The curl project’s source code has been hosted on GitHub since March 2010. I wrote a blog post in 2013 about what I missed from the service back then and while it has improved significantly since then, there are still features I miss and flaws I think can be fixed.
For this reason, I’ve created and now maintain a dedicated git repository with feedback “items” that I think could enhance GitHub when used by a project like curl:
The purpose of this repository is to allow each entry to be on-point and good feedback to GitHub. I do not expect GitHub to implement any of them, but the better we can present the case for every issue, the more likely I think it is that we can gain supporters for them.
What makes curl “special”
I don’t think curl is a unique project in the way we run and host it. But there are a few characteristics that maybe make it stand out a little from many other projects hosted on GitHub:
curl is written in C. It means it cannot be part of the “dependency” and related security checks etc that GitHub provides
we are git users but we are not GitHub exclusive: we allow participation in and contributions to the project without a GitHub presence
we are an old-style project where discussions, planning and arguments about project details are held on mailing lists (outside of GitHub)
we have strict ideas about how git commits should be done and how the messages should look like etc, so we cannot accept merges done with the buttons on the GitHub site
You can help
Feel free to help me polish the proposals, or even submit new ones, but I think they need to be focused and I will only accept issues there that I agree with.
In a world that is now gradually adopting HTTP/3 (which, as you know, is implemented over QUIC), the problem with the missing API for QUIC is still a key problem.
There are a number of existing QUIC library implementation now since a few years back, and they are slowly maturing. The QUIC protocol became RFC 9000 and friends, but the most popular TLS libraries still don’t provide the necessary APIs to make QUIC libraries possible to use them.
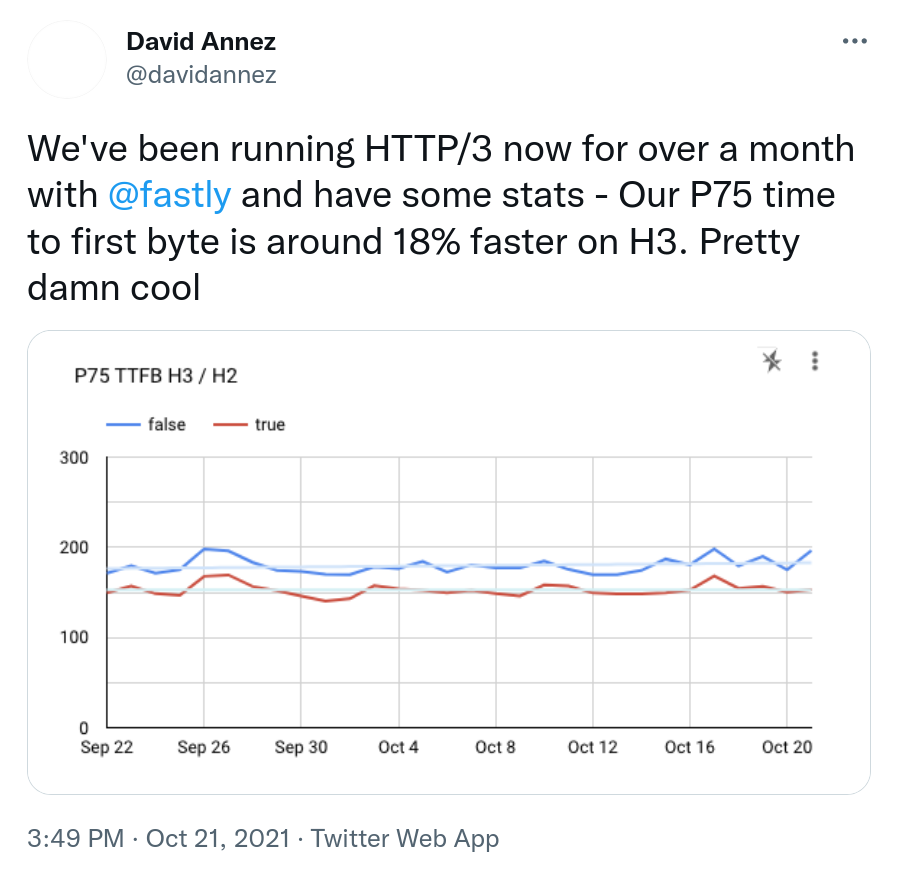
Example that makes people want HTTP/3
Example tweet of what makes people keen on experimenting and deploying HTTP/3.
OpenSSL PR8797
For a long time, many people and projects (including yours truly) in the QUIC community were eagerly following the OpenSSL Pull Request 8797, which introduced the necessary QUIC APIs into OpenSSL. This change brought the same API to OpenSSL that BoringSSL already provides and as such the API has already been used and tested out by several independent implementations.
