
I sat down and talked curl, HTTP, HTTP/2, IETF, the web, Firefox and various internet subjects with Mattias Geniar on his podcast the syscast the other day.
Category Archives: Open Source
Open Source, Free Software, and similar
curl user survey results 2016
The annual curl user poll was up 11 days from May 16 to and including May 27th, and it has taken me a while to summarize and put together everything into a single 21 page document with all the numbers and plenty of graphs.
Full 2016 survey analysis document
The conclusion I’ve drawn from it: “We’re not done yet”.
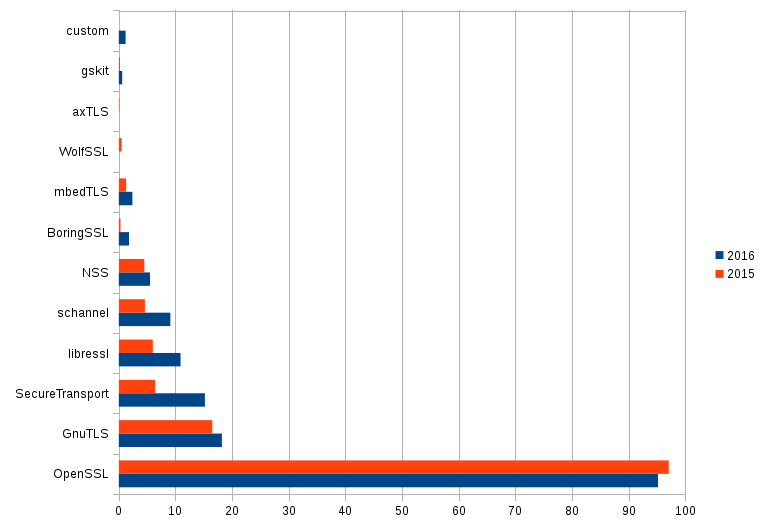
Here’s a bonus graph from the report, showing what TLS backends people are using with curl in 2016 and 2015:
No websockets over HTTP/2
There is no websockets for HTTP/2.
By this, I mean that there’s no way to negotiate or upgrade a connection to websockets over HTTP/2 like there is for HTTP/1.1 as expressed by RFC 6455. That spec details how a client can use Upgrade: in a HTTP/1.1 request to switch that connection into a websockets connection.
Note that websockets is not part of the HTTP/1 spec, it just uses a HTTP/1 protocol detail to switch an HTTP connection into a websockets connection. Websockets over HTTP/2 would similarly not be a part of the HTTP/2 specification but would be separate.
(As a side-note, that Upgrade: mechanism is the same mechanism a HTTP/1.1 connection can get upgraded to HTTP/2 if the server supports it – when not using HTTPS.)

Draft
There’s was once a draft submitted that describes how websockets over HTTP/2 could’ve been done. It didn’t get any particular interest in the IETF HTTP working group back then and as far as I’ve seen, there has been very little general interest in any group to pick up this dropped ball and continue running. It just didn’t go any further.
This is important: the lack of websockets over HTTP/2 is because nobody has produced a spec (and implementations) to do websockets over HTTP/2. Those things don’t happen by themselves, they actually require a bunch of people and implementers to believe in the cause and work for it.
Websockets over HTTP/2 could of course have the benefit that it would only be one stream over the connection that could serve regular non-websockets traffic at the same time in many other streams, while websockets upgraded on a HTTP/1 connection uses the entire connection exclusively.
Instead
So what do users do instead of using websockets over HTTP/2? Well, there are several options. You probably either stick to HTTP/2, upgrade from HTTP/1, use Web push or go the WebRTC route!
If you really need to stick to websockets, then you simply have to upgrade to that from a HTTP/1 connection – just like before. Most people I’ve talked to that are stuck really hard on using websockets are app developers that basically only use a single connection anyway so doing that HTTP/1 or HTTP/2 makes no meaningful difference.
Sticking to HTTP/2 pretty much allows you to go back and use the long-polling tricks of the past before websockets was created. They were once rather bad since they would waste a connection and be error-prone since you’d have a connection that would sit idle most of the time. Doing this over HTTP/2 is much less of a problem since it’ll just be a single stream that won’t be used that much so it isn’t that much of a waste. Plus, the connection may very well be used by other streams so it will be less of a problem with idle connections getting killed by NATs or firewalls.
The Web Push API was brought by W3C during 2015 and is in many ways a more “webby” way of doing push than the much more manual and “raw” method that websockets is. If you use websockets mostly for push notifications, then this might be a more convenient choice.
Also introduced after websockets, is WebRTC. This is a technique introduced for communication between browsers, but it certainly provides an alternative to some of the things websockets were once used for.
Future
Websockets over HTTP/2 could still be done. The fact that it isn’t done just shows that there isn’t enough interest.
Non-TLS
Recall how browsers only speak HTTP/2 over TLS, while websockets can also be done over plain TCP. In fact, the only way to upgrade a HTTP connection to websockets is using the HTTP/1 Upgrade: header trick, and not the ALPN method for TLS that HTTP/2 uses to reduce the number of round-trips required.
If anyone would introduce websockets over HTTP/2, they would then probably only be possible to be made over TLS from within browsers.
curl on windows versions
I had to ask. Just to get a notion of which Windows versions our users are actually using, so that we could get an indication which versions we still should make an effort to keep working on. As people download and run libcurl on their own, we just have no other ways to figure this out.
As always when asking a question to our audience, we can’t really know which part of our users that responded and it is probably more safe to assume that it is not a representative distribution of our actual user base but it is simply as good as it gets. A hint.
I posted about this poll on the libcurl mailing list and over twitter. I had it open for about 48 hours. We received 86 responses. Click the image below for the full res version:
 So, Windows 10, 8 and 7 are very well used and even Vista and XP clocked in fairly high on 14% and 23%. Clearly those are Windows versions we should strive to keep supported.
So, Windows 10, 8 and 7 are very well used and even Vista and XP clocked in fairly high on 14% and 23%. Clearly those are Windows versions we should strive to keep supported.
For Windows versions older than XP I was sort of hoping we’d get a zero, but as you can see in the graph we have users claiming to use curl on as old versions as Windows NT 4. I even checked, and it wasn’t the same two users that checked all those three oldest versions.
The “Other” marks were for Windows 2008 and 2012, and bonus points for the user who added “Other: debian 7”. It is interesting that I specifically asked for users running curl on windows to answer this survey and yet 26% responded that they don’t use Windows at all..
curl tshirts and hoodies
Ben Radler over at Teespring was awesome enough to put up a set of curl tshirts and hoodies sporting the new fancy logo.
Run over to https://teespring.com/curl-logo to order your own set!
Update: EU friends will appreciate the EU version of the curl logo tshirt shop!


On billions and “users”
At times when I’ve gone out (yes it happens), faced an audience and talked about my primary spare time project curl, I’ve said a few times in the past that we have one billion users.
Users?

OK, as this is open source I’m talking about, I can’t actually count my users and what really constitutes “a user” anyway?
If the same human runs multiple copies of curl (in different devices and applications), is that human then counted once or many times? If a single developer writes an application that uses libcurl and that application is used by millions of humans, is that one user or are they millions of curl users?
What about pure machine “users”? In the subway in one of the world’s largest cities, there’s an automated curl transfer being done for every person passing the ticket check point. Yet I don’t think we can count the passing (and unknowing) passengers as curl users…
I’ve had a few people approach me to object to my “curl has one billion users” statement. Surely not one in every seven humans on earth are writing curl command lines! We’re engineers and we’re picky with the definitions.
Because of this, I’m trying to stop talking about “number of users”. That’s not a proper metric for a project whose primary product is a library that is used by applications or within devices. I’m instead trying to assess the number of humans that are using services, tools or devices that are powered by curl. Fun challenge, right?
Who isn’t using?
 I’ve tried to imagine of what kind of person that would not have or use any piece of hardware or applications that include curl during a typical day. I certainly can’t properly imagine all humans in this vast globe and how they all live their lives, but I quite honestly think that most internet connected humans in the world own or use something that runs my code. Especially if we include people who use online services that use curl.
I’ve tried to imagine of what kind of person that would not have or use any piece of hardware or applications that include curl during a typical day. I certainly can’t properly imagine all humans in this vast globe and how they all live their lives, but I quite honestly think that most internet connected humans in the world own or use something that runs my code. Especially if we include people who use online services that use curl.
curl is used in basically all modern TVs, a large percentage of all car infotainment systems, routers, printers, set top boxes, mobile phones and apps on them, tablets, video games, audio equipment, Blu-ray players, hundreds of applications, even in fridges and more. Apple alone have said they have one billion active devices, devices that use curl! Facebook uses curl extensively and they have 1.5 billion users every month. libcurl is commonly used by PHP sites and PHP empowers no less than 82% of the sites w3techs.com has figured out what they run (out of the 10 million most visited sites in the world).
