The annual curl user survey is up. If you ever used curl or libcurl during the last year, please consider donating ten minutes of your time and fill in the question on the link below!
[no longer open]
The survey will be up for 14 days. Please share this with your curl-using friends as well and ask them to contribute. This is our only and primary way to find out what users actually do with curl and what you want with it – and don’t want it to do!
The survey is hosted by Google forms. The curl project will not track users and we will not ask who you are (and than some general details to get a picture of curl users in general).
Today we take a closer look at one of the real vintage curl options. It was added already in early 1999. -Y for short, --speed-limit is the long version. This option needs an additional argument: <speed>. Let me describe exactly what that speed is and how it works below.
Slow or stale transfers
Very early on in curl’s lifetime, it became obvious to us that lots of times when you use curl in order to do an Internet transfer, that transfer could sometimes take a long time. Occasionally even ridiculously long times and it could seem that the transfers just stalled without any hope of resurrecting and completing its mission.
How do you tell curl to abandon such lost-hope transfers? The options we provide for timeouts provide one answer. But since the transfer speeds can vary greatly from time to time and machine to machine, you have to use a timeout value that uses an insane margin, which for the cases when everything flies fast turns out annoying.
We needed another way to detect and abort these stale transfers. Enter speed limit.
Lower than speed-limit bytes per second during speed-time
The --speed-limit <speed> you tell curl is the transfer speed threshold below which you think the transfer is untypically slow, specified as bytes per second. If you have a really fast Internet, you might for example think that a transfer that is below 1000 bytes/second is a sign of something not being right.
