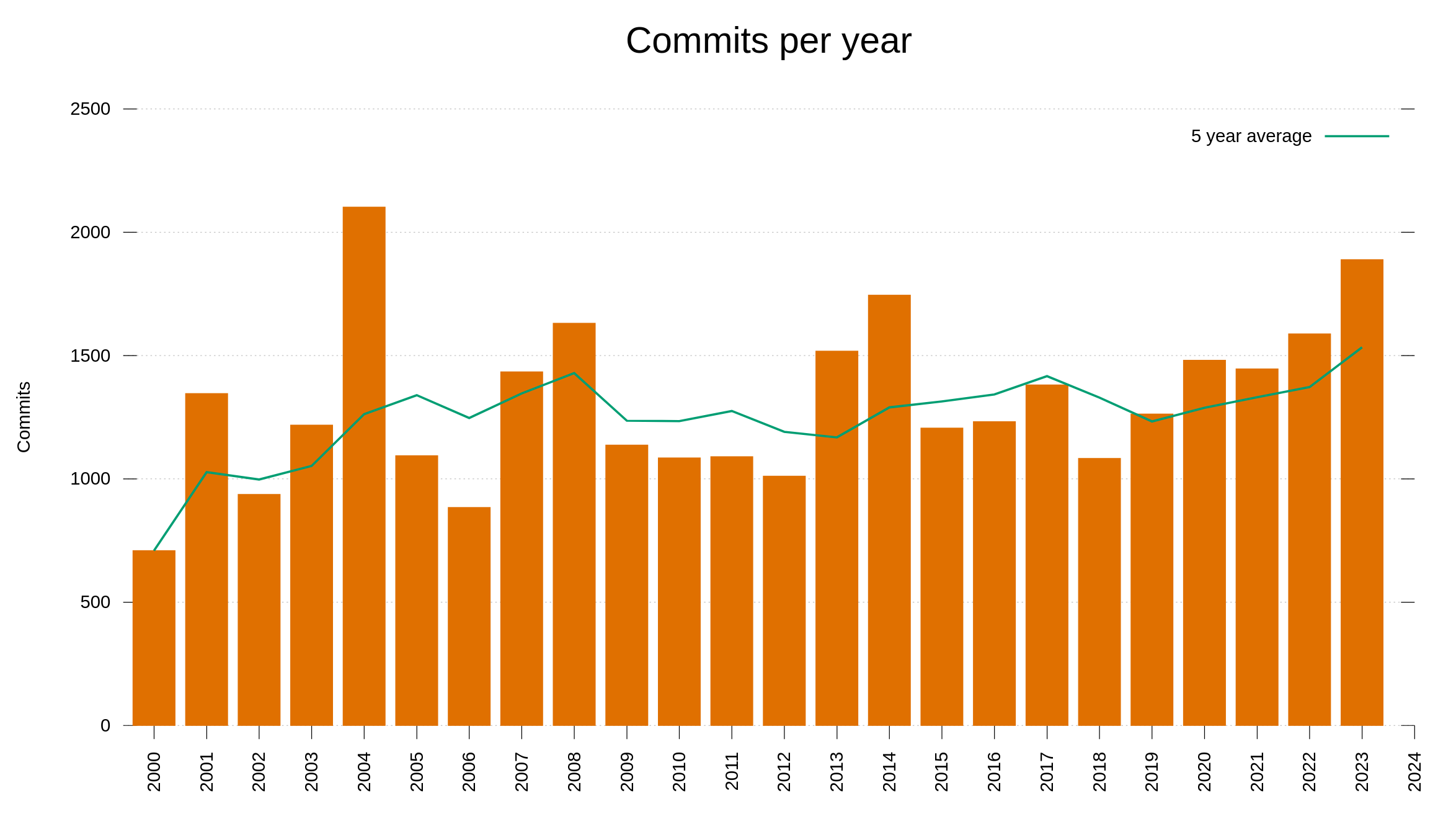
On December 21 2023 I started using this new keyboard as my daily driver. I have used my previous one almost daily since August 2014. Back in 2015 I counted doing almost 7 million key-presses/year. I don’t think I’ve typed any less since then. I rather think there are signs that I have typed a lot more since, especially since I started working full-time on curl in 2019. My estimate is thus that my trusted old keyboard has served over 70 million key-presses. And it has done it very well.
I did not want to comment on the keyboard too early, but I also did not want too long so that I forget about the little details a transition like this can bring up. I have averaged around 30,000 key strokes per day since I started using the new keyboard (I used keyfreq to figure this out). I also toyed around on keybr.com (where I reach 84 words/minute typing speed – with a fair amount of typos), to get a feel for how efficient I can possibly become on this thing. Seems okay!
Keyboards belongs in this annoying category of products that are really hard to figure out and get a proper feel for ahead of time even if you would be able to try them out before purchase. They pretty much require that we use them for a while before we can tell for sure we like them and want to stay with them many hours every day for the next several years.
Based on a recommendation from my brother Björn, I went with Logitech G915 TKL – tactile keys flavored. “Carbon” they call this color. It apparently also is available in white. Without a recommendation, I would not have considered this brand.

RGB Lights
This thing is branded a “gaming keyboard” and then of course the default keyboard RGB lightning effects consist of moving and changing colors across all the keys. There are 10 color style presets to select from, but the keyboard goes back to the default after idle timeouts, making the default mode really important. The factory default mode really screams hey look at me!, and is mostly disturbing to use.
I have read comments from Linux users online who even returned their G915 keyboards due to this crazy scheme not being possible to change properly on device, and the unfortunate truth is that I had to install their control software on a Windows box nearby to set a new default coloring mode: a solid single color on all keys – including that big G logo-symbol in the top left. Resetting back to this mode is fine. I appreciate some light on the keys, especially when using the keyboard at night.
It could perhaps also be mentioned that their control software on Windows, G Hub , while looking fancy, was not easy to figure out how to do this with.
I like that the lights on the keyboard go off completely after idling long enough, so that my workplace goes almost completely dark when left alone.
TKL
Ever since I got my previous keyboard I have been interested in a Ten Key Less (TKL) model. I never use any of those keys on the numerical part and I figured it could be good ergonomics to reduce the travel distance for my right hand when moving from keys to the mouse and back. A move that I must do hundreds if not thousands of times per day.
Wireless
This keyboard is wireless but it is not a feature I care about. I use this quite stationary at my desk within cable distance and I find rather use a cable than having to recharge the device.
Layout
I’m using the traditional Swedish QWERTY layout, which some people legitimately will mention is not optimal for development compared to US keyboard layouts. This would be because of what key combos you need to write for parentheses, braces, forward-slash etc. But since the Swedish language has these commonly used extra letters (Å, Ä and Ö) and we have been using this keyboard layout for a long time in this country, I am used to it and where ever you go on Sweden and find a keyboard, almost every one of them will use this layout. It is the path of least resistance.
I have never been a fan of the ergonomic keyboard styles and layouts. Probably because I never really allowed myself enough time to get used to them.
Media keys
With my previous keyboard I had to press Fn plus an F-key to do media control, while this new one has a set of dedicated media keys above the F-keys as you can see on the image above. I can also control the volume with the scroll wheel thing on the top right. Pretty convenient actually.
I have grown to appreciate having media control keys on the keyboard, and I find that having dedicated keys like this is a step up as it saves me from doing combo-presses frequently. A little less finger gymnastics.
Switches
Logitech does not seem to have a specific brand name for their switches. They offer the same keyboard with three different styles: linear, clicky or tactile. I went with tactile and I’m satisfied. The feel is not substantially different than my previous cherry reds.
Sound
I had Cherry MX Red switches in my previous keyboard, and this new one uses Logitech switches without any distinct name (that I could find). I did not have any particular problem with the noise level before but I hoped that this new one would perhaps be a little quieter. For the sake of family members when I type away on my keyboard when they are asleep and maybe to be less audible when I do video recordings etc. My home office and this keyboard setup is not far away from where they sleep.
I think maybe this keyboard is a little more silent, but not by much. I asked family members if they had noticed any difference in sound levels since my keyboard switch but none of them had noticed any change.
Size
Length: 368 mm
Width: 150 mm
Height: 22 mm
Weight: 810 g
The actual size of the keyboard and keys is almost identical to my previous keyboard, I mean when excluding the removed numerical keyboard. The weight of the G915 makes it feel solid and it sits firmly and fixated on the table reliably even during most my intense typing sessions. I suppose it is also good for wireless use as it won’t feel as “flimsy” as regular all-plastic wireless ones tend to feel. But I have not used it much in wireless mode.
Feeling
It feels solid and like it can survive being used daily for a long time.