I’m happy to announce that curl now supports a third SSH library option: wolfSSH. Using this, you can build curl and libcurl to do SFTP transfers in a really small footprint that’s perfectly suitable for embedded systems and others. This goes excellent together with the tiny-curl effort.
SFTP only
The initial merge of this functionality only provides SFTP ability and not SCP. There’s really no deeper thoughts behind this other than that the work has been staged and the code is smaller for SFTP-only and it might be that users on these smaller devices are happy with SFTP-only.
Work on adding SCP support for the wolfSSH backend can be done at a later time if we feel the need. Let me know if you’re one such user!
Build time selection
You select which SSH backend to use at build time. When you invoke the configure script, you decide if wolfSSH, libssh2 or libssh is the correct choice for you (and you need to have the correct dev version of the desired library installed).
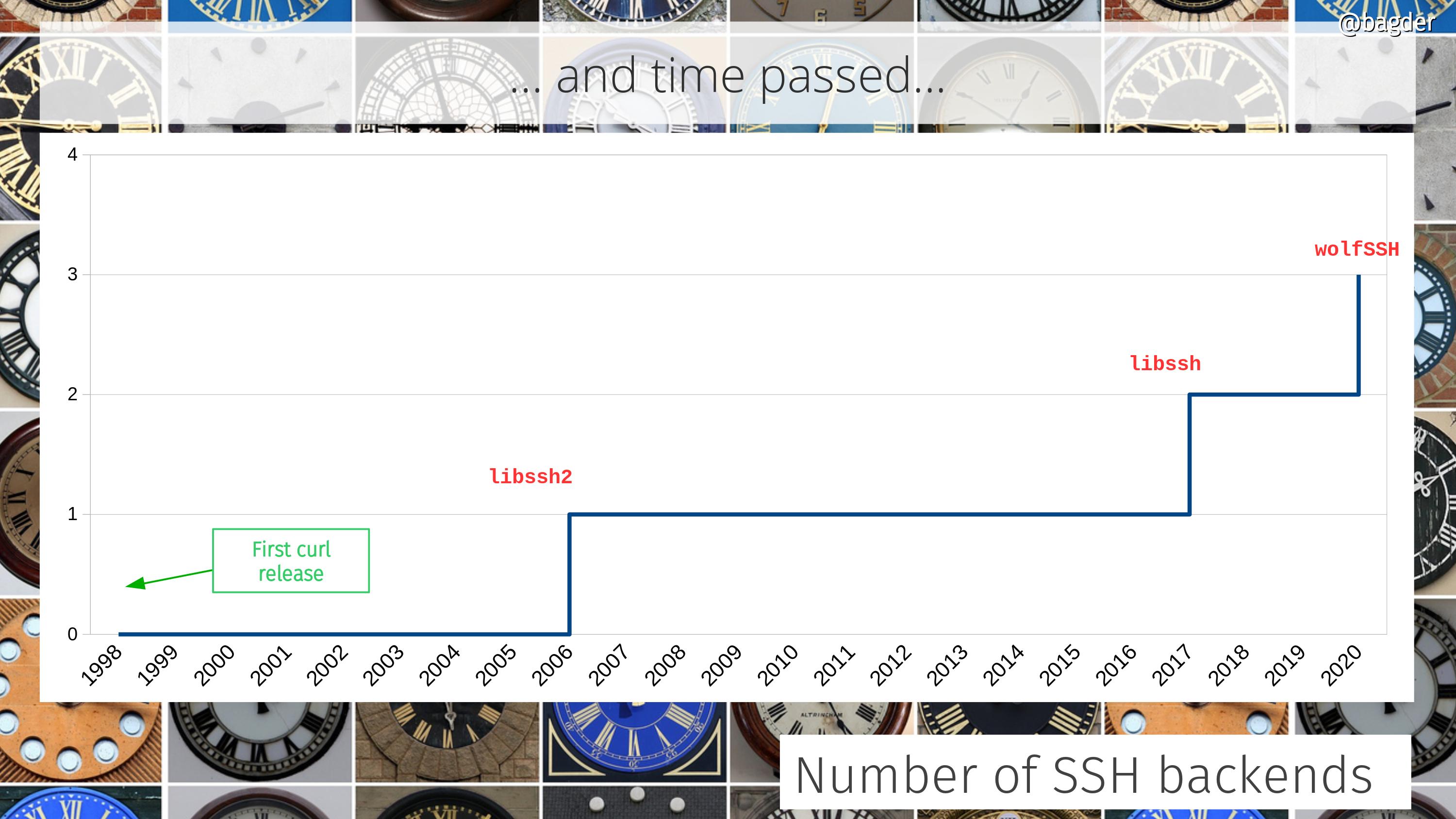
The initial SFTP and SCP support was added to curl in November 2006, powered by libssh2 (the first release to ship it was 7.16.1). Support for getting those protocols handled by libssh instead (which is a separate library, they’re just named very similarly) was merged in October 2017.
