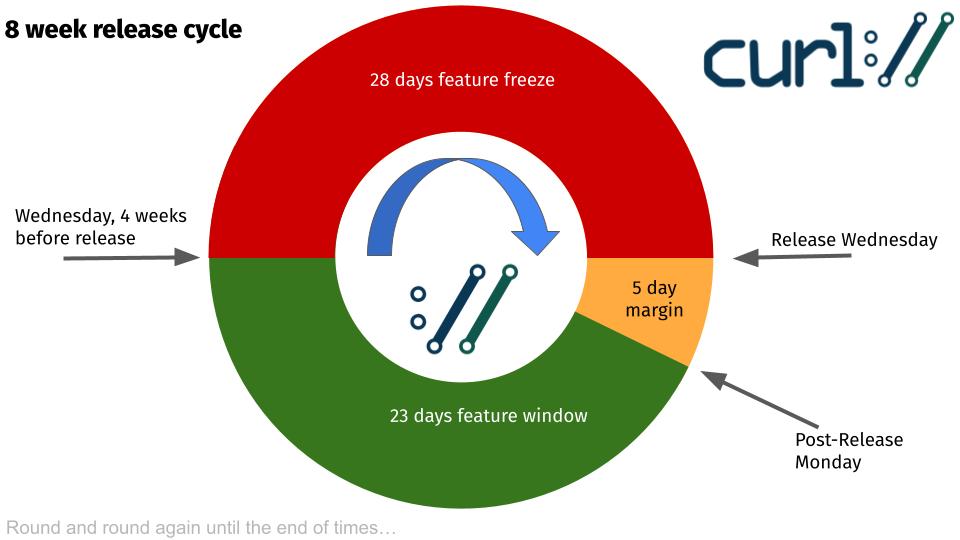
The cycle has three windows
Within the eight week release cycle, there are three distinct and different windows or phases.
1 – release margin
The cycle can be said to start at the day of a release. The release is created straight from the master git branch. It gets signed, uploaded, blogged about and the news of it is shouted across the globe.
This day also starts the “release margin window”. In this window we still accept and merge bugfixes into the master branch, but we do not merge changes or new features.
The five day margin this speaks of, is that this window gives us a few calendar days to assess and get a feel for how the previous release is being received. Is there a serious bug reported? Did we somehow royally mess up? If we did an important enough snafu, we may decide to do a follow-up patch release soon and if we do, we are in a better position if we have not merged any changes yet into the release branch.
If we decide on doing a patch release, we skip the feature window and go directly to feature freeze.
2 – feature window
If we survived the margin window without anything alarming happening, we open the feature window. On the Monday following the preceding release.
This is the phase during which we merge changes and new features in addition to the regular normal bugfixes (assuming there are any of course). Things that warrant the minor version number for the next release to get bumped.
The feature window is open 23 days. Ideally, people have already been working and polishing on their pull-requests for a while before this window opens and then the work can get merged fairly quickly – and presumably painless.
What exactly can be considered a change and what is a bugfix can of course become a matter of opinion and discussion, but we tend to take the safer approach when in doubt.
3 – feature freeze
In the 28 days before the pending release we only merge bugfixes into the master branch. All features and changes are queued up and will have to wait until the feature window opens again. (Exceptions might be made for experimental and off-by-default features.)
This phase is of course intended for things to calm down, to smooth out rough edges, to fix any leftover mistakes done in the previous feature merges. With the mindset that the pending next release will be the best, most stable, shiniest, glorious release we ever did. With even fewer bugs than before. The next release is always our best release yet.
The release cycle as an image
(Yes, if you squint and roll your chair away from the screen a bit, it looks like the Chrome logo!)
