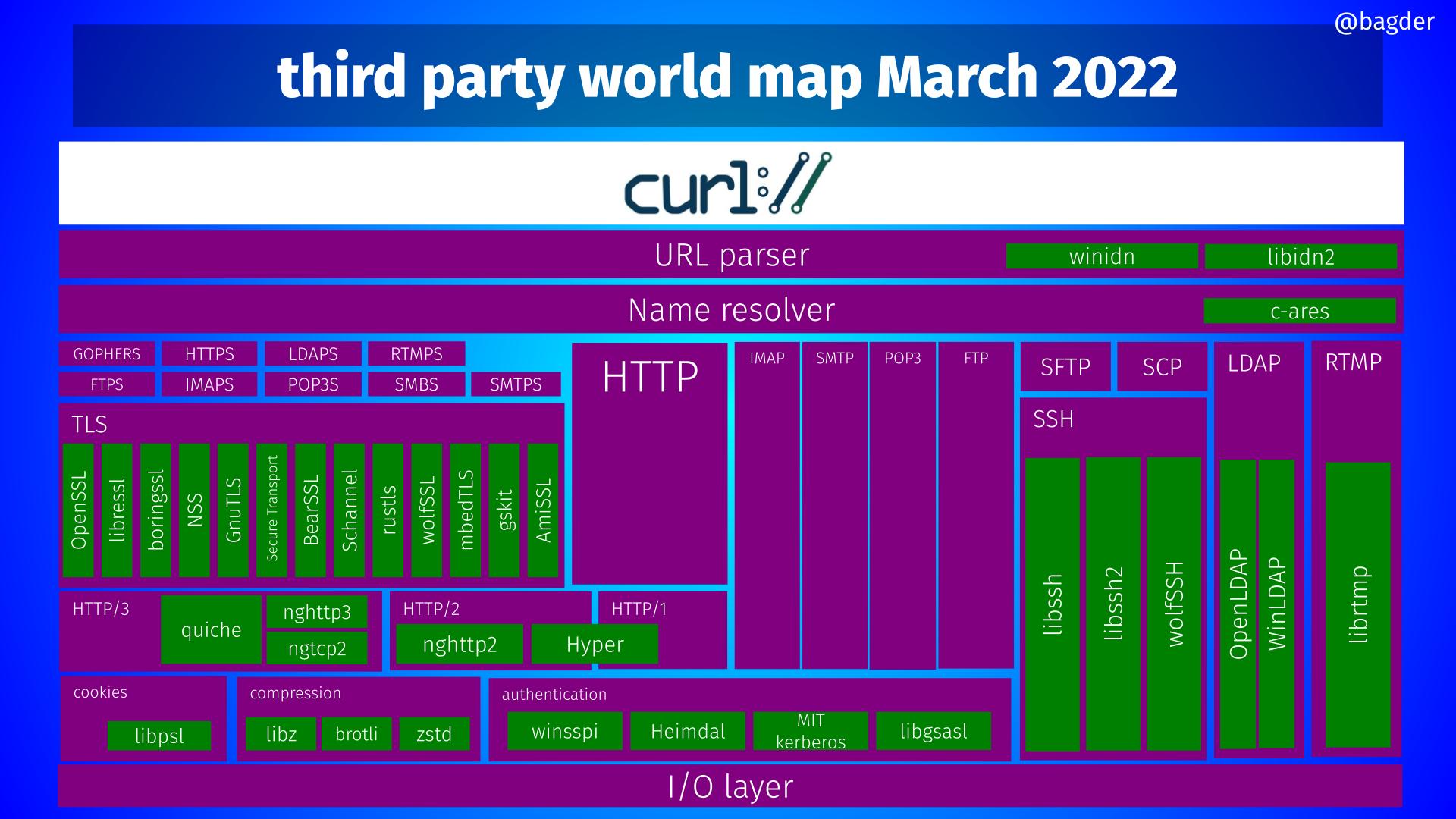
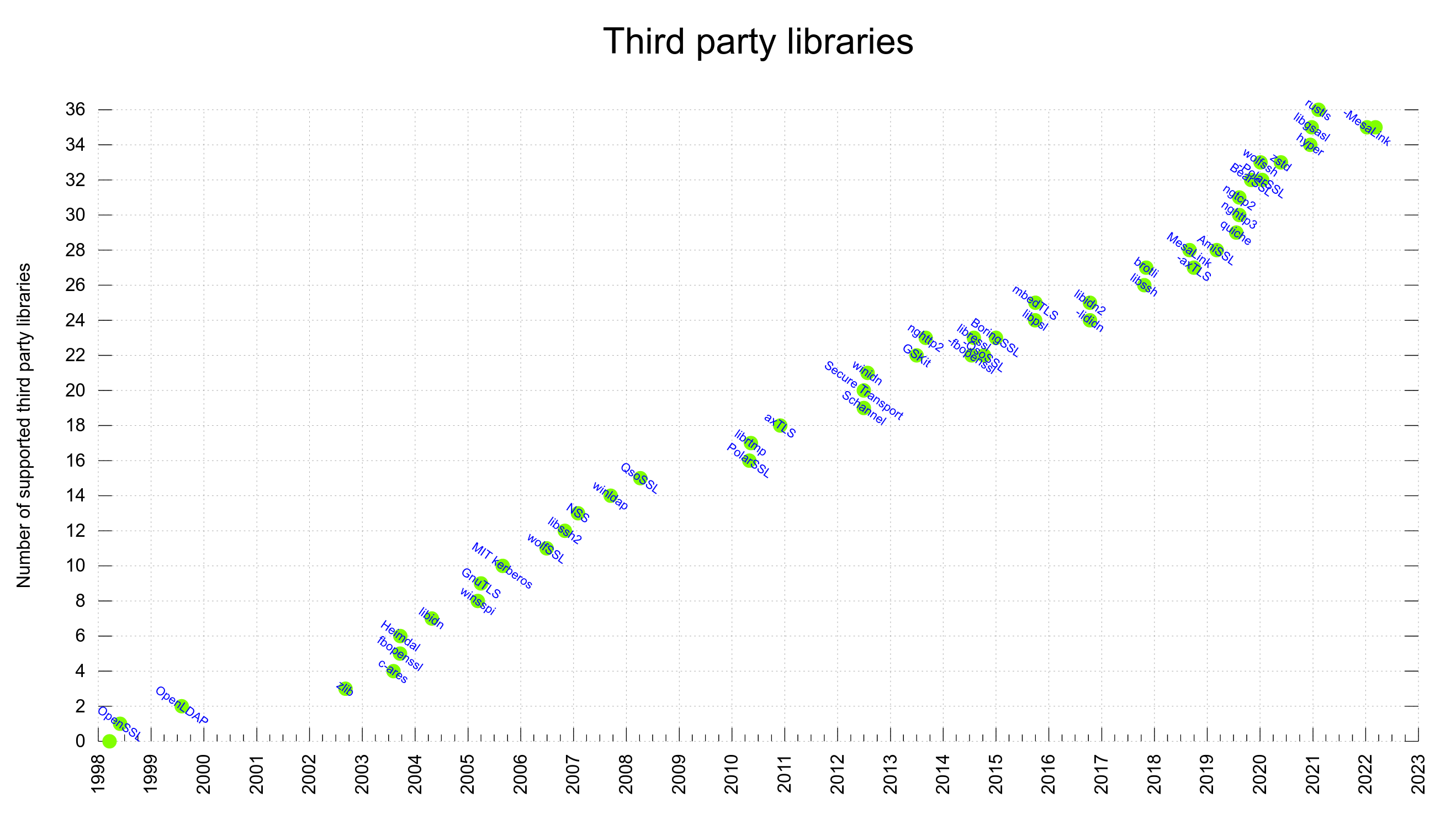
curl supports a large number of third party libraries. In a build, those libraries become “dependencies”. These components offer functionality and features that we don’t implement ourselves but still have been deemed interesting or even crucial to support to do Internet transfers the way we want.