Number of supported SSH backends over time in the curl project.
WolfSSH uses WolfSSL functions
If you decide to use the wolfSSH backend for SFTP, it is also possibly a good idea to go with WolfSSL for the TLS backend to power HTTPS and others.
A plethora of third party libs
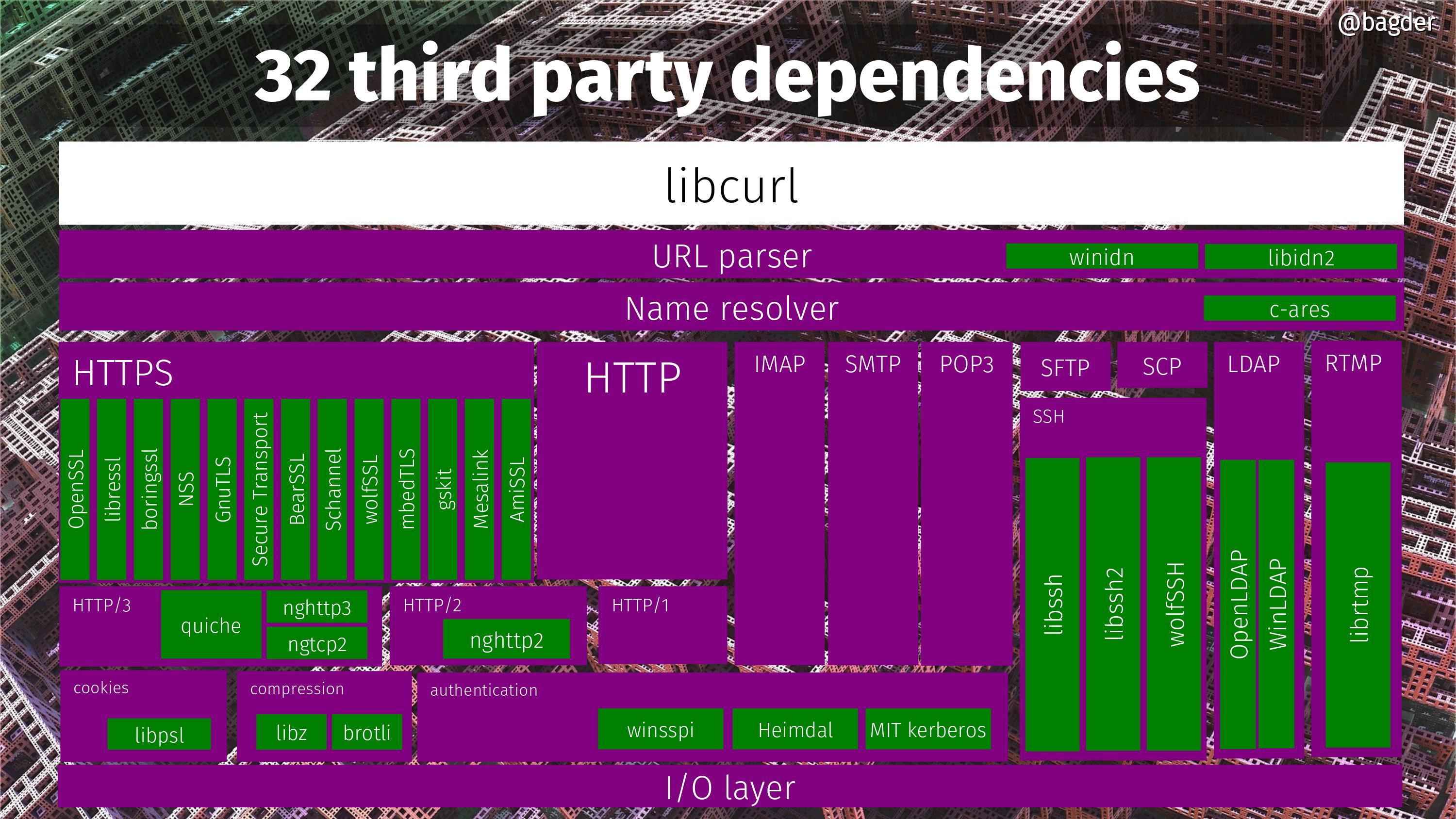
WolfSSH becomes the 32nd third party component that curl can currently be built to use. See the slide below and click on it to get the full resolution version.
