One of the toughest jobs I have, is to assess if a reported security problem is indeed an actual security vulnerability or “just” a bug. Let me take you through a recent case to give you an insight…
Some background
curl is 24 years old and so far in our history we have registered 111 security vulnerabilities in curl. I’ve sided with the “security vulnerability” side in reported issues 111 times. I’ve taken the opposite stance many more times.
Over the last two years, we have received 129 reports about suspected security problems and less than 15% of them (17) were eventually deemed actual security vulnerabilities. In the other 112 cases, we ended up concluding that the report was not pointing out a curl security problem. In many of those 112 cases, it was far from easy to end up with that decision and in several instances the reporter disagreed with us. (But sure, in the majority of the cases we could fairly quickly conclude that the reports were completely bonkers.)
The reporter’s view
Many times, the reporter that reports a security bug over on Hackerone has spent a significant amount of time and effort to find it, research it, reproduce it and report it. The reporter thinks it is a security problem and there’s a promised not totally insignificant monetary reward for such problems. Not to mention that a found and reported vulnerability in curl might count as something of a feat and a “feather in the hat” for a security researcher. The reporter has an investment in this work and a strong desire to have their reported issue classified as a security vulnerability.
The project’s view
If the reported problem is a security problem then we must consider it as that and immediately work on fixing the issue to reduce the risk of users getting hurt, and to inform all users about the risk and ask them to upgrade or otherwise mitigate and take precautions against the risks.
Most reported security issues are not immediately obvious. At least not in my eyes. I usually need to object, discuss, question and massage the data for a while in order to land on how we should best view the issue. I’m a skeptic by nature and I need to be convinced before I accept it.
Labeling something a “security vulnerability” if it indeed is not, is rather hurting users and the entire community rather than helping it. We must not cry wolf for a problem that cannot hurt users or that in practical terms is impossible to occur. Or maybe it is a problem that users are already expected to deal with. Or a result of an explicit or implicit application choice rather than a mistake done by us.
A bug in current libcurl makes it misbehave under certain conditions. When the MQTT connection gets closed mid message, libcurl refuses to acknowledge that and thinks the connection is still alive. Easily triggered by a malicious server.
libcurl considers the connection readable non-stop
Reading from the connection brings no more data
Busy-looping in the event-loop. Goto 2
The loop stops only once it reaches the set timeout, the progress callback can stop it and the speed-limit options will stop it if the right conditions are met.
By default, none of those options are set for a transfer and therefore, by default this makes an endless busy-loop.
At the same time…
A transfer can always stall and take a very long time to complete. A server can basically always just stop delivering more data, making the transfer take an infinite amount of time to complete. Applications that have not set any options to stop such a transfer risk doing a transfer that never ends. An endless transfer.
Also: if libcurl makes a transfer over a really fast network, such as localhost or using a super fast local network, then it might also reach the same level of busy-loop due to never having to wait for data. Albeit for a limited amount of time – until the transfer is complete. This busy-loop is highly unlikely to actually starve out any important threads in a system.
Yes, a closed connection is a much “cheaper” attack from server’s point of view than maintaining a long-living connection, but the cost of the attack is not a factor here.
Where in this grey area do we land?
This is difficult one.
I can see the point of the reporter, but I can also see how this flaw will basically not hurt any existing curl user. Where is our responsibility here?
I ended up concluding that this issue not a security vulnerability. The reporter disagreed.
It is a terribly annoying bug for sure. But the only applications that are seriously affected by it, are the ones that already allow an endless transfer.
The bug-fix was instead submitted as a normal pull-request: PR 8644, targeted to be fixed and included in the pending curl 7.83.0 release.
We publicize the reports after the fact
We make all (non-rubbish) previously reported hackerone issues public, whether they ended up being a vulnerability or not. To give everyone involved time to object or redact sensitive details, the publication date is usually within a month after the issue was closed.
By making the reports public, we allow everyone interested enough the ability and chance to check out and follow past discussions and deliberations for going the directions we did. The idea is primarily to be completely open about the reported issues and how we classify them, to show that we are not hiding anything and it also provides a chance for us to get more feedback from the surrounding and from security people who might disagree with previous analyses.
On March 16 2022, the curl security team received an email in which the reporter highlighted an Apple web page. What can you tell us about this?
I hadn’t seen it before. On this page with the title “About the security content of macOS Monterey 12.3”, said to have been published just two days prior, Apple mentions recent package upgrades and the page lists a bunch of products and what security fixes that were done for them in this update. Among the many products listed, curl is mentioned.
This is what the curl section of the page looked like:
Screenshot from March 17, 2022
In the curl project we always make all CVEs public with as much detail as we can possibly extract and provide about them. We take great pride in being the best in class in security flaw information and transparency.
Apple listed four CVE fixed. The three first IDs we immediately recognized from the curl security page. The last one however, was a surprise. What was that?
CVE-2022-22623
This is not a CVE published by the curl project. The curl project has in fact not shipped any CVE at all in 2022 (yet) so that’s easy to spot. When we looked at the MITRE registration for the ID, it also didn’t disclose any clues really. Not that it was expected to. It did show it was created on January 5 though, so it wasn’t completely new.
Was it a typo?
I compared this number to other recent CVE numbers announced from curl and I laid eyes on CVE-2021-22923 which had just two digits changed. Did they perhaps mean that CVE?
The only “problem” with that CVE is that it was in regards to Metalink and I don’t think Apple ever shipped their curl package with metalink support so therefore they wouldn’t have fixed a Metalink problem. So probably not a typo for that number at least!
I reached out to a friend at Apple as well with an email to Apple Product Security.
Security is our number one priority
In the curl project, we take security seriously. The news that there might be a security problem in curl that we haven’t been told about and that looks like it was about to get public sooner or later was of course somewhat alarming and something we just needed to get to the bottom of. It was also slightly disappointing that a large vendor and packager of curl since over 20 years would go about it this way and jab this into our back.
No source code
Apple has not made the source code for their macOS 12.3 version and the packages they use in there public, so there was no way for us to run diffs or anything to check for the exact modifications that this claimed fix would’ve resulted in.
Apple said so
Several “security websites” (the quotes are there to indicate that clearly these sites are more security in the name than in reality) immediately posted details about this “vulnerability”. Some of them with CVSS scores and CWE numbers , explaining how this problem can hurt users. Obviously completely made up since none of that info was made available by any first party sources anywhere. Not from Apple and not from the curl project. If you now did a web search on that CVE number, several of the top search results linked to such sites providing details – obviously made up from thin air.
As I think these sites don’t add much value to humanity, I won’t link to them here but instead I will show you a screenshot from such an article to show you what a made up CVE number posted by Apple can make people claim:
Screenshot from exploitone.com
At 23:28 (my time zone) on the 17th, my Apple friend responded saying they had forwarded the issue to “the right team”.
The Apple Product Security team I also emailed about this issue, answered at 00:23 (still my time) on the 18th saying “we are looking into this and will provide an update soon when we have more information.”
The MITRE page got more details
The MITRE CVE page from March 21st
After the weekend passed with no response, I looked back again on the MITRE page for the CVE in question and it had then gotten populated with additional curl details; mentioning Apple as CNA and now featuring links back to the Apple page! Now it really started to look like the CVE was something real that Apple (or someone) had registered but not told us about. It included real curl related snippets like this:
Multiple issues were addressed by updating to curl version 7.79.1. This issue is fixed in macOS Monterey 12.3. Multiple issues in curl.
Please tell us more details
On Monday the 21st, I continued to get questions about this CVE. Among others, from a member of a major European ISP’s CERT team curious about this CVE as they couldn’t find any specific information about this issue either and they were concerned they might have this vulnerability in the curl versions they run. They of course (rightfully) assumed that I would know about curl CVEs.
It turns out that when a major company randomly mentions a new CVE, it actually has an impact on the world!
Gone!
At around 20:30 on March 21st, someone on Twitter spotted that the ghost CVE had been removed from Apple’s web page and it only listed three issues (and a mention that the section had been updated). At 21:39 I get an email response from Apple Product Security:
Thank you for reaching out to us about the error with this CVE on our security advisory. We’ve updated our site and requested that MITRE reject CVE-2022-22623 on their end.
Please let us know if you have any questions.
Screenshot from March 21, 2022
The reject request to MITRE is expected to be slow so that page will remains showing the outdated data for a while longer.
Exploit one
When Apple had retracted the wrong CVE, I figured I should maybe try to get exploitone.com to remove their “article” to maybe at least stop one avenue of further misinformation about this curl “issue”. I tweeted (in perhaps a tad bit inflammatory manner):
I get the feeling they didn’t quite understand my point. They replied:
What happened?
As I had questions about Apple’s mishap, I replied (sent off 22:28 on the 21st, still only early afternoon on the US west coast), asking for details on what exactly had happened here. If it was a typo, then how come it got registered with MITRE? It’s just so puzzling and mysterious!
When I’m posting this article on my blog (36 hours after I sent the question), I still haven’t gotten any response or explanation. I don’t expect to get any either, but if I do, I will update this post accordingly.
Update March 26
exploitone.com updated their page at some point after my tweet to remove the mention of the imaginary CVE, but the wording remains very odd:
I’ve talked on this topic before but I realized I never did a proper blog post on the topic. So here it is: how we develop curl to keep it safe. The topic of supply chain security is one that is discussed frequently these days and every so often there’s a very well used (open source) component that gets a terrible weakness revealed.
Don’t get me wrong. Proprietary packages have their share of issues as well, and probably even more so, but for obvious reasons we never get the same transparency, details and insight into those problems and solutions.
If we would find a critical vulnerability in curl, it could potentially exist in every internet-connected device on the globe. We don’t want that.
A critical security flaw in our products would be bad, but we also similarly need to make sure that we provide APIs and help users of our products to be safe and to use curl safely. To make sure users of libcurl don’t accidentally end up getting security problems, to the best of our ability.
In the curl project, we work hard to never have our own version of a “heartbleed moment“. How do we do this?
Always improving
Our method is not strange, weird or innovative. We simply apply all best practices, tools and methods that are available to us. In all areas. As we go along, we tighten the screws and improve our procedures, learning from past mistakes.
There are no short cuts or silver bullets. Just hard work and running tools.
Not a coincidence
Getting safe and secure code into your product is not something that happens by chance. We need to work on it and we need to make a concerned effort. We must care about it.
We all know this and we all know how to do it, we just need to make sure that we also actually do it.
The steps
Write code following the rules
Review written code and make sure it is clear and easy to read.
Test the code. Before and after merge
Verify the products and APIs to find cracks
Bug-bounty to reward outside helpers
Act on mistakes – because they will happen
Writing
For users of libcurl we provide an API with safe and secure defaults as we understand the power of the default. We also document everything with details and take great pride in having world-class documentation. To reduce the risk of applications becoming unsafe just because our API was unclear.
We also document internal APIs and functions to help contributors write better code when improving and changing curl.
We don’t allow compiler warnings to remain – on any platform. This is sometimes quite onerous since we build on such a ridiculous amount of systems.
We encourage use of source code comments and assert()s to make assumptions obvious. (curl is primarily written in C.)
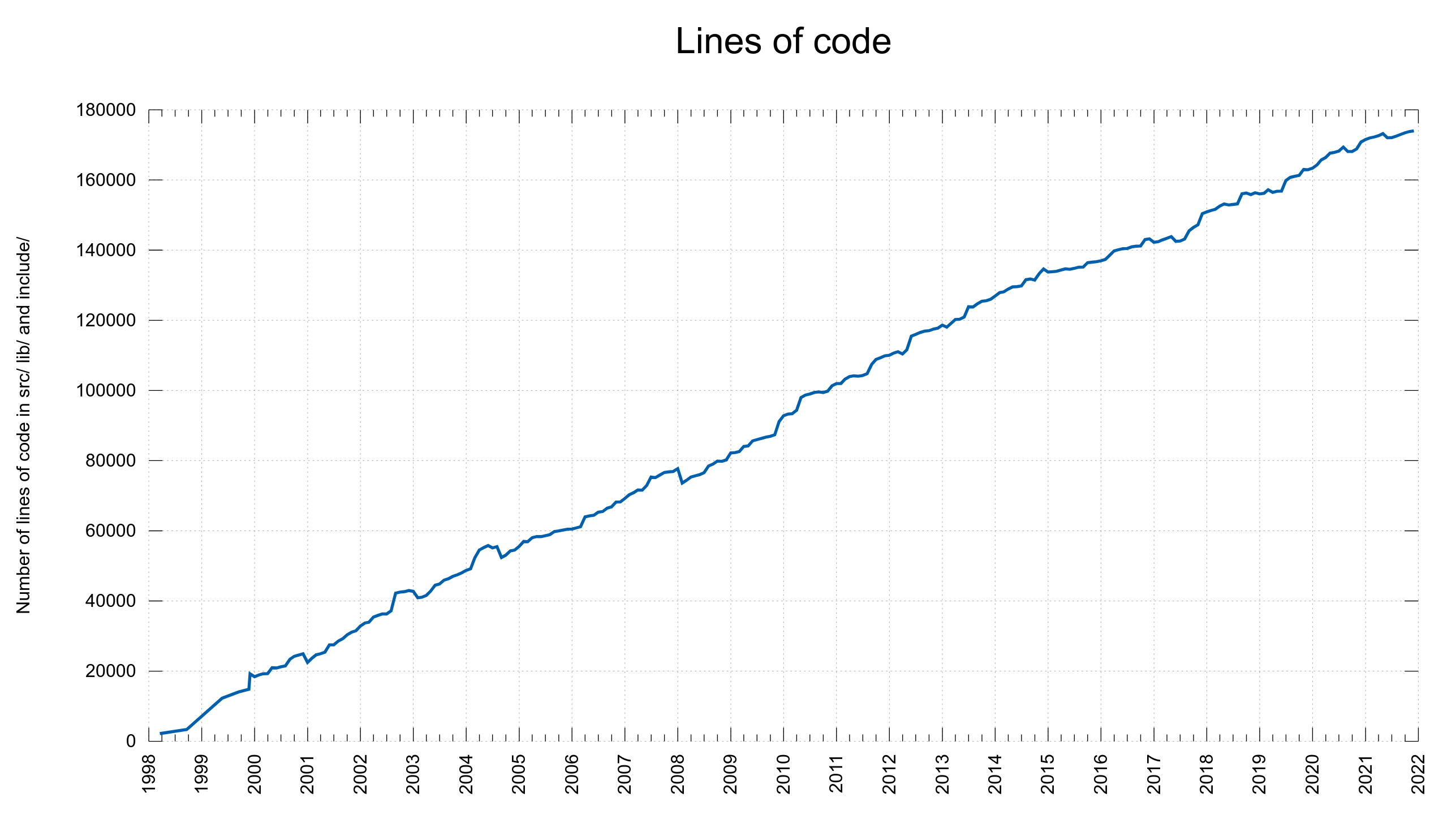
Number of lines of (product) code in the curl project over time.
Review
All code should be reviewed. Maintainers are however allowed to review and merge their own pull-requests for practical reasons.
Code should be easy to read and understand. Our code style must be followed and encourages that: for example, no assignments in conditions, one statement per line, no lines longer than 80 columns and more.
Strict compliance with the code style also means that the code gets a flow and a consistent look, which makes it easier to read and manage. We have a tool that verifies most aspects of the code style, which takes away most of that duty away from humans. I find that PR authors generally take code style remarks better when pointed out by a tool than when humans do it.
A source code change is accompanied with a git commit message that need to follow the template. A consistent commit message style makes it easier to later come back and understand it proper when viewing source code history.
Test
We want everything tested.
Unit tests. We strive at writing more and more unit tests of internal functions to make sure they truly do what expected.
System tests. Do actual network transfers against test servers, and make sure different situations are handled.
Integration tests. Test libcurl and its APIs and verify that they handle what they are expected to.
Documentation tests. Check formats, check references and cross-reference with source code, check lists that they include all items, verify that all man pages have all sections, in the same order and that they all have examples.
“Fix a bug? Add a test!” is a mantra that we don’t always live up to, but we try.
curl runs on 80+ operating systems and 20+ CPU architectures, but we only run tests on a few platforms. This usually works out fine because most of the code is written to run on multiple platforms so if tested on one, it will also run fine on all the other.
curl has a flexible build system that offers many million different build combinations with over 30 different possible third-party libraries in countless version combinations. We cannot test all build combos, but we try to test all the popular ones and at least one for each config option enabled and disabled.
We have many tests, but there are unfortunately still gaps and details not tested by the test suite. For those things we simply have to rely on the code review and then that users report problems in the shipped products.
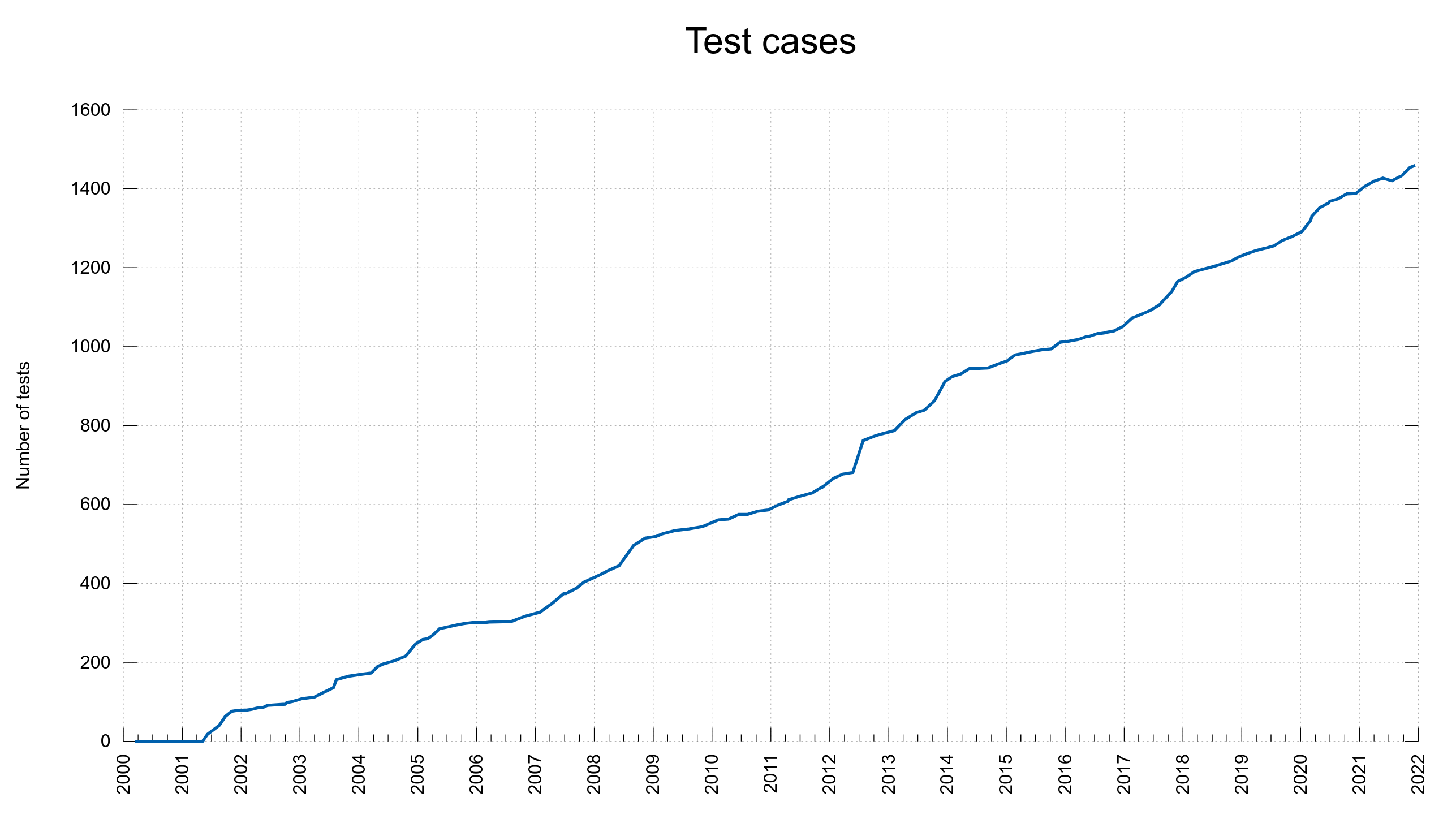
Number of test cases, test files really, over time.
Verify
We run all the tests using valgrind to make sure nothing leaks memory or do bad memory accesses.
We build and run with address, undefined behavior and integer overflow sanitizers.
We are part of the OSS-Fuzz project which fuzzes curl code non-stop, and we run CIFuzz in CI builds, which runs “a little” fuzzing on the curl code in the normal pull-request process.
We do “torture testing“: run a test case once and count the number of “fallible” function calls it makes. Those are calls to memory allocation, file operations, socket read/write etc. Then re-run the test that many times, and for each new iteration we make another one of the fallible functions fail and return error. Verify that no memory leaks or crashes occur. Do this on all tests.
