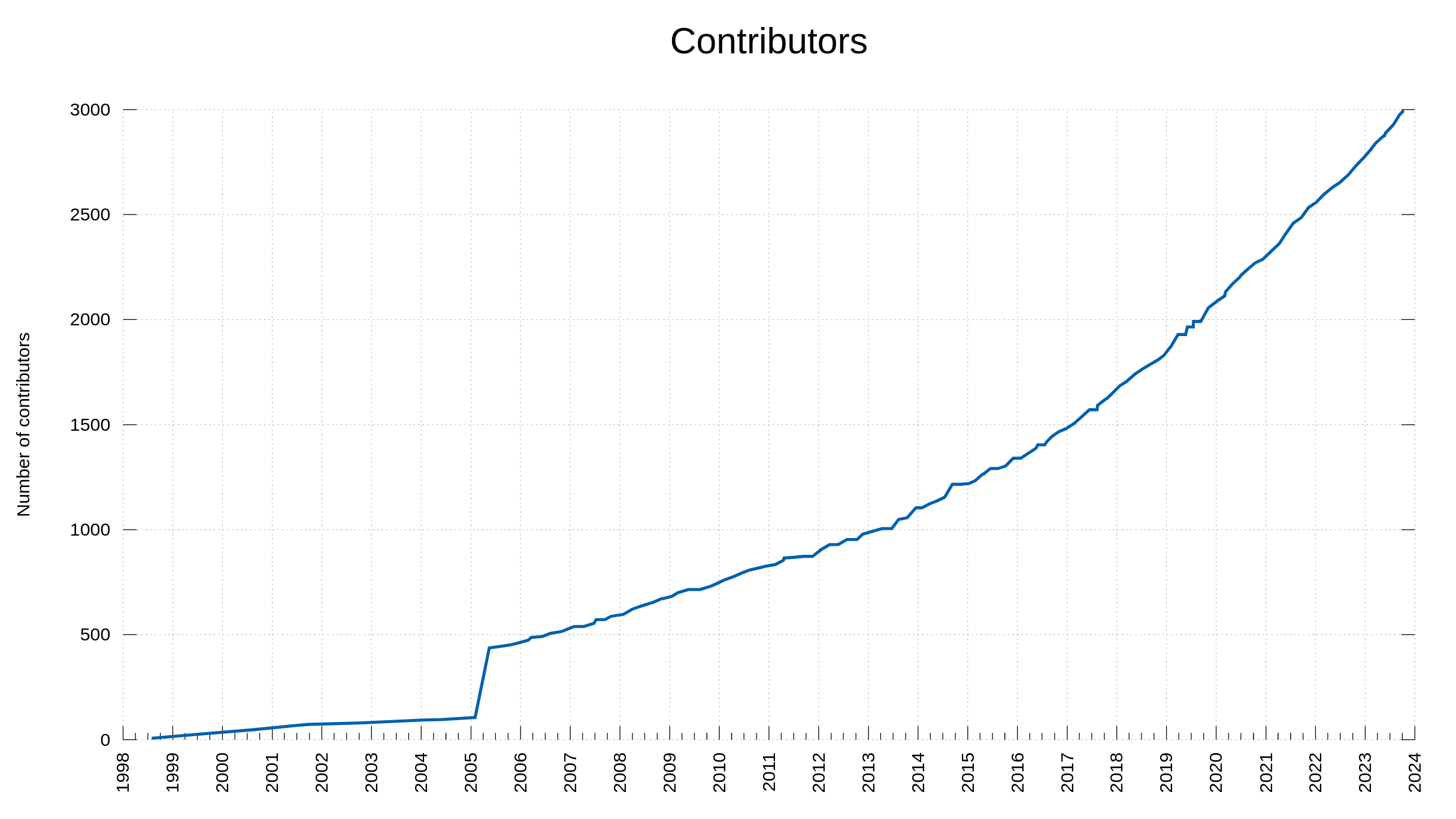
We have the full commit history of all curl source code since late December 1999. The reason we don’t have the history from before that moment is simply because I did not bother with that when I imported our code into Sourceforge back then. Just me being sloppy.
We know exactly when and who authored every change done to curl since then.
Development activity has gone both up and down over time since then. The number of new commit authors has increased slowly over time.
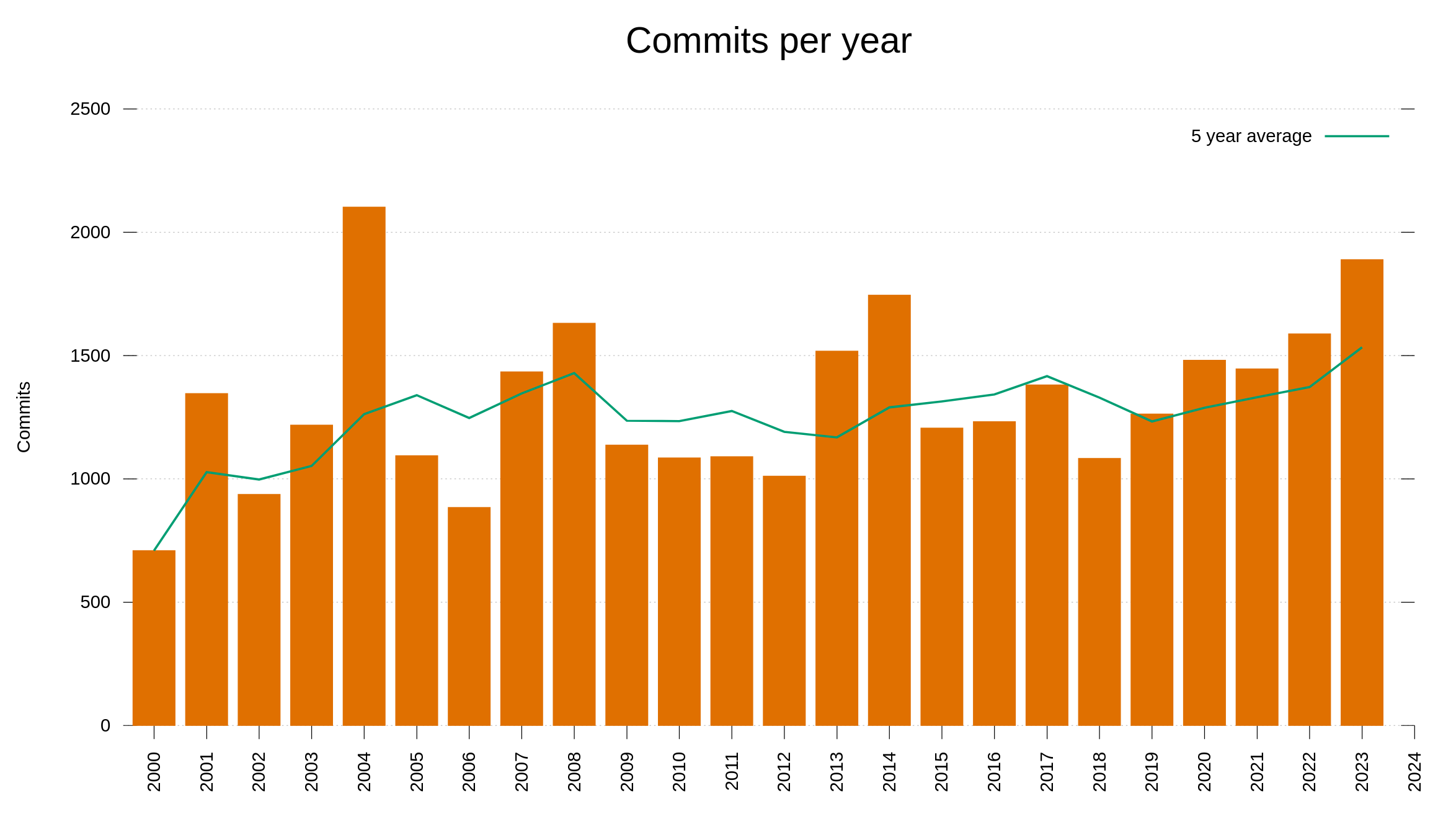
Commits
In the record year of 2004, when we still used CVS for version control, we had no CI infrastructure and I wrote 91% of all the commits myself. We made 2102 commits in the curl source tree that year. Back then without CI we did many more follow-up “oops” commits when we had to repair breakages we discovered post commit in our “autobuilds”. The quality of every individual commit was much lower then than today.