32 possible third party dependencies curl can be built to use
Credits
I, Daniel, wrote the initial new wolfSSH backend code. Merged in this commit.
2019 is special in my heart. 2019 was different than many other years to me in several ways. It was a great year! This is what 2019 was to me.
curl and wolfSSL
I quit Mozilla last year and in the beginning of the year I could announce that I joined wolfSSL. For the first time in my life I could actually work with curl on my day job. As the project turned 21 I had spent somewhere in the neighborhood of 15,000 unpaid spare time hours on it and now I could finally do it “for real”. It’s huge.
Just in November 2018 the name HTTP/3 was set and this year has been all about getting it ready. I was proud to land and promote HTTP/3 in curl just before the first browser (Chrome) announced their support. The standard is still in progress and we hope to see it ship not too long into next year.
curl
Focusing on curl full time allows a different kind of focus. I’ve landed more commits in curl during 2019 than any other year going back all the way to 2005. We also reached 25,000 commits and 3,000 forks on github.
We’ve added HTTP/3, alt-svc, parallel transfers in the curl tool, tiny-curl, fixed hundreds of bugs and much, much more. Ten days before the end of the year, I’ve authored 57% (over 700) of all the commits done in curl during 2019.
We also (re)started our own curl Bug Bounty in 2019 together with Hackerone and paid over 1000 USD in rewards through-out the year. It was so successful we’re determined to raise the amounts significantly going into 2020.
Public speaking
I’ve done 28 talks in six countries. A crazy amount in front of a lot of people.
When Github had their Github Universe event in November and talked about their new sponsors program on stage (which I am part of, you can sponsor me) this huge quote of mine was shown on the big screen.
Maybe not media, but in no less than two Mr Robot episodes we could see curl commands in a TV show!
In 2019 I did more public speaking than I’ve ever than before in a single year: 28 public appearances. More than 4,500 persons have seen my presentations live at both huge events (like 1,200 in the audience at FOSDEM 2019) but also some very small and up-close occasions. Many thousands more have also seen video recordings of some of the talks – my most viewed youtube talk of 2019 has been seen over 58,000 times. Do I need to say that it was about HTTP/3, a topic that was my most common one to talk about through-out the year? I suspect the desire to listen and learn more about that protocol version is far from saturated out there…
Cities
Nordic APIs Summit 2019
During the year I’ve done presentations in
Barcelona, Brussels, Copenhagen, Gothenburg, Mainz, Prague, Stockholm and Umeå.
I did many in Stockholm, two in Copenhagen.
Countries
Castor Software Days 2019
During the year I’ve done presentations in
Belgium, Czechia, Denmark, Germany, Spain and Sweden.
Most of my talks were held in Sweden. I did one streamed from my home office!
Topics
JAX 2019
14 of these talks had a title that included “HTTP/3” (example)
9 talks had “curl” in the title (one of them also had HTTP/3 in it) (example)
The Internet Museum translated to Swedish becomes “internetmuseum“. It is a digital, online-only, museum that collects Internet- and Web related historical information, especially focused on the Swedish angle to all of this. It collects stories from people who did the things. The pioneers, the ground breakers, the leaders, the early visionaries. Most of their documentation is done in the form of video interviews.
I was approached and asked to be part of this – as an Internet Pioneer. Me? Internet Pioneer, really?