We use several different static code analyzers to scan the code checking for flaws and we always fix or otherwise handle every reported defect. Many of them for each pull-request and commit, some are run regularly outside of that process:
scan-build
clang tidy
lgtm
CodeQL
Lift
Coverity
The exact set has varied and will continue to vary over time as services come and go.
Bug-bounty
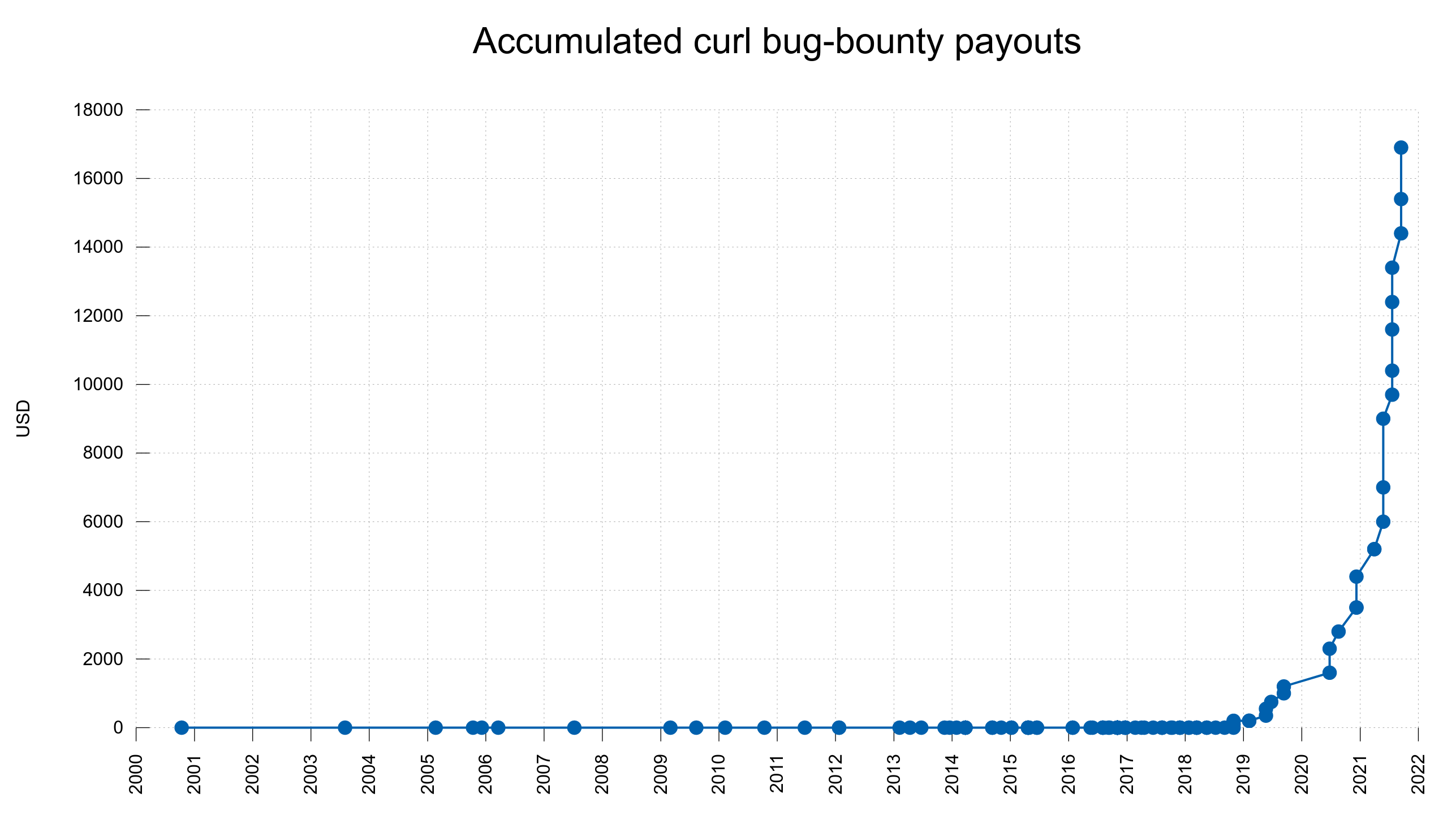
No matter how hard we try, we still ship bugs and mistakes. Most of them of course benign and harmless but some are not. We run a bug-bounty program to reward security searchers real money for reported security vulnerabilities found in curl. Until today, we have paid almost 17,000 USD in total and we keep upping the amounts for new findings.
Accumulated bug-bounty payouts over time
When we report security problems, we produce detailed and elaborate advisories to help users understand every subtle detail about the problem and we provide overview information that shows exactly what versions are vulnerable to which problems. The curl project aims to also be a world-leader in security advisories and related info.
Act on mistakes
We are not immune, no matter how hard we try. Bad things will happen. When they do, we:
Act immediately.
Own the problem, responsibly
Fix it and announce it – as soon as possible
Learn from it
Make it harder to do the same or similar mistakes again
Does it work? Do we actually learn from our history of mistakes? Maybe. Having our product in ten billion installations is not a proof of this. There are some signs that might show we are doing things right:
We were reporting fewer CVEs/year the last few years but in 2021 we went back up. It could also be the result of more people looking, thanks to the higher monetary rewards offered. At the same time the number of lines of code have kept growing at a rate of around 6,000 lines per year.
We get almost no issues reported by OSS-Fuzz anymore. The first few years it ran it found many problems.
We are able to increase our bug-bounty payouts significantly and now pay more than one thousand USD almost every time. We know people are looking hard for security bugs.
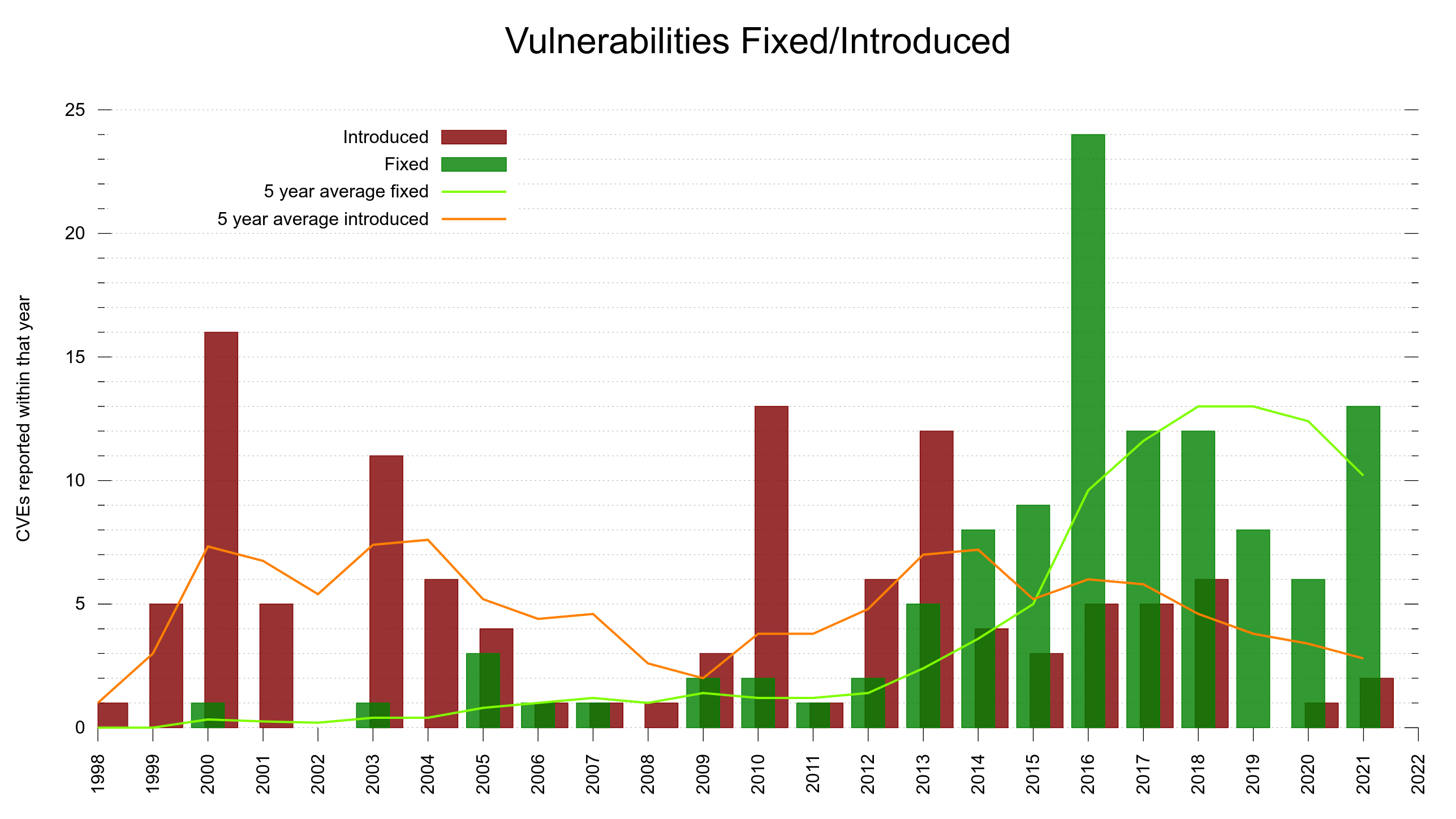
Security vulnerabilities. Fixed vs Introduced over the years.
