This is a recorded online presentation about curl that I did today, March 24 2022. How it started, grew, where it is today, how we make it and where it perhaps might go in the future.
The slides are available.

This is a recorded online presentation about curl that I did today, March 24 2022. How it started, grew, where it is today, how we make it and where it perhaps might go in the future.
The slides are available.
Okay you might ask, what’s the news here? We’ve been able to get HTTP response headers with curl since virtually the stone age. Yes we have. Get the page and also show the headers:
curl -i https://example.com/
Make a HEAD request and see what headers we get back:
curl -I https://example.com/
Save the response headers in a separate file:
curl -D headers.txt https://example.com/
This gets a little more complicated but you can always do
curl -I https://example.com/ | grep Date:
Which of course will fail if the casing is different, you need to check for it case insensitively. There might also be another header ending with “date:” that matches so you need to make sure that this an exact match
curl -I https://example.com/ | grep -i ^Date:
Now this shows the entire header, but for most cases you only want the value. So get it with cut:
curl -I https://example.com/ | grep -i ^Date: | cut -d: -f2-
You have the header value extracted now, but the leading and trailing white spaces in the content are probably not what you want in there so let’s strip them as well:
curl -I https://example.com/ | grep -i ^Date: | cut -d: -f2- | sed 's/^ *\(.*\).*/\1/'
There are of course many different ways you can do this operation and some of them are more clever than the methods I’ve used here. They are still often more or less convoluted and error-prone.
If we imagine that this is a fairly common use case for curl users in the world, then this kind of operation is found duplicated in quite a few scripts, applications and devices in the world.
Maybe we could make this easier for curl users?
The other day we introduced a new experimental headers API to libcurl. Using this API, an application using libcurl gets an easy to use API to extract individual or several headers and their content.
As curl is such a libcurl-using application, we have expanded it to make use of this new API and this brings some new fun features to the curl tool.
Let me emphasize that since this API is labeled experimental it is not enabled in a default build. You need to explicitly enable it!
I decided to extend the -w output feature for this.
To extract a single header, get the value with leading and trailing spaces trimmed, use %header{name}. To repeat the operation from above and get the Date: header
curl -I -w '%header{date}' https://example.com/
‘date’ in this example is a case insensitive header name without the trailing colon and you can of course use any header name you please there. If the given header did not actually arrive in the response, it outputs nothing.