Looking through the commits and at the official history logs, there is no spectacular or special events that happened that year. It was just a period of intense development and general improvements of the code. The project was still young. We did seven curl releases in 2004, which is below the all time annual average.
The slowest (in terms of number of commits) recorded year so far was 2000, when I alone committed 100% of the 709 commits. The first year we have saved code history from.
The second most active year has been 2014 with 1745 commits. Also a year that does not really stand out when you look at features or other special things in the project. It was probably pushed that high due to an increased activity by others than me. I was just the second most commit author in curl that year. We did six releases in 2014.
In 2023 we celebrated curl’s official 25th birthday.
Today, we have merged more commits into the curl git during 2023 than we did in 2014 and 2023 is now officially the most active curl year commit-wise since 2004. With only a few days left of 2023, we can also conclude that we cannot reach the amount of 2004.
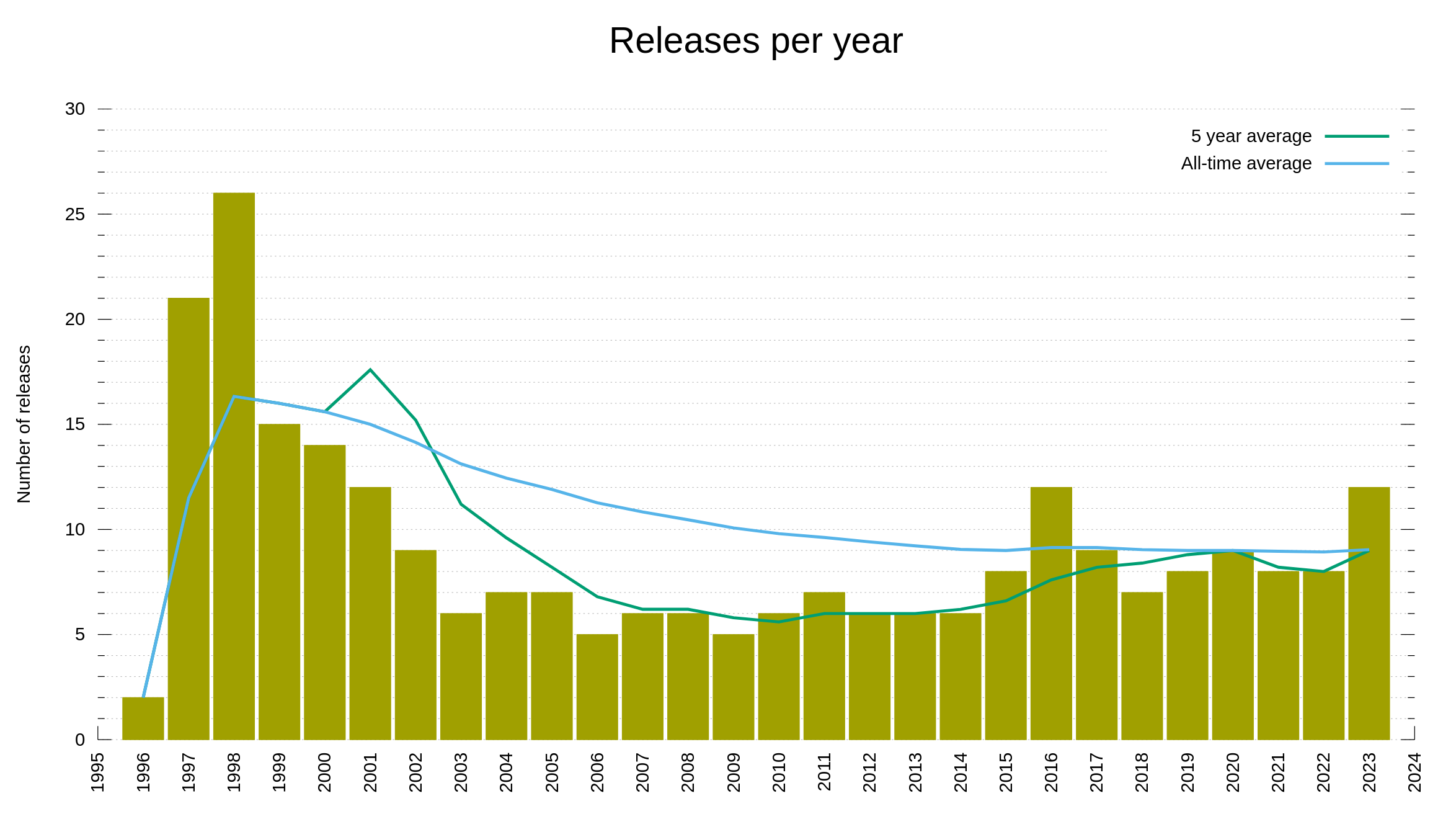
Releases
The commits of course end up in releases. This year, the shipped twelve new versions, which is over the average amount. The increased frequency is due to a modified policy where we are more likely to do follow-up patch releases when we find regressions in a release. In an effort to reduce the amount of known problems existing in the latest release.