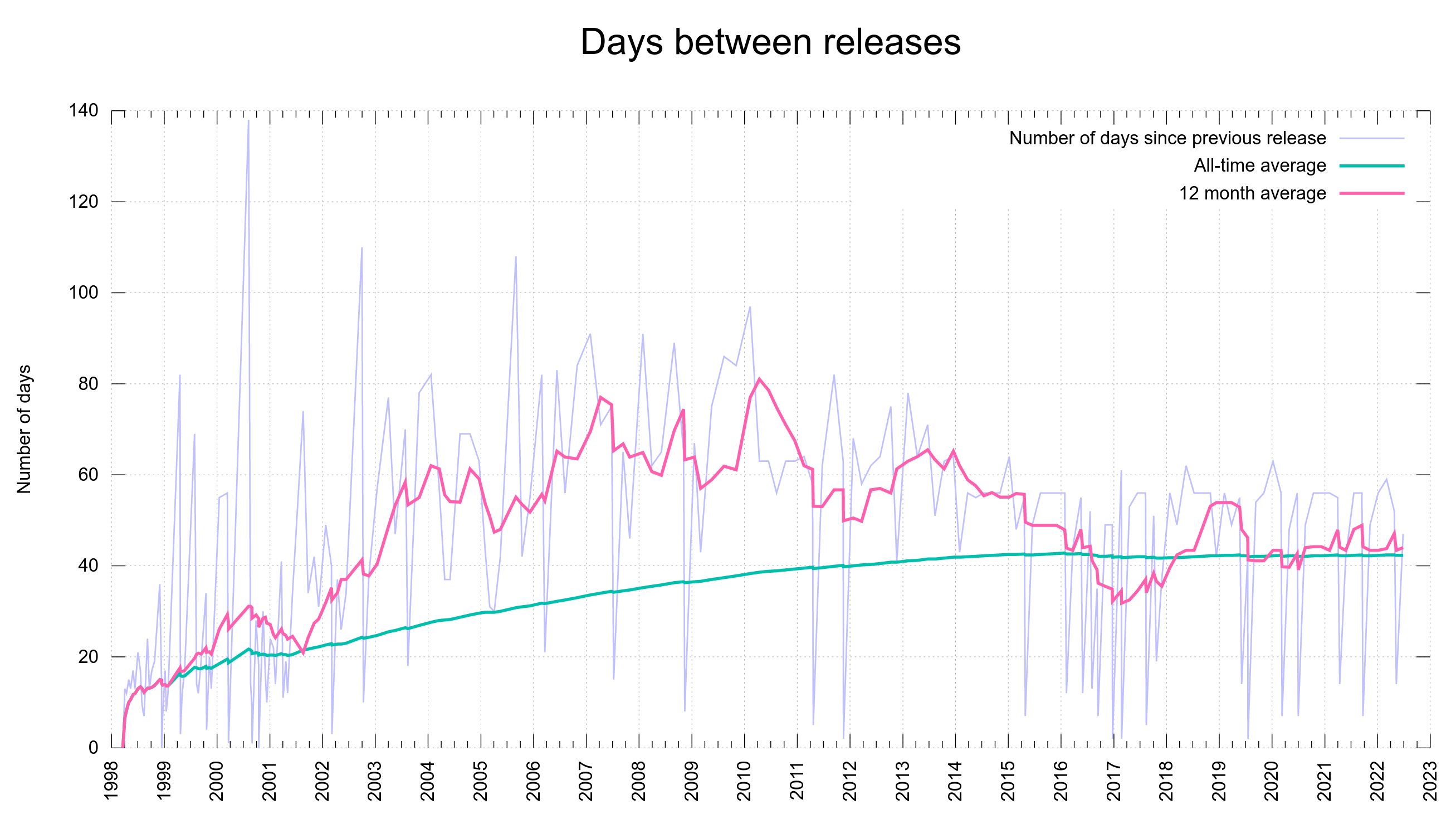
Release frequency graph
The graph below shows the number of days between all curl releases ever done. You can see the eight week release cycle introduced in 2014 visible in the graph, and you can also easily spot that we have done much quicker releases than eight weeks a number of a times since then – all of them actually a sign of some level of failure since that means we felt urged to do a patch release sooner than we had previously anticipated.
Disclaimer: I work for wolfSSL but I don’t speak for wolfSSL. I state my own opinions and I try to be as honest and transparent as possible. As always.
QUIC API
Back in the summer of 2020 I blogged about QUIC support coming in wolfSSL. That work never actually took off, primarily I believe because the team kept busy with other projects and tasks that had more customer focus and interest and yeah, there was not really any noticeable customer demand for QUIC with wolfSSL.
Time passed.
On July 21 2022, Stefan Eissing submitted his work on introducing a QUIC API and after reviews and updates, it was merged into the wolfSSL master branch on August 9th.
The QUIC API is planned to appear “for real” in a coming wolfSSL release version. Until then, we can play with what is available in git.
Let me be clear here: the good people at wolfSSL has not decided to write a full QUIC implementation, because that would be insane when so many good alternatives are already being worked on. This is just a set of new functions to allow wolfSSL to be used as TLS component when a QUIC stack is created.
Having QUIC support in wolfSSL is just one (but important) step along the way as it makes it possible to use wolfSSL to build a QUIC implementation but there are some more steps needed to turn this baby into full HTTP/3.
ngtcp2
Luckily, ngtcp2 exists and it is an established QUIC implementation that was written to be TLS agnostic from the beginning. This “only” needs adaptions provided to make sure it can be built and used with wolSSL as the TLS provider.