If you want more headers output, just repeat the %header{name} construct as many times as you like. If the -w output string gets unwieldy and hard to manage on the command line, then make it into a text file instead and tell -w about it with -w @filename.
curl -I -w @filename https://example.com/
There are several different kinds of headers and there can be multiple requests used for a transfer, but this option outputs the “normal” server response headers from the most recent request done. The option only works for HTTP(S) responses.
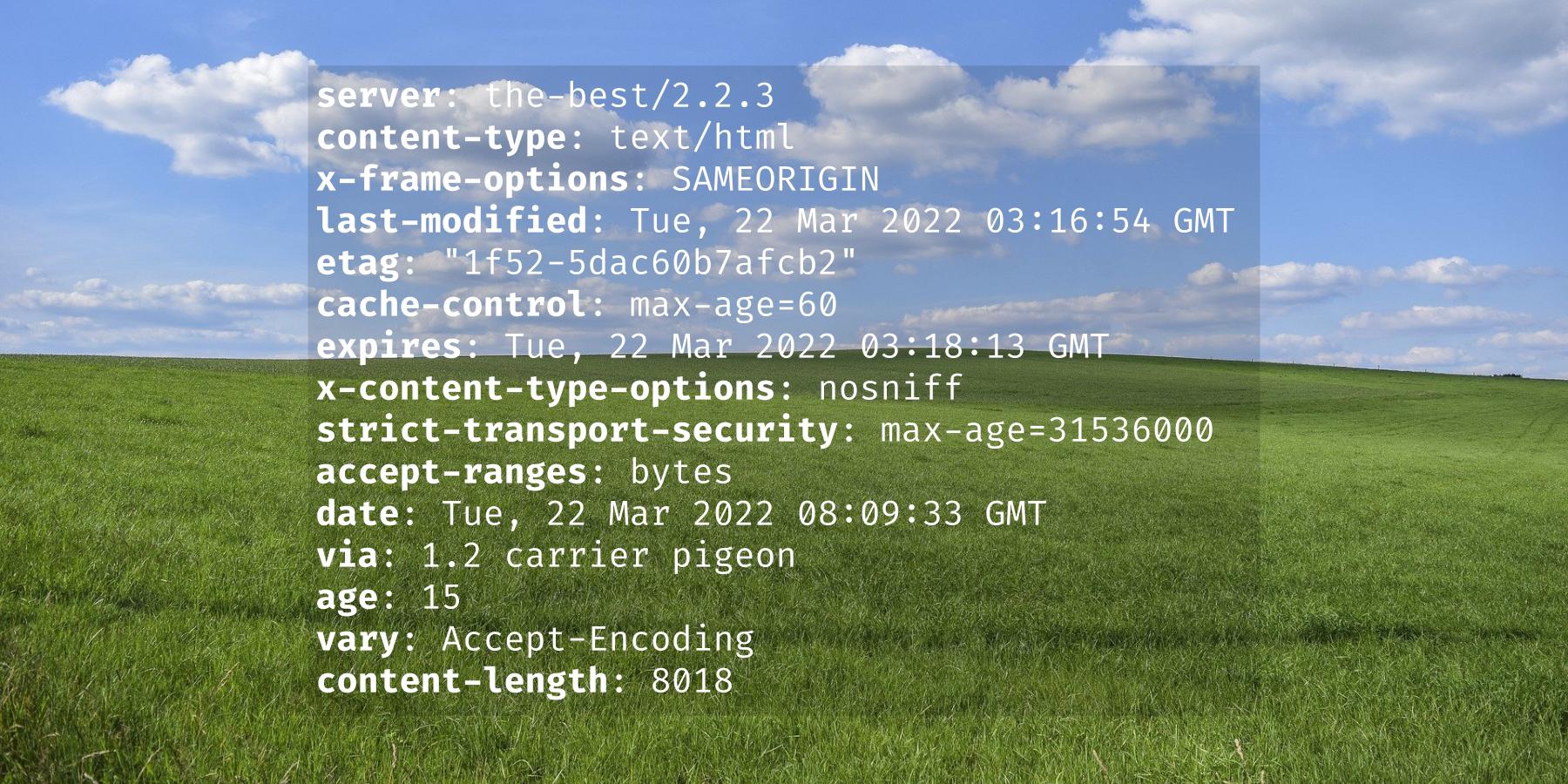
As dealing with formatted data in the form of JSON has become very popular, I want to help fertilize this by making curl able to output all response headers as a JSON object.
This way, you can move the header handling, parsing and perhaps filtering to your JSON aware tool.
Tell curl to output the received HTTP headers as a JSON object:
curl -o save -w "%{header_json}" https://example.com/
curl itself does not pretty-print this, but if you pass the JSON from curl to a beautifier such as jq, the output ends up looking like this:
{
"age": [
"269578"
],
"cache-control": [
"max-age=604800"
],
"content-type": [
"text/html; charset=UTF-8"
],
"date": [
"Tue, 22 Mar 2022 08:35:21 GMT"
],
"etag": [
"\"3147526947+ident\""
],
"expires": [
"Tue, 29 Mar 2022 08:35:21 GMT"
],
"last-modified": [
"Thu, 17 Oct 2019 07:18:26 GMT"
],
"server": [
"ECS (nyb/1D2E)"
],
"vary": [
"Accept-Encoding"
],
"x-cache": [
"HIT"
],
"content-length": [
"1256"
]
}
The headers are presented in the same order as received over the wire. Except if there are duplicated header names, as then they are grouped on the first occurrence and all values are provided there as a JSON array.
All headers are arrays just because there can be multiple headers using the same name .
The casing for the header names are kept unmodified from what was received, but for duplicated headers the casing used for the first occurrence will be used in the output.
Update: we lowercase all header names in the JSON output.
The “status line” of HTTP 1.x response, that first line that says “HTTP1.1 200 OK” when everything is fine, is not counted as a header by this function and will therefor not be included in this output.
This feature is present in source code that will ship in curl 7.83.0, scheduled to happen late April 2022. Run your own build with it enabled, or ask your packager to provide an experimental build for you.
With enough positive feedback we should be able to move this out of experimental state fairly quickly.
“The Lord giveth and the Lord taketh away.”
Job 1:21
On March 16 2022, the curl security team received an email in which the reporter highlighted an Apple web page. What can you tell us about this?
