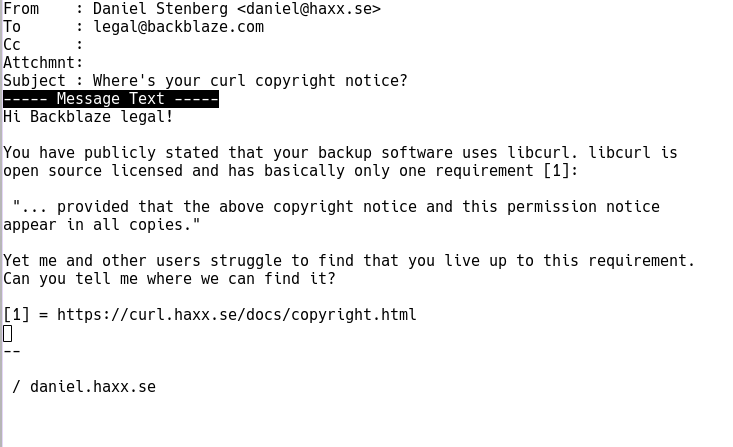
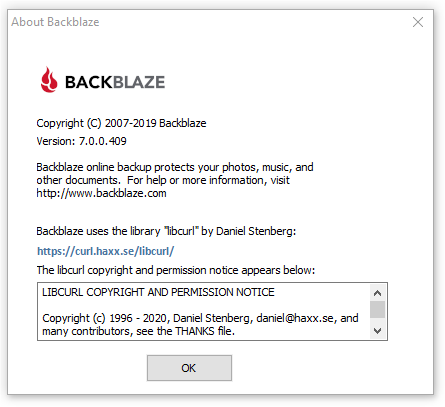
Remember Rockbox? It is a free software firmware replacement for mp3 players. I co-founded the project back in 2001 together with Björn and Linus. I officially left the project back in 2014.
The project is still alive today, even of course many of us can’t hardly remember the concept of a separate portable music player and can’t figure out why that’s a good idea when we carry around a powerful phone all days anyway that can do the job – better.
Already when the project took off, we at Haxx hosted the web site and related services. Heck, if you don’t run your own server to add fun toy projects to, then what kind of lame hacker are you?
None of us in Haxx no longer participates in the project and we haven’t done so for several years. We host the web site, we run the mailing lists, we take care of the DNS, etc.
Most of the time it’s no biggie. The server hosts a bunch of other things anyway for other project so what is a few extra services after all?
Then there are times when things stop working or when we get a refreshed bot attack or web crawler abuse against the site and we get reminded that here we are more than eighteen years later hosting things and doing work for a project we don’t care much for anymore.
It doesn’t seem right anymore. We’re pulling the plug on all services for Rockbox that occasionally gives us work and annoyances. We’re offering to keep hosting DNS and the mailing lists – but if active project members rather do those too, feel free. It never was a life-time offer and the time has come for us.
If people still care for the project, it is much better if those people will also care for these things for the project’s sake. And today there are more options than ever for an open source project to get hosting, bug tracking, CI systems etc setup for free with quality. There’s no need for us ex-Rockboxers to keep doing this job that we don’t want to do.
I created a wiki page to detail The Transition. We will close down the specified services on January 1st 2021 but I strongly urge existing Rockboxers to get the transition going as soon as possible.
I’ve also announced this on the rockbox-dev mailing list, and I’ve mentioned it in the Rockbox IRC.