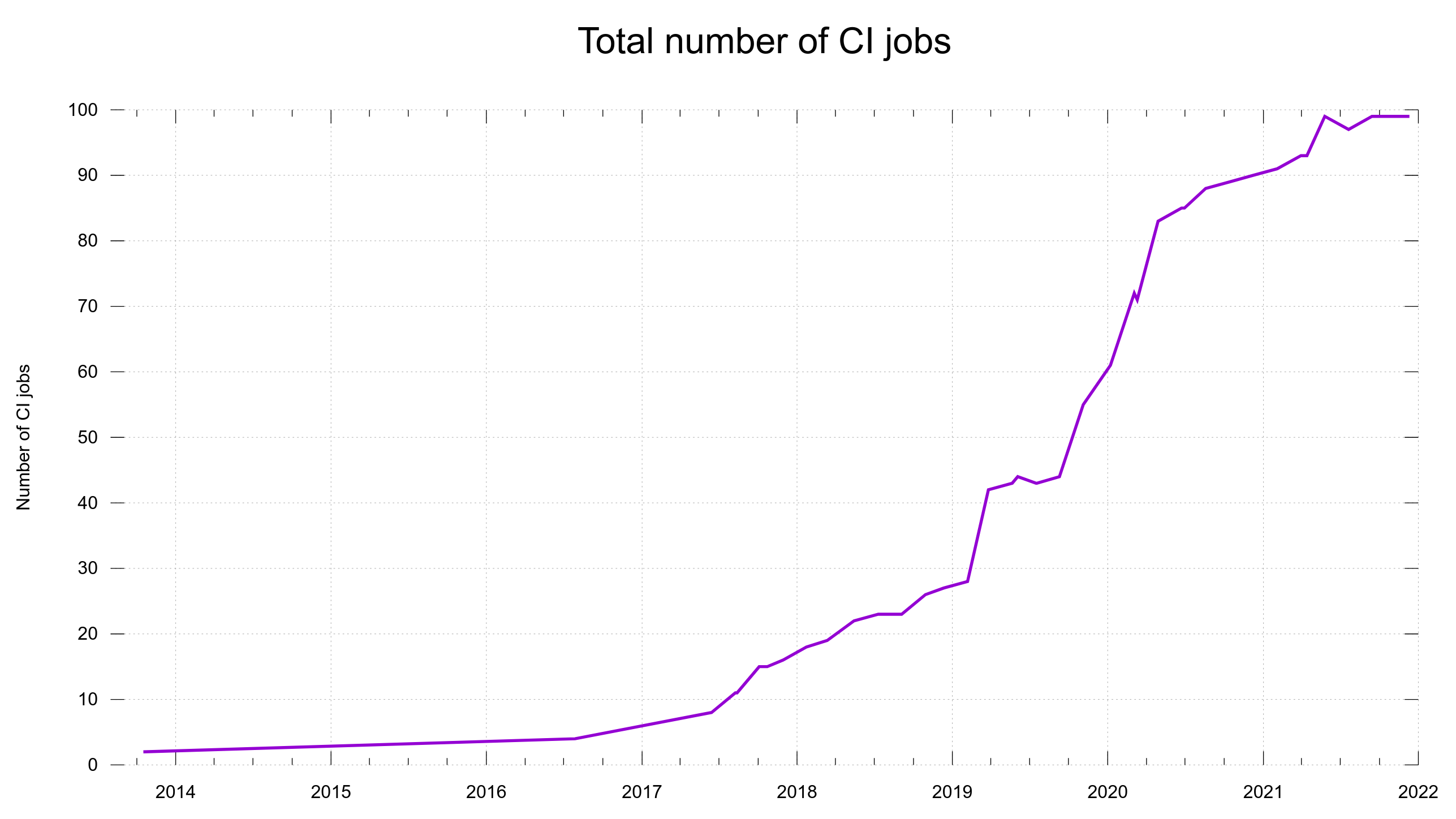
Continuous Integration
For every pull-request and commit done in the project, we run about 100 different builds + test rounds.
Total number of CI builds per pull-request and commit, over time
Done using several different CI services for maximum performance, widest possible coverage and shortest time to completion.
We currently use the following CI services: Cirrus CI, AppVeyor, Azure Pipelines, GitHub Actions, Circle CI and Zuul CI.
We also have a separate autobuild system with systems run by volunteers that checkout the latest code, build, run all the tests and report back in a continuous manner a few times or maybe once per day.
New habits past mistakes have taught us
We have done several changes to curl internals as direct reactions to past security vulnerabilities and their root causes. Lessons learned.
Unified dynamic buffer functions
These days we have a family of functions for working with dynamically sized buffers. Be using the same set for this functionality we have it well tested and we reduce the risk that new code messes up. Again, nothing revolutionary or strange, but as curl had grown organically over the decades, we found ourselves in need of cleaning this up one day. So we did.
Maximum string sizes
Several past mistakes came from possible integer overflows due to libcurl accepting input string sizes of unrestricted lengths and after doing operations on such string sizes, they would sometimes lead to overflows.
Since a few years back now, no string passed to curl is allowed to be larger than eight megabytes. This limit is somewhat arbitrarily set but is meant to be way larger than the largest user names and passwords ever used etc. We could also update the limit in a future, should we want. It’s not a limit that is exposed in the API or even mentioned. It is there to trap mistakes and malicious use.
Avoid reallocs
Thanks to the previous points we now avoid realloc as far as possible outside of those functions. History shows that realloc in combination with integer overflows have been troublesome for us. Now, both reallocs and integer overflows should be much harder to mess up.
Code coverage
A few years ago we ran code coverage reports for one build combo on one platform. This generated a number that really didn’t mean a lot to anyone but instead rather mislead users to drawing funny conclusions based on the report. We stopped that. Getting a “complete” and representative number for code coverage for curl is difficult and nobody has yet gone back to attempt this.
The impact of security problems
Every once in a while someone discovers a security problem in curl. To date, those security vulnerabilities have been limited to certain protocols and features that are not used by everyone and in many cases even disabled at build-time among many users. The issues also often rely on either a malicious user to be involved, either locally or remotely and for a lot of curl users, the environments it runs in limit that risk.
To date, I’m not aware of any curl user, ever, having been seriously impacted by a curl security problem.
This is not a guarantee that it will not ever happen. I’m only stating facts about the history so far. Security is super hard and I can only promise that we will keep working hard on shipping secure products.
Is it scary?
Changes done to curl code today will end up in billions of devices within a few years. That’s an intimidating fact that could truly make you paralyzed by fear of the risk that the world will “burn” due to a mistake of mine.
Rather than instilling fear by this outlook, I think the proper way to think it about it, is respecting the challenge and “shouldering the responsibility”. Make the changes we deem necessary, but make them according to the guidelines, follow the rules and trust that the system we have setup is likely to detect almost every imaginable mistake before it ever reaches a release tarball. Of course we plug holes in the test suite that we spot or suspect along the way.
The back-door threat
I blogged about that recently. I think a mistake is much more likely to slip-in and get shipped to the world than a deliberate back-door is.
Memory safe components might help
By rewriting parts of curl to use memory safe components, such as hyper for HTTP, we might be able to further reduce the risk of future vulnerabilities. That’s a long game to make reality. It will also be hard in the future to actually measure and tell for sure if it truly made an impact.
How can you help out?
Pay for a curl support contract. This is what enables me to work full time on curl.
Help out with reviews and adding new tests to curl
Help out with fixing issues and improving the code
In April 2019 we launched the current curl bug-bounty program under the Hackerone umbrella and from my point of view it has been nothing but a raging success. Until today we’ve paid almost 17,000 USD in rewards and and the average payment amount has been increasing all the time.
The reward money in this program have been paid to security reporters sourced from our own funds. Funds that have been donated to the curl project by our generous curl sponsors.
Before that day in 2019, when this program started, we did a few attempts to lean on and piggy-back on other bug-bounty efforts, but that never worked good enough. It mostly made the process unpredictable, outside of our control and ability to influence them and they never paid researchers “proper”.
We even started this latest program in association with a known brand company (that I won’t name here) who promised to chip-in and contribute money to the rewards whenever they would affect one of their use cases – but that similarly just ended up an empty promise for something that apparently never could happen. It feels much more honest and straight forward not giving anyone such false expectations – so they’re no longer involved here.
The original Internet Bug-Bounty
Another “failed program” from the past, at least as far as bounties for curl issues go, was the Hackerone driven bounty program known as IBB. It was an umbrella project to offer bounties for security problems in a set of “internet programs” including curl. I won’t bore you with details why that didn’t work. I think they paid some small bounties to two or three curl related issues.
IBB reborn but different now
The experience from all previous attempts and programs we’ve tried for bounties says that we need to be in control of what reported issues that are considered security related problems and I think it is important that we reward all such issues, without discrimination or other conditions. If the issue is indeed a security problem, then we appreciate getting told about it and we reward the person who did the job, figured it out and told us.
Therefore, skepticism was the initial response I felt when I was briefed about the re-introduction, rebirth if you want, of the IBB program. We’ve been there, we tried that.
But after talking to the people involved, I was subsequently convinced that we should give this effort a chance. There are several reasons that made me think this time can be different, to our benefit. They include:
The IBB program will pay the rewards from their funds, and they will do their own fund raising and “pester “big companies to help out, thus either entirely or mostly remove the need for us to fund the rewards or at least make our spending smaller. Or the rewards larger.
The members of the curl security team will still work with reported issues the exact same way as before and our security team will remain the sole arbiters of what problems that are in-scope and what problems that are not for issues reported on curl. We’ve established a decent working method for that over the last two something years and I feel good about us sticking to this. The IBB program is mostly involved at the end of the process when the reward amount and payout are handled.
We stick to mostly the same work-flow and site for reporting issues and communicating with reporters while the issues are in the initial non-disclosed state. Namely within the nicely working Hackerone issue tracker, which is designed and made specifically for this purpose.
Evaluation
We have not signed up for this new way of doing things for life. If it turns out that it is bad somehow for the curl project or for security researchers filing problems about curl, then we can always just backpedal back to the previous situation and continue as before.
This should be a fairly harmless test and change of process that should be an improvement for us as otherwise we won’t stick to it!
Welcome to the 200th curl release. We call it 200 OK. It coincides with us counting more than 900 commit authors and surpassing 2,400 credited contributors in the project. This is also the first release ever in which we thank more than 80 persons in the RELEASE-NOTES for having helped out making it and we’ve set two new record in the bug-bounty program: the largest single payout ever for a single bug (2,000 USD) and the largest total payout during a single release cycle: 3,800 USD.
This release cycle was 42 days only, two weeks shorter than normal due to the previous 7.76.1 patch release.
Release Presentation
Numbers
the 200th release 5 changes 42 days (total: 8,468) 133 bug-fixes (total: 6,966) 192 commits (total: 27,202) 0 new public libcurl function (total: 85) 2 new curl_easy_setopt() option (total: 290) 2 new curl command line option (total: 242) 82 contributors, 44 new (total: 2,410) 47 authors, 23 new (total: 901) 3 security fixes (total: 103) 3,800 USD paid in Bug Bounties (total: 9,000 USD)
Security
We set two new records in the curl bug-bounty program this time as mentioned above. These are the issues that made them happen.
This is a Use-After-Free in the OpenSSL backend code that in the absolutely worst case can lead to an RCE, a Remote Code Execution. The flaw is reasonably recently added and it’s very hard to exploit but you should upgrade or patch immediately.
The issue occurs when TLS session related info is sent from the TLS server when the transfer that previously used it is already done and gone.
The reporter was awarded 2,000 USD for this finding.
When libcurl accepts custom TELNET options to send to the server, it the input parser was flawed which could be exploited to have libcurl instead send contents from the stack.
The reporter was awarded 1,000 USD for this finding.
In the Schannel backend code, the selected cipher for a transfer done with was stored in a static variable. This caused one transfer’s choice to weaken the choice for a single set transfer could unknowingly affect other connections to a lower security grade than intended.
The reporter was awarded 800 USD for this finding.
Changes
In this release we introduce 5 new changes that might be interesting to take a look at!
Make TLS flavor explicit
As explained separately, the curl configure script no longer defaults to selecting a particular TLS library. When you build curl with configure now, you need to select which library to use. No special treatment for any of them!
No more SSL
curl now has no more traces of support for SSLv2 or SSLv3. Those ancient and insecure SSL versions were already disabled by default by TLS libraries everywhere, but now it’s also impossible to activate them even in special build. Stripped out from both the curl tool and the library (thus counted as two changes).
HSTS in the build
We brought HSTS support a while ago, but now we finally remove the experimental label and ship it enabled in the build by default for everyone to use it more easily.
In-memory cert API
We introduce API options for libcurl that allow users to specify certificates in-memory instead of using files in the file system. See CURLOPT_CAINFO_BLOB.
Favorite bug-fixes
Again we manage to perform a large amount of fixes in this release, so I’m highlighting a few of the ones I find most interesting!
Version output
The first line of curl -V output got updated: libcurl now includes OpenLDAP and its version of that was used in the build, and then the curl tool can add libmetalink and its version of that was used in the build!
curl_mprintf: add description
We’ve provided the *printf() clone functions in the API since forever, but we’ve tried to discourage users from using them. Still, now we have a first shot at a man page that clearly describes how they work.
This is important as they’re not quite POSIX compliant and users who against our advice decide to rely on them need to be able to know how they work!
CURLOPT_IPRESOLVE: preventing wrong IP version from being used
This option was made a little stricter than before. Previously, it would be lax about existing connections and prefer reuse instead of resolving again, but starting now this option makes sure to only use a connection with the request IP version.
This allows applications to explicitly create two separate connections to the same host using different IP versions when desired, which previously libcurl wouldn’t easily let you do.
Ignore SIGPIPE in curl_easy_send
libcurl makes its best at ignoring SIGPIPE everywhere and here we identified a spot where we had missed it… We also made sure to enable the ignoring logic when built to use wolfSSL.
Several HTTP/2-fixes
There are no less than 6 separate fixes mentioned in the HTTP/2 module in this release. Some potential memory leaks but also some more behavior improving things. Possibly the most important one was the move of the transfer-related error code from the connection struct to the transfers struct since it was vulnerable to a race condition that could make it wrong. Another related fix is that libcurl no longer forcibly disconnects a connection over which a transfer gets HTTP_1_1_REQUIRED returned.
Partial CONNECT requests
When the CONNECT HTTP request sent to a proxy wasn’t all sent in a single send() call, curl would fail. It is baffling that this bug hasn’t been found or reported earlier but was detected this time when the reporter issued a CONNECT request that was larger than 16 kilobytes…
TLS: add USE_HTTP2 define
There was several remaining bad assumptions that HTTP/2 support in curl relies purely on nghttp2. This is no longer true as HTTP/2 support can also be provide by hyper.
When libcurl (built with libssh2 support) stopped an SFTP transfer because a timeout was triggered, the following SFTP disconnect procedure was subsequently also stopped because of the same timeout and therefore wasn’t allowed to properly clean up everything, leading to a memory-leak!
IRC network switch
We moved the #curl IRC channel to the new network libera.chat. Come join us there!
Next release
On Jul 21, 2021 we plan to ship the next release. The version number for that is not yet decided but we have changes in the pipeline, making a minor version number bump very likely.
In the curl project we make great efforts to store a lot of meta data about each and every vulnerability that we have fixed over the years – and curl is over 23 years old. This data set includes CVE id, first vulnerable version, last vulnerable version, name, announce date, report to the project date, CWE, reward amount, code area and “C mistake kind”.
We also keep detailed data about releases, making it easy to look up for example release dates for specific versions.
Dashboard
All this, combined with my fascination (some would call it obsession) of graphs is what pushed me into creating the curl project dashboard, with an ever-growing number of daily updated graphs showing various data about the curl projects in visual ways. (All scripts for that are of course also freely available.)
What to show is interesting but of course it is sometimes even more important how to show particular data. I don’t want the graphs just to show off the project. I want the graphs to help us view the data and make it possible for us to draw conclusions based on what the data tells us.
Vulnerabilities
The worst bugs possible in a project are the ones that are found to be security vulnerabilities. Those are the kind we want to work really hard to never introduce – but we basically cannot reach that point. This special status makes us focus a lot on these particular flaws and we of course treat them special.
For a while we’ve had two particular vulnerability graphs in the dashboard. One showed the number of fixed issues over time and another one showed how long each reported vulnerability had existed in released source code until a fix for it shipped.
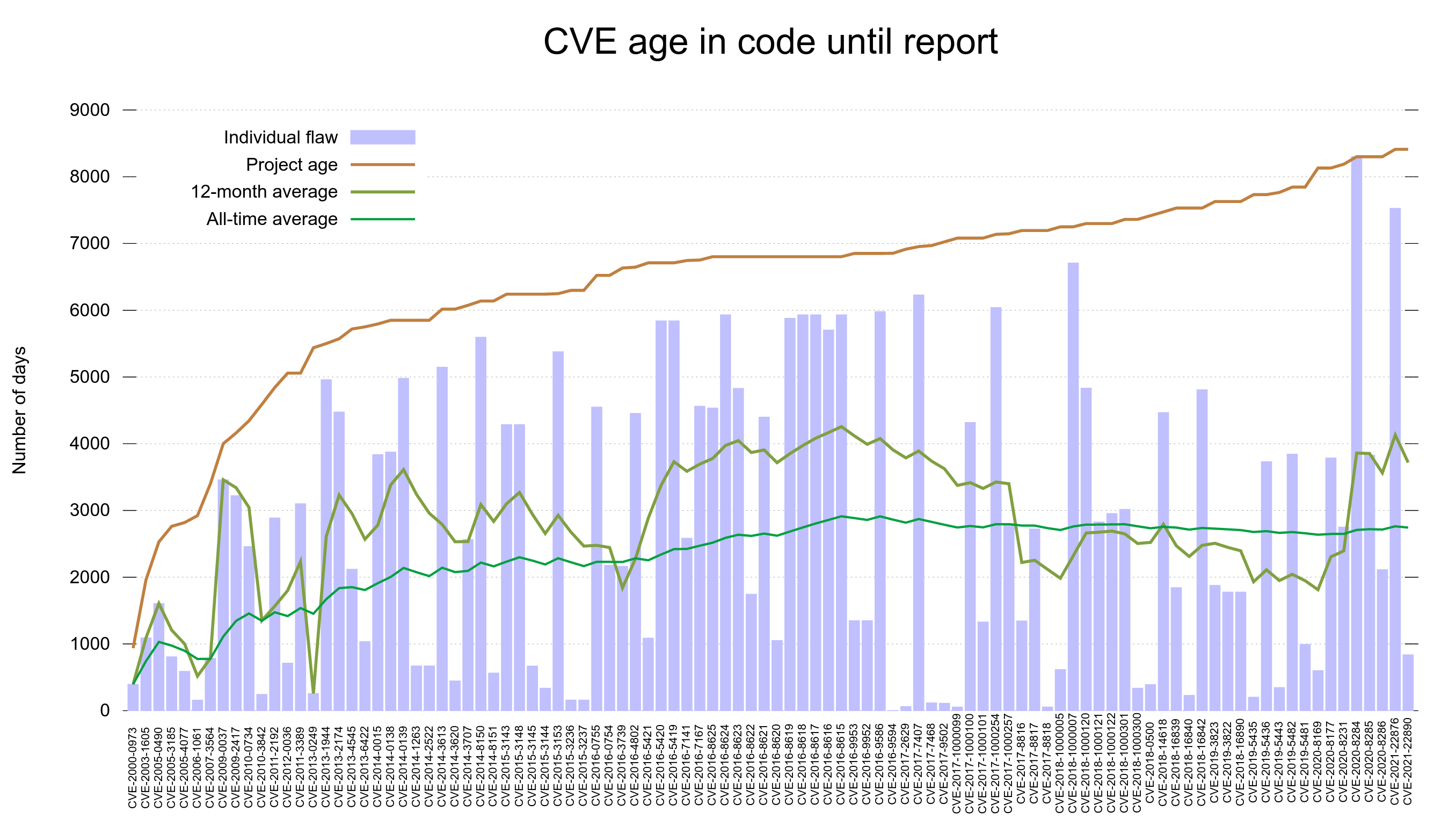
CVE age in code until report
The CVE age in code until report graph shows that in general, reported vulnerabilities were introduced into the code base many years before they are found and fixed. In fact, the all time average time suggests they are present for more than 2,700 – more than seven years. Looking at the reports from the last 12 months, the average is even almost 1000 days more!
It takes a very long time for vulnerabilities to get found and reported.
When were the vulnerabilities introduced
Just the other day it struck me that even though I had a lot of graphs already showing in the dashboard, there was none that actually showed me in any nice way at what dates we created the vulnerabilities we spent so much time and effort hunting down, documenting and talking about.