Implementations have a problem to ship to the world based on BoringSSL since that’s a TLS library without versions and proper releases, so it is not a good choice for the big wide world. OpenSSL is already the most widely used TLS library out there and lots of applications are already made to use that.
Delays made quictls happen
The OpenSSL PR8797 was delayed back in February 2020 on when the OpenSSL management committee (OMC) decreed that they would not deal with that PR until after their pending 3.0.0 release had shipped.
“It is our expectation that once the 3.0 release is done, QUIC will become a significant focus of our effort.”
OpenSSL then proceeded and their 3.0.0 release was delayed significantly compared to their initial time schedule.
In March 2021, Microsoft and Akamai announcedquictls, an OpenSSL fork with the express idea to ship OpenSSL + the QUIC API. They didn’t want to wait for OpenSSL to do it.
Several QUIC libraries can now use quictls. quictls has kept their fork up to date and now offers the equivalent of OpenSSL 3.0.0 + the QUIC API.
While we’ve been waiting for OpenSSL to adopt the API.
OpenSSL makes a turn instead
Then came the next blow to everyone’s expectations. An autumn surprise. On October 13, the OpenSSL OMC announces:
The focus for the next releases is QUIC, with the objective of providing a fully functional QUIC implementation over a series of releases (2-3).
OpenSSL has decided to implement a complete QUIC stack on their own and with the given time line it sounds like it will take them a few years (?) to ship. And instead of providing the API lots of implementers have been been waiting for so long, they explicitly say that it is a non-goal at the start:
The MVP will not contain a library API for an HTTP/3 implementation (it is a non-goal of the initial release).
I didn’t write my own QUIC implementation but I’ve followed the work of several of the implementations fairly closely and it is fairly complicated journey they set out for themselves – for very unclear reasons. There already exist several high quality QUIC libraries, why does OpenSSL think they need to make yet another one? They seem to be overloaded with work already before, which the long delays of the 3.0.0 release seemed to show, how are they going to be able to add a complete new stack implementation of top of this? The future will tell.
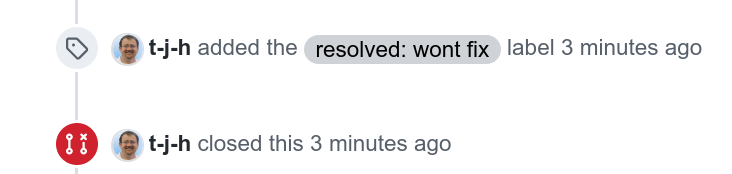
PR8797 closed
On October 20 2021, the pull request that was created in April 2019, is finally closed for real as a “won’t fix”.
Screenshot of the actual closing of the PR
Where are we now?
The lack of a QUIC API in OpenSSL has held us back and with this move from OpenSSL, it will continue to hold us back for an uncertain amount of time going forward.
QUIC stacks will have to stick to using or switching to other libraries.
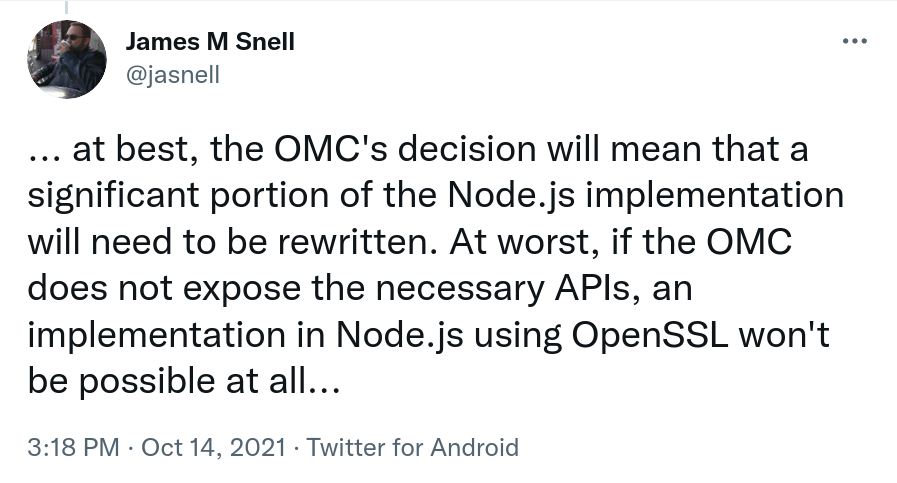
I’m disappointed.
James Snell, one of the key contributors on the QUIC and HTTP/3 work in nodejs tweeted:
I’ve previously said that curl is one of the most widely used software components in the world with its estimated over ten billion installations, and I’m getting questions about it every now and then.
— Is curl the most widely used software component in the world? If not, which one is?
We can’t know for sure which products are on the top list of the most widely deployed software components. There’s no method for us to count or estimate these numbers with a decent degree of certainty. We can only guess and make rough estimates – and it also depends on exactly what we count. And quite probably also depending on who‘s doing the counting.
First, let’s acknowledge that SQLite already hosts a page for mostly deployed software module, where they speculate on this topic (and which doesn’t even mention curl). Also, does this count number of devices running the code or number of installs? If we count devices, does virtual machines count? Is it the number of currently used installations or total number of installations done over the years?
Choices
The SQLite page suggests four contenders for the top-5 list and I think it is pretty good:
zlib (the original implementation)
libpng
libjpeg
sqlite
I will go out on a limb and say that the two image libraries in the list, while of course very widely used, are not typically used on devices without screens and in the IoT world of today, such devices are fairly common. Light bulbs, power switches, networking gear etc. I think it might imply that they are slightly less used than the others in the list. Secondarily, libjpeg seems to not actually be around, but there are a few other successors that are used? Ie not a single implementation.
All top components are Open Source (sqlite’s situation is special but they still call it open source), and I don’t think it is a coincidence.
Are there other contenders not mentioned here? I figure maybe some of the operating systems for the tiniest devices that ship in the billions could be there. But I’m not sure there’s any such obvious market dominant player. There are other compression libraries too, but I doubt they reach the levels of zlib at this moment.
Someone brings up the Linux kernel, which certainly is very well used, but all Android devices, servers, windows 10 etc probably don’t make the unit count go over 7 billion and I believe that in virtually all Linux these kernel installs, curl, zlib and sqlite also run…
Similarly to how SQLite forgot to mention curl, I might of course also have a blind eye for some other really well-used code block.
The finalists
We end up with three finalists:
zlib
sqlite
libcurl
I think it is impossible for us to rank these three in an order with any good certainty. If we look at that sqlite list of where it is used, we quickly recognize that zlib and libcurl are deployed in pretty much all of them as well. The three modules have a huge overlap and will all be installed in billions of devices, while of course there are also plenty that only install one or two of them.
I just can’t figure out the numbers that would rank these modules in the top-list.
The SQLite page says: our best guess is that SQLite is the second mostly widely deployed software library, after libz. They might of course be right. Or wrong. They also don’t specify or explain how they do that guess.
libc
Whenever I’ve mentioned widely used components in the past, someone has brought up “libc” as a contender. But since there are many different libc implementations and they are typically done for specific platforms/operating systems, I don’t think any single of the libc implementations actually reach the top-5 list.
zlib in curl/sqlite
Many people says zlib, partly because curl uses it, but then I have to add that zlib is an optional dependency for curl and I know many, including large volume, users that ship products with libcurl that doesn’t use zlib at all. One very obvious and public example, is the curl.exeshipped in Windows 10 – that’s maybe one billion installs of curl that don’t bundle zlib.
If I understand things correctly, the situation is similar in sqlite: it doesn’t always ship with a zlib dependency.
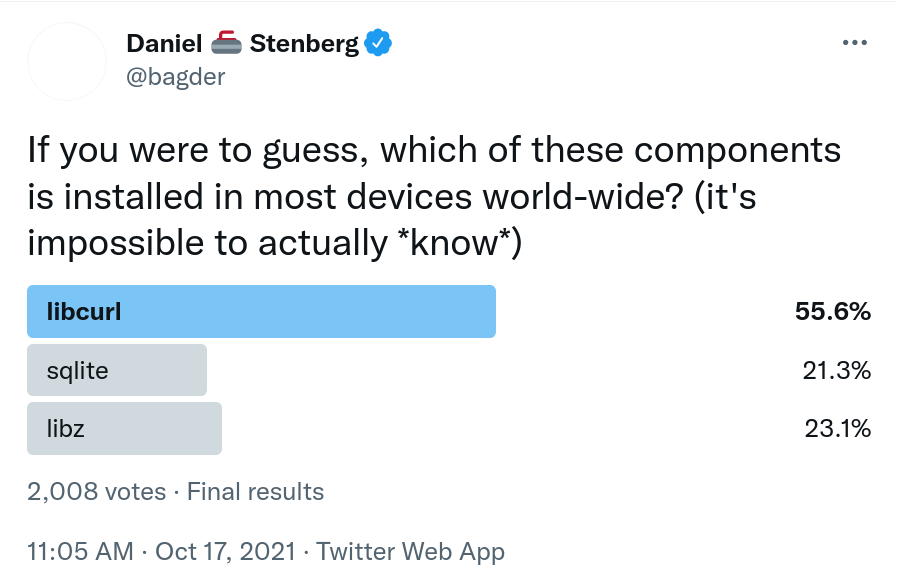
The poll
I asked my twitter followers which one of these three components they guess is the most widely used one. Very unscientifically and of course skewed towards libcurl (since I asked and I have a curl bias),
The over 2,000 respondents voted libcurl with a fairly high margin.
The datestamp shown in the image is when the poll went up and it was online for 24 hours.
What did I miss?
Did I miss a contender?
Have I overlooked some stats that make one of these win?
Updates: Since this was originally posted, I have had OpenSSL, expat and the Linux kernel proposed to me as additional finalists and possibly most-used components.
There’s this new TV-show on Swedish Television (SVT) called Hackad (“hacked” in English), which is about a team of white hat hackers showing the audience exactly how vulnerable lots of things, people and companies are and how they can be hacked using various means. In the show the hackers show how they hack into peoples accounts, their homes and their devices.
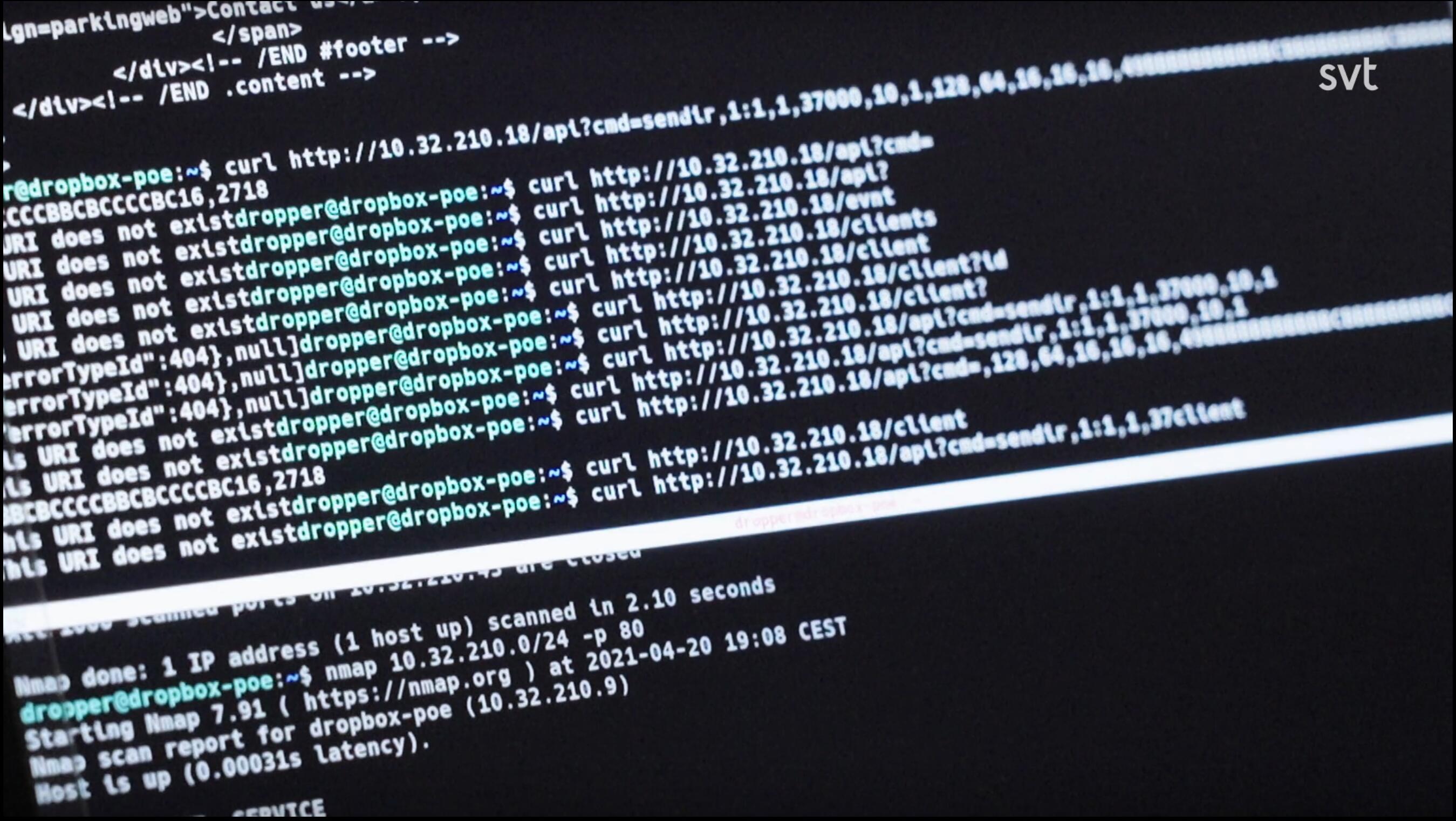
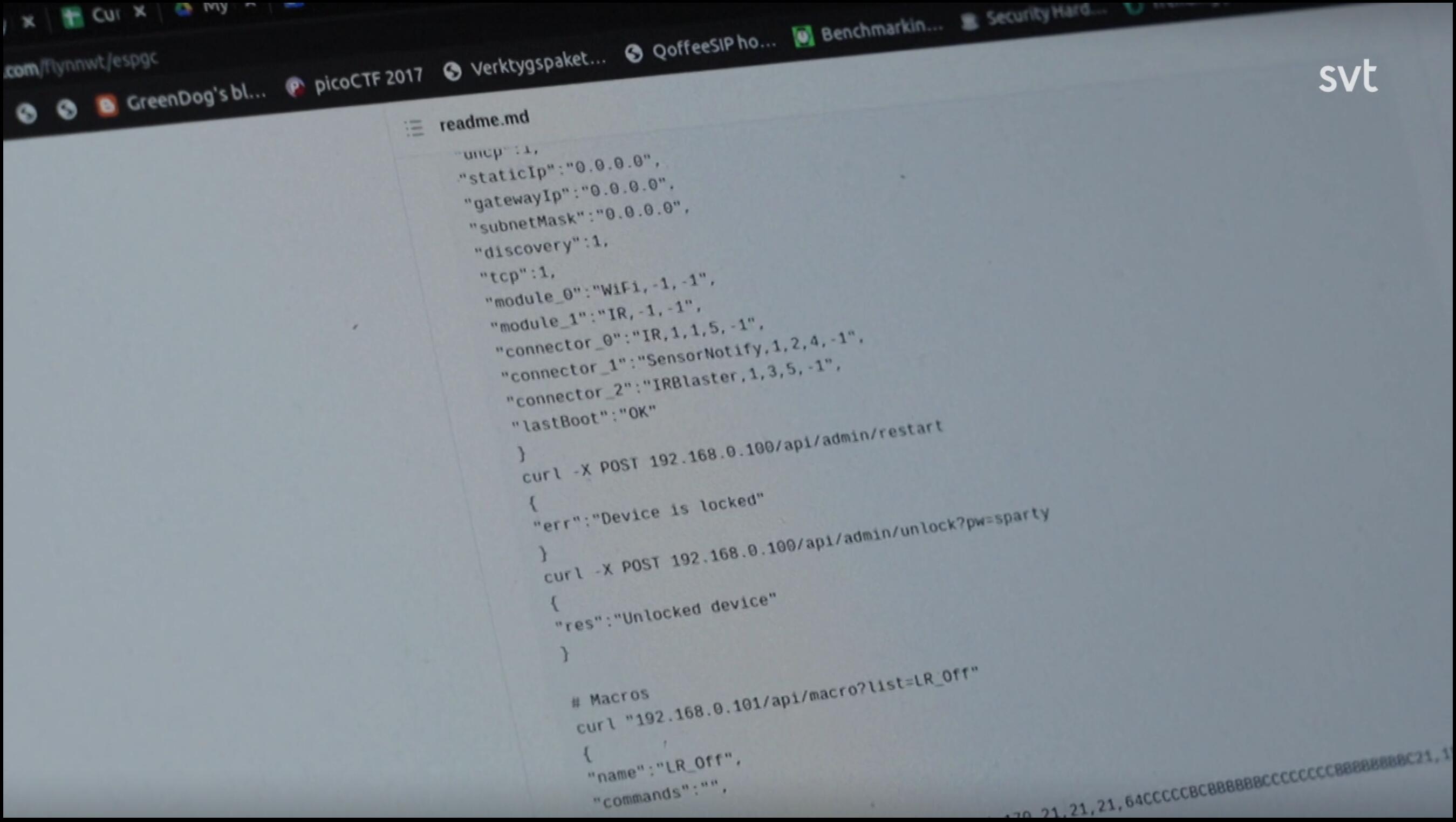
Generally this is done in a rather non-techy way as they mostly describe what they do in generic terms and not very specifically or with technical details. But in some short sequences the camera glances over a screen where source code or command lines are shown.
Similar to the fictional mr Robot, a readily available tool to use to accomplish what you want is of course… curl. In episode 4, we can easily spot curl command lines in several different shots.
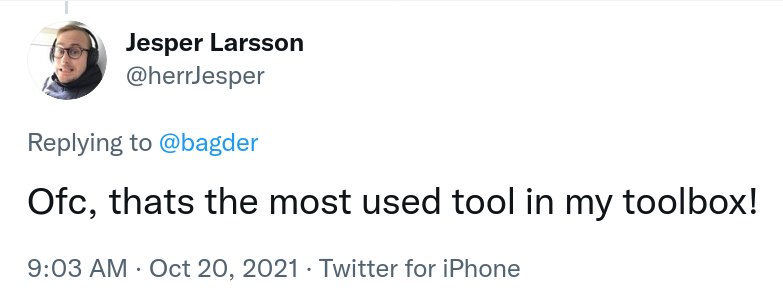
Jesper Larsson is one of the hackers in the show and he responded on this blog post about them using curl, on Twitter:
Screenshots from episode 4
Lots of curl command lines
Markdown document with embedded curl command lines
Another snap of the same document showing more curl
David’s laptop when outside the house, showing a number of curl command lines, slightly blurry.
I’ve joked with friends and said that we should have a competition to see whom among us have the largest number of curl installations in their homes. This is of course somewhat based on that I claim that there are more than ten billion curl installations in the world. That’s more installations than humans. How many curl installations does an average person have?
Amusingly, someone also asked me this question at curl presentation I did recently.
I decided I would count my own installations to see what number I could possibly come up with, ignoring the discussion if I’m actually could be considered “average” in this regard or not. This counting includes a few assumptions and estimates, but this isn’t a game we can play with complete knowledge. But no crazy estimates, just reasonable ones!
I decided to count my entire household’s amount just to avoid having to decide exactly which devices to include or not. I’m counting everything that is “used regularly” in my house (things that haven’t been used within the last 12 months don’t count). We’re four persons in my household. Me, my wife and my two teenage kids.
Okay. Let the game begin. This is the Stenberg household count of October, 2021.
Computer Operating Systems
4: I have two kids who have one computer each at home. One Windows 10 and one macOS. They also have one ChromeOS laptop each for school.
3: My wife has no less than three laptops with Windows 10 for work and for home.
3: I have three computers I use regularly. One Windows 10 laptop and two Debian Linuxes (laptop + desktop).
1: We have a Windows 10 NUC connected to the living room TV.
Subtotal: 11 full fledged computers.
Computer applications
Tricky. In the Linux machines, the curl installation is often shared by all users so just because I use multiple tools (like git) that use curl doesn’t increase the installation count. Presumably this is also the same for most macOS and ChromeOS apps.
On Windows however, applications that use libcurl use their own private build (as Windows itself doesn’t provide libcurl, only the curl tool) so they would count as additional installations. But I’m not sure how much curl is used in the applications my family use on Windows. I don’t think my son for example plays any of those games in which I know they use curl.
I do however have (I counted!) 8 different VMs installed in my two primary development machines, running Windows, Linux (various distros for curl testing) and FreeBSD and they all have curl installed in them. I think they should count.
Subtotal: 8 (at least)
Phone and Tablet Operating Systems
2: Android phones. curl is part of AOSP and seem to be shipped bundled by most vendor Androids as well.
1: Android tablet
2: iPhones. curl has been part of iOS since the beginning.
1: iOS tablet
Subtotal: 6
Phone and tablet apps
6 * 5: Youtube, Instagram. Spotify, Netflix, Google photos are installed in all of the mobile devices. Lots of other apps and games also use libcurl of course. I’ve decided to count low.
Subtotal: 30 – 40 yeah, the mobile apps really boost the amount.
TV, router, NAS, printer
1: an LG TV. This is tricky since I believe the TV operating system itself uses curl and I know individual apps do, and I strongly suspect they run their own builds so more or less every additional app on the TV run its own curl installation…
1: An ASUS wifi router I’m “fairly sure” includes curl
1: A Synology NAS I’m also fairly sure has curl
1: My printer/scanner is an HP model. I know from “sources” that pretty much every HP printer made has curl in them. I’m assuming mine does too.
Subtotal: 4 – 9
Potentials
I have half a dozen wifi-enabled powerplugs in my house but to my disappointment I’ve not found any evidence that they use curl.
I have a Peugeot e2008 (electric) car, but there are no signs of curl installed in it and my casual Google searches also failed me. This could be one of the rarer car brands/models that don’t embed curl? Oh the irony.
My Peugeot e2008
I have a Fitbit Versa 3 watch, but I don’t think it runs curl. Again, my googling doesn’t show any signs of that, and I’ve found no traces of my Ember coffee cup using curl.
My fridge, washing machine, dish washer, stove and oven are all “dumb”, not network connected and not running curl. Gee, my whole kitchen is basically curl naked.
We don’t have game consoles in the household so we’re missing out on those possible curl installations. I also don’t have any bluray players or dedicated set-top/streaming boxes. We don’t have any smart speakers, smart lightbulbs or fancy networked audio-players. We have a single TV, a single car and have stayed away from lots of other “smart home” and IoT devices that could be running lots of curl.
Subtotal: lots of future potential!
Score
11 + 8 + 6 + 30to40 + 4to9 = 59 to 74 CIPH (curl installations per household). If we go with the middle estimate, it means 66.
16.5 CIPC (curl installations per capita)
If the over 16 curl installations per person in just this household is an indication, I think it may suggest that my existing “ten billion installations” estimate is rather on the low side… If we say 10 is a fair average count and there are 5 billion Internet connected users, yeah then we’re at 50 billion installations…
Have you been curious about getting your feet wet with doing Internet transfers with libcurl but reasons (excuses?) have kept you away? Maybe it has felt as a too big step to take?
Fear not, on October 21 I’m doing a free webinar on Getting started with libcurl detailing useful first steps on how to get your initial application off the ground!
The half-hour presentation will include details such as:
Basic fundamentals in the libcurl API and a look on the common data types and concepts.
Setting up and understanding a first libcurl transfer.
Differences between the two primary libcurl transfer interfaces: easy and multi.
A look at the most commonly used libcurl options
Suggestions on how and where to take the next steps
The plan is to make this presentation work independently of platform, compiler and IDE choice and it will focus on C/C++ code. Still, since most libcurl bindings are very “thin” and often mimics the C API fairly closely, it should be valuable and provide good information even for you who plan to write your libcurl-using applications in other languages.
We’ll also end the session with a Q&A-part of course so queue up your questions!
The presentation will be recorded and made available after the fact.
Register
To participate on the live event, skip over and sign up for it.
The event will take place on October 21, 2021 at 10:00 PDT (check your time zone)
In the curl project we keep track of and say thanks to every single contributor. That includes persons who report bugs or security problems, who run infrastructure for us, who assist in debugging or fixing problems as well as those who author code or edit the website. Those who have contributed to make curl to what it is.
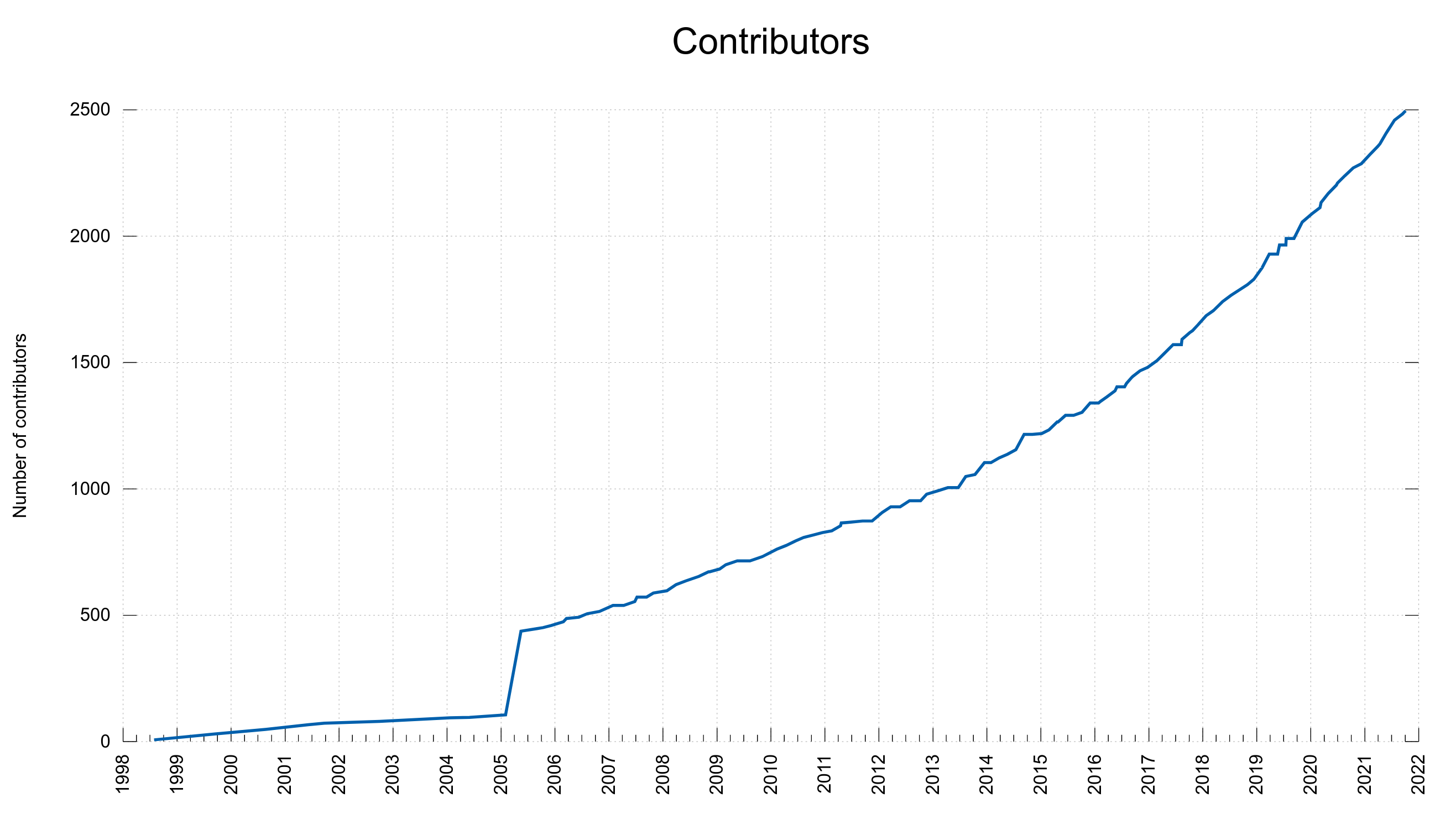
Exactly today October 4th 2021, we reached 2,500 names in this list of contributors for the first time. 2,500 persons since the day curl was created back in March 1998. 2,500 contributors in 8599 days. This means that on average we’ve seen one new contributor helping out in the project every 3.44 days for almost twenty-four years. Not bad at all.
The 2,500th recorded contributor was Ryan Mast who brought pull-request 7809.
Thank you everyone who have helped us so far!
As can be seen on the graph below plotting the number of people in the THANKS file, the rate of newcomers have increased slowly over the years and we’ve added new names at the rate of about two hundred per year recently. There’s a chance that we will add the next 2,500 names to the list faster than twenty-four years. The latest 1,000 contributors have been added since the beginning of 2017, so in less than five years.