I hadn’t seen it before. On this page with the title “About the security content of macOS Monterey 12.3”, said to have been published just two days prior, Apple mentions recent package upgrades and the page lists a bunch of products and what security fixes that were done for them in this update. Among the many products listed, curl is mentioned.
This is what the curl section of the page looked like:

In the curl project we always make all CVEs public with as much detail as we can possibly extract and provide about them. We take great pride in being the best in class in security flaw information and transparency.
Apple listed four CVE fixed. The three first IDs we immediately recognized from the curl security page. The last one however, was a surprise. What was that?
This is not a CVE published by the curl project. The curl project has in fact not shipped any CVE at all in 2022 (yet) so that’s easy to spot. When we looked at the MITRE registration for the ID, it also didn’t disclose any clues really. Not that it was expected to. It did show it was created on January 5 though, so it wasn’t completely new.
Was it a typo?
I compared this number to other recent CVE numbers announced from curl and I laid eyes on CVE-2021-22923 which had just two digits changed. Did they perhaps mean that CVE?
The only “problem” with that CVE is that it was in regards to Metalink and I don’t think Apple ever shipped their curl package with metalink support so therefore they wouldn’t have fixed a Metalink problem. So probably not a typo for that number at least!
I reached out to a friend at Apple as well with an email to Apple Product Security.
In the curl project, we take security seriously. The news that there might be a security problem in curl that we haven’t been told about and that looks like it was about to get public sooner or later was of course somewhat alarming and something we just needed to get to the bottom of. It was also slightly disappointing that a large vendor and packager of curl since over 20 years would go about it this way and jab this into our back.
Apple has not made the source code for their macOS 12.3 version and the packages they use in there public, so there was no way for us to run diffs or anything to check for the exact modifications that this claimed fix would’ve resulted in.
Several “security websites” (the quotes are there to indicate that clearly these sites are more security in the name than in reality) immediately posted details about this “vulnerability”. Some of them with CVSS scores and CWE numbers , explaining how this problem can hurt users. Obviously completely made up since none of that info was made available by any first party sources anywhere. Not from Apple and not from the curl project. If you now did a web search on that CVE number, several of the top search results linked to such sites providing details – obviously made up from thin air.
As I think these sites don’t add much value to humanity, I won’t link to them here but instead I will show you a screenshot from such an article to show you what a made up CVE number posted by Apple can make people claim:

At 23:28 (my time zone) on the 17th, my Apple friend responded saying they had forwarded the issue to “the right team”.
The Apple Product Security team I also emailed about this issue, answered at 00:23 (still my time) on the 18th saying “we are looking into this and will provide an update soon when we have more information.”

After the weekend passed with no response, I looked back again on the MITRE page for the CVE in question and it had then gotten populated with additional curl details; mentioning Apple as CNA and now featuring links back to the Apple page! Now it really started to look like the CVE was something real that Apple (or someone) had registered but not told us about. It included real curl related snippets like this:
Multiple issues were addressed by updating to curl version 7.79.1. This issue is fixed in macOS Monterey 12.3. Multiple issues in curl.
On Monday the 21st, I continued to get questions about this CVE. Among others, from a member of a major European ISP’s CERT team curious about this CVE as they couldn’t find any specific information about this issue either and they were concerned they might have this vulnerability in the curl versions they run. They of course (rightfully) assumed that I would know about curl CVEs.
It turns out that when a major company randomly mentions a new CVE, it actually has an impact on the world!
At around 20:30 on March 21st, someone on Twitter spotted that the ghost CVE had been removed from Apple’s web page and it only listed three issues (and a mention that the section had been updated). At 21:39 I get an email response from Apple Product Security:
Thank you for reaching out to us about the error with this CVE on our security advisory. We’ve updated our site and requested that MITRE reject CVE-2022-22623 on their end.
Please let us know if you have any questions.

The reject request to MITRE is expected to be slow so that page will remains showing the outdated data for a while longer.
When Apple had retracted the wrong CVE, I figured I should maybe try to get exploitone.com to remove their “article” to maybe at least stop one avenue of further misinformation about this curl “issue”. I tweeted (in perhaps a tad bit inflammatory manner):
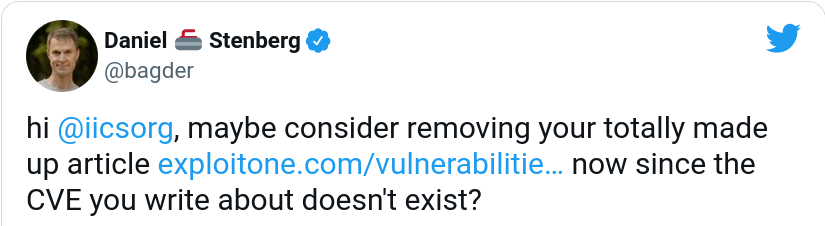
I get the feeling they didn’t quite understand my point. They replied:
As I had questions about Apple’s mishap, I replied (sent off 22:28 on the 21st, still only early afternoon on the US west coast), asking for details on what exactly had happened here. If it was a typo, then how come it got registered with MITRE? It’s just so puzzling and mysterious!
When I’m posting this article on my blog (36 hours after I sent the question), I still haven’t gotten any response or explanation. I don’t expect to get any either, but if I do, I will update this post accordingly.
exploitone.com updated their page at some point after my tweet to remove the mention of the imaginary CVE, but the wording remains very odd:

For many years we’ve had this outstanding idea to add a new API to libcurl that would offer applications easy access to HTTP response headers.
Applications could already retrieve the headers using existing methods but that requires them to write a callback and to a certain amount of parsing and “understanding” HTTP that we always felt was a little unfortunate, a bit error-prone on the behalf of the applications and perhaps also a thing that forced a lot of applications out there having to write the same kind of extra function logic.
If libcurl provides this functionality, it would remove a lot of (duplicated) code from a lot of applications.
We started this process a while ago when I first wrote down a basic approach to an API for this and sent it off to the curl-library mailing list for feedback and critique.
/* first take */
char *curl_easy_header(CURL *easy,
const char *name);
The conversation that followed that first plea for help, made me realize that my first proposal had been far too basic and it wouldn’t at all work to satisfy the needs and use cases we could think of for this API.
I went back to mull over what I’ve learned and update my design proposal, trying to take the feedback into account in the best possible way. A few weeks later, I returned with a “proposal v2” and again I asked for comments and opinions on what I had put together.
/* second shot */
CURLHcode curl_easy_header(CURL *easy,
const char *name,
size_t index,
struct curl_header **h);
As I had already adjusted the API from feedback the first time around, the feedback this time was perhaps not calling for as big changes or radical differences as they did the first time around. I could adapt my proposal to what people asked and suggested. We arrived at something that seemed like a pretty solid API for offering HTTP headers to applications.
As the API proposal feedback settled down and the interface felt good and sensible, I decided it was time for me to write up a first implementation so that we can offer code to people to give everyone a chance to try out the API in real life as well. There’s one thing to give feedback on a “paper product”, actually being able to use it and try it in an application is way better. I dove in.
When the code worked to the level that I started to be able to extract the first headers with the API, it proved to that we needed to adjust the API a little more, so I did. I then ran into more questions and thoughts about specifics that we hadn’t yet dealt with or nailed proper in the discussions up to that point and I took some questions back to the curl community. This became an iterative process and we smoothed out questions about how access different header “sources” as well as how to deal with multiple headers and “request sequences”. All supported now.
/* final version */
CURLHcode curl_easy_header(CURL *easy,
const char *name,
size_t index,
unsigned int origin,
int request,
struct curl_header **h);This API allows applications to extract all headers from a previous transfer. It can get one or many headers when there are duplicated ones, like Set-Cookie: commonly arrive as.
The application can ask for “normal” headers, for trailers (that arrive after the body), headers associated with the CONNECT request (if such a one was performed), pseudo headers (that might arrive when HTTP/2 and HTTP/3 is used) or headers associated with a HTTP 1xx “intermediate” response.
The libcurl APIs typically work on transfers, which means that a single transfer may end up doing multiple transfers, multiple HTTP requests. Primarily when redirects are followed but it can also be due to other reasons. This header API therefore allows the caller to extract headers from the entire “chain” of requests a previous transfer was made with.
This API is initially merged (in this commit) labeled “experimental” to be included in the upcoming 7.83.0 release. The experimental label means a few different things to us:
--enable-headers-api when you run configureWe use the experimental “route” to lower the bar for merging new stuff, so that we get some extra chances to fix up mistakes before the rules and API are carved in stone and we are set to support that for a life time.
This setup relies on users actually trying out the experimental stuff as otherwise it isn’t method for improving the API, it will only delay the introduction of it to the general public. And it risks becoming be less good.
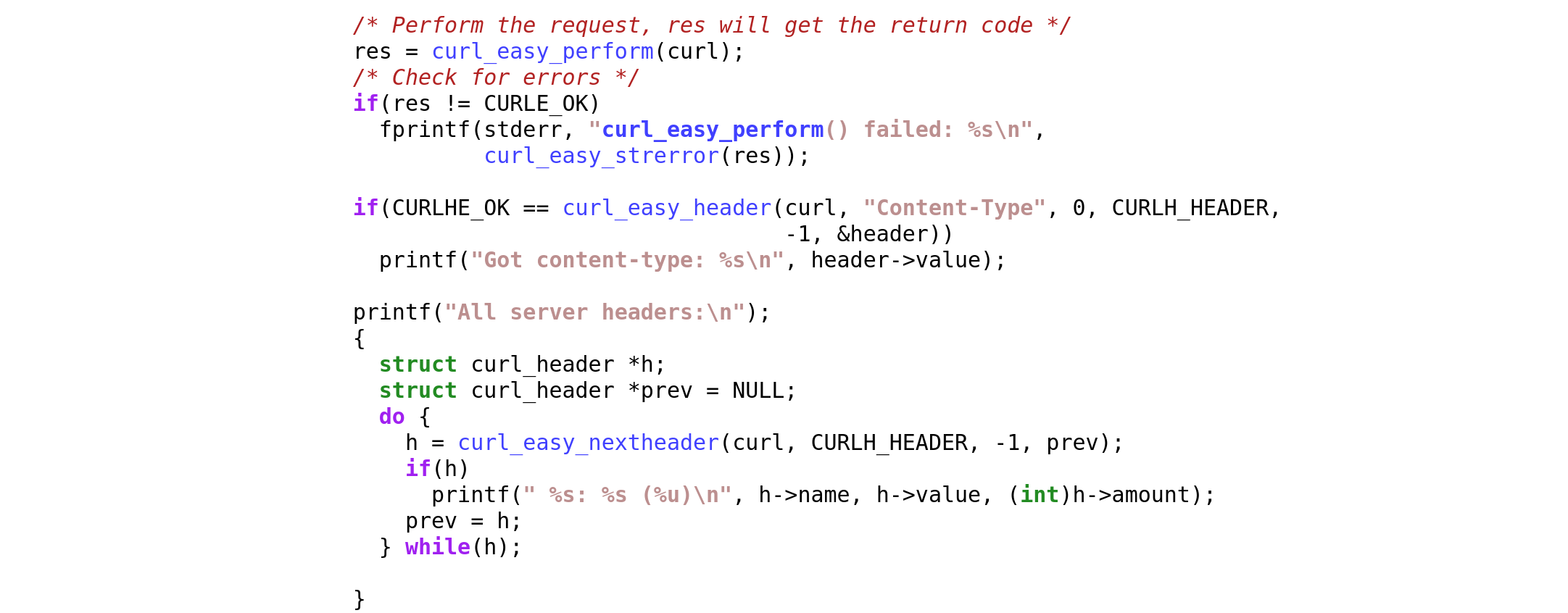
The two new functions have detailed man pages: curl_easy_header and curl_easy_nextheader. If there is anything missing on unclear in there, let us know!
I have also created an initial example source snippet showing header API use. See headerapi.c.
This API deserves its own little section in the everything curl book, but I think I will wait for it to get landed “for real” before I work on adding that.
It was a while since I last spoke Swedish on a podcast. I joined the friendly hosts Sebastian and Alex of the Trevlig Mjukvara (translates to something like “Nice Software”) podcast and we talked software development, open source, curl, Mozilla and a few other topics for an hour. I had a great time. (We had Jitsi act up on us more than once so we had to switch away from it mid-recording!)
Listen to Trevlig Mjukvara s10e04. In Swedish!
I’ve also participated in a lot of other podcasts over the years.
On March 20, 2022 curl turns 24 years old.
Hooray.
(This blog post has been updated a few times after the initial publication.)
In the Fedora project there is/was a proposal to introduce a curl-minimal package (and its companion libcurl-minimal) by default, as a way to provide default packages with smaller security risk areas. The full curl version packages would then be offered next to the minimal ones and require users to opt-in. (Related article on lwn.net)
The proposal is for making curl-minimal the default for “non-containerized installations of Fedora”. The curl-minimal packages already exists since 2017. Kamil Dudka had a talk about it at curl-up 2018.
curl-minimal would disable lesser used protocols and features. The discussion around exactly which parts it should disable is ongoing. The proposal to make it default was at least initially shut down by the Fedora Steering Committee on March 8, 2022 but I get the sense the curl-minimal idea have not died yet.
The balance is really tricky but yet seems to be the key to if this is going to be a worthwhile effort or not.
Disabling too many things in the name of security will make many more users install the full package, and then there is no security gain.
Enabling too many things in the minimal version makes it less of a security gain to begin with.
The harsh truth about past security problems in curl and libcurl, is that most of them were found in components and parts that this minimal package would include.
The question is really how much a minimal package will actually save users from risk and not just cause endless amounts of friction going forward.
Not to mention that since Fedora aims to provide the full package as well, they will not avoid the risk of security problems even in the parts that are disabled in the minimal version. They can only reduce the impact of such flaws.
It is really hard for packagers to know what curl features that are used and not used. There simply is no way to find out, besides shipping a version and listening to the screams of users in pain when things break. It will also force them into line-drawing decisions such as “only N users seem to use feature Z so let’s keep that in the full package” and figuring out the N number is a fuzzy estimate at best.
Some curl features are generally assumed to be there by tools and environments. An example is how a lot of tools and services, like for example web browsers, these days offer copy-as-curl functions. They put a generated curl command line in the clipboard so that users can paste that command in a shell prompt to reproduce an operation with curl.
If those generated command lines stop working because the newly installed curl package doesn’t have feature Z enabled while the generated curl command lines uses it, that’s going to make users unhappy.
The worst part for us in the curl project is probably that this is ultimately going to lead to an increased number of bug reports to the curl project because people will not understand why or how things go wrong.
Neither the curl project nor me personally have been asked or prompted for our views or feedback on this. It seems the Fedora people have not even considered the little and uncertain numbers on curl usage that exist – namely the results from the annual curl user surveys.
The 2021 analysis is here.
Update: I have been informed they are using that data and results as input. I was wrong above.
In the lwn comments on this topic, several people brought up that the curl project could “fix this” by making the support for different protocols into separate loadable modules, as then people could chose to only install the modules for the particular protocols they want.
That wouldn’t solve the issue at all. That would then instead just push users into installing several different protocol modules instead of minimal vs full. It would still be the same “this application suddenly broke because its needs YYY from libcurl”. Plus, the discussion around the curl-minimal package goes into more details and features than just protocols, and we can’t do every single feature a loadable module.
I have no intention of working on loadable modules for libcurl – for anything. That’s just a lot of work for no obvious benefit and it will introduce lots of new error and problem surfaces to users and it will not be possible to support on all platforms so it also needs to be provided conditionally.
I don’t know.
On Thursday March 17 2022 at 09:00 PDT (16:00 UTC, 17:00 CET) I will run this free live webinar.
It is an introduction to doing Internet transfers using libcurl, may 30-35 minutes presentation followed by a Q&A session where I can answer all and any questions you may have.
The presentation will include:
The webinar was recorded:
Do you remember August 26 2002? I can’t say I particularly do but the curl git log remembers for us that it was on that day we added this TODO item:
Add an option that prevents cURL from overwriting existing local files. When used, and there already is an existing file with the target file name (either -O or -o), a number should be appended (and increased if already existing).
That idea hadn’t even been listed for twenty years before it was converted into code by HexTheDragon and landed in curl the other day (with this commit). To get included in the pending curl 7.83.0 release.
--no-clobberThis new command line option (curl’s 247th) is called --no-clobber and it works as suggested already back in 2002. If the output file already exists at the time when curl wants to create it, it will instead append a number to the end of the name. If that file also exists, curl retries iteratively with numbers up to a 100 before it gives up and returns error.
To help you write even cooler scripts. Oh, and the -w variable %{filename_effective} will show this actually used file name.
We have just merged curl’s 246th command line option: --remove-on-error (with this commit). To be included in the upcoming curl 7.83.0 release.
This command line option is quite simple and does exactly what the name suggests. If you tell curl to download something into a local file and something goes wrong in that transfer – that makes curl return an error – this option will make curl remove that file rather than leaving the leftovers on disk in a possibly partial file.
The most basic use can look similar to:
curl --remove-on-error -O https://example.com/file
The option is in fact slightly more useful in more complicated cases, like when you want to download lots files in parallel and some of them might fail and you rather only keep the files that actually were transferred successfully:
curl --parallel -O 'https://example.com/file[1-999]'
Enjoy!