But just measuring a the transfer speed to be below that special threshold in a single snapshot is not a strong enough signal for curl to act on it. The speed also needs to be measure below that threshold during --limit-time <seconds>. If the transfer speed just incidentally sometimes and very quickly drops below the threshold (bad wifi?) that’s not a reason for concern. The default limit time (when --limit-speed is used without --limit-time set) is 30. The transfer speed needs to be measured below the threshold for that many consecutive seconds (and it samples once per second).
If curl deems that your transfer speed was too slow during the given period, it will break the transfer and return 28. Timeout.
These two options are entirely protocol independent and work for all transfers using any of the protocols curl supports.
Examples
Tell curl to give up the transfer if slower than 1000 bytes per second during 20 seconds:
The HP Color LaserJet CP3525 Printer looks like any other ordinary printer done by HP. But there’s a difference!
A friend of mine fell over this gem, and told me.
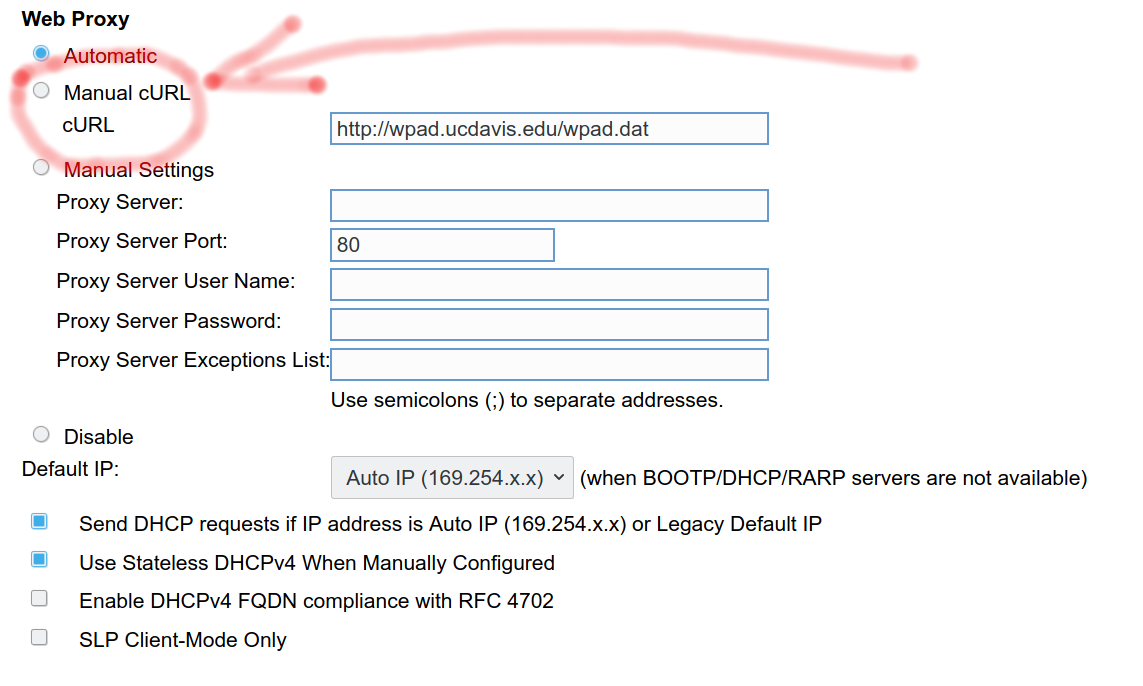
TCP/IP Settings
If you go to the machine’s TCP/IP settings using the built-in web server, the printer offers the ordinary network configure options but also one that sticks out a little exta. The “Manual cURL cURL” option! It looks like this:
I could easily confirm that this is genuine. I did this screenshot above by just googling for the string and printer model, since there appears to exist printers like this exposing their settings web server to the Internet. Hilarious!
What?
How on earth did that string end up there? Certainly there’s no relation to curl at all except for the actual name used there? Is it a sign that there’s basically no humans left at HP that understand what the individual settings on that screen are actually meant for?
Given the contents in the text field, a URL containing the letters WPAD twice, I can only presume this field is actually meant for Web Proxy Auto-Discovery. I spent some time trying to find the user manual for this printer configuration screen but failed. It would’ve been fun to find “manual cURL cURL” described in a manual! They do offer a busload of various manuals, maybe I just missed the right one.
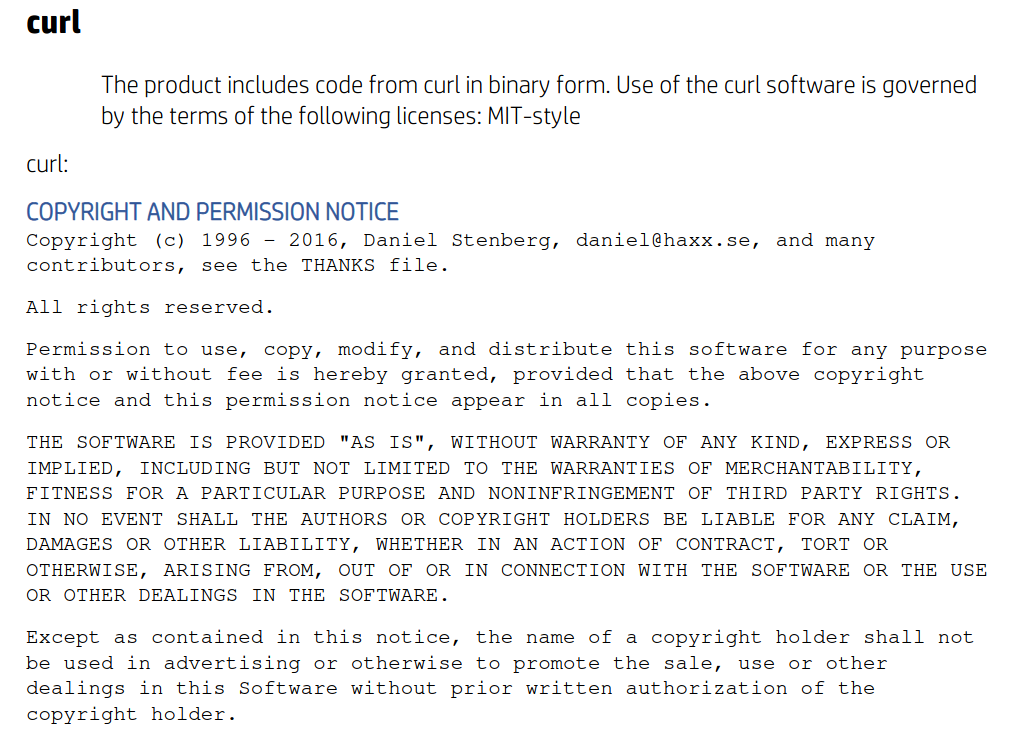
The curl license as found in the HP printer open source report.
HP using curl for Print-Uri?
Independently, someone else recently told me about another possible HP + curl connection. This user said his HP printer makes HTTP requests using the user-agent libcurl-agent/1.0:
I haven’t managed to get this confirmed by anyone else (although the license snippet above certainly implies they use curl) and that particular user-agent string has been used everywhere for a long time, as I believe it is copied widely from the popular libcurl example getinmemory.c where I made up the user-agent and put it there already in 2004.
Credits
Frank Gevaerts tricked me into going down this rabbit hole as he told me about this string.
I want curl to be on the very bleeding edge of protocol development to aid the Internet protocol development community to test out protocols early and to work out kinks in the protocols and server implementations using curl’s vast set of tools and switches.
For this, curl supported HTTP/2 really early on and helped shaping the protocol and testing out servers.
For this reason, curl supports HTTP/3 already since August 2019. A convenient and well-known client that you can then use to poke on your brand new HTTP/3 servers too and we can work on getting all the rough edges smoothed out before the protocol is reaching its final state.
QUIC tooling
One of the many challenges QUIC and HTTP/3 have is that with a new transport protocol comes entirely new paradigms. With new paradigms like this, we need improved or perhaps even new tools to help us understand the network flows back and forth, to make sure we all have a common understanding of the protocols and to make sure we implement our end-points correctly.
QUIC only exists as an encrypted-only protocol, meaning that we can no longer easily monitor and passively investigate network traffic like before, QUIC also encrypts more of the protocol than TCP + TLS do, leaving even less for an outsider to see.
The current QUIC analyzer tool lineup gives us two options.
Wireshark
We all of course love Wireshark and if you get a very recent version, you’ll be able to decrypt and view QUIC network data.
With curl, and a few other clients, you can ask to get the necessary TLS secrets exported at run-time with the SSLKEYLOGFILE environment variable. You’ll then be able to see every bit in every packet. This way to extract secrets works with QUIC as well as with the traditional TCP+TLS based protocols.
qvis/qlog
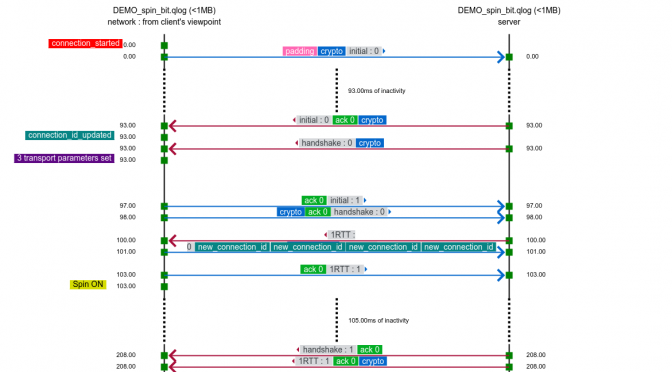
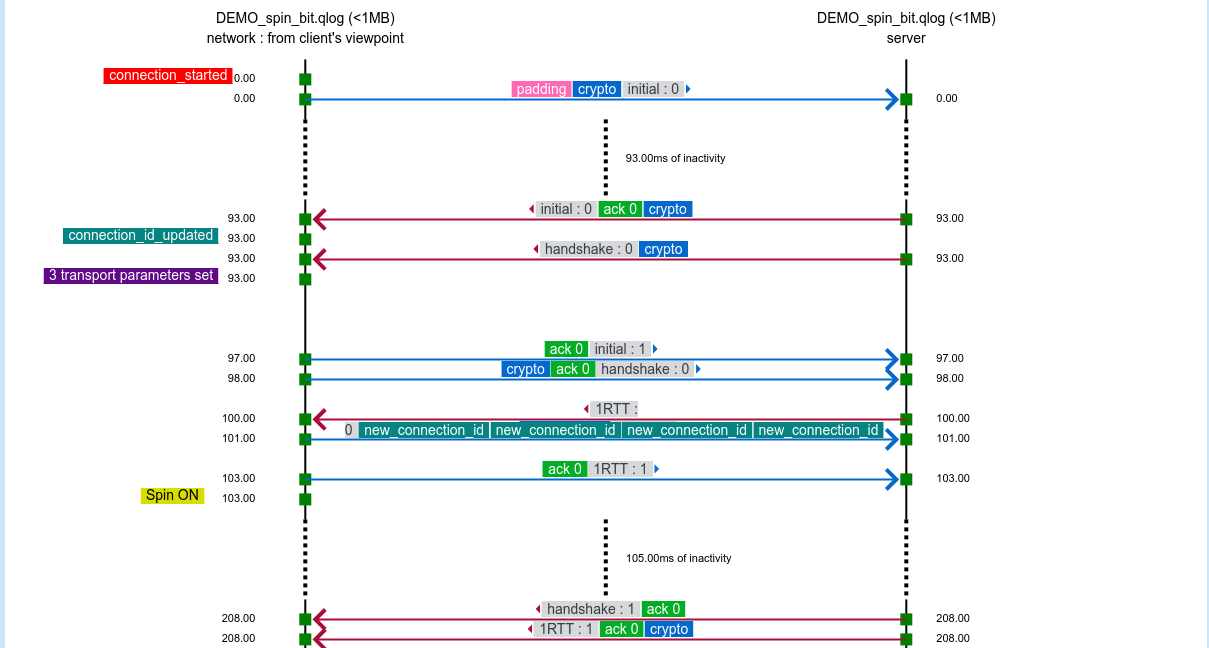