Stefan brought wolfSSL support to ngtcp2 in this PR. Merged on August 13th.
nghttp3
nghttp3 is the HTTP/3 library that uses ngtcp2 for QUIC, so once ngtcp2 supports wolfSSL we can use nghttp3 to do HTTP/3.
curl
curl can (as one of the available options) get built to use nghttp3 for HTTP/3, and if we just make sure we use an underlying ngtcp2 built to use a wolfSSL version with QUIC support, we can now do proper curl HTTP/3 transfers powered by wolfSSL.
Stefan made it possible to build curl with the wolfSSL+ngtcp2 combo in this PR. Merged on August 15th.
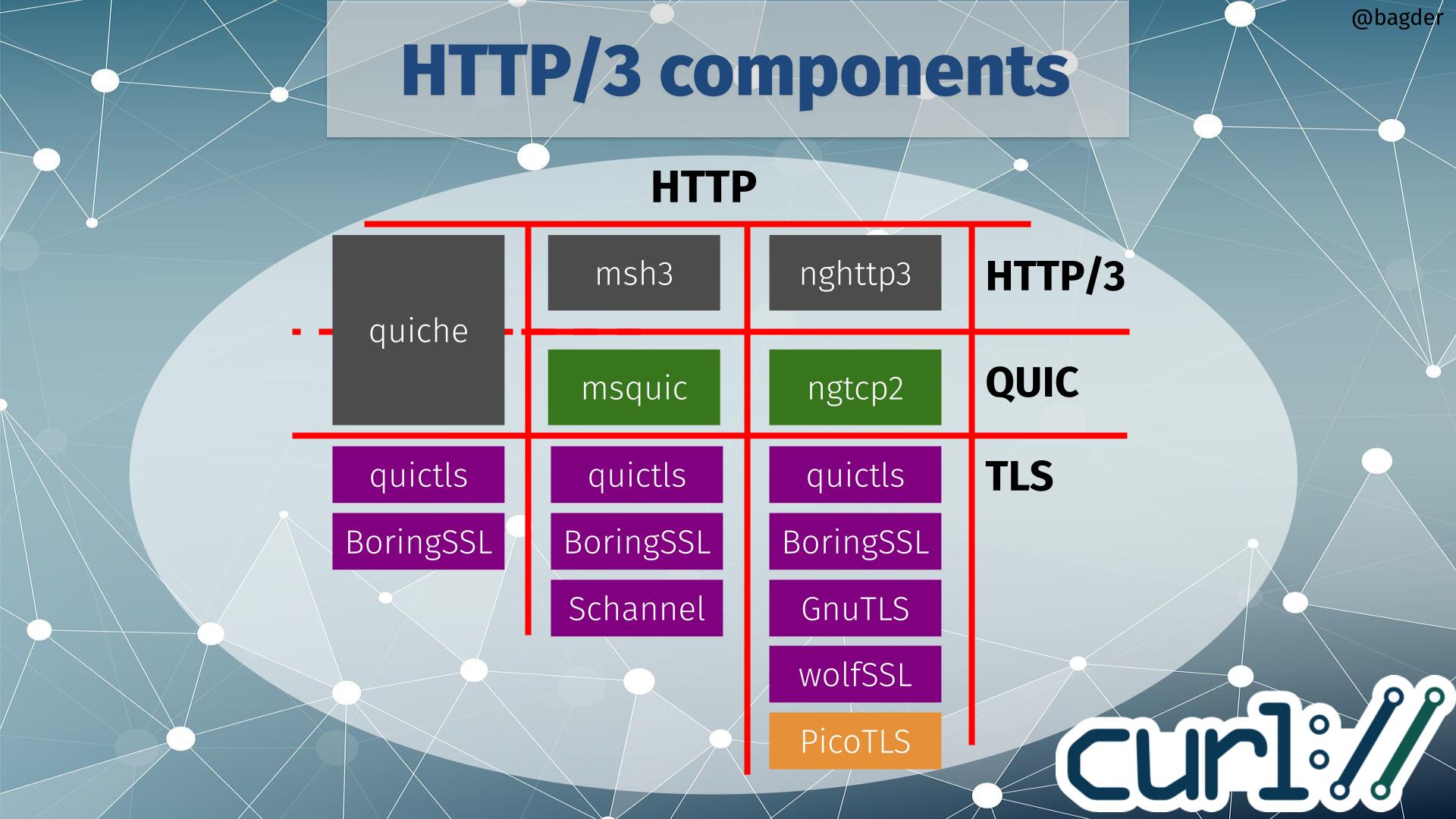
Available HTTP/3 components
With this new ecosystem addition, the chart of HTTP/3 components for curl did not get any easier to parse!
If you start by selecting which HTTP/3 library (or maybe I should call it HTTP/3 vertical) to use when building, there are three available options to go with: quiche, msh3 or nghttp3. Depending on that choice, the QUIC library is given. quiche does QUIC as well, but the two other HTTP/3 libraries use dedicated QUIC libraries (msquic and ngtcp2 respectively).
Depending on which QUIC solution you use, there is a limited selection of TLS libraries to use. The image above shows TLS libraries that curl also supports for other protocols, meaning that if you pick one of those you can still use that curl build to for example do HTTPS for HTTP version 1 or 2.
TLS options
If you instead rather pick TLS library first, only quictls and BoringSSL are supported by all QUIC libraries (quictls is an OpenSSL fork with a BoringSSL-like QUIC API patched in). If you rather build curl to use Schannel (that’s the native Windows TLS API), GnuTLS or wolfSSL you have also indirectly chosen which QUIC and HTTP/3 libraries to use.
Picotls
ngtcp2 supports Picotls shown in orange in the image above because that is a TLS 1.3-only library that is not supported for other TLS operations within curl. If you build curl and opt to go with a ngtcp2 build using Picotls for QUIC, you would need to have use an second TLS library for other TLS-using protocols. This is possible, but is rarely what users prefer.
No OpenSSL option
It should probably be especially highlighted that the plain vanilla OpenSSL is not an available option. Primarily because they decided that the already created API was not good enough for them so they will instead work on implementing their own QUIC library to be released at some point in the future. That also implies that if we want to build curl to do HTTP/3 with OpenSSL in the future, we probably need to add support for a forth QUIC library – and someone would also have to write a HTTP/3 library to use OpenSSL for QUIC.
Why wolfSSL adding QUIC is good for HTTP/3
People in general want to build applications and infrastructure using released, official and supported libraries and the sad truth is that there is a clear shortage in such TLS libraries with QUIC support.
In your typical current Linux distribution, quictls and BoringSSL are usually not viable options. The first since it is an OpenSSL fork not many even ship as a package and the second because it is done by Google for Google and they don’t do releases and generally care little for outside-Google users.
For the situations where those two TLS options are out of the game, the image above shows you the grim reality: your HTTP/3 options are limited. On Windows you can go with msh3 since it can use Schannel there, but on non-Windows you can only use ngtcp2/nghttp3 and before this wolfSSL support the only TLS option was GnuTLS.
For many embedded solutions, or even FIPS requirements, wolfSSL is now the only viable option for doing HTTP/3 with curl.
curl, along with every other Internet tool with aspirations, supports proxies. A proxy is a (usually known) middle-man in a network operation; instead of going directly to the remote end server, the client goes via a proxy.
curl has supported proxies since the day it was born.
Which proxy?
Applications that do Internet transfers often would like to automatically be able to do their transfers even when users are trapped in an environment where they use a proxy. To figure out the proxy situation automatically.
Many proxy users have to use their proxy to do Internet transfers.
A library to detect which proxy?
The challenge to figure out the proxy situation is of course even bigger if your applications can run on multiple platforms. macOS, Windows and Linux have completely different ways of storing and accessing the necessary information.
libproxy
libproxy is a well-known library used for exactly this purpose. The first feature request to add support for this into libcurl that I can find, was filed in December 2007 (I also blogged about it) and it has been popping up occasionally over the years since then.
In August 2016, David Woodhouse submitted a patch for curl that implemented support for libproxy (the PR version is here). I was skeptical then primarily because of the lack of tests and docs in libproxy (and that the project seemed totally unresponsive to bug reports). Subsequently we did not merge that pull request.
Almost six years later, in June 2022, Jan Brummer revived David’s previous work and submitted a fresh pull request to add libproxy support in curl. Another try.
The proxy library dream is clearly still very much alive. There are also a fair amount of applications and systems today that are built to use libproxy to figure out the proxy and then tell curl about it.
What is unfortunately also still present, is the unsatisfying state of libproxy. It seems to have changed and improved somewhat since the last time I looked at it (6 years ago), but there several warning signs remaining that make me hesitate.
This is not a dependency I want to encourage curl users to lean and depend upon.
I greatly appreciate the idea of a libproxy but I do not like the (state of the) implementation.
My responsibility
Or rather, the responsibility I think we have as curl maintainers. We ship a product that is used and depended upon by an almost unfathomable amount of users, tools, products and devices.
Our job is to help guide our users so that the entire product, including third party dependencies, become an as safe and secure solution as possible. I am not saying that we can take full responsibility for the security of code outside of our own domain, but I think we should recognize that what we condone and recommend will be used. People read our support for library X as some level of approval.
We should only add support for third party libraries that meets a certain quality threshold. This threshold or bar maybe is (unfortunately) not written down anywhere but is still mostly a soft “gut feeling” based on human reviews of the situation.
What to do
I think the sensible thing to do first, before trying to get curl to use libproxy, is to make sure that there is a library for proxies that we can and want to lean on. That library can be the libproxy of today but it could also be something else.
Some areas in need of attention in libproxy that I recently also highlighted in the curl PR, that would take it closer to meeting the requirements we can ask of a dependency:
Improve the project with docs. We cannot safely rely on a library and its APIs if we don’t know exactly what to expect.
There needs to be at least basic tests that verify its functionality. We cannot fix and improve the library safely if we cannot check that it still works and behaves as expected. Tests is the only reliable way to make sure of this.
Add CI jobs that build the project and run those tests. To help the project better verify that things don’t break along the way.
Consider improving the API. To be fair, it is extremely simple now, but it’s also so simple that that it becomes ineffective and quirky in some use cases.
Allow for external URL parser and URL retrieving etc to avoid blocking, double-parsing and to reuse caches properly. It would be ridiculous for curl to use a library that has its own separate (semi-broken) HTTP transfer and its own (synchronous) name resolving process.
A solid proxy library?
The current libproxy is not even a lot of code, it could perhaps make more sense to just plainly write a new library based on how you would want a library like this to work – and use all the knowledge, magic and experience from libproxy to get the technical parts done correctly. A libproxy-next-generation.
But
This would require that someone really wanted to see this development take place and happen. It would take someone to take lead in the project and push for changes (like perhaps the 5 bullets I listed above). The best would be if someone who would like to use this kind of setup could sponsor a developer half/full time for a while to get a good head start on this.
Based on history, seeing we have had this known use case and this library around for well over a decade and this is the best we have accomplished so far, I am not optimistic that we can turn this ship around. Until then, we simply cannot allow curl to use this dependency.
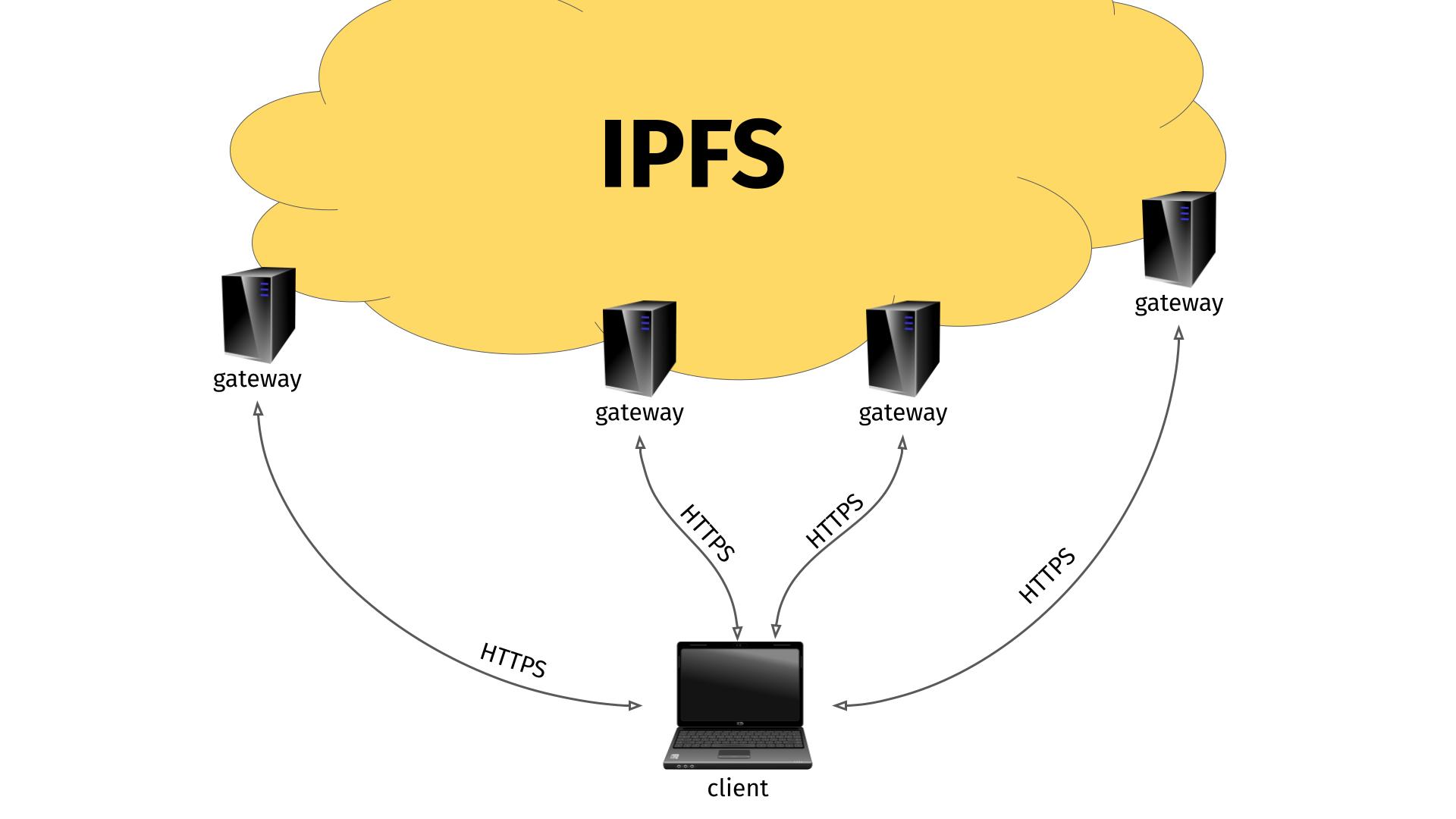
The InterPlanetary File System (IPFS) is according to the Wikipedia description: “a protocol, hypermedia and file sharing peer-to-peer network for storing and sharing data in a distributed file system.”. It works a little like bittorrent and you typically access content on it using a very long hash in an ipfs:// URL. Like this:
I guess partly because IPFS is a rather new protocol not widely supported by many clients yet, people came up with the concept of IPFS “gateways”. (Others might have called it a proxy, because that is what it really is.)
This gateway is an HTTP server that runs on a machine that also knows how to speak and access IPFS. By sending the right HTTP request to the gateway, that includes the IPFS hash you are interested in, the gateway can respond with the contents from the IPFS hash.
This way, you just need an ordinary HTTP client to access IPFS. I think it is pretty clever. But as always, the devil is in the details.
Rewrite ipfs:// into https://
The quest for IPFS aficionados have seemingly become to add support for IPFS using this gateway approach to multiple widely used applications that know how to speak HTTP(S). Just rewrite the URL internally from IPFS to HTTPS.
The IPFS “URL rewrite” is done in such so that the example IPFS URL is converted into “https://$gateway/$hash”. The transfer is done by the client as if it was a plain old HTTPS transfer.
What if the gateway is not local?
This approach has its biggest benefit of course when you can actually use a remote IPFS gateway. I presume most random ordinary users who want to access IPFS does not actually want to download, install and run an IPFS gateway on their machine to use this new power. They might very well appreciate the idea and convenience of accessing a remote IPFS gateway.
Remote IPFS gateways illustration
After all, the gateways are using HTTPS so at least the transfers are secure, right?
Leading people behind IPFS are even running public IPFS gateways for anyone to use. Both dweb.link and ipfs.io have been mentioned and suggested for default use. Possibly they are the same physical host as they appear to have the same IP addresses (owned by Protocol Labs, one of the big proponents behind IPFS).
In an attempt to make this even easier for users, ffmpeg is made to use a built-in default gateway if none is set by the user.
I would expect very few users to actually have an IPFS gateway set. And even fewer to actually specify a local one.
So, when users want to watch a video using ffmpeg and an ipfs:// URL what happens?
The gateway sees it all
The remote gateway, that is administered by someone, somewhere, gets to see the full incoming request, and all traffic (video, whatever) that is sent back to the client (ffmpeg in this example) goes via the gateway. Sure, the client accesses the gateway via HTTPS so nobody can tamper with the traffic along the way, but the gateway is in full control and can inspect and tamper with the data as much as it likes. And there is no way for the client to know or detect if it is happening.
I am not involved in ffmpeg, nor do I have any insights into how the discussions evolved and were done around this subject, but for curl I have put my foot down and said that we must not blindly use and trust any default remote gateway like this. I believe it is our responsibility to not lure users into this traffic-monitoring setup.
Make sure you trust the gateway you use.
The curl way
curl will probably output an error message if there was no gateway set when an ipfs:// URL is used, and inform the user that it needs a gateway set to function and probably also show a URL for a page that contains more information about what this means and how to specify a gateway.
Bouncing gateways!
During the work of making the IPFS support for curl (which I review and comment on, not written or authored myself) I have also learned that some of the IPFS gateways even do regular HTTP 30x redirects to bounce over the client to another gateway.
Meaning: not only do you use and rely a total rando’s gateway on the Internet for your traffic. That gateway might even, on its own discretion, redirect you over to another host. Possibly run somewhere else, monitored by a separate team.
I have insisted, in the PR for ipfs support to curl, that the IPFS URL handling code should not automatically follow such gateway redirects, as I believe that adds even more risk to the user so if a user wants to allow this operation, it should be opt-in.
Imagine rising use of this
I would imagine that the ones hosting a popular default gateway either becomes overloaded and slow, or they need to scale up. If they scale up, they risk to leak traffic even wider. Scaling up also makes the operation more expensive, leading to incentives to make money somehow to finance it. Will the cookie car in the form of a massive data trove perhaps then be used/sold?
Users of these gateways get no promises, no rights, no contracts.
Other IPFS privacy concerns
Brave, the browser, has actual native IPFS support (not using any gateway) and they have an informative page called How does IPFS Impact my Privacy?
Final verdict
I am not dissing the idea nor implementation of IPFS itself. I think using HTTP gateways to access IPFS is a good idea in general as it makes the network more accessible. It is just a fragile solution that easily misleads users to do things they maybe shouldn’t. So maybe a little too accessible?
I poked the ffmpeg project over Twitter, there was immediate reaction and there is already a proposed patch for ffmpeg that removes the use of a default IPFS gateway. “it’s a security risk”
The preferred method of providing changes to the curl project, be it source code, documentation or web site contents, is by submitting a pull-request. A “PR”. On the curl repository on GitHub.
When a proposed curl change, bugfix or improvement is submitted as a PR on GitHub, it gets built, checked, tested and verified in countless ways and a few hundred developers get a notification about it.
The first thing I do every morning and the last thing I do every night before I go to bed, is eyeing through the list of open PRs, and especially the ones with recent activities. I of course also get back to them during the day if there is activity that might need my attention – not to mention that I also personally submit by own PRs to curl at an average rate of a few per day.
You can rightly say that my day and my work with curl is extremely PR centered. And by extension, also extremely git and GitHub focused.
Merging the work
When all the CI checks run green and all review comments and concerns have been addressed, the PR has become ripe for merge.
As a general rule, we always work in the master branch as the current development branch that is destined to become the next release when the time comes. An approved PR thus gets merged into the master branch and pushed there. We keep the git history linear and clean, meaning we do merge + rebase before pushing.
Commit messages
One of the key properties of a git commit, is the commit message. The text that describes the particular change in the repository.
In the curl project we have a standard style or template for how to write these messages. This makes them consistent and helps making them useful and get populated with informational meta-data that future versions of ourselves might appreciate when we look back at the changes decades into the future.
The PR review UI on GitHub unfortunately totally ignores commit messages, which means that we cannot comment on them or insist or check that users write them in our preferred style. Arguably, it is also just quicker and easier not to do that and instead just gently brush up the message in the commit locally before the commit is pushed.
Adding correct fixes #xxx and closes #xxx information to the message also helps making sure GitHub closes the associated issues/pull-requests and allows us to map git repository commits with GitHub activities at will – like when running statistic scripts etc.
This strictness and way of working makes it impossible to use the “merge” button in the GitHub UI since we simply cannot ensure that the commit is good enough with it. The button is however not possible to remove from the UI with any settings. We just prohibit its use.
They appear as “closed this in”
This way of working makes most PRs appear as “closed this in #[commit hash]” in the GitHub UI instead of saying “merged by” that same hash. Because in GitHub’s view, the PR was not merged.
GitHub could fix this with a merges keyword, which has been suggested since forever, but clearly they do not see this as a problem.
Occasional users of course get surprised or even puzzled by us closing the PR “instead of merging”, because that is what it looks like. When it really is not.
Ultimately, I consider the state and contents of our git repository and history more important than how the PRs appear on GitHub so I stick to our way of working.
Signed commits
As a little side-note, I of course also always GPG sign my commits so you can verify on GitHub and with git that my commits are genuinely done by me.
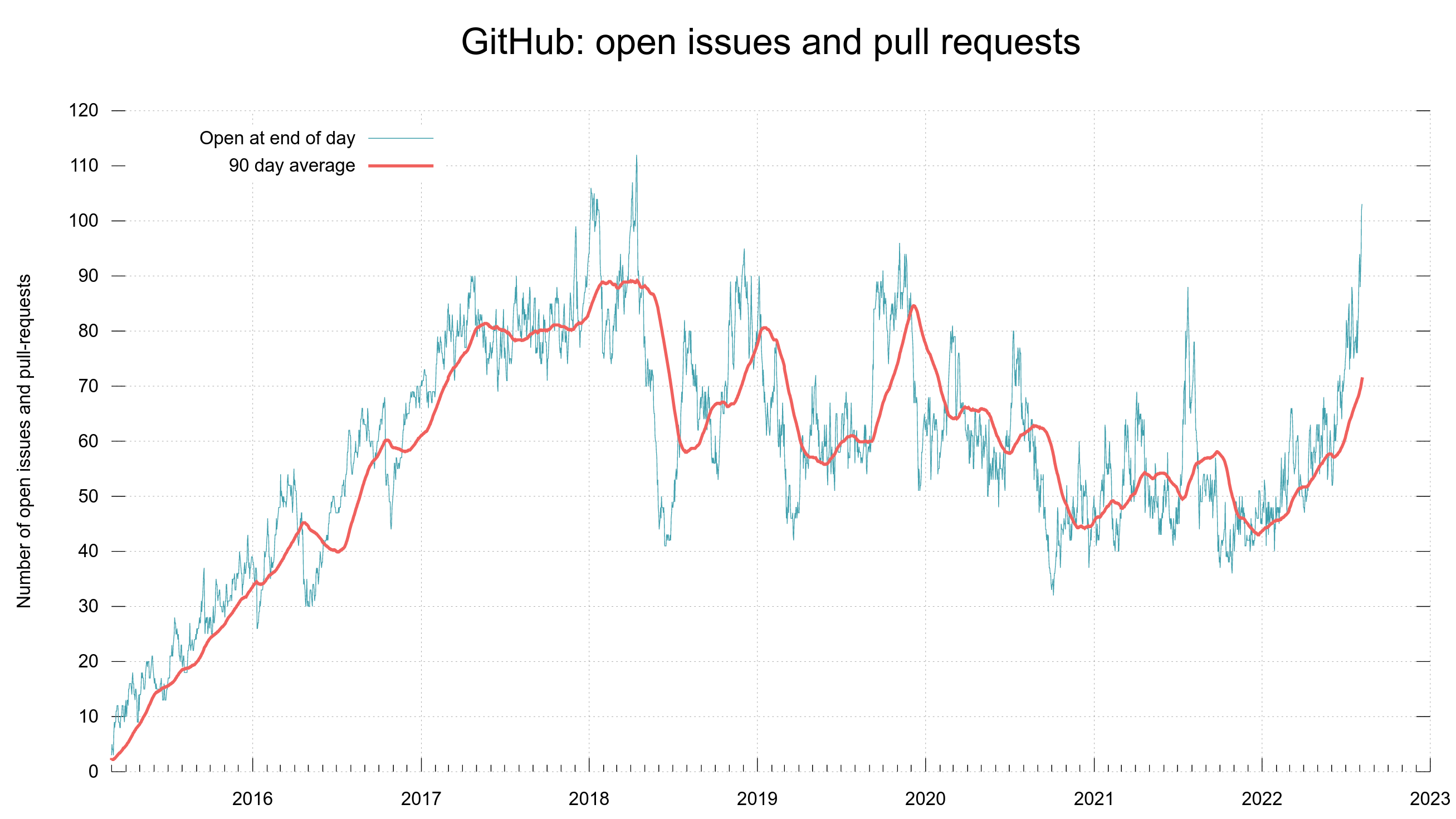
Stats
To give you an idea of the issue and pull request frequency and management in curl (the source code repository). Snapshots from the curl dashboard from August 8, 2022.
Update
Several people have mentioned to me after I posted this article that I could squash and edit the commits and force-push the work back to the user’s branch used for the PR before using the “merge” button or auto-merge feature of GitHub.
Sure, I could do it that way, but I think that is an even worse solution and a poor work-around. It is very intrusive method that would make me force-push in every user’s PR branch and I am certain a certain amount of users will be surprised by that and some even downright upset because it removes/overwrites their work. For the sake of working around a GitHub quirk. Nope, I will not do that.
My name is Emma Irwin, and I am a program manager at Microsoft, specifically working in the open source program’s office (OSPO). One of the programs I lead is the FOSS fund.
This may sound a bit odd, but normally I send an email notice to project winners, yet someone pointed out that I have missed notifying curl of their won (and I could not find any history of reaching out). As a result, I offer my sincere apologies now! – I will happily provide notice now, although the payments themselves have already started!
The Free and Open Source Software Fund (FOSS Fund) is a way for our employees to collectively select open source projects to receive $10,000 sponsorship awards throughout the year.
Microsoft’s engineers select projects they are super passionate about. Only employees who contribute to open source projects can participate in the selection process.
curl was selected in January for $10, 000.00 provided one month, for ten months through GitHub Sponsors.
Thanks very much and congratulations!
-Emma Irwin
Emma Irwin (she/her) Senior Program Manager Open Source Programs Office Microsoft