I’m humbled and honored to be considered and I certainly had a lot of fun doing this interview. To all my friends not (yet) fluent in Swedish: here’s your grand opportunity to practice, because this is done entirely in this language of curl founders and muppet chefs.
Back in the morning of October 18th 2019, two guys showed up as planned at my door and I let them in. One of my guests was a photographer who set up his gear in my living room for the interview, and then me and and guest number two, interviewer Jörgen, sat down and talked for almost an hour straight while being recorded.
The result can be seen here below.
The Science museum was first
This is in fact the second Swedish museum to feature me.
I have already been honored with a display about me, at the Tekniska Museet in Stockholm, the “Science museum” which has an exhibition about past Polhem Prize award winners.
Information displayed about me at the Swedish Science museum in Stockholm. I have a private copy of the cardboard posters.
By late 2019, there’s an estimated amount of ten billion curl installations in the world. Of course this is a rough estimate and depends on how you count etc.
There are several billion mobile phones and tablets and a large share of those have multiple installations of curl. Then there all the Windows 10 machines, web sites, all macs, hundreds of millions of cars, possibly a billion or so games, maybe half a billion TVs, games consoles and more.
How much data are they transferring?
In the high end of volume users, we have at least two that I know of are doing around one million requests/sec on average (and I’m not even sure they are the top users, they just happen to be users I know do high volumes) but in the low end there will certainly be a huge amount of installations that barely ever do any requests at all.
If there are two users that I know are doing one million requests/sec, chances are there are more and there might be a few doing more than a million and certainly many that do less but still many.
Among many of the named and sometimes high profiled apps and users I know use curl, I very rarely know exactly for what purpose they use curl. Also, some use curl to do very many small requests and some will use it to do a few but very large transfers.
Additionally, and this really complicates the ability to do any good estimates, I suppose a number of curl users are doing transfers that aren’t typically considered to be part of “the Internet”. Like when curl is used for doing HTTP requests for every single subway passenger passing ticket gates in the London underground, I don’t think they can be counted as Internet transfers even though they use internet protocols.
How much data are browsers driving?
According to some data, there is today around 4.388 billion “Internet users” (page 39) and the world wide average time spent “on the Internet” is said to be 6 hours 42 minutes (page 50). I think these numbers seem credible and reasonable.
According to broadbandchoices, an average hour of “web browsing” spends about 25MB. According to databox.com, an average visit to a web site is 2-3 minutes. httparchive.org says the median page needs 74 HTTP requests to render.
So what do users do with their 6 hours and 42 minutes “online time” and how much of it is spent in a browser? I’ve tried to find statistics for this but failed.
@chuttenc (of Mozilla) stepped up and helped me out with getting stats from Firefox users. Based on stats from users that used Firefox on the day of October 1, 2019 and actually used their browser that day, they did 2847 requests per client as median with the median download amount 18808 kilobytes. Of that single day of use.
I don’t have any particular reason to think that other browsers, other days or users of other browsers are very different than Firefox users of that single day. Let’s count with 3,000 requests and 20MB per day. Interestingly, that makes the average data size per request a mere 6.7 kilobytes.
A median desktop web page total size is 1939KB right now according to httparchive.org (and the mobile ones are just slightly smaller so the difference isn’t too important here).
Based on the median weight per site from httparchive, this would imply that a median browser user visits the equivalent of 15 typical sites per day (30MB/1.939MB).
If each user spends 3 minutes per site, that’s still just 45 minutes of browsing per day. Out of the 6 hours 42 minutes. 11% of Internet time is browser time.
3000 requests x 4388000000 internet users, makes 13,164,000,000,000 requests per day. That’s 13.1 trillion HTTP requests per day.
The world’s web users make about 152.4 million HTTP requests per second.
(I think this is counting too high because I find it unlikely that all internet users on the globe use their browsers this much every day.)
The equivalent math to figure out today’s daily data amounts transferred by browsers makes it 4388000000 x 30MB = 131,640,000,000 megabytes/day. 1,523,611 megabytes per second. 1.5 TB/sec.
30MB/day equals a little under one GB/month per person. Feels about right.
