This was the title of my keynote at the Open Source Summit Europe 2025 conference in Amsterdam that I delivered on August 25, 2025.
The giants, as in fact large parts of modern infrastructure, stand on the shoulders of Open Source projects and their maintainers. But maybe these projects and people are not treated in optimal ways.
My slot allowed me 15 minutes and I completed my presentation with around two minutes left. I have rarely received so many positive comments as after this talk.
Credits
The painting in the top image, The Colossus (also known as The Giant), is traditionally attributed to Francisco de Goya but might actually have been made by his friend Asensio Juliá.
On Tuesday January 21st 2025, at 16:00 CET (15:00 UTC) I will do a presentation titled as per above. I have not done this one before.
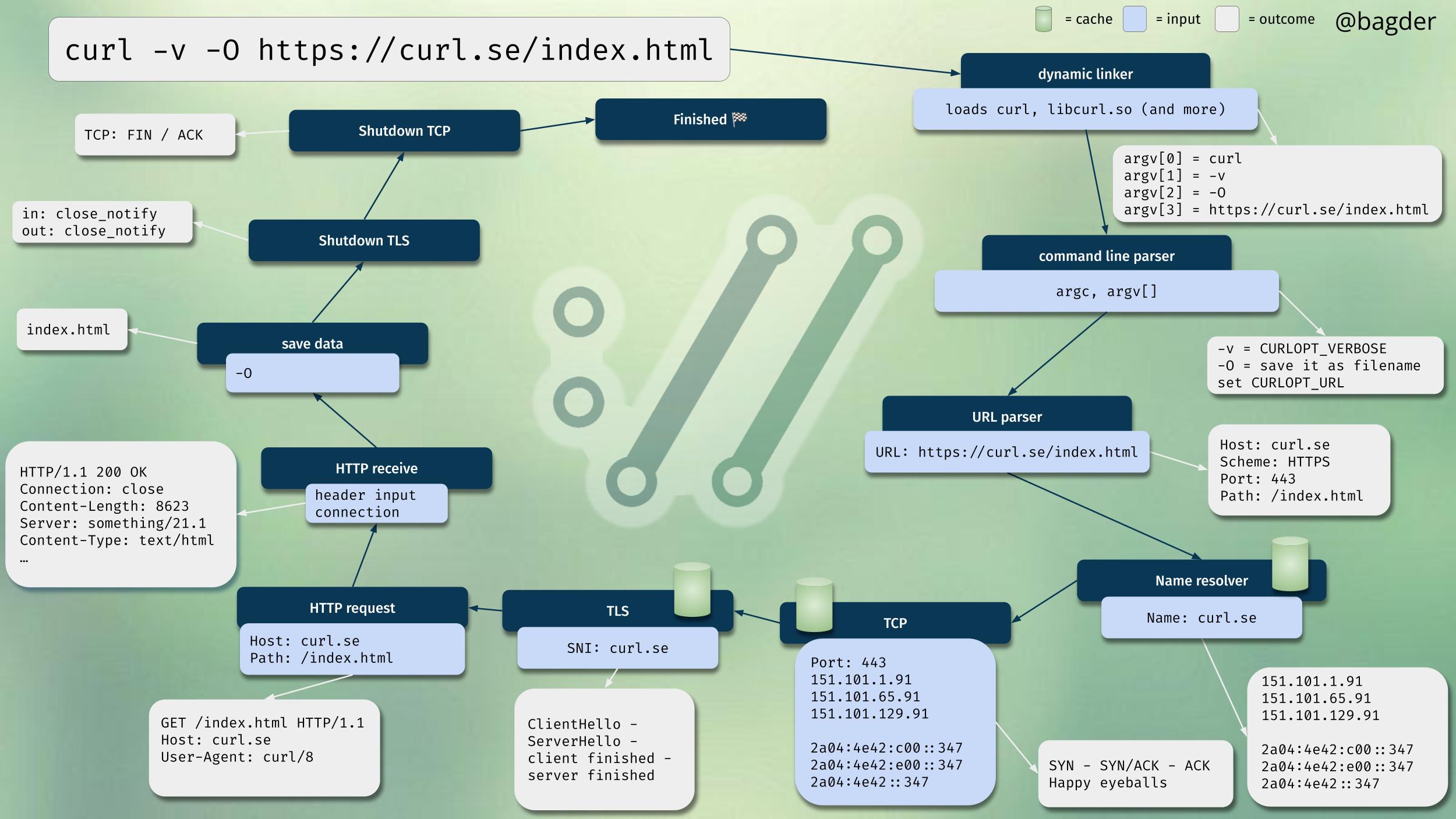
The talk will be a detailed explainer and step-by-step going through exactly what happens when a curl command line is typed into a shell and the return key is pressed. As the image below illustrates.
The talk will be live-streamed on twitch, and will be recorded and hosted on YouTube after the fact. For free of course, no signup. Just show up.
Those who join the live-stream chat can of course also ask questions live in the following Q&A.
On November 16 2023, I will do a multi-hour tutorial video on how to use libcurl. How to master it. As a follow-up to my previous video class called mastering the curl command line (at 13,000+ views right now).
This event will run as a live-stream webinar combination. You can opt to join via zoom or twitch. Zoom users can ask questions using voice, twitch viewers can do the same using the chat. For attending via Zoom you need to register, for twitch you can just show up.