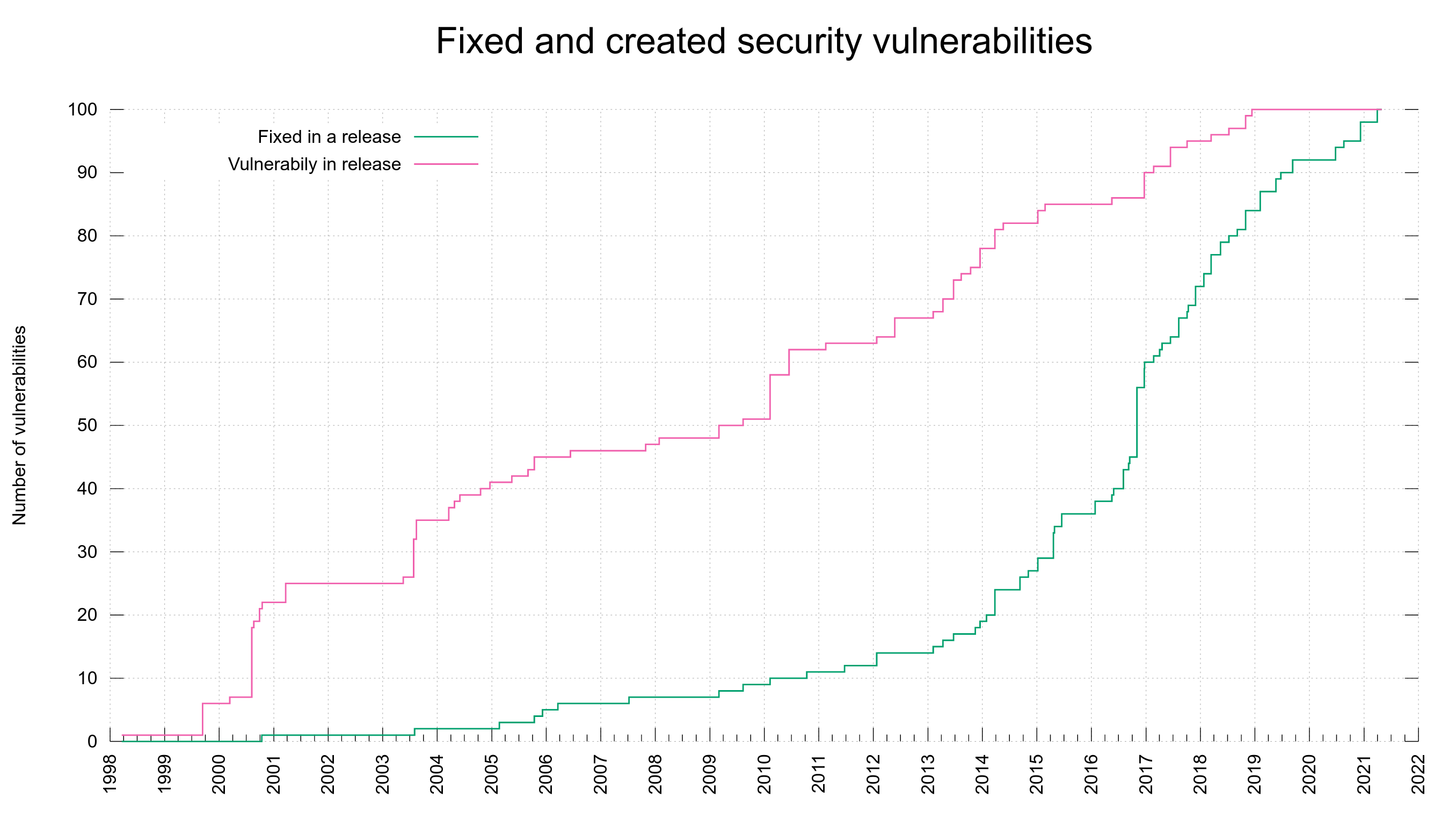
I decided to use the meta data we already have and add a second plot line to the already existing graph. Now we have the previous line (shown in green) that shows the number of fixed vulnerabilities bumped at the date when a fix was released.
Added is the new line (in red) that instead is bumped for every date we know a vulnerability was first shipped in a release. We know the version number from the vulnerability meta data, we know the release date of that version from the release meta data.
This all new graph helps us see that out of the current 100 reported vulnerabilities, half of them were introduced into the code before 2010.
Using this graph it also very clear to me that the increased CVE reporting that we can spot in the green line started to accelerate in the project in 2016 was not because the bugs were introduced then. The creation of vulnerabilities rather seem to be fairly evenly distributed over time – with occasional bumps but I think that’s more related to those being particular releases that introduced a larger amount of features and code.
As the average vulnerability takes 2700 days to get reported, it could indicate that flaws landed since 2014 are too young to have gotten reported yet. Or it could mean that we’ve improved over time so that new code is better than old and thus when we find flaws, they’re more likely to be in old code paths… I don’t think the red graph suggests any particular notable improvement over time though. Possibly it does if we take into account the massive code growth we’ve also had over this time.
The green “fixed” line at least has a much better trend and growth angle.
Present in which releases
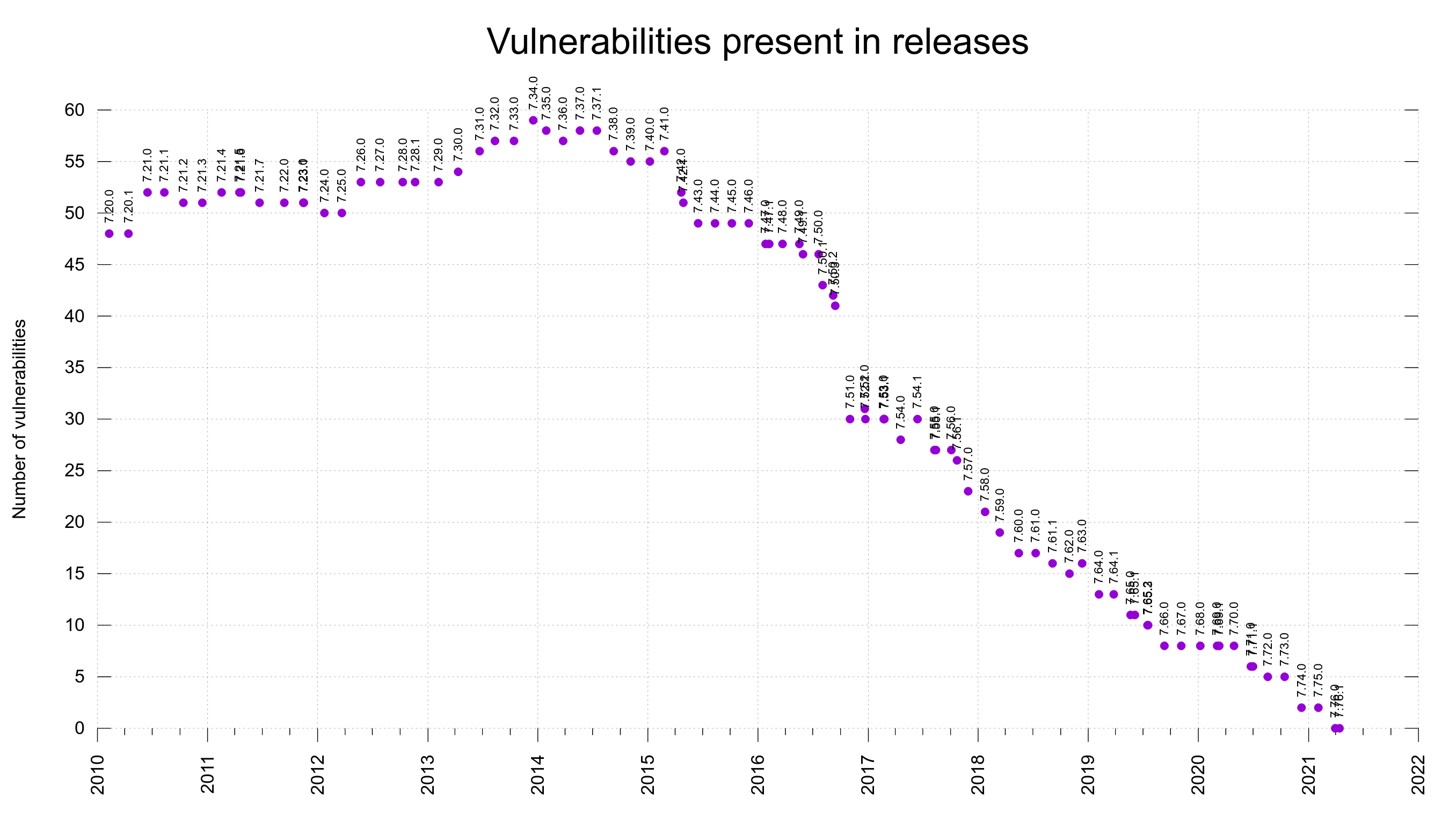
As we have the range of vulnerable releases stored in the meta data file for each CVE, we can then add up the number of the flaws that are present in every past release.
Together with the release dates of the versions, we can make a graph that shows the number of reported vulnerabilities that are present in each past release over time, in a graph.
You can see that some labels end up overwriting each other somewhat for the occasions when we’ve done two releases very close in time.
I’ve previously blogged about the possible backdoor threat to curl. This post might be a little repeat but also a refresh and renewed take on the subject several years later, in the shadow of the recent PHP backdoor commits of March 28, 2021. Nowadays, “supply chain attacks” is a hot topic.
Since you didn’t read that PHP link: an unknown project outsider managed to push a commit into the PHP master source code repository with a change (made to look as if done by two project regulars) that obviously inserted a backdoor that could execute custom code when a client tickled a modified server the right way.
Partial screenshot of a diff of the offending commit in question
The commits were apparently detected very quickly. I haven’t seen any proper analysis on exactly how they were performed, but to me that’s not the ultimate question. I rather talk and think about this threat in a curl perspective.
PHP is extremely widely used and so is curl, but where PHP is (mostly) server-side running code, curl is client-side.
How to get malicious code into curl
I’d like to think about this problem from an attacker’s point of view. There are but two things an attacker need to do to get a backdoor in and a third adjacent step that needs to happen:
Make a backdoor change that is hard to detect and appears innocent to a casual observer, while actually still being able to do its “job”
Get that changed landed in the master source code repository branch
The code needs to be included in a curl release that is used by the victim/target
These are not simple steps. The third step, getting into a release, is not strictly always necessary because there are sometimes people and organizations that run code off the bleeding edge master repository (against our advice I should add).
Writing the backdoor code
As was seen in this PHP attack, it failed rather miserably at step 1, making the attack code look innocuous, although we can suspect that maybe that was done so on purpose. In 2010 there was a lengthy discussion about an alleged backdoor in OpenBSD’s IPSEC stack that presumably had been in place for years and even while that particular backdoor was never proven to be real, the idea that it can be done certainly is.
Every time we fix a security problem in curl there’s that latent nagging question in the back of our collective minds: was this flaw placed here deliberately? Historically, we’ve not seen any such attacks against curl. I can tell this with a high degree of certainty since almost all of the existing security problems detected and reported in curl was done by me…!
The best attack code would probably do something minor that would have a huge impact in a special context for which the attacker has planned to use it. I mean minor as in doing a NULL-pointer dereference or doing a use-after-free or something. This, because doing a full-fledged generic stack based buffer overflow is much harder to land undetected. Maybe going with a single-byte overwrite outside of a malloc could be the way, like it was back in 2016 when such a flaw in c-ares was used as the first step in a multi-flaw exploit sequence to execute remote code as root on ChromeOS…
Ideally, the commit should also include an actual bug-fix that would be the public facing motivation for it.
Get that code landed in the repo
Okay let’s imagine that you have produced code that actually is a useful bug-fix or feature addition but with an added evil twist, and you want that landed in curl. I can imagine several different theoretical ways to do it:
A normal pull-request and land using the normal means
Tricking or forcing a user with push rights to circumvent the review process
Use a weakness somewhere and land the code directly without involving existing curl team members
The Pull Request method
I’ve never seen this attempted. Submit the pull-request to the project the usual means and argue that the commit fixes a bug – which could be true.
This makes the backdoor patch to have to go through all testing and reviews with flying colors to get merged. I’m not saying this is impossible, but I will claim that it is very hard and also a very big gamble by an attacker. Presumably it is a fairly big job just to get the code for this attack to work, so maybe going with a less risky way to land the code is then preferable? But then which way is likely to have the most reliable outcome?
