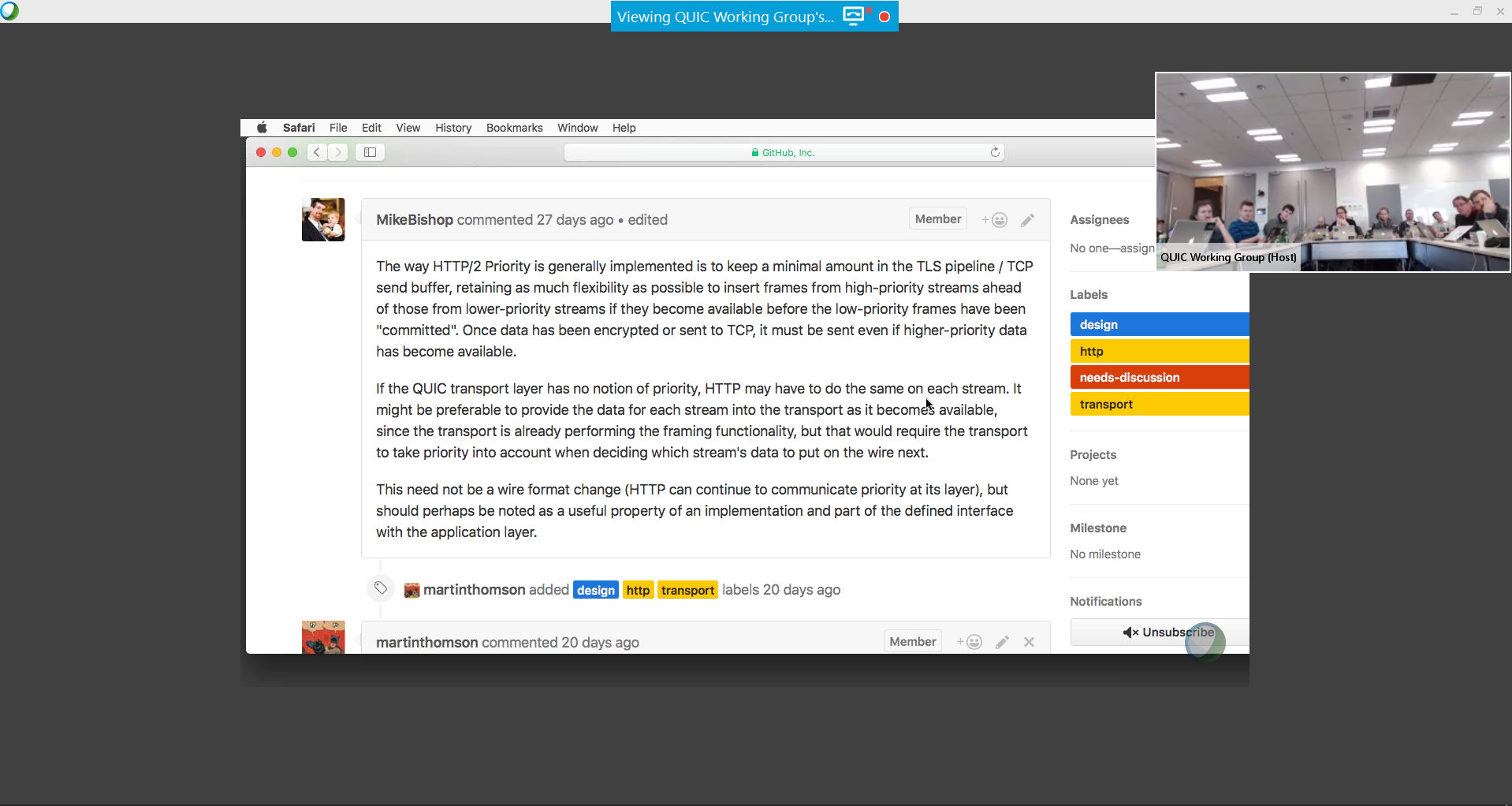
I’ve run my own public web sites on hardware I’ve administered myself for over twenty years now. I’ve hosted the curl web site myself since it’s inception.
