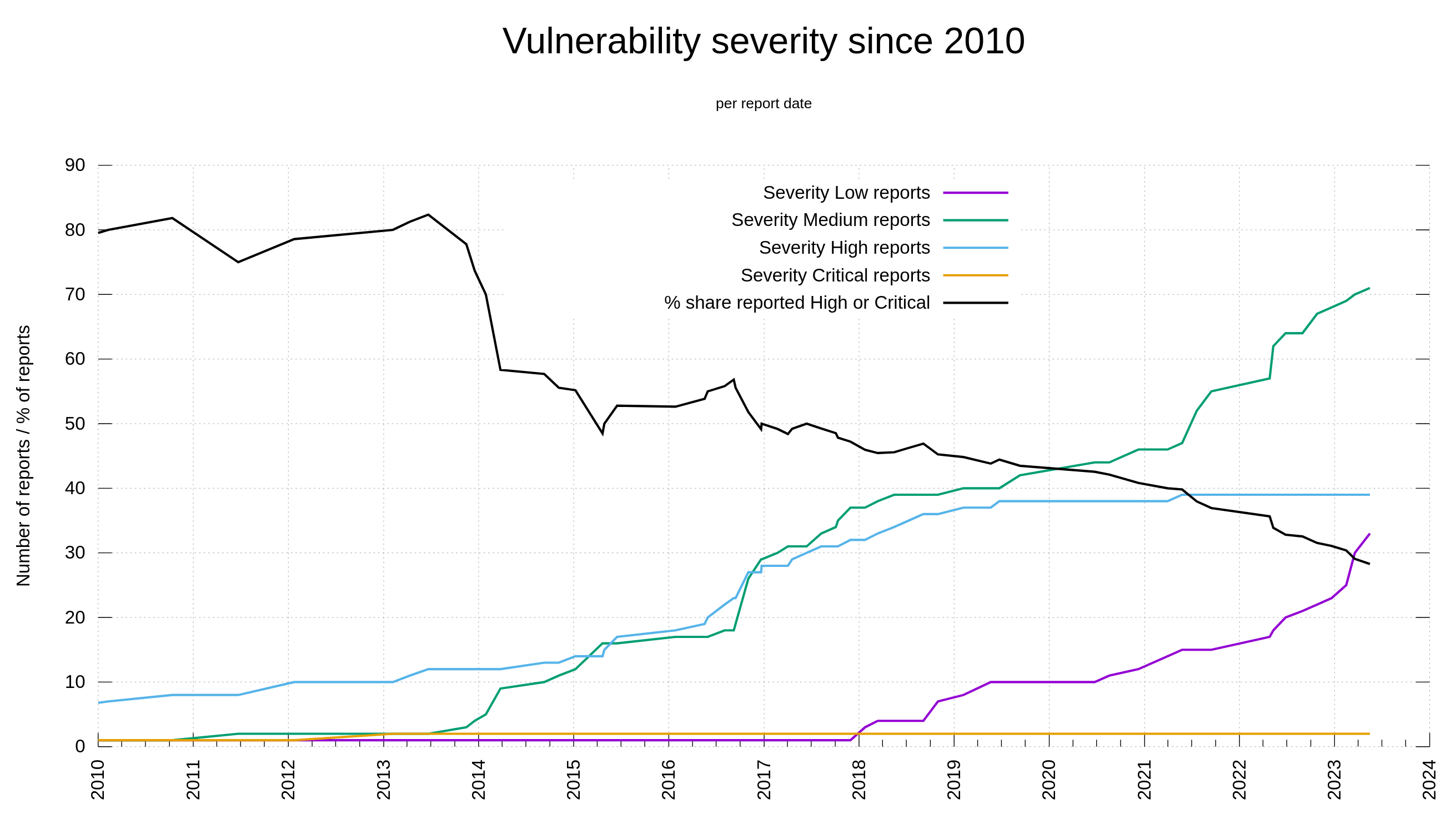
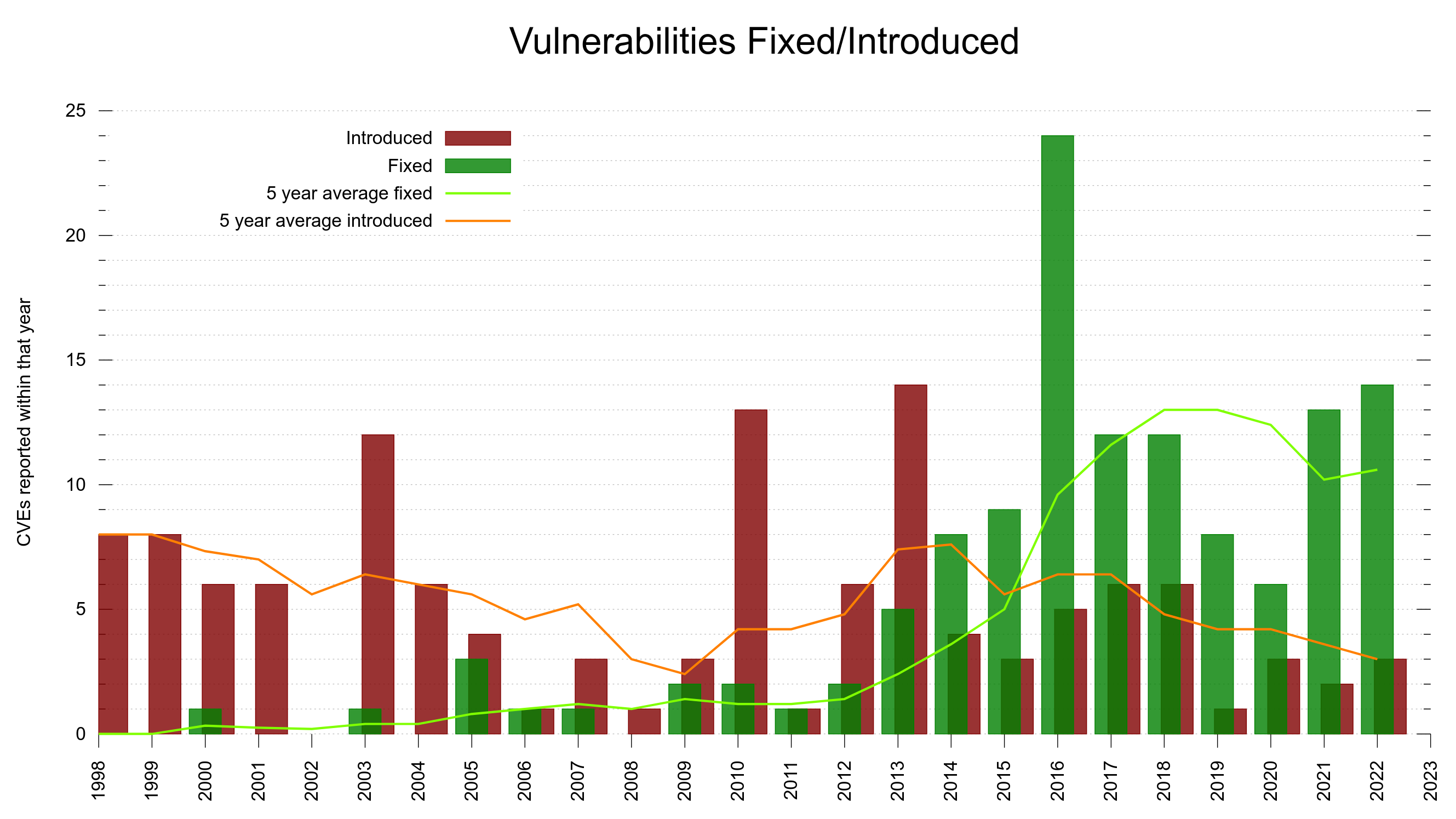
On August 26 I posted details here on my blog about the bogus curl issue CVE-2020-19909. Luckily, it got a lot of attention and triggered discussions widely. Maybe I helped shed light on the brittleness of this system. This was not a unique instance and it was not the first time it happened. This has been going on for years.
For example, the PostgreSQL peeps got a similarly bogus CVE almost at the same time. Not a real problem either.
UB
Some people did in discussions following my blog post insist that a signed long overflow is undefined behavior in C and since it truly is undefined all bets are off so this could be a security issue.
I am not a fan of philosophical thought exercises around vulnerabilities. They are distractions from the real matters and I find them rather pointless. It is easy to test how this flaw plays out on numerous platforms using numerous compilers. It’s not a security problem on any of them. Even if the retry time would go down to 0, it is not a DOS to do multiple internet transfers next to each other. If it would be, then a browser makes a DOS every time you visit a website – and curl does it when you give it two URLs on the same command line. Unexpected behavior and a silly bug, yes. Security flaw: no.
Not to even mention that no person or script actually would use such numbers on the command line that trigger the bug. This is the bug that never triggered for anyone who did not deliberately try to make it happen.
Who gets to report a CVE
A CVE Id is basically just a bug tracker identifier. You can ask for a number for a problem you found, and by the nature of this you don’t even have to present many details when you ask for it. You are however supposed to provide them when the issue goes public. CVE-2020-19909 certainly failed this latter step. You could perhaps ask why MITRE even allows for CVEs to get published at all if there isn’t more information available.