There are about 3 billion internet users worldwide. I seriously believe that most of those use something that is running curl, every day. Where Internet is less used, so is of course curl.
Every human in the connected world, use something powered by curl every day
Frigging Amazing
It is an amazing feeling when I stop and really think about it. When I pause to let it sink in properly. My efforts and code have spread to almost every little corner of the connected world. What an amazing feat and of course I didn’t think it would reach even close to this level. I still have hard time fully absorbing it! What a collaborative success story, because I could never have gotten close to this without the help from others and the community we have around the project.
But it isn’t something I think about much or that make me act very different in my every day life. I still work on the bug reports we get, respond to emails and polish off rough corners here and there as we go forward and keep releasing new curl releases every 8 weeks. Like we’ve done for years. Like I expect us and me to continue doing for the foreseeable future.
It is also a bit scary at times to think of the massive impact it could have if or when a really terrible security flaw is discovered in curl. We’ve had our fair share of security vulnerabilities so far through our history, but we’ve so far been spared from the really terrible ones.
So I’m rich, right?

If I ever start to describe something like this to “ordinary people” (and trust me, I only very rarely try that), questions about money is never far away. Like how come I give it away free and the inevitable “what if everyone using curl would’ve paid you just a cent, then…“.
I’m sure I don’t need to tell you this, but I’ll do it anyway: I give away curl for free as open source and that is a primary reason why it has reached to the point where it is today. It has made people want to help out and bring the features that made it attractive and it has made companies willing to use and trust it. Hadn’t it been open source, it would’ve died off already in the 90s. Forgotten and ignored. And someone else would’ve made the open source version and instead filled the void a curlless world would produce.
everybody runs this code all the time
I was invited to talk about curl at the recent FOSS North conference in Gothenburg on May 26th. It was the first time the conference ran, but I think it went smooth and the ~110 visitors seemed to have a good time. It was a single track and there was a fairly good and interesting mix of talkers and subjects I think. They’re already planning to make it return again in spring 2017, so if you’re into FOSS and you’re in the Nordic region, consider this event next year…
I took on the subject of talking about my hacker ring^W^Wcurl project insights. Here’s my slide set:
At the event I sat down and had a chat with Simon Campanello, a reporter at IDG Techworld here in Sweden who subsequently posted this article about curl (in Swedish) and how our code has ended up getting used so widely.

a new curl logo
The original logo for the curl project was created in 1998 by Henrik Hellerstedt. When we started version controlling the web site contents in June 2001 it had already been revised slightly and it looked like this
![]()
I subsequently did the slightly refreshed version that’s been visible on the site since early 2003 which sort of emphasized the look by squeezing the letters together. The general “cURL” look was obviously kept.

It was never considered a good-looking logo by anyone. People mostly at best thought it was cute because it looked goofy and it helped provide the web site with a sort of retro feeling. Something that was never intended.
(As you can see I shortened the tag line slightly between those two versions.)
Over the years I’ve tried to refresh the logo and even gently tried to ask around for help to get it revamped, but it was never done and my own futile attempts didn’t end up in any improvements.
The funny casing of the word cURL might’ve contributed to the fact that people considered it ugly. It came with the original naming of the project that was focused on the fact that we work with URLs. A client for URLs could be cURL. Or if you’d pronounce the c as “see”, you’d “see URL”. The casing is really only used in the logo these days. We just call it curl now. The project is curl, the command line tool is curl and even I have started to give up somewhat and have actually referred to libcurl as the curl library several times. “curl” with no upper case being the common denominator.
When I got this offer to refresh the logo this time, I was a bit skeptical since attempts had failed before, but what the heck, we had nothing to lose so sure, please help us!
We started out with their own free-style suggestions on a new logo. That proved these guys are good and have an esthetic sense for this. To me that first set also quite clearly showed me that the funny casing have to go. A lower case version seemed calmer, more modern and more in line with our current view of the naming.
As an example from their first set, a clean and stylish version that tried to use the letter c as a sort of symbol. Unfortunately it makes you mostly read “URL”.
![]()
As step two, I also suggested we’d try to work with :// (colon slash slash) somehow as a symbol, since after all the :// letter sequence is commonly used in all the URL formats that curl supports. And it is sort of a global symbol for URLs when you start to think about it. Made sense to me.
Their second set of logo versions were good. Really good. But they mostly focused on having the :// symbol to the left of ‘curl’ and that made it look a bit weird. Like “:// curl” – which looks so strange when you’re used to seeing URLs. They also did some attempts with writing it “c:URL” and having the // as part of the U letter like “c://RL” but those versions felt too crazy and ended more funny-looking than cool.
An example from the second set with a colon-slash-slash symbol on the left side:
![]()
The third set of logos were then made for us with various kinds of :// variations put on the right side of the curl, the curl in lowercase only.
There, among that third set of suggestions, there was one that was a notch better than the rest. The new curl logo. We made it.
I offer you: the curl logo of 2016.
![]()
Used in a real-life like situation:
![]()
and the plan is as this image shows, to be able to use the colon-slash-slash symbol stand-alone:
 The new curl logo is made by Soft Dreams. Thanks a lot for this stellar work!
The new curl logo is made by Soft Dreams. Thanks a lot for this stellar work!
curl user poll 2016
It is time for our annual survey on how you use curl and libcurl. Your chance to tell us how you think we’ve done and what we should do next. The survey will close on midnight (central European time) May 27th, 2016.
If you use curl or libcurl from time to time, please consider helping us out with providing your feedback and opinions on a few things:
http://goo.gl/forms/e4CoSDEKde
It’ll take you a couple of minutes and it’ll help us a lot when making decisions going forward. Thanks a lot!
The poll is hosted by Google and that short link above will take you to:
https://docs.google.com/forms/d/1JftlLZoOZLHRZ_UqigzUDD0AKrTBZqPMpnyOdF2UDic/viewform
My URL isn’t your URL

When I started the precursor to the curl project, httpget, back in 1996, I wrote my first URL parser. Back then, the universal address was still called URL: Uniform Resource Locators. That spec was published by the IETF in 1994. The term “URL” was then used as source for inspiration when naming the tool and project curl.
The term URL was later effectively changed to become URI, Uniform Resource Identifiers (published in 2005) but the basic point remained: a syntax for a string to specify a resource online and which protocol to use to get it. We claim curl accepts “URLs” as defined by this spec, the RFC 3986. I’ll explain below why it isn’t strictly true.
There was also a companion RFC posted for IRI: Internationalized Resource Identifiers. They are basically URIs but allowing non-ascii characters to be used.
The WHATWG consortium later produced their own URL spec, basically mixing formats and ideas from URIs and IRIs with a (not surprisingly) strong focus on browsers. One of their expressed goals is to “Align RFC 3986 and RFC 3987 with contemporary implementations and obsolete them in the process“. They want to go back and use the term “URL” as they rightfully state, the terms URI and IRI are just confusing and no humans ever really understood them (or often even knew they exist).
The WHATWG spec follows the good old browser mantra of being very liberal in what it accepts and trying to guess what the users mean and bending backwards trying to fulfill. (Even though we all know by now that Postel’s Law is the wrong way to go about this.) It means it’ll handle too many slashes, embedded white space as well as non-ASCII characters.
From my point of view, the spec is also very hard to read and follow due to it not describing the syntax or format very much but focuses far too much on mandating a parsing algorithm. To test my claim: figure out what their spec says about a trailing dot after the host name in a URL.
On top of all these standards and specs, browsers offer an “address bar” (a piece of UI that often goes under other names) that allows users to enter all sorts of fun strings and they get converted over to a URL. If you enter “http://localhost/%41” in the address bar, it’ll convert the percent encoded part to an ‘A’ there for you (since 41 in hex is a capital A in ASCII) but if you type “http://localhost/A A” it’ll actually send “/A%20A” (with a percent encoded space) in the outgoing HTTP GET request. I’m mentioning this since people will often think of what you can enter there as a “URL”.
The above is basically my (skewed) perspective of what specs and standards we have so far to work with. Now we add reality and let’s take a look at what sort of problems we get when my URL isn’t your URL.
So what is a URL?
Or more specifically, how do we write them. What syntax do we use.
I think one of the biggest mistakes the WHATWG spec has made (and why you will find me argue against their spec in its current form with fierce conviction that they are wrong), is that they seem to believe that URLs are theirs to define and work with and they limit their view of URLs for browsers, HTML and their address bars. Sure, they are the big companies behind the browsers almost everyone uses and URLs are widely used by browsers, but URLs are still much bigger than so.
The WHATWG view of a URL is not widely adopted outside of browsers.
colon-slash-slash
If we ask users, ordinary people with no particular protocol or web expertise, what a URL is what would they answer? While it was probably more notable years ago when the browsers displayed it more prominently, the :// (colon-slash-slash) sequence will be high on the list. Seeing that marks the string as a URL.
Heck, going beyond users, there are email clients, terminal emulators, text editors, perl scripts and a bazillion other things out there in the world already that detects URLs for us and allows operations on that. It could be to open that URL in a browser, to convert it to a clickable link in generated HTML and more. A vast amount of said scripts and programs will use the colon-slash-slash sequence as a trigger.
The WHATWG spec says it has to be one slash and that a parser must accept an indefinite amount of slashes. “http:/example.com” and “http:////////////////////////////////////example.com” are both equally fine. RFC 3986 and many others would disagree. Heck, most people I’ve confronted the last few days, even people working with the web, seem to say, think and believe that a URL has two slashes. Just look closer at the google picture search screen shot at the top of this article, which shows the top images for “URL” google gave me.
We just know a URL has two slashes there (and yeah, file: URLs most have three but lets ignore that for now). Not one. Not three. Two. But the WHATWG doesn’t agree.
“Is there really any reason for accepting more than two slashes for non-file: URLs?” (my annoyed question to the WHATWG)
“The fact that all browsers do.”
The spec says so because browsers have implemented the spec.
No better explanation has been provided, not even after I pointed out that the statement is wrong and far from all browsers do. You may find reading that thread educational.
In the curl project, we’ve just recently started debating how to deal with “URLs” having another amount of slashes than two because it turns out there are servers sending back such URLs in Location: headers, and some browsers are happy to oblige. curl is not and neither is a lot of other libraries and command line tools. Who do we stand up for?
Spaces
A space character (the ASCII code 32, 0x20 in hex) cannot be part of a URL. If you want it sent, you percent encode it like you do with any other illegal character you want to be part of the URL. Percent encoding is the byte value in hexadecimal with a percent sign in front of it. %20 thus means space. It also means that a parser that for example scans for URLs in a text knows that it reaches the end of the URL when the parser encounters a character that isn’t allowed. Like space.
Browsers typically show the address in their address bars with all %20 instances converted to space for appearance. If you copy the address there into your clipboard and then paste it again in your text editor you still normally get the spaces as %20 like you want them.
I’m not sure if that is the reason, but browsers also accept spaces as part of URLs when for example receiving a redirect in a HTTP response. That’s passed from a server to a client using a Location: header with the URL in it. The browsers happily allow spaces in that URL, encode them as %20 and send out the next request. This forced curl into accepting spaces in redirected “URLs”.
Non-ASCII
Making URLs support non-ASCII languages is of course important, especially for non-western societies and I’ve understood that the IRI spec was never good enough. I personally am far from an expert on these internationalization (i18n) issues so I just go by what I’ve heard from others. But of course users of non-latin alphabets and typing systems need to be able to write their “internet addresses” to resources and use as links as well.
In an ideal world, we would have the i18n version shown to users and there would be the encoded ASCII based version below, to get sent over the wire.
For international domain names, the name gets converted over to “punycode” so that it can be resolved using the normal system name resolvers that know nothing about non-ascii names. URIs have no IDN names, IRIs do and WHATWG URLs do. curl supports IDN host names.
WHATWG states that URLs are specified as UTF-8 while URIs are just ASCII. curl gets confused by non-ASCII letters in the path part but percent encodes such byte values in the outgoing requests – which causes “interesting” side-effects when the non-ASCII characters are provided in other encodings than UTF-8 which for example is standard on Windows…
Similar to what I’ve written above, this leads to servers passing back non-ASCII byte codes in HTTP headers that browsers gladly accept, and non-browsers need to deal with…
No URL standard
I’ve not tried to write a conclusive list of problems or differences, just a bunch of things I’ve fallen over recently. A “URL” given in one place is certainly not certain to be accepted or understood as a “URL” in another place.
Not even curl follows any published spec very closely these days, as we’re slowly digressing for the sake of “web compatibility”.
There’s no unified URL standard and there’s no work in progress towards that. I don’t count WHATWG’s spec as a real effort either, as it is written by a closed group with no real attempts to get the wider community involved.
My affiliation
I’m employed by Mozilla and Mozilla is a member of WHATWG and I have colleagues working on the WHATWG URL spec and other work items of theirs but it makes absolutely no difference to what I’ve written here. I also participate in the IETF and I consider myself friends with authors of RFC 1738, RFC 3986 and others but that doesn’t matter here either. My opinions are my own and this is my personal blog.