The curl web site at curl.haxx.se has recently been delivering roughly 1.5 terabyte of data to the world per month. The CA bundle we convert to PEM from the Mozilla source code, is alone downloaded more than 100,000 times per day. Occasional blog entries I’ve posted here on my blog have climbed very fast on popular sites such as Hacker news and Reddit, and have resulted in intense visitor storms hitting this same server – sometimes reaching visitor counts above 200,000 “uniques” – most of them within the first few hours of the publication. At times, those visitor spikes have effectively brought the server to its knees.
Yes, my personal web site and the curl web site are both sharing the same physical server. It also hosts more than a dozen other sites and numerous services for our own pleasures and fun, providing services for a handful of different open source projects. So when the server has to cease doing work because it runs out of memory or hits other resource restraints, that causes interruptions all over. Oh yes, and my email doesn’t reach me.
Inconvenient and annoying.
The server
Haxx owns and runs this co-located server that we have a busload of web servers on – for the good of the projects and people that run things on it. This machine’s worst bottle neck is available RAM memory and perhaps I/O performance. Every time the server goes down to a crawl due to network traffic overload we discuss how we should upgrade it. Installing a new machine and transferring over all the sites and services is work. Work that none of us at Haxx are very happy to volunteer to do. So it hasn’t been done yet, and frankly the server handles the daily load just fine and without even a blink. Which is ninety nine point something percent of the time…
Haxx pays for a certain amount of network traffic so as long as we’re below some threshold we remain paying the same monthly fee. We don’t want to increase the traffic by magnitudes as that would cost more.
The specific machine, that sits deep inside a server room in Stockholm Sweden, is a five(?) years old Dell Poweredge E310, Intel Xeon X3440 2.53GHz with 8GB ram, This model is shown on the image at the top.
Alternatives that hasn’t helped
Why not a mirror system? We had a fair amount of curl site mirrors a few years ago, but it never worked well because they were always less reliable than the main site and they often turned stale and out of sync with the master site which eventually just hurt users.
They also trick visitors into bookmark or otherwise go back to the mirror site instead of the real one and there were always the annoying people who couldn’t resist but to fill the mirror with ads and stuff. Plus, they didn’t help much with with the storms to the main site.
Why not a cloud server? Because with the amount of services, servers and various things we do on our server, it would be inconvenient and expensive. But perhaps even more because we started out like this so we have invested time and energy into the infrastructure as it works right now. And I enjoy rowing my own boat!
The CDN
![]() Fastly reached out and graciously offered to help us handle the load. Both on the account of traffic amounts but also to save our machine from struggling this hard the next time I’ll write something that tickles people’s curiosity (or rage) to that level when several thousands of visitors want to read the same article at the same time.
Fastly reached out and graciously offered to help us handle the load. Both on the account of traffic amounts but also to save our machine from struggling this hard the next time I’ll write something that tickles people’s curiosity (or rage) to that level when several thousands of visitors want to read the same article at the same time.
Starting now, the curl.haxx.se and the daniel.haxx.se web sites are fronted by Fastly. It should give web site visitors from all over the world faster response times and it will make the site more reliable and less likely to have problems due to traffic load going forward.
In case you’re not familiar with what a CDN is, a simplified explanation would say it is a globally distributed network of reverse proxy servers deployed in multiple data centers. These CDN servers front the Internet and will to the largest extent possible serve the visitors with the right content directly from their own caches instead of them reaching the actual lowly backend server I run that hosts the original content. Fastly has lots of servers across the globe for this purpose. Users who are a long way away from Sweden will probably be the ones who will notice this change the most, as you may suddenly find haxx.se content much closer (network round-trip wise) than before.
Standards
These new servers will host the sites over HTTPS just like before, and they will require TLS 1.2 and SNI. They will work over IPv6 and support HTTP/2. Network standard wise, there shouldn’t be any step down – and honestly, I haven’t exactly been on the cutting edge of these technologies myself for these sites in the past.
Editing the site
We will keep editing and maintaining the site like before. It is made up of an old system with templates and include files that generate mostly static web pages. The site is mostly available on github and using that, you can build a local version for development and trying out changes before they land.
Hopefully, this move to Fastly will only make the site faster and more reliable. If you notice any glitches or experience any problems with the site, please let us know!


 I think more flaws in libcurl could’ve met the criteria, but I suspect more people than me haven’t been aware of this possibility for bounties.
I think more flaws in libcurl could’ve met the criteria, but I suspect more people than me haven’t been aware of this possibility for bounties.