2,500 contributors to curl
The thanks page on the website is usually synced at release time so it is always a little bit behind compared to what’s recorded in the curl git repository.
2005
The graph bump back in 2005: it was a one-time sweep-up where I went through our entire history and made sure that all names of people who were previously mentioned and who had helped were added correctly to the document. Since then, we’ve kept better track and make sure to add new names as we go along.
Scripting
We of course collect the names of the contributors primarily by the use of scripts, which is also the best way to avoid some slipping through.
We always mention contributors and helpers in git commits, and they should be “marked” correctly for scripts to be able to extract them
We keep a list of contributors per-release in the RELEASE-NOTES document. When we commit updates to RELEASE-NOTES, we use the fixed commit message ‘synced’ to have our tools use that as a marker.
To get the updated list of contributors since the previous update of RELEASE-NOTES, we use the scripts/contributors.sh script.
For some TLS connections you want the secrets you exchange over them to remain private for decades to come.
So what if someone in the future produces a computer system that can crack all the common current encryption algorithms in no time and they already have past secret communications stored?
Such a possible future computer system that might do this is believed to be the quantum computer. There are early and tiny versions of such machines already in existence, but they are far from strong enough to be cracking any strong ciphers today. The question is then how long it takes until they will be able to do that, and thus for how long recorded secret communications can expect to remain secret. 10 years? 20? 30?
If there’s a capable quantum computer made available in let’s say twenty years time, our currently most common TLS ciphers are then rendered next to worthless in twenty years. If you want your communication to remain private even after the introduction of quantum computers, you need post-quantum safe algorithms for your TLS data, and you need a post-quantum curl to use those ciphers for your transfers!
Post-quantum TLS
My colleagues at wolfSSL have recently been working on making sure that the library with the same name has support for a set of ciphers that are post-quantum safe. That work has been merged into wolfSSL’s git repository and will be part of a future pending release. That “future release” is hopefully just a few weeks off now.
In association with that, we’ve also made sure that curl built with wolfSSL can take advantage of these powers. The necessary curl changes for this have landed in git and will be part of the pending curl 7.80.0 release.
Use it with curl
To make your curl transfers post-quantum safe today, all you need to do is:
make sure you have a wolfSSL build and install with the proper algorithms enabled
build curl from git (or wait for the 7.80.0 release) and tell it to use wolfSSL for TLS
specify a post-quantum curve when you invoke curl
Example
curl --curve SABER_LEVEL5 https://example.com
The success of such a TLS 1.3 handshake with a server then of course also requires that you communicate with a server that conversely also supports quantum-safe algorithms. This is not terribly common yet.
Credits
The primary curl pull-request for this feature was authored by Anthony Hu.