It starts at 18:00 CET (09:00 PST, 17:00 UTC)
This session is part one of the planned two-part series. The amount of content is simply too much for me to deliver in a single sitting with intact quality. The second part will happen the following Monday, on November 20. Same time.
Both sessions will be recorded and will be made available for browsing after the fact.
At the time of me putting this blog post up the presentation and therefore agenda is not complete. I have also not yet figured out exactly how to do the split between the two episodes. Below you will find the planned topics that will be covered over the two episodes. Details will of course change in the final presentation.
The idea is that very little about developing with libcurl should be left out. This is the most thorough, most advanced, most in-depth libcurl video you ever saw. And it will be shock-full with source code examples. All examples that are shown in the video, are also provided stand-alone for easy browsing, copy and paste and later reading in a dedicated mastering libcurl GitHub repository.
I’ve watched how my thirteen year old son goes about to acquire information about things online. I am astonished how he time and time again deliberately chooses to get it from a video on YouTube rather than trying to find the best written documentation for whatever he’s looking for. I just have to accept that some people, even some descendants in my own family tree, prefer video as a source of information. And I realize he’s not alone.
My intent is to record a series of short and fairly independent episodes, each detailing a specific libcurl area. A particular “thing”, feature, option or area of the APIs. Each episode is also thoroughly documented and all the source code seen on the video is available on the site so that viewers can either follow along while viewing, or go back to the code afterward as a reference. Or both!
I’ve done the four first episodes so far, and they range from five minutes to nineteen minutes a piece. I expect that it might take me a while to just complete the list of episodes I could come up with myself. I also hope and expect that readers and viewers will think of other areas that I could cover so the list of video episodes could easily expand over time.
Feedback
If you have comments on the episodes. If you have suggestion of what to improve or subjects to cover, head over to the libcurl-video-tutorials github page and file an issue or two!
Video setup
I use a Debian Linux installation to develop on. I figure it should be similar enough to many other systems.
Video wise, in each episode I show you my text editor for code, a terminal window for building the code, running what we build in the episode and also for looking up man page information etc. And a small image of myself. Behind those three squares, there’s a photo of a forest (taken by me).
I plan to make each episode use the same basic visuals.
In the initial “setup” episode I create a generic Makefile, which we can reuse in several (all?) other episodes to build the example code easily and swiftly. I’ve previously learned that people consider Makefiles difficult, or sometimes even magic, to work with so I wanted to get that out of the way from the start and then focus more directly on actual C code that uses libcurl.
Receive data episode
Here’s the “receive data” episode as an example of how this can look.
At the Netnod spring meeting 2017 in Stockholm on the 5th of April I did a talk with the title of this post.
Why was HTTP/2 introduced, how well has HTTP/2 been deployed and used, did it deliver on its promises, where doesn’t HTTP/2 perform as well. Then a quick (haha) overview on what QUIC is and how it intends to fix some of the shortcomings of HTTP/2 and TCP. In 28 minutes.
On April 12 I had the pleasure of doing another talk in the Google Tech Talk series arranged in the Google Stockholm offices. I had given it the title “HTTP/2 is upon us, and here’s what you need to know about it.” in the invitation.
The room seated 70 persons but we had the amazing amount of over 300 people in the waiting line who unfortunately didn’t manage to get a seat. To those, and to anyone else who cares, here’s the video recording of the event.
If you’ve seen me talk about HTTP/2 before, you might notice that I’ve refreshed the material somewhat since before.
Challenge: you have 90 pictures of various sizes, taken in different formats and shapes. Using all sorts strange file names. Make a movie out of all of them, with the images using the correct aspect ratio. And add music. Use only command line tools on Linux.
Solution: this is a solution, you can most likely solve this in 22 other ways as well. And by posting it here, I can find it myself if I ever want to do the same stunt again…
#!/bin/sh
j=0
# convert options
pic="-resize 1920x1080 -background black -gravity center -extent 1920x1080"
# loop over the images
for i in `ls *jpg | sort -R`; do
echo "Convert $i"
convert $pic $i "pic-$j.jpg"
j=`expr $j + 1`
done
# now generate the movie
mp3="file.mp3"
echo "make movie"
ffmpeg -framerate 3 -i pic-%d.jpg -i $mp3 -acodec copy -c:v libx264 -r 30 -pix_fmt yuv420p -s 1920x1080 -shortest out.mp4
Explained
This is a shell script.
The ‘pic’ variable holds command line options for the ImageMagick ‘convert‘ tool. It resizes each picture to 1920×1080 while maintaining aspect ratio and if the pic gets smaller, it is centered and gets a black border.
The loop goes through all files matching *,jpg, randomizes the order with ‘sort’ and then runs ‘convert’ on them one by one and calls the output files pic-[number].jpg where number is increased by one for each image.
Once all images have the correct and same size, ‘ffmpeg‘ is invoked. It is told to produce a movie with 3 photos per second, how to find all the images, to include an mp3 file into the output and to stop encoding when one of the streams ends – this assumes the playing time of the mp3 file is longer than the total time the images are shown so the movie stops when we run out of images to show.
Result
The ‘out.mp4’ file, uploaded to youtube could then look like this: