The forth season of my favorite HTTP series is back! The HTTP Workshop skipped over last year but is back now with a three day event organized by the very best: Mark, Martin, Julian and Roy. This time we’re in Amsterdam, the Netherlands.

35 persons from all over the world walked in the room and sat down around the O-shaped table setup. Lots of known faces and representatives from a large variety of HTTP implementations, client-side or server-side – but happily enough also a few new friends that attend their first HTTP Workshop here. The companies with the most employees present in the room include Apple, Facebook, Mozilla, Fastly, Cloudflare and Google – having three or four each in the room.
Patrick Mcmanus started off the morning with his presentation on HTTP conventional wisdoms trying to identify what have turned out as successes or not in HTTP land in recent times. It triggered a few discussions on the specific points and how to judge them. I believe the general consensus ended up mostly agreeing with the slides. The topic of unshipping HTTP/0.9 support came up but is said to not be possible due to its existing use. As a bonus, Anne van Kesteren posted a new bug on Firefox to remove it.
Mark Nottingham continued and did a brief presentation about the recent discussions in HTTPbis sessions during the IETF meetings in Prague last week.
Martin Thomson did a presentation about HTTP authority. Basically how a client decides where and who to ask for a resource identified by a URI. This triggered an intense discussion that involved a lot of UI and UX but also trust, certificates and subjectAltNames, DNS and various secure DNS efforts, connection coalescing, DNSSEC, DANE, ORIGIN frame, alternative certificates and more.
Mike West explained for the room about the concept for Signed Exchanges that Chrome now supports. A way for server A to host contents for server B and yet have the client able to verify that it is fine.
Tommy Pauly then talked to his slides with the title of Website Fingerprinting. He covered different areas of a browser’s activities that are current possible to monitor and use for fingerprinting and what counter-measures that exist to work against furthering that development. By looking at the full activity, including TCP flows and IP addresses even lots of our encrypted connections still allow for pretty accurate and extensive “Page Load Fingerprinting”. We need to be aware and the discussion went on discussing what can or should be done to help out.

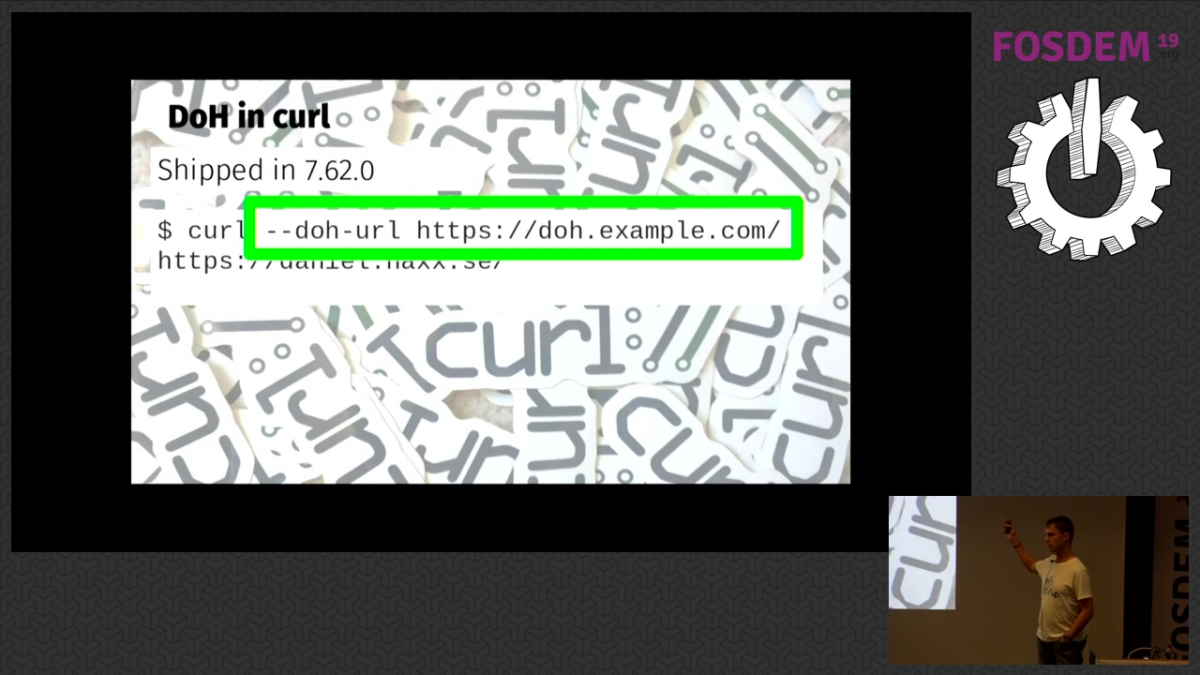
Lucas Pardue discussed and showed how we can do TLS interception with Wireshark (since the release of version 3) of Firefox, Chrome or curl and in the end make sure that the resulting PCAP file can get the necessary key bundled in the same file. This is really convenient when you want to send that PCAP over to your protocol debugging friends.
Roberto Peon presented his new idea for “Generic overlay networks”, a suggested way for clients to get resources from one out of several alternatives. A neighboring idea to Signed Exchanges, but still different. There was an interested to further and deepen this discussion and Roberto ended up saying he’d at write up a draft for it.
Max Hils talked about Intercepting QUIC and how the ability to do this kind of thing is very useful in many situations. During development, for debugging and for checking what potentially bad stuff applications are actually doing on your own devices. Intercepting QUIC and HTTP/3 can thus also be valuable but at least for now presents some challenges. (Max also happened to mention that the project he works on, mitmproxy, has more stars on github than curl, but I’ll just let it slide…)
Poul-Henning Kamp showed us vtest – a tool and framework for testing HTTP implementations that both Varnish and HAproxy are now using. Massaged the right way, this could develop into a generic HTTP test/conformance tool that could be valuable for and appreciated by even more users going forward.
Asbjørn Ulsberg showed us several current frameworks that are doing GET, POST or SEARCH with request bodies and discussed how this works with caching and proposed that SEARCH should be defined as cacheable. The room mostly acknowledged the problem – that has been discussed before and that probably the time is ripe to finally do something about it. Lots of users are already doing similar things and cached POST contents is in use, just not defined generically. SEARCH is a already registered method but could get polished to work for this. It was also suggested that possibly POST could be modified to also allow for caching in an opt-in way and Mark volunteered to author a first draft elaborating how it could work.
Indonesian and Tibetan food for dinner rounded off a fully packed day.
Thanks Cory Benfield for sharing your notes from the day, helping me get the details straight!
Diversity
We’re a very homogeneous group of humans. Most of us are old white men, basically all clones and practically indistinguishable from each other. This is not diverse enough!