The tricking a user method
Social engineering is very powerful. I can’t claim that our team is immune to that so maybe there’s a way an outsider could sneak in behind our imaginary personal walls and make us take a shortcut for a made up reason that then would circumvent the project’s review process.
We can even include more forced “convincing” such as direct threats against persons or their families: “push this code or else…”. This way of course cannot be protected against using 2fa, better passwords or things like that. Forcing a users to do it is also likely to eventually get known and then immediately make the commit reverted.
Tricking a user doesn’t make the commit avoid testing and scrutinizing after the fact. When the code has landed, it will be scanned and tested in a hundred CI jobs that include a handful of static code analyzers and memory/address sanitizers.
Tricking a user could land the code, but it can’t make it stick unless the code is written as the perfect stealth change. It really needs to be that good attack code to work out. Additionally: circumventing the regular pull-request + review procedure is unusual so I believe it is likely that such commit will be reviewed and commented on after the fact, and there might then be questions about it and even likely follow-up actions.
The exploiting a weakness method
A weakness in this context could be a security problem in the hosting software or even a rogue admin in the company that hosts the main source code git repo. Something that allows code to get pushed into the code repository without it being the result of one of the existing team members. This seems to be the method that the PHP attack was done through.
This is a hard method as well. Not only does it shortcut reviews, it is also done in the name of someone on the team who knows for sure that they didn’t do the commit, and again, the commit will be tested and poked at anyway.
For all of us who sign our git commits, detecting such a forged commit is easy and quickly done. In the curl project we don’t have mandatory signed commits so the lack of a signature won’t actually block it. And who knows, a weakness somewhere could even possibly find a way to bypass such a requirement.
The skip-git-altogether methods
As I’ve described above, it is really hard even for a skilled developer to write a backdoor and have that landed in the curl git repository and stick there for longer than just a very brief period.
If the attacker instead can just sneak the code directly into a release archive then it won’t appear in git, it won’t get tested and it won’t get easily noticed by team members!
curl release tarballs are made by me, locally on my machine. After I’ve built the tarballs I sign them with my GPG key and upload them to the curl.se origin server for the world to download. (Web users don’t actually hit my server when downloading curl. The user visible web site and downloads are hosted by Fastly servers.)
An attacker that would infect my release scripts (which btw are also in the git repository) or do something to my machine could get something into the tarball and then have me sign it and then create the “perfect backdoor” that isn’t detectable in git and requires someone to diff the release with git in order to detect – which usually isn’t done by anyone that I know of.
But such an attacker would not only have to breach my development machine, such an infection of the release scripts would be awfully hard to pull through. Not impossible of course. I of course do my best to maintain proper login sanitation, updated operating systems and use of safe passwords and encrypted communications everywhere. But I’m also a human so I’m bound to do occasional mistakes.
Another way could be for the attacker to breach the origin download server and replace one of the tarballs there with an infected version, and hope that people skip verifying the signature when they download it or otherwise notice that the tarball has been modified. I do my best at maintaining server security to keep that risk to a minimum. Most people download the latest release, and then it’s enough if a subset checks the signature for the attack to get revealed sooner rather than later.
The further-down-the-chain method
As an attacker, get into the supply chain somewhere else: find a weaker link in the chain between the curl release tarball and the target system for your attack . If you can trick or social engineer maybe someone else along the way to get your evil curl tarball to get used there instead of the actual upstream tarball, that might be easier and give you more bang for your buck. Perhaps you target your particular distribution’s or Operating System’s release engineers and pretend to be from the curl project, make up a story and send over a tarball to help them out…
Fake a security advisory and send out a bad patch directly to someone you know build their own curl/libcurl binaries?
Better ways?
If you can think of other/better ways to get malicious code via curl code into a victim’s machine, let me know! If you find a security problem, we will reward you for it!
Similarly, if you can think of ways or practices on how we can improve the project to further increase our security I’ll be very interested. It is an ever-moving process.
Dependencies
Added after the initial post. Lots of people have mentioned that curl can get built with many dependencies and maybe one of those would be an easier or better target. Maybe they are, but they are products of their own individual projects and an attack on those projects/products would not be an attack on curl or backdoor in curl by my way of looking at it.
In the curl project we ship the source code for curl and libcurl and the users, the ones that builds the binaries from that source code will get the dependencies too.
I spent a lot of time and effort digging up the numbers and facts for this post!
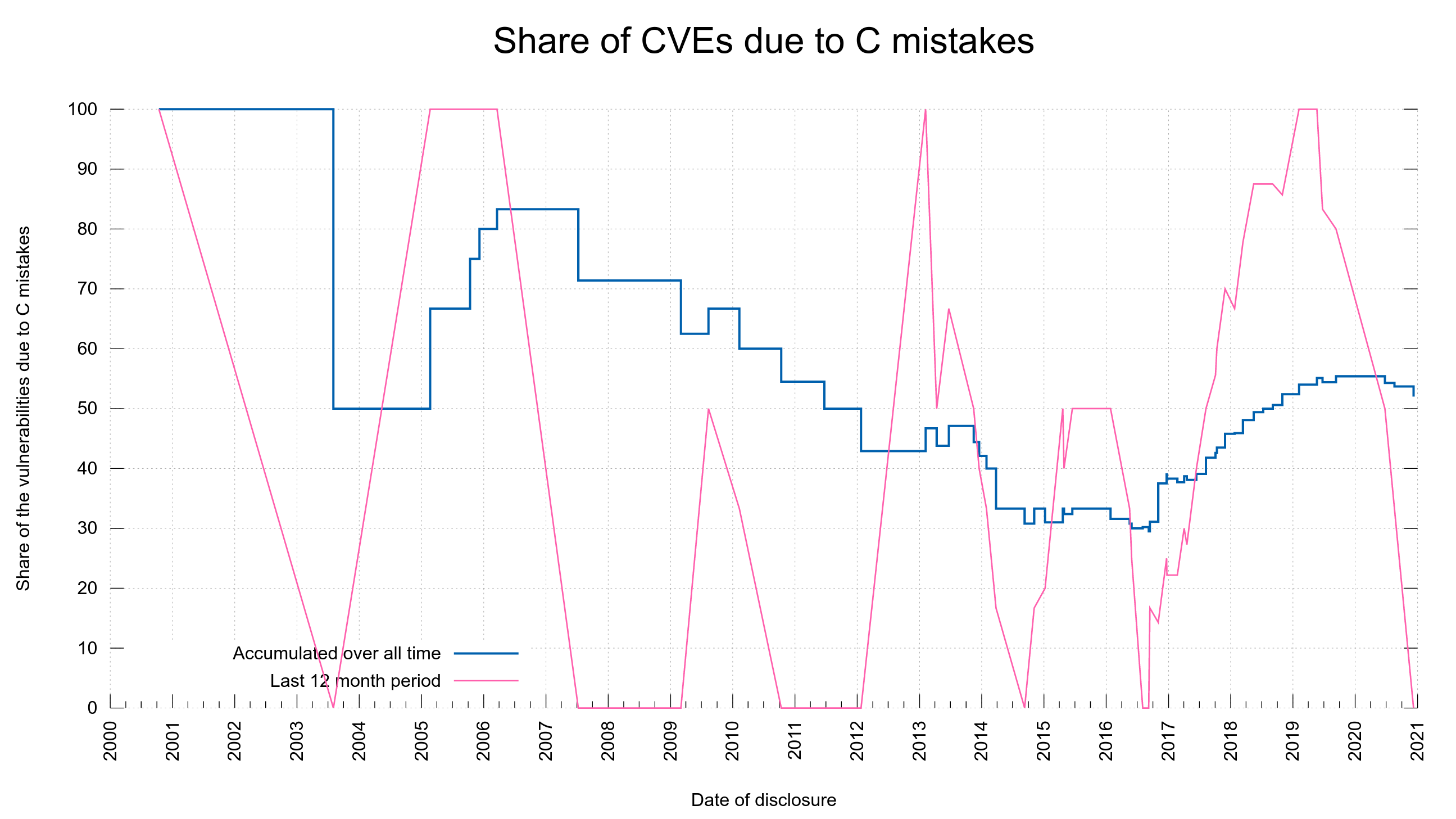
Lots of people keep referring to the awesome summary put together by a friendly pseudonymous “Tim” which says that “53 out of 95” (55.7%) security flaws in curl could’ve been prevented if curl had been written in Rust. This is usually in regards to discussions around how insecure C is and what to do about it. I’ve blogged about this topic before, but things change, the world changes and my own view on these matters keep getting refined.
I did my own count: how many of the current 98 published security problems in curl are related to it being written in C?
Possibly due to the slightly different question, possibly because I’ve categorized one or two vulnerabilities differently, possibly because I’m biased as heck, but my count end up at:
51 out of 98 security vulnerabilities are due to C mistakes
That’s still 52%. (you can inspect my analysis and submit issues/pull-requests against the vuln.pm file) and yes, 51 flaws that could’ve been avoided if curl had been written in a memory safe language. This contradicts what I’ve said in the past, but I will also show you below that the numbers have changed and I still was right back then!
Let me also already now say that if you check out the curl security section, you will find very detailed descriptions of all vulnerabilities. Using those, you can draw your own conclusions and also easily write your own blog posts on this topic!
This post is not meant as a discussion around how we can rewrite C code into other languages to avoid these problems. This is an introspection of the C related vulnerabilities in curl. curl will not be rewritten but will continue to support backends written in other languages.
It seems hard to draw hard or definite conclusions based on the CVEs and C mistakes in curl’s history due to the relatively small amounts to analyze. I’m not convinced this is data enough to actually spot real trends, but might be mostly random coincidences.
98 flaws out of 6,682
The curl changelog counts a total of 6,682 bug-fixes at the time of this writing. It makes the share of all vulnerabilities to be 1.46% of all known curl bugs fixed through curl’s entire life-time, starting in March 1998.
Looking at recent curl development: the last three years. Since January 1st 2018, we’ve fixed 2,311 bugs and reported 26 vulnerabilities. Out of those 26 vulnerabilities, 18 (69%) were due to C mistakes. 18 out of 2,311 is 0.78% of the bug-fixes.
We’ve not reported a single C-based vulnerability in curl since September 2019, but six others. And fixed over a thousand other bugs. (There’s another vulnerability pending announcement, a 99th one, to become public on March 31, but that is also not a C mistake.)
This is not due to lack of trying. We’re one of the few small open source projects that pays several hundred dollars for any reported and confirmed security flaw since a few years back.