Back to curl usage
The curl users with the highest request frequencies known to me (*) are racing away at one million requests/second on average, but how many requests do the others actually do? It’s really impossible to say. Let’s play the guessing game!
First, it feels reasonable to assume that these two users that I know of are not alone in doing high frequency transfers with curl. Purely based on probability, it seems reasonable to assume that the top-20 something users together will issue at least 10 million requests/second.
Looking at the users that aren’t in that very top. Is it reasonable to assume that each such installed curl instance makes a request every 10 minutes on average? Maybe it’s one per every 100 minutes? Or is it 10 per minute? There are some extremely high volume and high frequency users but there’s definitely a very long tail of installations basically never doing anything… The grim truth is that we simply cannot know and there’s no way to even get a ballpark figure. We need to guess.
Let’s toy with the idea that every single curl instance on average makes a transfer, a request, every tenth minute. That makes 10 x 10^9 / 600 = 16.7 million transfers per second in addition to the top users’ ten million. Let’s say 26 million requests per second. The browsers of the world do 152 million per second.
If each of those curl requests transfer 50Kb of data (arbitrarily picked out of thin air because again we can’t reasonably find or calculate this number), they make up (26,000,000 x 50 ) 1.3 TB/sec. That’s 85% of the data volume all the browsers in the world transfer.
The world wide browser market share distribution according to statcounter.com is currently: Chrome at 64%, Safari at 16.3% and Firefox at 4.5%.
This simple-minded estimate would imply that maybe, perhaps, possibly, curl transfers more data an average day than any single individual browser flavor does. Combined, the browsers transfer more.
Guesses, really?
Sure, or call them estimates. I’m doing them to the best of my ability. If you have data, reasoning or evidence to back up modifications my numbers or calculations that you can provide, nobody would be happier than me! I will of course update this post if that happens!
(*) = I don’t name these users since I’ve been given glimpses of their usage statistics informally and I’ve been asked to not make their numbers public. I hold my promise by not revealing who they are.
Thanks
Thanks to chuttenc for the Firefox numbers, as mentioned above, and thanks also to Jan Wildeboer for helping me dig up stats links used in this post.
$ cd $HOME/src
$ unzip wolfssl-4.1.0-gplv3-fips-ready.zip
$ cd wolfssl-4.1.0-gplv3-fips-ready
Build the fips-ready wolfSSL and install it somewhere suitable
$ ./configure --prefix=$HOME/wolfssl-fips --enable-harden --enable-all
$ make -sj
$ make install
Download curl, the normal curl package. (in my case I got curl 7.65.3)
Unzip the source code somewhere suitable
$ cd $HOME/src
$ unzip curl-7.65.3.zip
$ cd curl-7.65.3
Build curl with the just recently built and installed fips ready wolfSSL version.
$ LD_LIBRARY_PATH=$HOME/wolfssl-fips/lib ./configure --with-wolfssl=$HOME/wolfssl-fips --without-ssl
$ make -sj
Now, verify that your new build matches your expectations by:
$ ./src/curl -V
It should show that it uses wolfSSL and that all the protocols and features you want are enabled and present. If not, iterate until it does!
“FIPS Ready means that you have included the FIPS code into your build and that you are operating according to the FIPS enforced best practices of default entry point, and Power On Self Test (POST).”
In the afternoon of August 5 2019, I successfully made curl request a document over HTTP/3, retrieve it and then exit cleanly again.
(It got a 404 response code, two HTTP headers and 10 bytes of content so the actual response was certainly less thrilling to me than the fact that it actually delivered that response over HTTP version 3 over QUIC.)
The components necessary for this to work, if you want to play along at home, are reasonably up-to-date git clones of curl itself and the HTTP/3 library called quiche (and of course quiche’s dependencies too, like boringssl), then apply pull-request 4193 (build everything accordingly) and run a command line like:
curl --http3-direct https://quic.tech:8443
The host name used here (“quic.tech”) is a server run by friends at Cloudflare and it is there for testing and interop purposes and at the time of this test it ran QUIC draft-22 and HTTP/3.
The command line option --http3-direct tells curl to attempt HTTP/3 immediately, which includes using QUIC instead of TCP to the host name and port number – by default you should of course expect a HTTPS:// URL to use TCP + TLS.
The official way to bootstrap into HTTP/3 from HTTP/1 or HTTP/2 is via the server announcing it’s ability to speak HTTP/3 by returning an Alt-Svc: header saying so. curl supports this method as well, it just needs it to be explicitly enabled at build-time since that also is still an experimental feature.
To use alt-svc instead, you do it like this:
curl --alt-svc altcache https://quic.tech:8443
The alt-svc method won’t “take” on the first shot though since it needs to first connect over HTTP/2 (or HTTP/1) to get the alt-svc header and store that information in the “altcache” file, but if you then invoke it again and use the same alt-svc cache curl will know to use HTTP/3 then!
Early days
Be aware that I just made this tiny GET request work. The code is not cleaned up, there are gaps in functionality, we’re missing error checks, we don’t have tests and chances are the internals will change quite a lot going forward as we polish this.
You’re of course still more than welcome to join in, play with it, report bugs or submit pull requests! If you help out, we can make curl’s HTTP/3 support better and getting there sooner than otherwise.
QUIC and TLS backends
curl currently supports two different QUIC/HTTP3 backends, ngtcp2 and quiche. Only the latter currently works this good though. I hope we can get up to speed with the ngtcp2 one too soon.
quiche uses and requires boringssl to be used while ngtcp2 is TLS library independent and will allow us to support QUIC and HTTP/3 with more TLS libraries going forward. Unfortunately it also makes it more complicated to use…
The official OpenSSL doesn’t offer APIs for QUIC. QUIC uses TLS 1.3 but in a way it was never used before when done over TCP so basically all TLS libraries have had to add APIs and do some adjustments to work for QUIC. The ngtcp2 team offers a patched version of OpenSSL that offers such an API so that OpenSSL be used.
Draft what?
Neither the QUIC nor the HTTP/3 protocols are entirely done and ready yet. We’re using the protocols as they are defined in the 22nd version of the protocol documents. They will probably change a little more before they get carved in stone and become the final RFC that they are on their way to.
The libcurl API so far
The command line options mentioned above of course have their corresponding options for libcurl using apps as well.
The first curl release ever saw the light of day on March 20, 1998 and already then, curl could transfer any amount of URLs given on the command line. It would iterate over the entire list and transfer them one by one.
Not even 22 years later, we introduce the ability for the curl command line tool to do parallel transfers! Instead of doing all the provided URLs one by one and only start the next one once the previous has been completed, curl can now be told to do all of them, or at least many of them, at the same time!
This has the potential to drastically decrease the amount of time it takes to complete an operation that involves multiple URLs.
–parallel / -Z
Doing transfers concurrently instead of serially of course changes behavior and thus this is not something that will be done by default. You as the user need to explicitly ask for this to be done, and you do this with the new –parallel option, which also as a short-hand in a single-letter version: -Z (that’s the upper case letter Z).
Limited parallelism
To avoid totally overloading the servers when many URLs are provided or just that curl runs out of sockets it can keep open at the same time, it limits the parallelism. By default curl will only try up to 50 transfers concurrently, so if there are more transfers given to curl those will wait to get started once one of the first transfers are completed. The new –parallel-max command line option can be used to change the concurrency limit.
Progress meter
Is different in this mode. The new progress meter that will show up for parallel transfers is one output for all transfers.
Transfer results
When doing many simultaneous transfers, how do you figure out how they all did individually, like from your script? That’s still to be figured out and implemented.
No same file splitting
This functionality makes curl do URLs in parallel. It will still not download the same URL using multiple parallel transfers the way some other tools do. That might be something to implement and offer in a future fine tuning of this feature.
libcurl already do this fine
This is a new command line feature that uses the fact that libcurl can already do this just fine. Thanks to libcurl being a powerful transfer library that curl uses, enabling this feature was “only” a matter of making sure libcurl was used in a different way than before. This parallel change is entirely in the command line tool code.
Ship
This change has landed in curl’s git repository already (since b8894085000) and is scheduled to ship in curl 7.66.0 on September 11, 2019.
I hope and expect us to keep improving parallel transfers further and we welcome all the help we can get!
We announced our glorious return to the “bug bounty club” (projects that run bug bounties) a month ago, and with the curl 7.65.0 release today on May 22nd of 2019 we also ship fixes to security vulnerabilities that were reported within this bug bounty program.