The qvis/qlog site. If you find the Wireshark network view a little bit too low level and leaving a lot for you to understand and draw conclusions from, the next-level tool here is the common QUIC logging format called qlog. This is an agreed-upon common standard to log QUIC traffic, which the accompanying qvis web based visualizer tool that lets you upload your logs and get visualizations generated. This becomes extra powerful if you have logs from both ends!
Starting with this commit (landed in the git master branch on May 7, 2020), all curl builds that support HTTP/3 – independent of what backend you pick – can be told to output qlogs.
Enable qlogging in curl by setting the new standard environment variable QLOGDIR to point to a directory in which you want qlogs to be generated. When you run curl then, you’ll get files creates in there named as [hex digits].log, where the hex digits is the “SCID” (Source Connection Identifier).
Credits
qlog and qvis are spear-headed by Robin Marx. qlogging for curl with Quiche was pushed for by Lucas Pardue and Alessandro Ghedini. In the ngtcp2 camp, Tatsuhiro Tsujikawa made it very easy for me to switch it on in curl.
The top image is snapped from the demo sample on the qvis web site.
Not long ago I discovered that someone had written this book about curl and that someone wasn’t me! (I believe this is a first) Thrilled of course that I could check off this achievement from my list of things I never thought would happen in my life, I was also intrigued and so extremely curious that I simply couldn’t resist ordering myself a copy. The book is dated October 2019, edition 1.0.
I don’t know the author of this book. I didn’t help out. I wasn’t aware of it and I bought my own copy through an online bookstore.
First impressions
It’s very thin! The first page with content is numbered 13 and the last page before the final index is page 110 (6-7 mm thick). Also, as the photo shows somewhat: it’s not a big format book either: 225 x 152 mm. I suppose a positive spin on that could be that it probably fits in a large pocket.
Size comparison with the 2018 printed version of Everything curl.
I’m not the target audience
As the founder of the curl project and my role as lead developer there, I’m not really a good example of whom the author must’ve imagined when he wrote this book. Of course, my own several decades long efforts in documenting curl in hundreds of man pages and the Everything curl book makes me highly biased. When you read me say anything about this book below, you must remember that.
A primary motivation for getting this book was to learn. Not about curl, but how an experienced tech author like Dan teaches curl and libcurl programming, and try to use some of these lessons for my own writing and manual typing going forward.
What’s in the book?