The share of C based security issues in curl is an extremely small fraction of the grand total of bugs. The security flaws are however of course the most fatal and serious ones – as all bugs are certainly not equal.
But also: not all vulnerabilities are equal. Very few curl vulnerabilities have had a severity level over medium and none has been marked critical.
Unfortunately we don’t have “severity” noted for very many many of the past vulnerabilities, as we only started that practice in 2019 and I’ve spent time and effort to backtrack and fill them in for the 2018 ones, but it’s a tedious job and I probably will not update the remainder soon, if at all.
51 flaws due to C
Let’s dive in to see how they look.
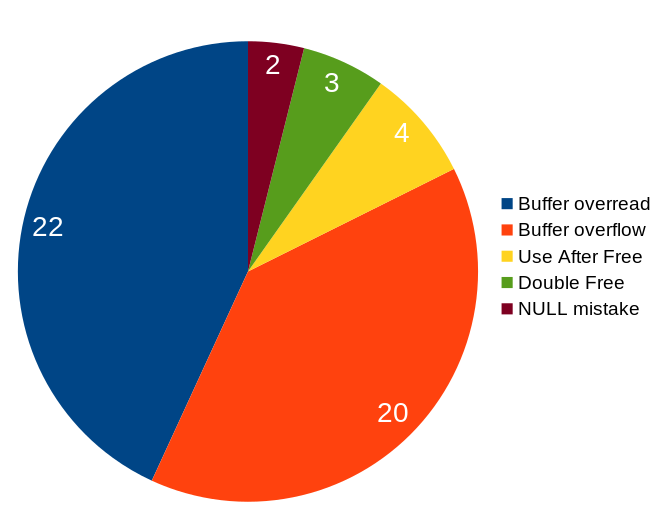
Here’s a little pie chart with the five different C mistake categories that have caused the 51 vulnerabilities. The categories here are entirely my own. No surprises here really. The two by far most common C mistakes that caused vulnerabilities are reading or writing outside a buffer.
Buffer overread – reading outside the buffer size/boundary. Very often due to a previous integer overflow.
Buffer overflow – code wrote more data into a buffer than it was allocated to hold.
Use after free – code used a memory area that had already been freed.
Double free – freeing a memory pointer that had already been freed.
NULL mistakes – NULL pointer dereference and NUL byte mistake.
Addressing the causes
I’ve previously described a bunch of the counter-measures we’ve done in the project to combat some of the most common mistakes we’ve done. We continue to enforce those rules in the project.
Two of the main methods we’ve introduced that are mentioned in that post, are that we have A) created a generic dynamic buffer system in curl that we try to use everywhere now, to avoid new code that handles buffers, and B) we enforce length restrictions on virtually all input strings – to avoid risking integer overflows.
Areas
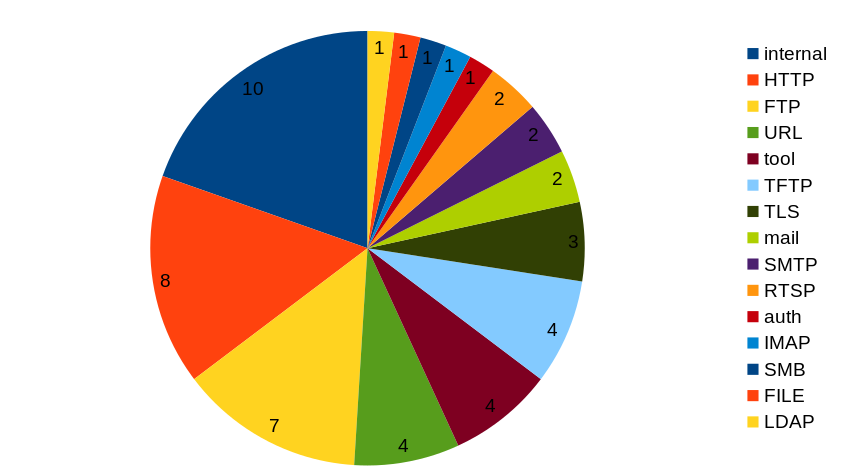
When I did the tedious job of re-analyzing every single security vulnerability anyway, I also assigned an “area” to each existing curl CVE. Which area of curl in which the problem originated or belonged. If we look at where the C related issues were found, can we spot a pattern? I think not.
“internal” being the number one area, which means that was in generic code that affected multiple protocols or in several cases even entirely protocol independent.
HTTP was the second largest area, but that might just also reflect the fact that it is the by far most commonly used protocol in curl – and there is probably the most amount of protocol-specific code for this protocol. And there were a total of 21 vulnerabilities reported in that area, and 8 out of 21 is 38% C mistakes – way below the total average.
Otherwise I think we can conclude that the mistakes were distributed all over, rather nondiscriminatory…
C mistake history
As curl is an old project now and we have a long history to look back at, we can see how we have done in this regard throughout history. I think it shows quite clearly that age hasn’t prevented C related mistakes to slip in. Even if we are experienced C programmers and aged developers, we still let such flaws slip in. Or at least we don’t find old such mistakes that went in a long time ago – as the reported vulnerabilities in the project have usually been present in the source code for many years at the time of the finding.
The fact is that we only started to take proper and serious counter-measures against such mistakes in the last few years and while the graph below shows that we’ve improved recently, I don’t think we yet have enough data to show that this is a true trend and not just a happenstance or a temporary fluke.
The blue line in the graph shows how big the accumulated share of all security vulnerabilities has been due to C mistakes over time. It shows we went below 50% totally in 2012, only to go above 50% again in 2018 and we haven’t come down below that again…
The red line shows the percentage share the last twelve months at that point. It illustrates that we have had several series of vulnerabilities reported over the years that were all C mistakes, and it has happened rather recently too. During the period one year back from the very last reported vulnerability, we did not have a single C mistake among them.
Finding the flaws takes a long time
C mistakes might be easier to find and detect in source code. valgrind, fuzzing, static code analyzers and sanitizers can find them. Logical problems cannot as easily be detected using tools.
I decided to check if this seems to be the case in curl and if it is true, then C mistakes should’ve lingered in the code for a shorter time until found than other mistakes.
I had a script go through the 98 existing vulnerabilities and calculating the average time the flaws were present in the code until reported, splitting out the C mistake ones from the ones not caused by C mistakes. It revealed a (small) difference:
C mistake vulnerabilities are found on average at 80% of the time other mistakes need to get found. Or put the other way around: mistakes that were not C mistakes took 25% longer to get reported – on average. I’m not convinced the difference is very significant. C mistakes are still shipped in code for 2,421 days – on average – until reported. Looking over the last 10 C mistake vulnerabilities, the average is slightly lower at 2,108 days (76% of the time the 10 most recent non C mistakes were found). Non C mistakes take 3,030 days to get reported on average.
Reproducibility
All facts I claim and provide in this blog post can be double-checked and verified using available public data and freely available scripts.
On February 11th, 2021 18:00 UTC (10am Pacific time, 19:00 Central Europe) we invite you to participate in a webinar we call “curl, Hyper and Rust”. To join us at the live event, please register via the link below:
https://www.wolfssl.com/isrg-partner-webinar/
What is the project about, how will this improve curl and Hyper, how was it done, what lessons can be learned, what more can we expect in the future and how can newcomers join in and help?
Participating speakers in this webinar are:
Daniel Stenberg. Founder of and lead developer of curl.
Josh Aas, Executive Director at ISRG / Let’s Encrypt.
The event went on for 60 minutes, including the Q&A session at the end.
Recording
Questions?
If you already have a question you want to ask, please let us know ahead of time. Either in a reply here on the blog, or as a reply on one of the many tweets that you will see about about this event from me and my fellow “webinarees”.
You might recall that my Twitter account was hijacked and then again just two weeks later.
The first: brute-force
The first take-over was most likely a case of brute-forcing my weak password while not having 2FA enabled. I have no excuse for either of those lapses. I had convinced myself I had 2fa enabled which made me take a (too) lax attitude to my short 8-character password that was possible to remember. Clearly, 2fa was not enabled and then the only remaining wall against the evil world was that weak password.
The second time
After that first hijack, I immediately changed password to a strong many-character one and I made really sure I enabled 2fa with an authenticator app and I felt safe again. Yet it would only take seventeen days until I again was locked out from my account. This second time, I could see how someone had managed to change the email address associated with my account (displayed when I wanted to reset my password). With the password not working and the account not having the correct email address anymore, I could not reset the password, and my 2fa status had no effect. I was locked out. Again.
It felt related to the first case because I’ve had my Twitter account since May 2008. I had never lost it before and then suddenly after 12+ years, within a period of three weeks, it happens twice?
Why and how
How this happened was a complete mystery to me. The account was restored fairly swiftly but I learned nothing from that.
Then someone at Twitter contacted me. After they investigated what had happened and how, I had a chat with a responsible person there and he explained for me exactly how this went down.
Had Twitter been hacked? Is there a way to circumvent 2FA? Were my local computer or phone compromised? No, no and no.
Apparently, an agent at Twitter who were going through the backlog of issues, where my previous hijack issue was still present, accidentally changed the email on my account by mistake, probably confusing it with another account in another browser tab.
There was no outside intruder, it was just a user error.
Okay, the cynics will say, this is what he told me and there is no evidence to back it up. That’s right, I’m taking his words as truth here but I also think the description matches my observations. There’s just no way for me or any outsider to verify or fact-check this.
A brighter future
They seem to already have identified things to improve to reduce the risk of this happening again and Michael also mentioned a few other items on their agenda that should make hijacks harder to do and help them detect suspicious behavior earlier and faster going forward. I was also happy to provide my feedback on how I think they could’ve made my lost-account experience a little better.
I’m relieved that the second time at least wasn’t my fault and neither of my systems are breached or hacked (as far as I know).
I’ve also now properly and thoroughly gone over all my accounts on practically all online services I use and made really sure that I have 2fa enabled on them. On some of them I’ve also changed my registered email address to one with 30 random letters to make it truly impossible for any outsider to guess what I use.
(I’m also positively surprised by this extra level of customer care Twitter showed for me and my case.)
Am I a target?
I don’t think I am. I think maybe my Twitter account could be interesting to scammers since I have almost 25K followers and I have a verified account. Me personally, I work primarily with open source and most of my works is already made public. I don’t deal in business secrets. I don’t think my personal stuff attracts attackers more than anyone else does.
What about the risk or the temptation for bad guys in trying to backdoor curl? It is after all installed in some 10 billion systems world-wide. I’ve elaborated on that before. Summary: I think it is terribly hard for someone to actually manage to do it. Not because of the security of my personal systems perhaps, but because of the entire setup and all processes, signings, reviews, testing and scanning that are involved.
So no. I don’t think my personal systems are a valued singled out target to attackers.