A curl build done today can use one or more out of 35 different libraries. No build can actually use all of them at once as many are mutually exclusive and most of them only work on one or a subset of platforms.
Keeping our backyard tidy
Every now and then we learn that one of the 3rd party libraries we can build curl to use has ceased development or has in some other way started to decay into a state where we feel is no longer healthy to the level that we can no longer recommend our users to use it.
We do this as a service to our users. If users build curl with a dependency we support, I think we should at least have some rudimentary knowledge that the dependencies we help users to use are not terrible. It’s not a guarantee, but we try. To help strengthen the ecosystem. To sweep our own backyard.
Also, getting rid of old code is good.
Indirect dependencies
There are of course also indirect dependencies in the form of libraries our direct dependencies use (or even libraries the indirect used libraries use), and we try to also include them in the “package” when we consider dependencies, but especially if they are optional we need to put less attention on them.
What is a healthy dependency?
We have no automatic checks or even fixed set of rules or conditions to help us make this distinction. It would of course be cool to have that, but we don’t.
Ideally, it would be awesome if all dependencies would be top-rated on bestpractices, as that would greatly help us figure this out. But unfortunately too many projects are still not even added to that effort so this doesn’t work – plus we also support a number of proprietary dependencies that can’t be rated there.
Instead, we need to rely on old-fashioned human checks and asking users and maintainers.
Maybe not add it to begin with
We have declined to add functionality to curl in the past just because the proposed 3rd party dependency it would use just didn’t live up to our standards. I don’t mean that we need to raise the bar to ridiculous levels, but if a casual browsing of the 3rd party library found issues and there were not satisfying answers in a reasonable time on how those should be addressed, then that library is probably not ready to be used by curl. There’s no need to “lure” curl users into a possibly bad situation if we can save them from it.
Abandoned
Sometimes work officially stops on a library we support. That’s a strong sign we should also stop.
curl users actually using it
Since curl is being developed, extended and bug-fixed at a fairly high pace, we can be fairly sure that if a dependency is actually being used, it needs to get fixed every now and then to keep up. If support code for a dependency hasn’t been updated or touched for many years, there’s a strong suspicion that there aren’t many users of it in modern curl.
Sometimes that can be verified to be the case when we notice a blatant bug that’s been present in the code for a good while without anyone noticing, but more often we need to ask users. Anyone using this anymore? (Which also is complicated because we often lack connections to users who don’t read any of our mailing lists and generally only upgrade curl once every decade so it might take a while until those users notice changes…)
Releases
A dependency that has stopped making new releases can be a signal that it on its way downwards. It could also be a sign that it has matured and doesn’t need much more to be done to it.
How do we even know they stopped? Maybe they just take forever from the previous release…
Developer activity
A library that is used by curl is almost required to have some level of developer activity over time. Nobody writes bug-free code unless its scope is razor-sharp-narrow and the project spent a lot of time perfecting it. No commits or developer activity for a long time means that clearly nobody takes care of the bug reports.
Slowly deteriorating projects are probably the hardest to handle. Are they still good enough?
Maintainers ultimately decide
But we just ship source code.
In the end of the day, the people who package curl or libcurl decide what third party libraries to actually get used. They are the ones who decide what dependencies users of their build rely on. In many cases this means the maintainers of the curl packages in Linux distros and other operating systems. Manufacturers of devices and tools that use libcurl often build their own and then they can decide and cherry-pick individually between all provided choices.
This makes it possible for such maintainers to add extra conditions and checks and only go with the dependencies they like.
The only binary packages the curl project itself provides, are the ones for Windows, and we try to go with only solid, reliable and conservative choices for those.