Despite its size, the book is still packed with information. It contains the following chapters after the introduction:
The amazing curl … 13
The libcurl library … 25
Your basic web page grab … 35
Advanced web page grab … 49
curl FTP … 63
MIME form data … 83
Fancy curl tricks … 97
As you can see it spends a total of 12 pages initially on explanations about curl the command line tool and some of the things you can do with it and how before it moves on to libcurl.
The book is explanatory in its style and it is sprinkled with source code examples showing how to do the various tasks with libcurl. I don’t think it is a surprise to anyone that the book focuses on HTTP transfers but it also includes sections on how to work with FTP and a little about SMTP. I think it can work well for someone who wants to get an introduction to libcurl and get into adding Internet transfers for their applications (at least if you’re into HTTP). It is not a complete guide to everything you can do, but then I doubt most users need or even want that. This book should get you going good enough to then allow you to search for the rest of the details on your own.
I think maybe the biggest piece missing in this book, and I really thing it is an omission mr Gookin should fix if he ever does a second edition: there’s virtually no mention of HTTPS or TLS at all. On the current Internet and web, a huge portion of all web pages and page loads done by browsers are done with HTTPS and while it is “just” HTTP with TLS on top, the TLS part itself is worth some special attention. Not the least because certificates and how to deal with them in a libcurl world is an area that sometimes seems hard for users to grasp.
A second thing I noticed no mention of, but I think should’ve been there: a description of curl_easy_getinfo(). It is a versatile function that provides information to users about a just performed transfer. Very useful if you ask me, and a tool in the toolbox every libcurl user should know about.
The author mentions that he was using libcurl 7.58.0 so that version or later should be fine to use to use all the code shown. Most of the code of course work in older libcurl versions as well.
Comparison to Everything curl
Everything curl is a free and open document describing everything there is to know about curl, including the project itself and curl internals, so it is a much wider scope and effort. It is however primarily provided as a web and PDF version, although you can still buy a printed edition.
Everything curl spends more space on explanations of features and discussion how to do things and isn’t as focused around source code examples as Curl Programming. Everything curl on paper is also thicker and more expensive to buy – but of course much cheaper if you’re fine with the digital version.
Where to buy?
First: decide if you need to buy it. Maybe the docs on the curl site or in Everything curl is already good enough? Then I also need to emphasize that you will not sponsor or help out the curl project itself by buying this book – it is authored and sold entirely on its own.
But if you need a quick introduction with lots of examples to get your libcurl usage going, by all means go ahead. This could be the book you need. I will not link to any online retailer or anything here. You can get it from basically anyone you like.
Mistakes or errors?
I’ve found some mistakes and ways of phrasing the explanations that I maybe wouldn’t have used, but all in all I think the author seems to have understood these things and describes functionality and features accurately and with a light and easy-going language.
Finally: I would never capitalize curl as Curl or libcurl as Libcurl, not even in a book. Just saying…
The long version option is called --get and the short version uses the capital -G. Added in the curl 7.8.1 release, in August 2001. Not too many of you, my dear readers, had discovered curl by then.
The thinking behind it
Back in the early 2000s when we had added support for doing POSTs with -d, it become obvious that to many users the difference between a POST and a GET is rather vague. To many users, sending something with curl is something like “operating with a URL” and you can provide data to that URL.
You can send that data to an HTTP URL using POST by specifying the fields to submit with -d. If you specify multiple -d flags on the same command line, they will be concatenated with an ampersand (&) inserted in between. For example, you want to send both name and bike shed color in a POST to example.com:
Okay, so curl can merge -d data entries like that, which makes the command line pretty clean. What if you instead of POST want to submit your name and the shed color to the URL using the query part of the URL instead and you still would like to use curl’s fancy -d concatenation feature?
Enter -G. It converts what is setup to be a POST into a GET. The data set with -d to be part of the request body will instead be put after the question mark in the HTTP request! The example from above but with a GET:
GET /?name=Daniel&shed=green HTTP/1.1
Host: example.com
User-agent: curl/7.70.0
Accept: /
If you want to investigate exactly what HTTP requests your curl command lines produce, I recommend --trace-ascii if you want to see the HTTP request body as well.
