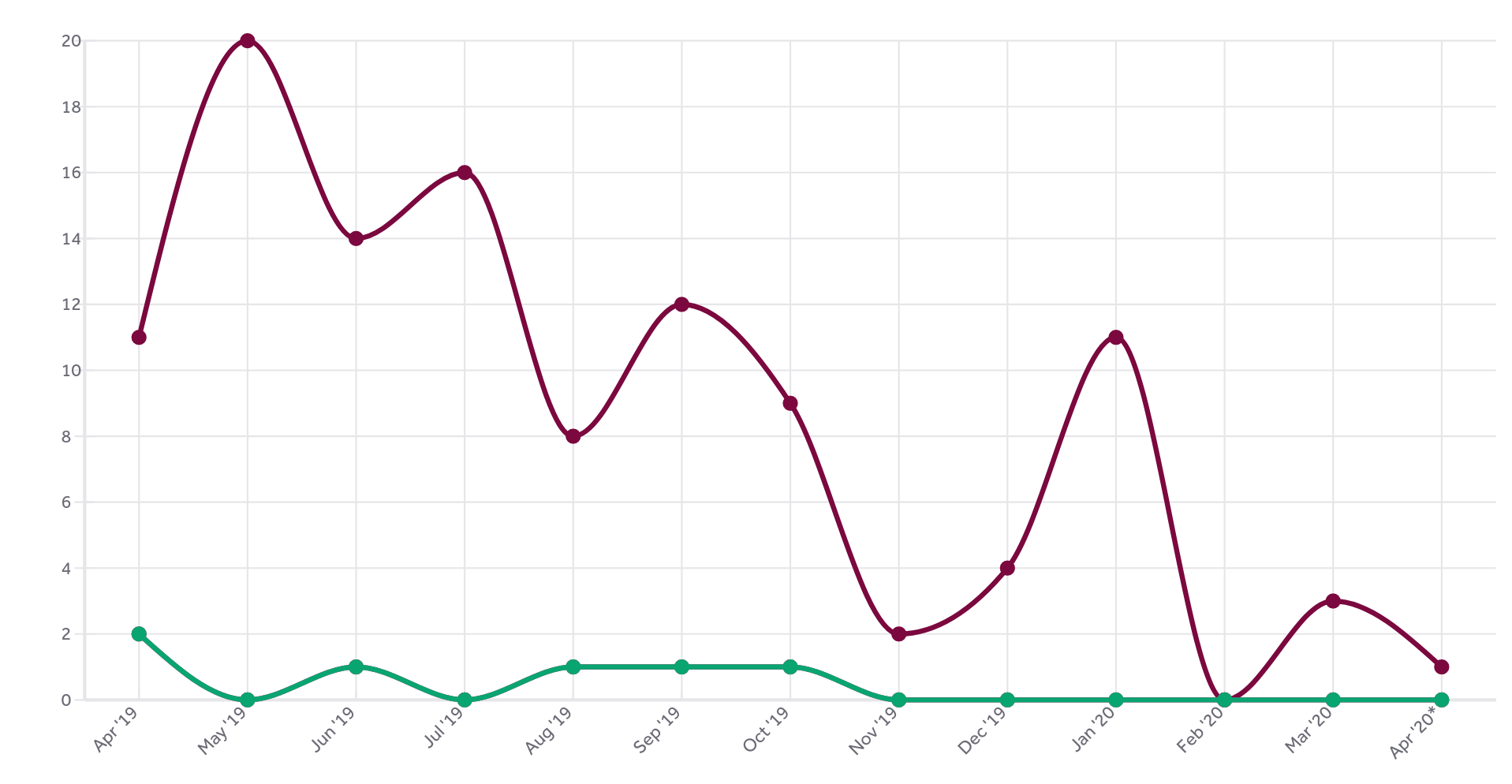
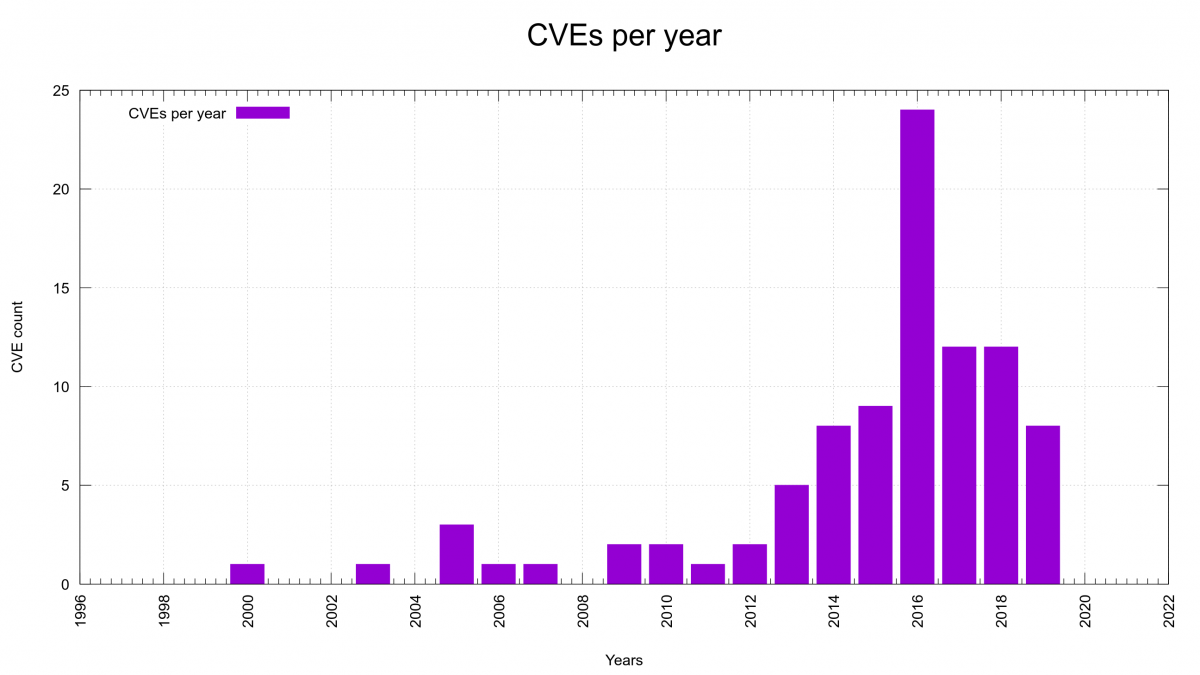
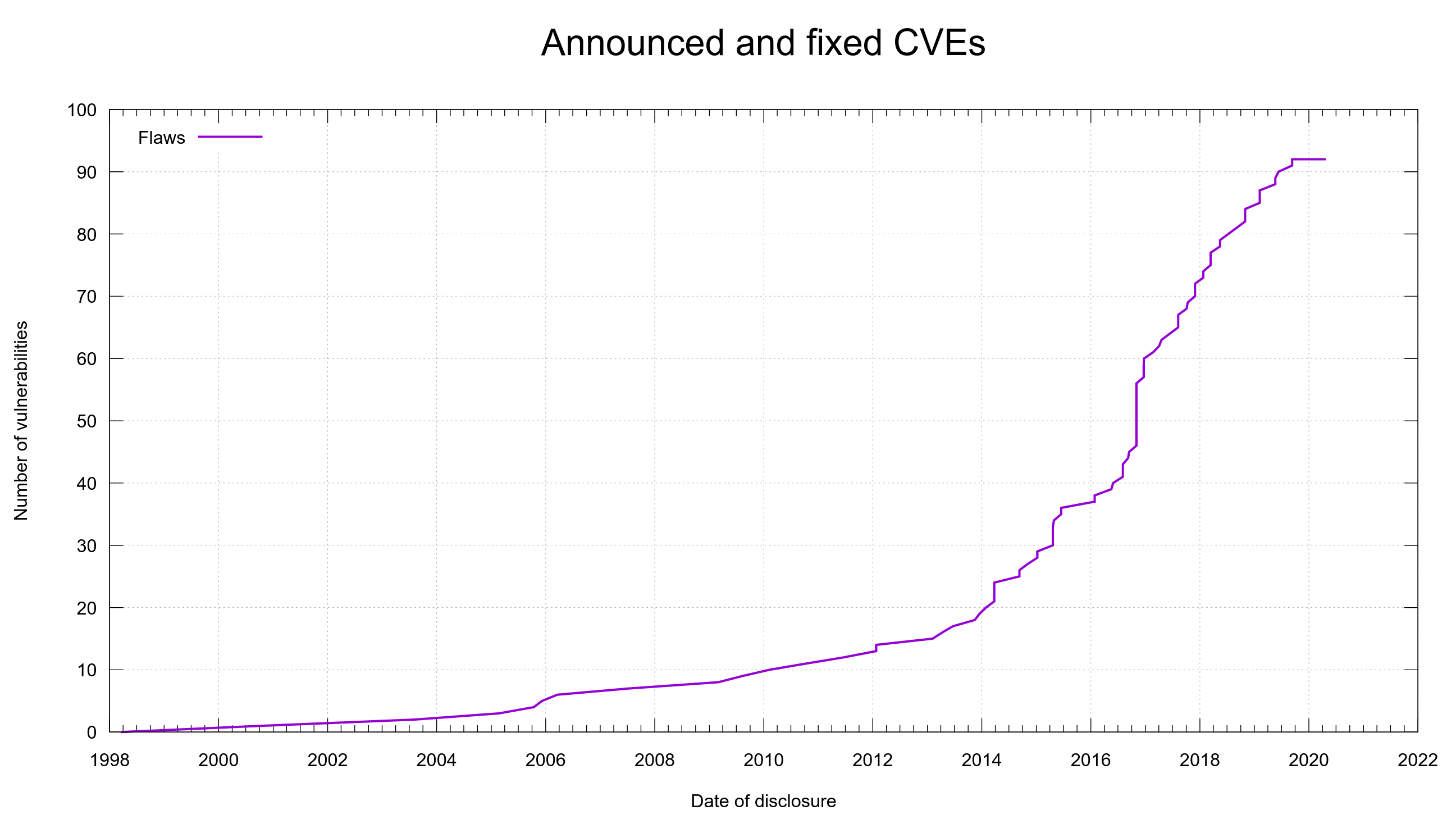
Title: Curl Programming
Author: Dan Gookin
ISBN: 9781704523286
Weight: 181 grams

Not long ago I discovered that someone had written this book about curl and that someone wasn’t me! (I believe this is a first) Thrilled of course that I could check off this achievement from my list of things I never thought would happen in my life, I was also intrigued and so extremely curious that I simply couldn’t resist ordering myself a copy. The book is dated October 2019, edition 1.0.