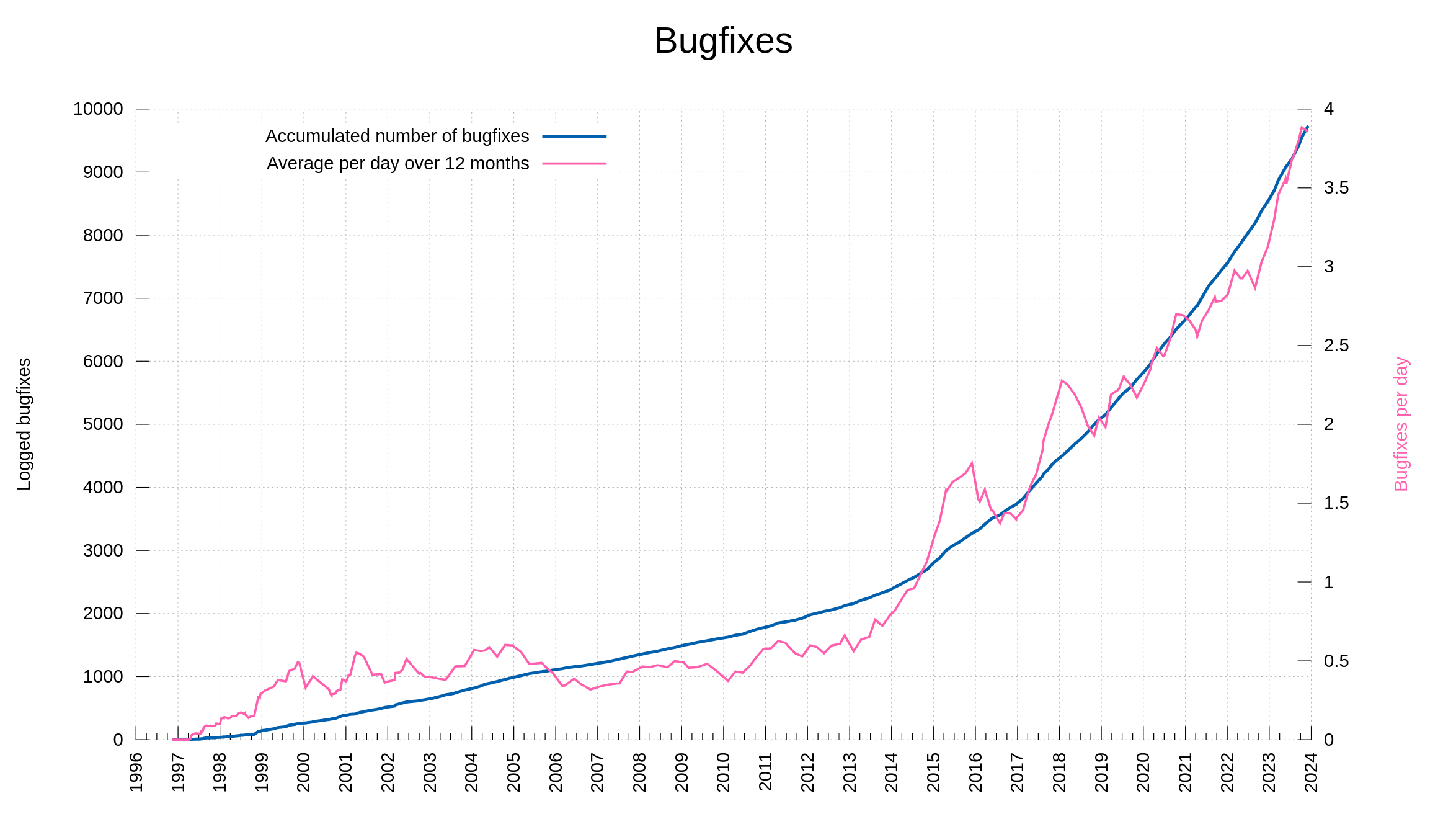
Bugfixes
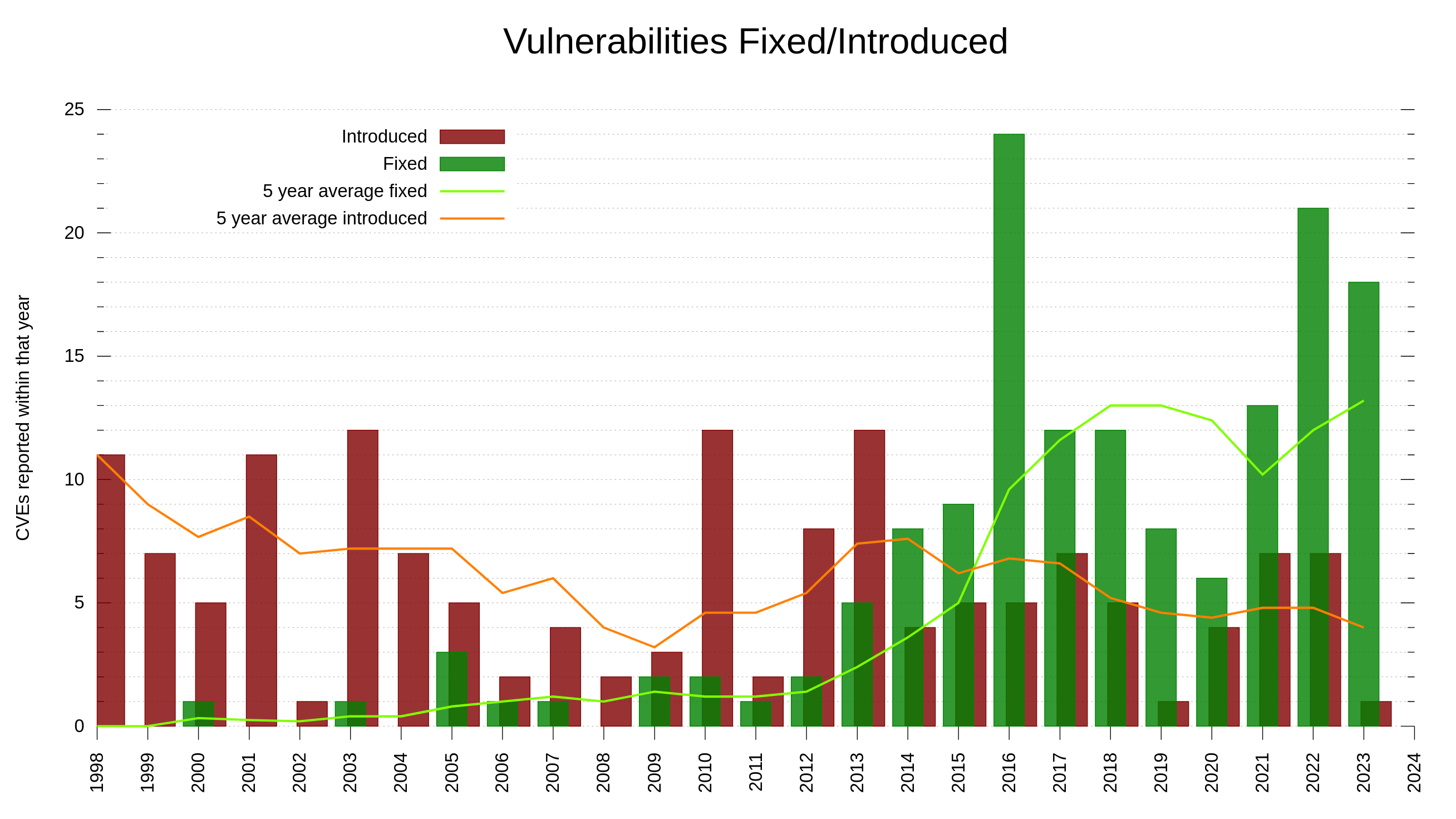
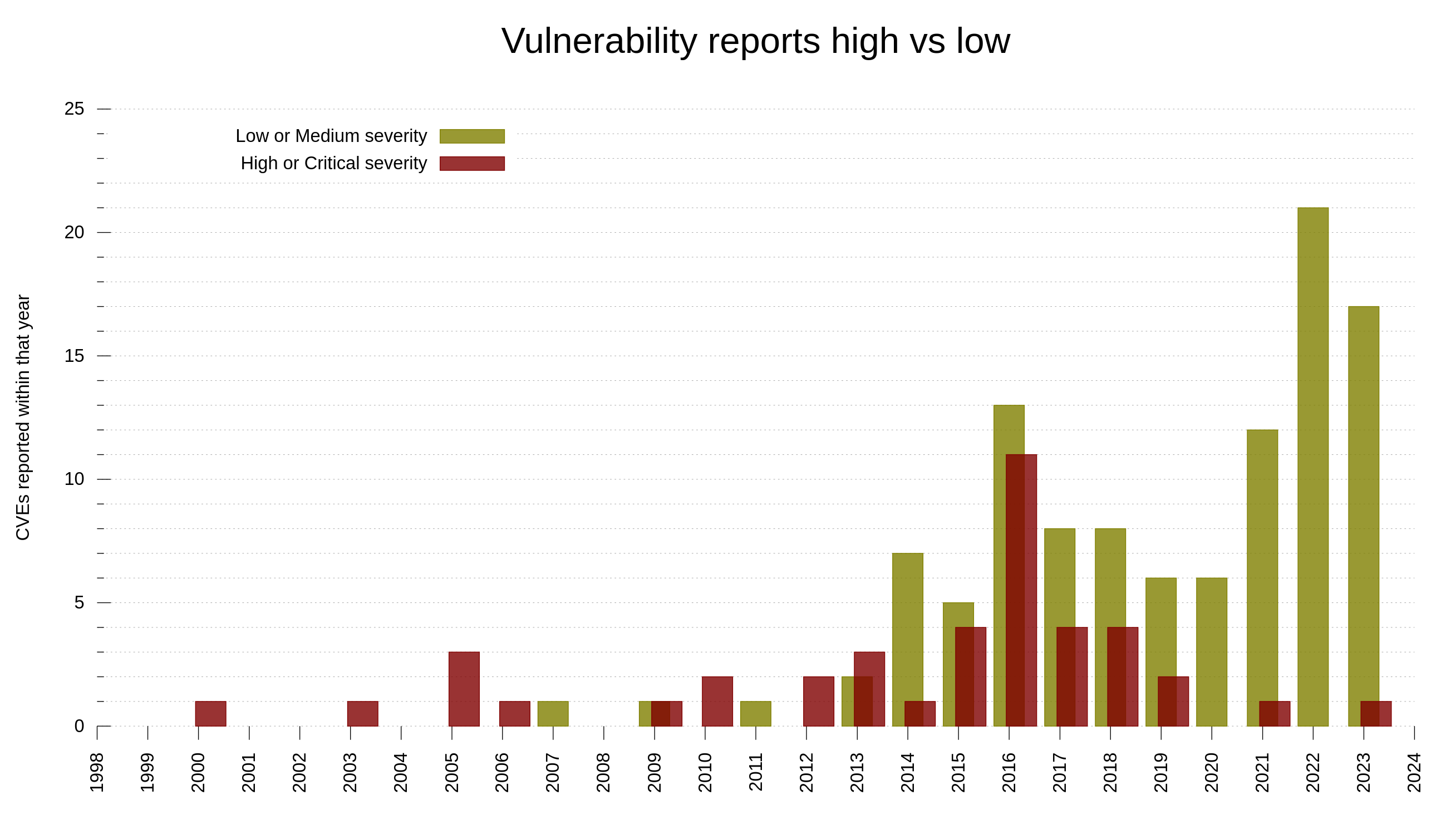
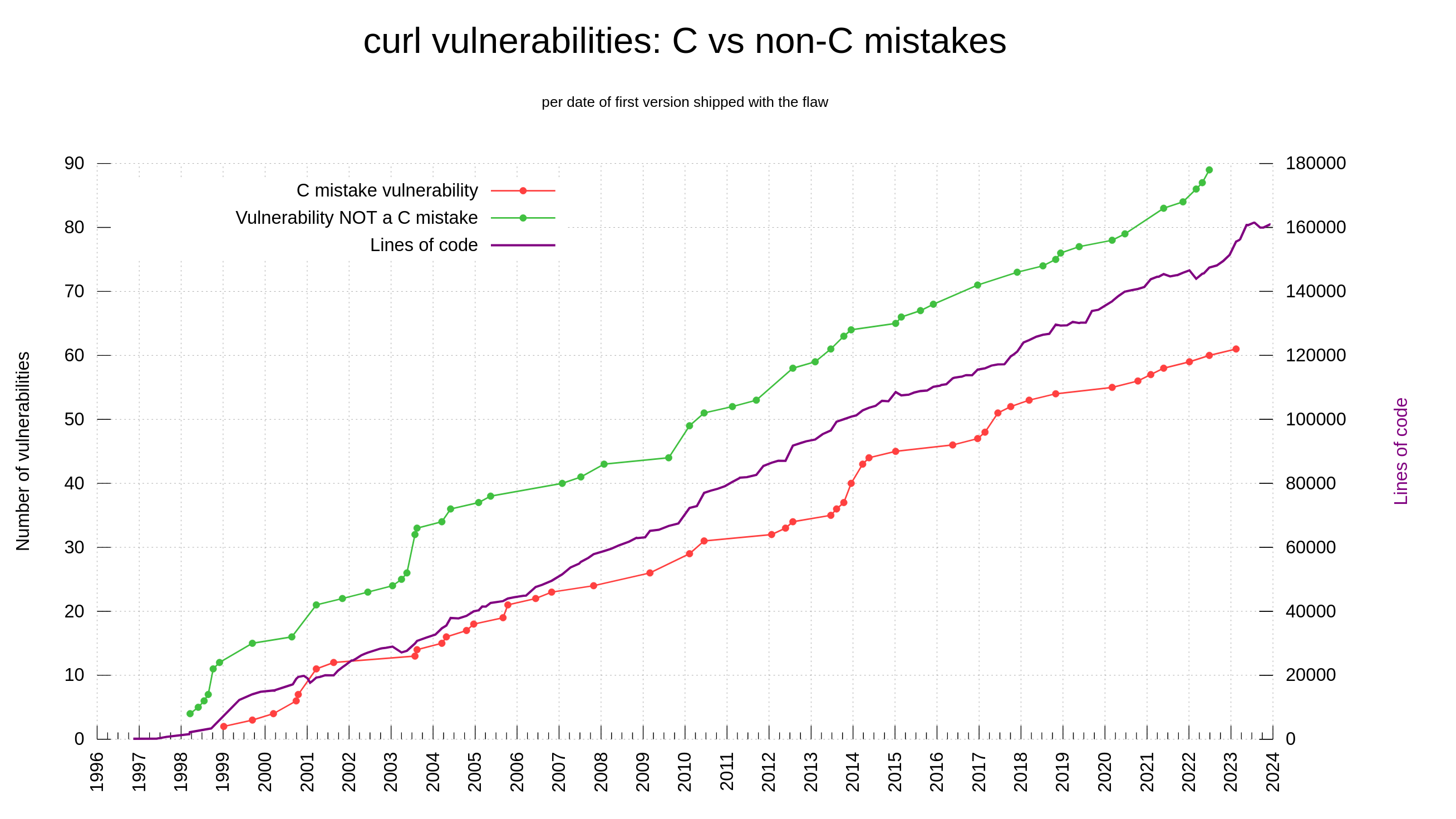
Counting these twelve releases of 2023, we released 1195 bugfixes during the year. Big and small. Code and docs. In build procedures and in the products. The rate of bugfixes has increased tremendously over the last decade. These days we average at over 3 bugfixes per day, compared to less than one ten years ago.