-X is only for changing the actual method string in the HTTP request. It doesn’t change behavior and the change is mostly done without curl caring what the new string is. It will behave as if it used the original one it intended to use there.
If you use -d in a command line, and then add -X GET to it, curl will still send the request body like it does when -d is specified.
If you use -d plus -G in a command line, then as explained above, curl sends a GET in the command line and -X GET will not make any difference (unless you also follow a redirect, in which the -Xmay ruin the fun for you).
Other options
HTTP allows more kinds of requests than just POST or GET and curl also allows sending more complicated multipart POSTs. Those don’t mix well with -G; this option is really designed only to convert simple -d uses to a query string.
As tradition dictates, I do a “the state of curl” presentation every year. This year, as there’s no physical curl up conference happening, I have recorded the full presentation on my own in my solitude in my home.
This is an in-depth look into the curl project and where it’s at right now. The presentation is 1 hour 53 minutes.
We’ve done many curl releases over the years and this 191st one happens to be the 20th release ever done in the month of April, making it the leading release month in the project. (February is the month with the least number of releases with only 11 so far.)
Numbers
the 191st release 4 changes 49 days (total: 8,076) 135 bug fixes (total: 6,073) 262 commits (total: 25,667) 0 new public libcurl function (total: 82) 0 new curl_easy_setopt() option (total: 270) 1 new curl command line option (total: 231) 65 contributors, 36 new (total: 2,169) 40 authors, 19 new (total: 788) 0 security fixes (total: 92) 0 USD paid in Bug Bounties
Security
There’s no security advisory released this time. The release of curl 7.70.0 marks 231 days since the previous CVE regarding curl was announced. The longest CVE-free period in seven years in the project.
Changes
The curl tool got the new command line option --ssl-revoke-best-effort which is powered by the new libcurl bit CURLSSLOPT_REVOKE_BEST_EFFORT you can set in the CURLOPT_SSL_OPTIONS. They tell curl to ignore certificate revocation checks in case of missing or offline distribution points for those SSL backends where such behavior is present (read: Schannel).
We’ve introduced the first take on MQTT support. It is marked as experimental and needs to be explicitly enabled at build-time.
Bug-fixes to write home about
This is just an ordinary release cycle worth of fixes. Nothing particularly major but here’s a few I could add some extra blurb about…
gnutls: bump lowest supported version to 3.1.10
GnuTLS has been a supported TLS backend in curl since 2005 and we’ve supported a range of versions over the years. Starting now, we bumped the lowest supported GnuTLS version to 3.1.10 (released in March 2013). The reason we picked this particular version this time is that we landed a bug-fix for GnuTLS that wanted to use a function that was added to GnuTLS in that version. Then instead of making more conditional code, we cleaned up a lot of legacy and simplified the code significantly by simply removing support for everything older than this. I would presume that this shouldn’t hurt many users as I suspect it is a very bad idea to use older versions anyway, for security reasons if nothing else.
libssh: Use new ECDSA key types to check known hosts
curl supports three different SSH backends, and one them is libssh. It turned out that the glue layer we have in curl between the core libcurl and the SSH library lacked proper mappings for some recent key types that have been added to the SSH known_hosts file. This file has been getting new key types added over time that OpenSSH is using by default these days and we need to make sure to keep up…
multi-ssl: reset the SSL backend on Curl_global_cleanup()
curl can get built to support multiple different TLS backends – which lets the application to select which backend to use at startup. Due to an oversight we didn’t properly support that the application can go back and cleanup everything and select a different TLS backend – without having to restart the application. Starting now, it is possible!
Revert “file: on Windows, refuse paths that start with \\”
Back in January 2020 when we released 7.68.0 we announced what we then perceived was a security problem: CVE-2019-15601.
Later, we found out more details and backpedaled on that issue. “It’s not a bug, it’s a feature” as the saying goes. Since it isn’t a bug (anymore) we’ve now also subsequently removed the “fix” that we introduced back then…
tests: introduce preprocessed test cases
This is actually just one out of several changes in the curl test suite that has happened as steps in a larger sub-project: move all test servers away from using fixed port numbers over to using dynamically assigned ones. Using dynamic port numbers makes it easier to run the tests on random users’ machines as the risk for port collisions go away.
Previously, users had the ability to ask the tests to run on different ports by using a command line option but since it was rarely used, new test were often written assuming the default port number hard-coded. With this new concept, such mistakes can’t slip through.
In order to correctly support all test servers running on any port, we’ve enhanced the main test “runner” (runtests) to preprocess the test case files correctly which allows all our test servers to work with such port numbers appearing anywhere in protocol details, headers or response bodies.
The work on switching to dynamic port numbers isn’t quite completed yet but there are still a few servers using fixed ports. I hope those will be addressed within shortly.
tool_operate: fix add_parallel_transfers when more are in queue
Parallel transfers in the curl tool is still a fairly new thing, clearly, as we can get a report on this kind of basic functionality flaw. In this case, you could have curl generate zero byte output files when using --parallel-max to limit the parallelism, instead of getting them all downloaded fine.
version: add ‘cainfo’ and ‘capath’ to version info struct
curl_version_info() in libcurl returns lots of build information from the libcurl that’s running right now. It includes version number of libcurl, enabled features and version info from used 3rd party dependencies. Starting now, assuming you run a new enough libcurl of course, the returned struct also contains information about the built-in CA store default paths that the TLS backends use.
The idea being that your application can easily extract and use this information either in information/debugging purposes but also in cases where other components are used that also want a CA store and the application author wants to make sure both/all use the same paths!
windows: enable UnixSockets with all build toolchains
Due to oversights, several Windows build didn’t enable support for unix domain sockets even when built for such Windows 10 versions where there’s support provided for it in the OS.
scripts: release-notes and copyright
During the release cycle, I regularly update the RELEASE-NOTES file to include recent changes and bug-fixes scheduled to be included in the coming release. I do this so that users can easily see what’s coming; in git, on the web site and in the daily snapshots. This used to be a fairly manual process but the repetitive process finally made me create a perl script for it that removes a lot of the manual work: release-notes.pl. Yeah, I realize I’m probably the only one who’s going to use this script…
Already back in December 2018, our code style tool checksrc got the powers to also verify the copyright year range in the top header (written by Daniel Gustafsson). This makes sure that we don’t forget to bump the copyright years when we update files. But because this was a bit annoying and surprising to pull-request authors on GitHub we disabled it by default – which only lead to lots of mistakes still being landed on the poor suckers (like me) who enabled it would get the errors instead. Additionally, the check is a bit slow. This finally drove me into disabling the check as well.
To combat the net effect of that, I’ve introduced the copyright.pl script which is similar in spirit but instead scans all files in the git repository and verifies that they A) have a header and B) that the copyright range end year seems right. It also has a whitelist for files that don’t need to fulfill these requirements for whatever reason. Now we can run this script one every release cycle instead and get the same end results. Without being annoying to users and without slowing down anyone’s everyday builds! Win-win!
The release presentation video
Credits
The top image was painted by Dirck van Delen 1631. Found in the Swedish National Museum’s collection.
On May 7, 2020 I will present common mistakes when using libcurl (and how to fix them) as a webinar over Zoom. The presentation starts at 19:00 Swedish time, meaning 17:00 UTC and 10:00 PDT (US West coast).
libcurl is used in thousands of different applications and devices for client-side Internet transfer and powers a significant part of what flies across the wires of the world a normal day.
Over the years as the lead curl and libcurl developer I’ve answered many questions and I’ve seen every imaginable mistake done. Some of the mistakes seem to happen more frequently and some of the mistake seem easier than others to avoid.
I’m going to go over a list of things that users often get wrong with libcurl, perhaps why they do and of course I will talk about how to fix those errors.
Length
It should be done within 30-40 minutes, plus some additional time for questions at the end.
Audience
You’re interested in Internet transfer, preferably you already know what libcurl is and perhaps you have even written code that uses libcurl. Directly in C or using a binding in another language.
Material
The video and slides will of course be made available as well in case you can’t tune in live.
Sign up
If you sign up to attend, you can join, enjoy the talk and of course ask me whatever is unclear or you think needs clarification around this topic. See you next week!