I don’t know the author of this book. I didn’t help out. I wasn’t aware of it and I bought my own copy through an online bookstore.
First impressions
It’s very thin! The first page with content is numbered 13 and the last page before the final index is page 110 (6-7 mm thick). Also, as the photo shows somewhat: it’s not a big format book either: 225 x 152 mm. I suppose a positive spin on that could be that it probably fits in a large pocket.

I’m not the target audience
As the founder of the curl project and my role as lead developer there, I’m not really a good example of whom the author must’ve imagined when he wrote this book. Of course, my own several decades long efforts in documenting curl in hundreds of man pages and the Everything curl book makes me highly biased. When you read me say anything about this book below, you must remember that.
A primary motivation for getting this book was to learn. Not about curl, but how an experienced tech author like Dan teaches curl and libcurl programming, and try to use some of these lessons for my own writing and manual typing going forward.
What’s in the book?
Despite its size, the book is still packed with information. It contains the following chapters after the introduction:
- The amazing curl … 13
- The libcurl library … 25
- Your basic web page grab … 35
- Advanced web page grab … 49
- curl FTP … 63
- MIME form data … 83
- Fancy curl tricks … 97
As you can see it spends a total of 12 pages initially on explanations about curl the command line tool and some of the things you can do with it and how before it moves on to libcurl.
The book is explanatory in its style and it is sprinkled with source code examples showing how to do the various tasks with libcurl. I don’t think it is a surprise to anyone that the book focuses on HTTP transfers but it also includes sections on how to work with FTP and a little about SMTP. I think it can work well for someone who wants to get an introduction to libcurl and get into adding Internet transfers for their applications (at least if you’re into HTTP). It is not a complete guide to everything you can do, but then I doubt most users need or even want that. This book should get you going good enough to then allow you to search for the rest of the details on your own.
I think maybe the biggest piece missing in this book, and I really thing it is an omission mr Gookin should fix if he ever does a second edition: there’s virtually no mention of HTTPS or TLS at all. On the current Internet and web, a huge portion of all web pages and page loads done by browsers are done with HTTPS and while it is “just” HTTP with TLS on top, the TLS part itself is worth some special attention. Not the least because certificates and how to deal with them in a libcurl world is an area that sometimes seems hard for users to grasp.
A second thing I noticed no mention of, but I think should’ve been there: a description of curl_easy_getinfo(). It is a versatile function that provides information to users about a just performed transfer. Very useful if you ask me, and a tool in the toolbox every libcurl user should know about.
The author mentions that he was using libcurl 7.58.0 so that version or later should be fine to use to use all the code shown. Most of the code of course work in older libcurl versions as well.
Comparison to Everything curl
Everything curl is a free and open document describing everything there is to know about curl, including the project itself and curl internals, so it is a much wider scope and effort. It is however primarily provided as a web and PDF version, although you can still buy a printed edition.
Everything curl spends more space on explanations of features and discussion how to do things and isn’t as focused around source code examples as Curl Programming. Everything curl on paper is also thicker and more expensive to buy – but of course much cheaper if you’re fine with the digital version.
Where to buy?
First: decide if you need to buy it. Maybe the docs on the curl site or in Everything curl is already good enough? Then I also need to emphasize that you will not sponsor or help out the curl project itself by buying this book – it is authored and sold entirely on its own.
But if you need a quick introduction with lots of examples to get your libcurl usage going, by all means go ahead. This could be the book you need. I will not link to any online retailer or anything here. You can get it from basically anyone you like.
Mistakes or errors?
I’ve found some mistakes and ways of phrasing the explanations that I maybe wouldn’t have used, but all in all I think the author seems to have understood these things and describes functionality and features accurately and with a light and easy-going language.
Finally: I would never capitalize curl as Curl or libcurl as Libcurl, not even in a book. Just saying…