As a comparison: in the summary of the curl year 2012, we counted 199 bugfixes.
This is also partly explained by us keeping better records these days.
Authors
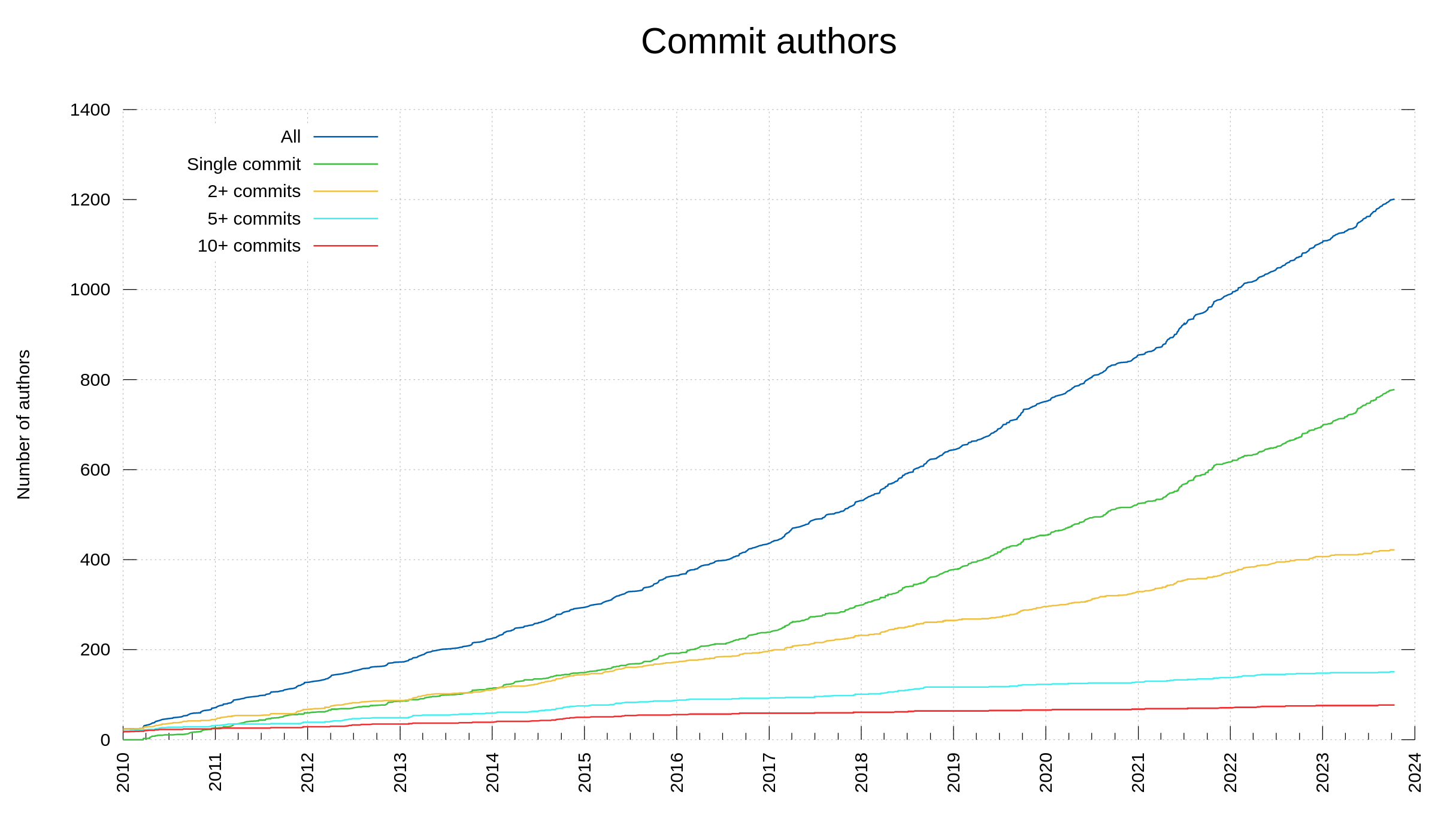
As I am typing this post, we count 187 commit authors of the year 2023 which is the exact same number we had in 2021 and a few more than last year. Out of all the committers this year, 123 authored a merged commit that for the first time. In 2021 that number was 135 so clearly we had a larger amount of return committers this year even if the total amount ended up the same.
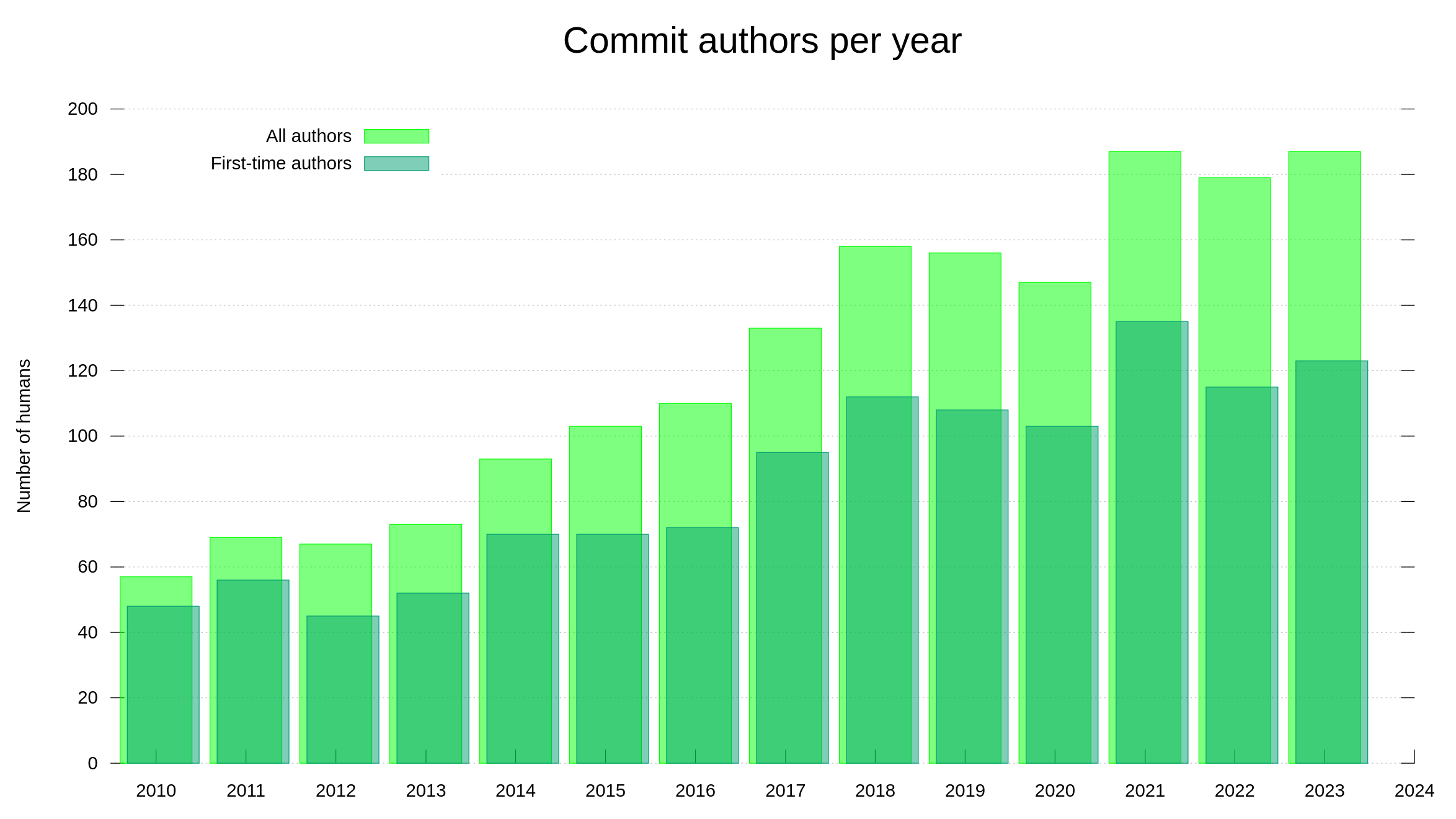
Looking at the most active commit authors, this year broke another trend. In 2023, two authors did 50% of all the commits. As the graph below shows, I did more than 50% of the commits for the last few years. This year, Dan Fandrich made 12.6% of the commits and I did less than half of them; together we did >50%.
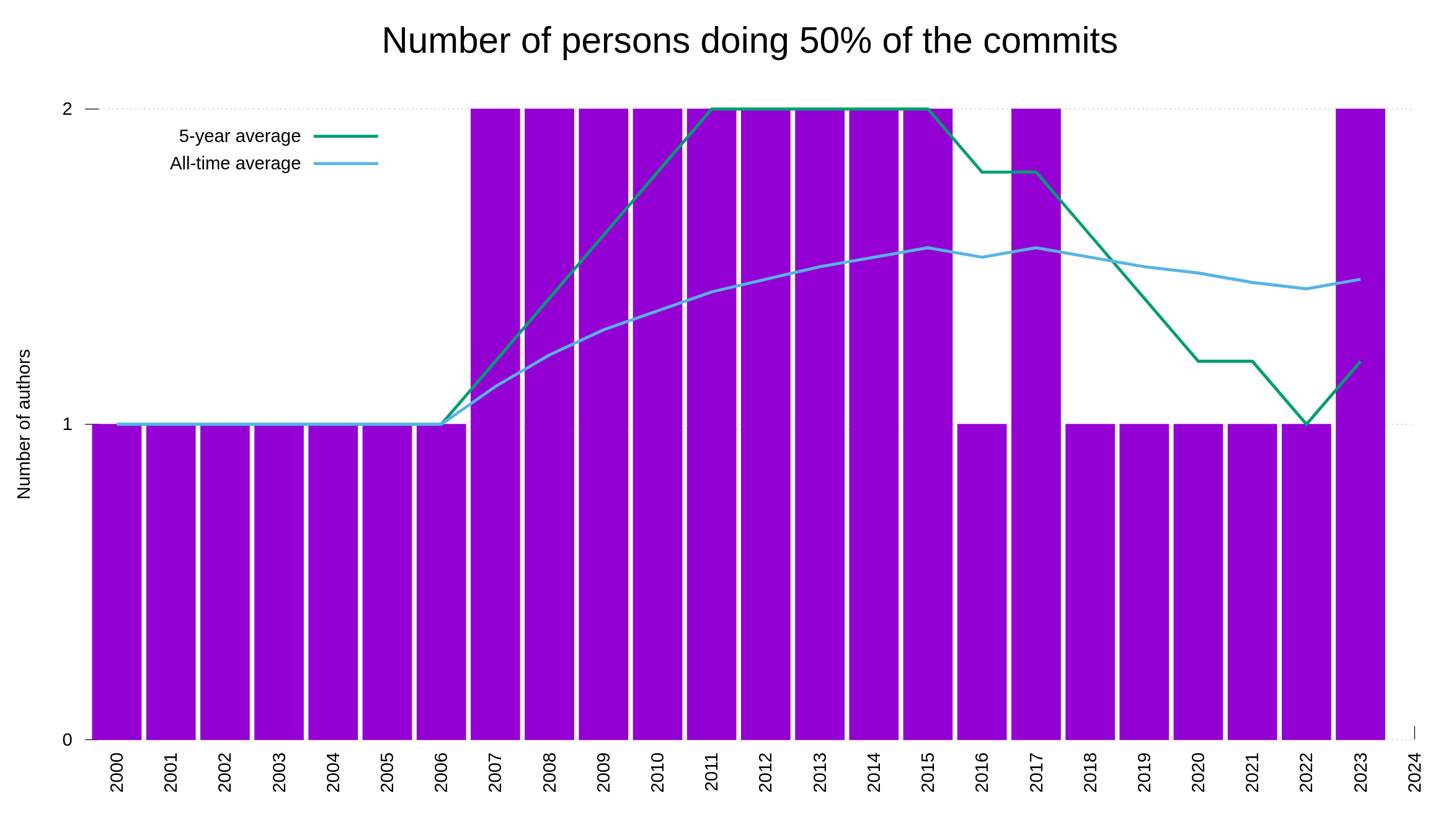
The number of authors needed to reach 70% and 95% of the commits show a little more varied story:
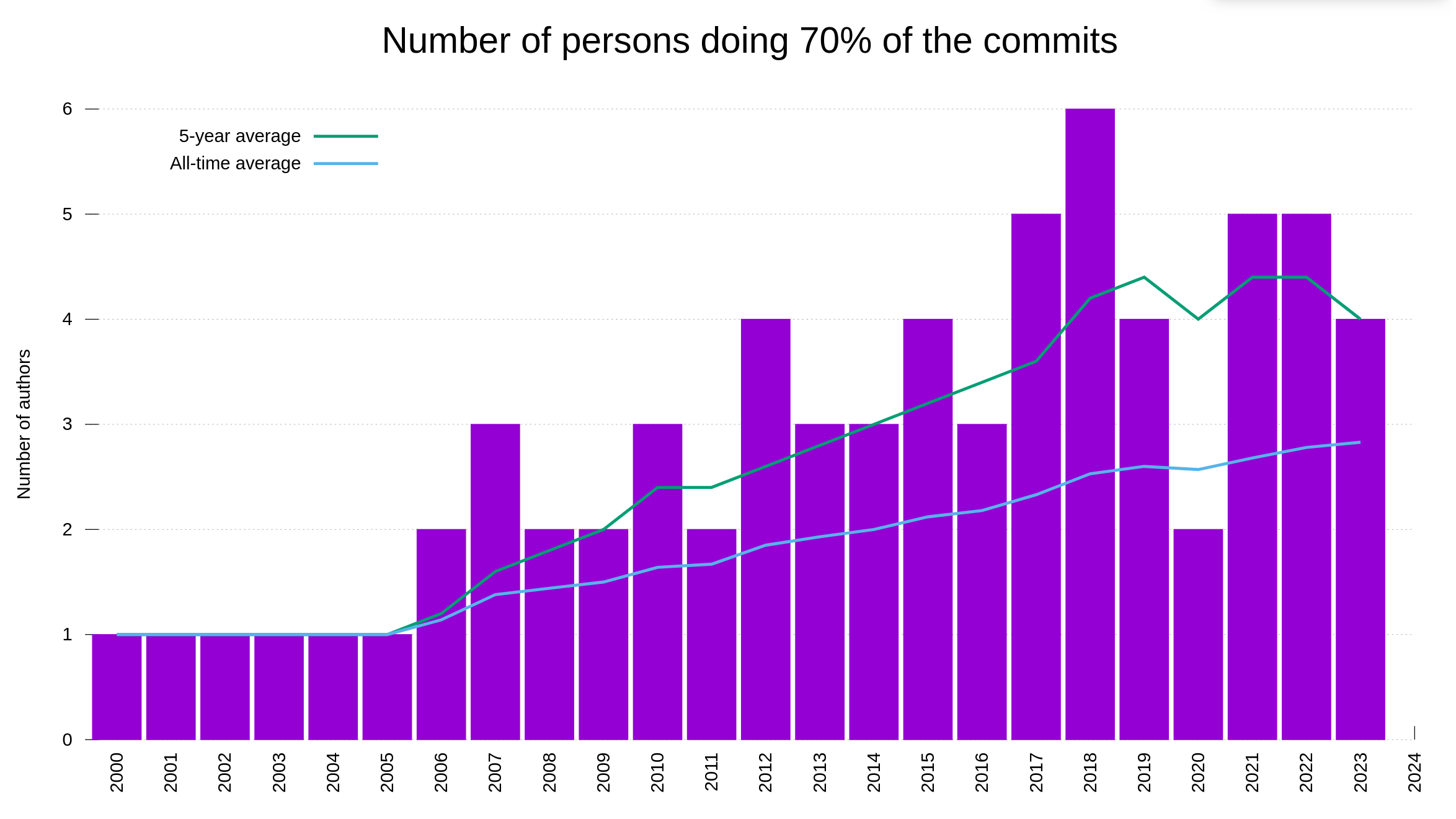
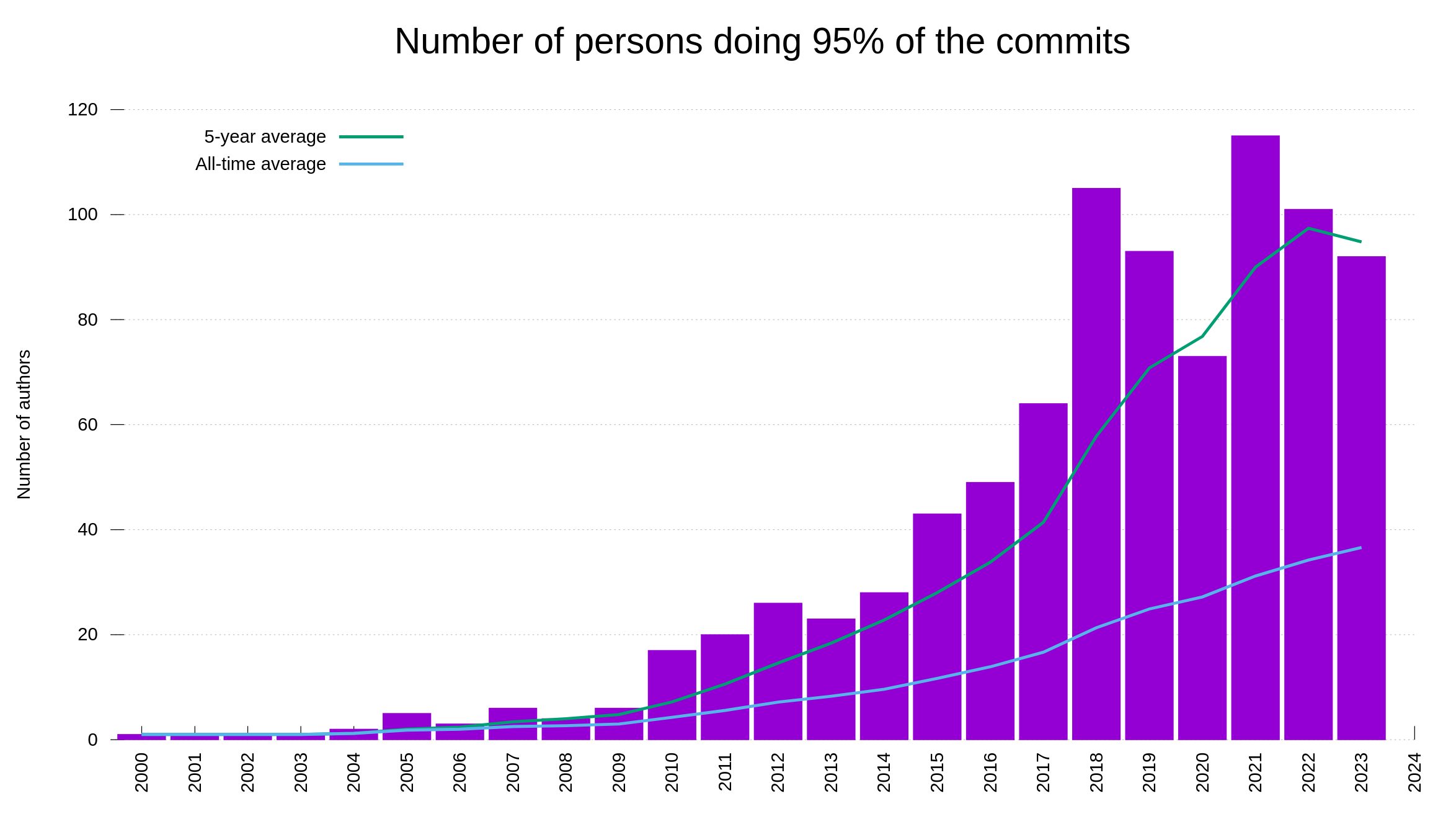
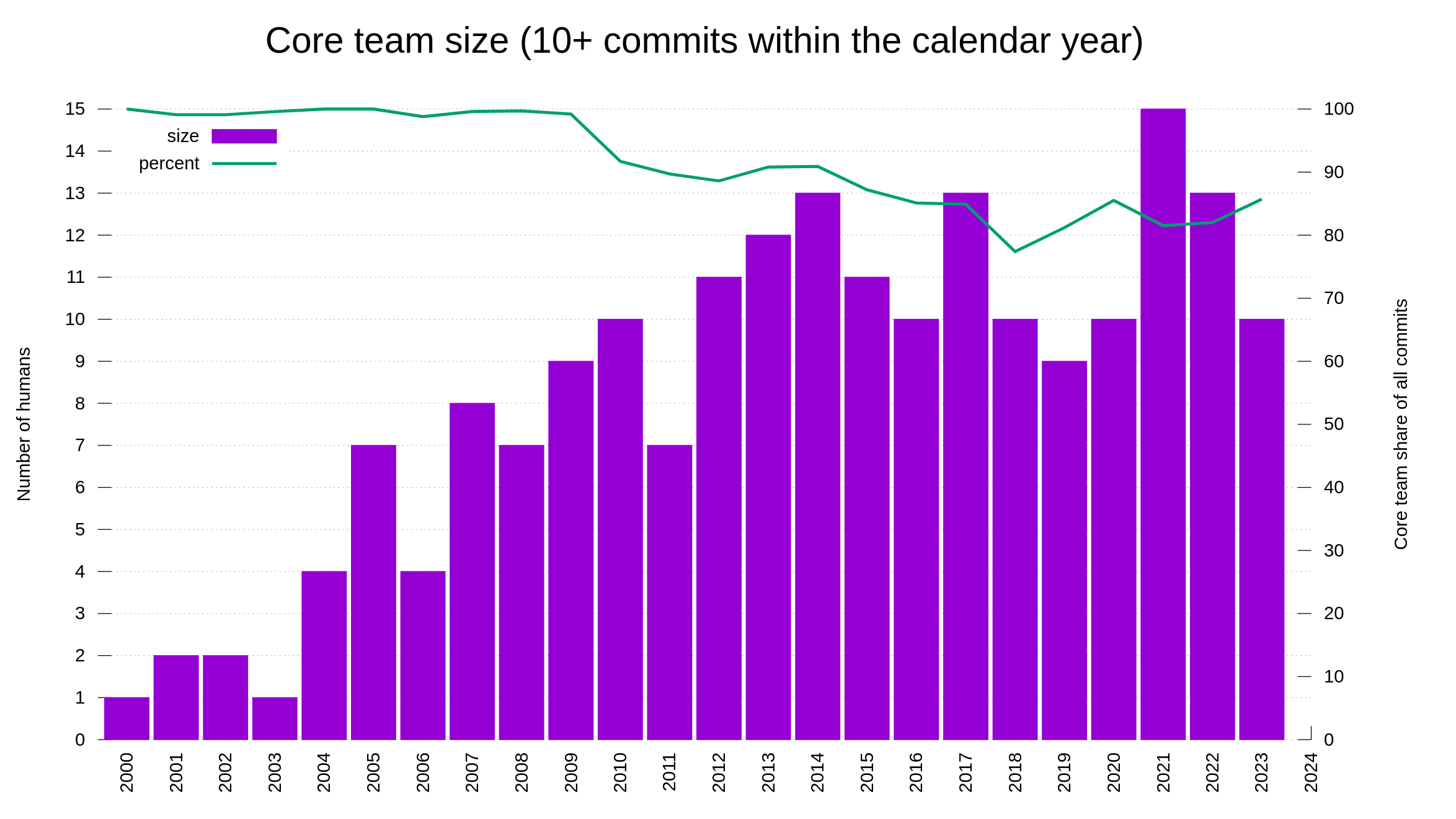
Or why not, the number of people who authored ten or more commits within the same calendar year:
My own activities
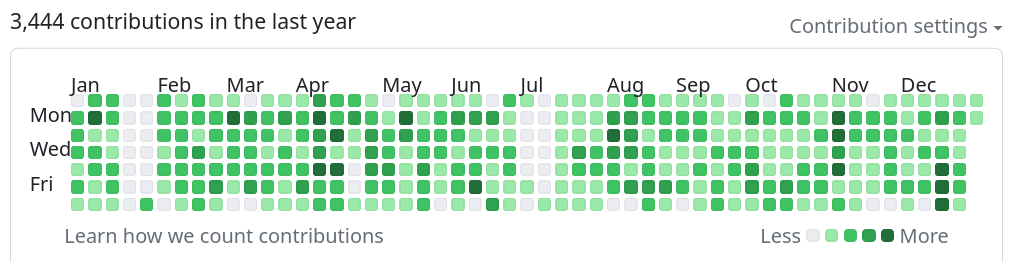
Out of the 1888 commits done in curl so far this year, I personally have done 847 (44.9%) of them.
According to GitHub, I have never had a more active year before than 2023. This increase seems unsustainable. I should probably then also add that a lot of these contributions were not done in the curl source tree repo. I was also fairly active in the repositories for the curl website, everything curl, trurl and a few others.
This year I approach the end of my fifth year working on curl full time. I maintain that I am living the dream: I work from home with my own open source “invention” with a team of awesome people. I can’t think of a better job.
Future
I stick to my old mantra: I cannot and I will not try to tell and foresee the future. I know that there will be more internet transfers, more protocols, more challenges, more bugs, more APIs, faster computers and quite likely more users, more customers and more security problems. But the details and how exactly all that is going to play out, I have no idea.
I hope we maintain a level of paying curl support customers so that I can keep living this life. I wish we get business to a degree to hire a second full time curl developer. I cross my fingers that companies and organizations will continue to pay up to get features added to curl and to sponsor maintenance, security and development in financial ways.
I have no plans to step off the curl train any time soon.
Credits
Image by Thomas Wolter from Pixabay