Announcement
Even before we publicly announced the program, it was made public on the Hackerone site. That was obviously enough to get noticed by people and we got the first reports immediately!
We have received 19 reports so far.
Infrastructure scans
Quite clearly some people have some scripts laying around and they do some pretty standard things on projects that pop up on hackerone. We immediately got a number of reports that reported variations of the same two things repeatedly:
Our wiki is world editable. In my world I’ve lived under the assumption that this is how a wiki is meant to be but we ended up having to specifically mention this on curl’s hackerone page: yes it is open for everyone on purpose.
Sending emails forging them to look like the come from the curl web site might work since our DNS doesn’t have SPF, DKIM etc setup. This is a somewhat better report, but our bounty program is dedicated for and focused on the actual curl and libcurl products. Not our infrastructure.
Bounties!
Within two days of the program’s life time, the first legit report had been filed and then within a few more days a second arrived. They are CVE-2019-5435 and CVE-2019-5436, explained somewhat in my curl 7.65.0 release post but best described in their individual advisories, linked to below.
I’m thrilled to report that these two reporters were awarded money for their findings:
Wenchao Li was awarded 150 USD for finding and reporting CVE-2019-5435.
l00p3r was awarded 200 USD for finding and reporting CVE-2019-5436.
Both these issues were rated severity level “Low” and we consider them rather obscure and not likely to hurt very many users.
Donate to help us fund this!
Please notice that we are entirely depending on donated funds to be able to run this program. If you use curl and benefit from a more secure curl, please consider donating a little something for the cause!
There seems to be no end to updated posts about bug bounties in the curl project these days. Not long ago I mentioned the then new program that sadly enough was cancelled only a few months after its birth.
Now we are back with a new and refreshed bug bounty program! The curl bug bounty program reborn.
This new program, which hopefully will manage to survive a while, is setup in cooperation with the major bug bounty player out there: hackerone.
Basic rules
If you find or suspect a security related issue in curl or libcurl, report it! (and don’t speak about it in public at all until an agreed future date.)
You’re entitled to ask for a bounty for all and every valid and confirmed security problem that wasn’t already reported and that exists in the latest public release.
The curl security team will then assess the report and the problem and will then reward money depending on bug severity and other details.
Where does the money come from?
We intend to use funds and money from wherever we can. The Hackerone Internet Bug Bounty program helps us, donations collected over at opencollective will be used as well as dedicated company sponsorships.
We will of course also greatly appreciate any direct sponsorships from companies for this program. You can help curl getting even better by adding funds to the bounty program and help us reward hard-working researchers.
Why bounties at all?
We compete for the security researchers’ time and attention with other projects, both open and proprietary. The projects that can help put food on these researchers’ tables might have a better chance of getting them to use their tools, time, skills and fingers to find our problems instead of someone else’s.
Finding and disclosing security problems can be very time and resource consuming. We want to make it less likely that people give up their attempts before they find anything. We can help full and part time security engineers sustain their livelihood by paying for the fruits of their labor. At least a little bit.
Only released code?
The state of the code repository in git is not subject for bounties. We need to allow developers to do mistakes and to experiment a little in the git repository, while we expect and want every actual public release to be free from security vulnerabilities.
So yes, the obvious downside with this is that someone could spot an issue in git and decide not to report it since it doesn’t give any money and hope that the flaw will linger around and ship in the release – and then reported it and claim reward money. I think we just have to trust that this will not be a standard practice and if we in fact notice that someone tries to exploit the bounty in this manner, we can consider counter-measures then.
How about money for the patches?
There’s of course always a discussion as to why we should pay anyone for bugs and then why just pay for reported security problems and not for heroes who authored the code in the first place and neither for the good people who write the patches to fix the reported issues. Those are valid questions and we would of course rather pay every contributor a lot of money, but we don’t have the funds for that. And getting funding for this kind of dedicated bug bounties seem to be doable, where as a generic pay contributors fund is trickier both to attract money but it is also really hard to distribute in an open project of curl’s nature.
How much money?
At the start of this program the award amounts are as following. We reward up to this amount of money for vulnerabilities of the following security levels: