Episode 41, just out:
Topics
http2 explained in markdown, translations. Swedish?
curl feature freeze period, release october 7
Bug of the week: Downloading a long sequence of URLs results in high CPU usage and slowness
Option of the week: -O

curl and/or libcurl related
Episode 41, just out:
http2 explained in markdown, translations. Swedish?
curl feature freeze period, release october 7
Bug of the week: Downloading a long sequence of URLs results in high CPU usage and slowness
Option of the week: -O
I was invited by Robert Nyman to speak at Google in their Stockholm offices on August 26th, in his Google Tech Talk series.
“curl – a hobby project with a billion users” was the humble title of the talk.
curl is like a Swiss army-knife for HTTP and internet transfers. For over 17 years the project has been run by volunteers and now counts perhaps more than one billion users. Daniel takes us through how it started, how it works and why it never gets done.
Already back in June all the 70 seats were taken and there were more than twice as many persons in the waiting list by the time the talk was happening! A totally mind-blowing interest I mostly credit Robert’s reach and ability to gather people.
Here’s the video of the talk:
To my great surprise and joy, I got this awesome gift from the host:
 (It is an LG Watch Urbane)
(It is an LG Watch Urbane)
MOAR DOX!
Whenever we ask curl users what they lack in our project and what we should improve, the response is always clear: documentation.
Here are the most common curl command line options when doing HTTP operations. This is the web page rendered as an image, click it to get to the web version.
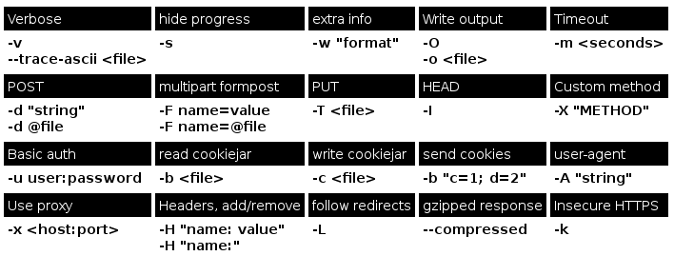
The source for the document/image is on github. As always, you can help improving it.
Update: see the refreshed version!

Kodsnack is a Swedish-speaking weekly podcast with a small team of web/app- developers discussing their experiences and thoughts on and around software development.
I was invited to participate a week ago or so, and I had a great time. Not surprisingly, the topics at hand moved a lot around curl, Firefox and HTTP/2. The recorded episode has now gone live, today.
You can find kodsnack episode 120 here, and again, it is all Swedish.
“To be honest, I often use wget to download files”
… some people tell me in a lowered voice, like if they were revealing one of their deepest family secrets to me. This is usually done with a slightly scared and a little ashamed look in their eyes – yet still intrigued, like it took some effort to say that straight in my face. How will I respond to that!?
I enjoy maintaining a notion that there is a “war” between curl and wget. Like the classics emacs vs vi or KDE vs GNOME. That we’re like two rivals competing for some awesome prize and both teams are glaring at the other one and throwing the occasional insult over the wall at the competing team. Mostly because people believe it and I sort of like the image it projects in my brain. So I continue doing jokes about it when I can.

In reality though, where some of us spend our lives, there is no such war. There’s no conflict or backstabbing going on. We’re quite simply two open source projects busy doing our own things and we’ve both been doing it for almost two decades. I consider the current wget maintainer, Giuseppe, a friend and I’m friends with the two former maintainers as well.
We have more things in common than what separates us. We’re like members of the fairly exclusive HTTP/FTP command line tool club that doesn’t have that many members.
We don’t have a lot of developer overlap, there are but a few occasional contributors sending patches to both projects and I’m one of them. We have some functional overlap in the curl tool with wget but really, I strongly recommend everyone to always use the best tool for the job and to use the tool they prefer. If wget does the job, use it. If it does the job better than curl, then switch to wget.
There’s been a line in the curl FAQ since over 15 years: “Never, during curl’s development, have we intended curl to replace wget or compete on its market.” and it tells the truth. We are believers in the Unix philosophy that each tool does what it does best and you get your job done best by combining the right set of tools. In the curl project we make one command line tool and we make it as good as we can, but we still urge our users to use the best tool for the job even when that means not using our tool.
All this said, there are plenty of things, protocols and features that curl does that you cannot find in wget and that wget doesn’t do. I’ve detailed some differences in my curl vs wget document. Some things that both can do are much easier to do with curl or offer you more control or power than in the wget counter part. Those are the things you should use curl for. Use the best tool for the job.
What takes the most effort in the curl project (and frankly that gets used by the largest amount of users in the world) is the making of the libcurl transfer library to which there is no alternative in the wget project. Writing a stable multi platform library with a sensible and solid API is much harder and lots of more work than writing a command line tool.
OK, I’ll stop tip-toeing and answer the question you really wanted to know while enduring all this text up until this point:
When do you suggest I use wget instead of curl?
For me, wget is for recursive gets and for doing more persistent and patient retries of continuing transfers over really bad connections and networks better. But then you really must take my bias into account and ignore anything I say because I live and breath the curl life.
I’ve grown a bit tired of the web filling up with curl command line examples showing use of superfluous -X’s. I’m putting code where my mouth is.

Starting with curl 7.45.0 (due to ship October 7th 2015), the tool will help users to understand that their use of the -X (or --request) is very often unnecessary or even downright wrong. If you specify the same method with -X that will be used anyway, and you have verbose mode enabled, curl will inform you about it and gently push you to stop doing it.
Example:
$ curl -I -XHEAD http://example.com --verbose
The option dash capital i means asking curl to issue a HEAD request. Adding -X HEAD to that command line asks for it again. This option sequence will now make curl say:
Note: Unnecessary use of -X or --request, HEAD is already inferred.
It’ll also inform the user similarly if you do -XGET on a normal fetch or -XPOST when using one of the -d options. Like this:
$ curl -v -d hello -XPOST http://example.com Note: Unnecessary use of
-Xor--request, POST is already inferred.
curl will still continue to work exactly like before though, these are only informational texts that won’t alter any behaviors. Again, it only says this if verbose mode is enabled.
When doing HTTP with curl, the -X option changes the actual method string in the HTTP request. That’s all it does. It does not change behavior accordingly. It’s the perfect option when you want to send a DELETE method or TRACE or similar that curl has no native support for and you want to send easily. You can use it to make curl send a GET with a request-body or you can use it to have the -d option work even when you want to send a PUT. All good uses.
I know several users out there will disagree with this. That’s also why this is only shown in verbose mode and it only says “Note:” about it. For now.
There are a few problems with the superfluous uses of -X in curl:
One of most obvious problems is that if you also tell curl to follow HTTP redirects (using -L or --location), the -X option will also be used on the redirected-to requests which may not at all be what the server asks for and the user expected. Dropping the -X will make curl adhere to what the server asks for. And if you want to alter what method to use in a redirect, curl already have dedicated options for that named --post301, --post302 and --post303!
But even without following redirects, just throwing in an extra -X “to clarify” leads users into believing that -X has a function to serve there when it doesn’t. It leads the user to use that -X in his or her’s next command line too, which then may use redirects or something else that makes it unsuitable.
The perhaps biggest mistake you can do with -X, and one that now actually leads to curl showing a “warning”, is if you’d use -XHEAD on an ordinary command line (that isn’t using -I). Like this (I’ll display it crossed over to make it abundantly clear that this is a bad command line):
$ curl -XHEAD http://example.com/
… which will have curl act as if it sends a GET but it sends a HEAD. A response to a HEAD never has a body, although it sends the size of the body exactly like a GET response which thus mostly will lead to curl to sit there waiting for the response body to arrive when it simply won’t and it’ll hang.
Starting with this change, this is the warning it’ll show for the above command line:
Warning: Setting custom HTTP method to HEAD may not work the way you want.
 Back in March 2015, I asked friends for a forecast on how much HTTP traffic that will be HTTP/2 by the end of the year and we arrived at about 10% as a group. Are we getting there? Remember that RFC 7540 was published on May 15th, so it is still less than 4 months old!
Back in March 2015, I asked friends for a forecast on how much HTTP traffic that will be HTTP/2 by the end of the year and we arrived at about 10% as a group. Are we getting there? Remember that RFC 7540 was published on May 15th, so it is still less than 4 months old!
The HTTP/2 implementations page now lists almost 40 reasonably up-to-date implementations.
Since then, all browsers used by the vast majority of people have stated that they have or will have HTTP/2 support soon (Firefox, Chrome, Edge, Safari and Opera – including Firefox and Chrome on Android and Safari on iPhone). Even OS support is coming: on iOS 9 the support is coming as we speak and the windows HTTP library is getting HTTP/2 support. The adoption rate so far is not limited by the clients.
Unfortunately, the WGet summer of code project to add HTTP/2 support failed.
(I have high hopes for getting a HTTP/2 enabled curl into Debian soon as they’ve just packaged a new enough nghttp2 library. If things go well, this leads the way for other distros too.)
Server-side we see Apache’s mod_h2 module ship in a public release soon (possibly in a httpd version 2.4 series release), nginx has this alpha patch I’ve already mentioned and Apache Traffic Server (ATS) has already shipped h2 support for a while and my friends tell me that 6.0 has fixed numerous of their initial bugs. IIS 10 for Windows 10 was released on July 29th 2015 and supports HTTP/2. H2O and nghttp2 have shipped HTTP/2 for a long time by now. I would say that the infrastructure offering is starting to look really good! Around the end of the year it’ll look even better than today.
Of course we’re still seeing HTTP/2 only deployed over HTTPS so HTTP/2 cannot currently get more popular than HTTPS is but there’s also no real reason for a site using HTTPS today to not provide HTTP/2 within the near future. I think there’s a real possibility that we go above 10% use already in 2015 and at least for browser traffic to HTTPS sites we should be able to that almost every single HTTPS site will go HTTP/2 during 2016.
The delayed start of letsencrypt has also delayed more and easier HTTPS adoption.
I’m waiting to see the intermediaries really catch up. Varnish, Squid and HAProxy I believe all are planning to support it to at least some extent, but I’ve not yet seen them release a version with HTTP/2 enabled.
I hear there’s still not a good HTTP/2 story on Android and its stock HTTP library, although you can in fact run libcurl HTTP/2 enabled even there, and I believe there are other stand-alone libs for Android that support HTTP/2 too, like OkHttp for example.
 The latest stable Firefox release right now is version 40. It counts 13% HTTP/2 responses among all HTTP responses. Counted as a share of the transactions going over HTTPS, the share is roughly 27%! (Since Firefox 40 counts 47% of the transactions as HTTPS.)
The latest stable Firefox release right now is version 40. It counts 13% HTTP/2 responses among all HTTP responses. Counted as a share of the transactions going over HTTPS, the share is roughly 27%! (Since Firefox 40 counts 47% of the transactions as HTTPS.)
This is certainly showing a share of the high volume sites of course, but there are also several very high volume sites that have not yet gone HTTP/2, like Facebook, Yahoo, Amazon, Wikipedia and more…
Right, it is not a fair comparison, but… The first IPv6 RFC has been out for almost twenty years and the adoption is right now at about 8.4% globally.
In the curl project we currently support eleven different TLS libraries. That is 8 libraries and the OpenSSL “trinity” consisting of BoringSSL, libressl and of course OpenSSL itself.
You could easily be mislead into believing that supporting three libraries that all have a common base would be really easy since they have the same API. But no, it isn’t. Sure, they have the same foundation and they all three have more in common that they differ but still, they all diverge in their own little ways and from my stand-point libressl seems to be the one that causes us the least friction going forward.
easy since they have the same API. But no, it isn’t. Sure, they have the same foundation and they all three have more in common that they differ but still, they all diverge in their own little ways and from my stand-point libressl seems to be the one that causes us the least friction going forward.
Let me also stress that I’m but a user of these projects, I don’t participate in their work and I don’t have any insights into their internal doings or greater goals.
Easy-peacy, very similar to OpenSSL. The biggest obstacle might be that the version numbering is different so an old program that might be adjusted to different OpenSSL features based on version numbers (like curl was) needs some adjusting. There’s a convenient LIBRESSL_VERSION_NUMBER define to detect libressl with.
I regularly build curl against OpenSSL from their git master to get an early head-start when they change things and break backwards compatibility. They’ve increased that behavior since Heartbleed and while I generally agree with their ambitions on making more structs opaque instead of exposing all internals, it also hurts us over and over again when they remove things we’ve been using for years. What’s “funny” is that in almost all cases, their response is “well use this way instead” and it has turned out that there’s an equally old API that is still there that we can use instead. It also tells something about their documentation situation when that is such a common pattern. It’s never been possible to grasp this from just reading docs.
BoringSSL has made great inroads in the market and is used on Android now and more. They don’t do releases(!) and have no version numbers so the only thing we can do is to build from git and there’s no install target in the makefile. There’s no docs for it, they remove APIs from OpenSSL (curl can’t support NTLM nor OCSP stapling when built with it), they’ve changed several data types in the API making it really hard to build curl without warnings. Funnily, they also introduced non-namespaced typedefs prefixed with X509_* that collide with other common headers.
A while ago we noticed BoringSSL had removed the DES_set_odd_parity function which we use in curl. We changed the configure script to look for it and changed the code to survive without it. The lack of that function then also signaled that it wasn’t OpenSSL, it was BoringSSL
BoringSSL moved around things that caused our configure script to no longer detect it as “OpenSSL compliant” because CRYPTO_lock could no longer be found by configure. We changed it to instead search for HMAC_Init and we were fine again.
Time passed and BoringSSL brought back DES_set_odd_parity, so our configure script no longer saw it as BoringSSL (the Android fixed this problem in their git but never sent as the fix). We changed the configure script accordingly to properly use OPENSSL_IS_BORINGSSL instead to detect BoringSSL which was the correct thing anyway and now as a bonus it can thus detect and work with both new and old BoringSSL versions.
A short time after, I again try to build curl against the OpenSSL master branch only to realize they’ve deprecated HMAC_Init that we just recently switched to for detection (since the configure script needs to check for a particular named function within a library to really know that it has detected and can use said library). Sigh, we switched “detect function” again to HMAC_Update. Hopefully this exists in all three and will stick around for a while…
Right now I think we can detect and use all three. It is only a matter of time until one of them will ruin that and we will adapt again.
I got this neat t-shirt in the mail yesterday. 3scale runs a sort of marketing campaign right now and they give away this shirt to the ones who participate, and they were kind enough to send one to me!

I produce a fair amount of open source code. I make that code available online. curl is probably the most popular package.
People ask me how they can trust that they are actually downloading what I put up there. People ask me when my source code can be retrieved over HTTPS. Signatures and hashes don’t add a lot against attacks when they all also are fetched over HTTP…
 I really and truly want to offer HTTPS (only) for all my sites. I and my friends run a whole busload of sites on the same physical machine and IP address (www.haxx.se, daniel.haxx.se, curl.haxx.se, c-ares.haxx.se, cool.haxx.se, libssh2.org and many more) so I would like a solution that works for all of them.
I really and truly want to offer HTTPS (only) for all my sites. I and my friends run a whole busload of sites on the same physical machine and IP address (www.haxx.se, daniel.haxx.se, curl.haxx.se, c-ares.haxx.se, cool.haxx.se, libssh2.org and many more) so I would like a solution that works for all of them.
I can do this by buying certs, either a lot of individual ones or a few wildcard ones and then all servers would be covered. But the cost and the inconvenience of needing a lot of different things to make everything work has put me off. Especially since I’ve learned that there is a better solution in the works!
Let’s Encrypt will not only solve the problem for us from a cost perspective, but they also promise to solve some of the quirks on the technical side as well. They say they will ship certificates by September 2015 and that has made me wait for that option rather than rolling up my sleeves to solve the problem with my own sweat and money. Of course there’s a risk that they are delayed, but I’m not running against a hard deadline myself here.
Related, I’ve been much involved in the HTTP/2 development and I host my “http2 explained” document on my still non-HTTPS site. I get a lot of questions (and some mocking) about why my HTTP/2 documentation isn’t itself available over HTTP/2. I would really like to offer it over HTTP/2.
Since all the browsers only do HTTP/2 over HTTPS, a prerequisite here is that I get HTTPS up and running first. See above.
Once HTTPS is in place, I want to get HTTP/2 going as well. I still run good old Apache here so it might be done using mod_h2 or perhaps with a fronting nghttp2 proxy. We’ll see.