When you request a CVE Id, there are a few hundred distributed CVE number authorities (CNAs) you can get the number from.
CNA
A CNA can (apparently) require to be consulted if the ask is in regards to their scope. To their products.
I have initiated work on having curl become a CNA; to take responsibility for all CVEs that concern curl or libcurl. I personally think it is rather problematic that this basically is the only available means to prevent this level of crap, but I still intend to attempt this route.
Lots of other Open Source projects (Apache, OpenSSL, Python, etc) already are CNAs, many of them presumably because they realized these things much faster than me. I suspect curl is a smaller shop than most of the existing CNAs, but I don’t think size matters here.
It does of course add administration and work for us which is unfortunate, because that time and energy could be spent on more productive activities, but it still feels like a reasonable thing to try. Hopefully this can also help combat inflated severity levels.
MITRE: Reject 2020-19909 please
The main care-taker of the CVE database is MITRE. They provide a means for anyone to ask for updates to already published CVEs. I submitted my request for rejection using their online form, explaining that this issue is not a security problem and thus should be removed again. With all the info I had, including a link to my blog post.
They denied my request.
Their motivation? The exact quote:
After review there are multiple perspectives on whether the issue information is helpful to consumers of the CVE List, our current preference is in the direction of keeping the CVE ID assignment. There is a valid weakness (integer overflow) that can lead to a valid security impact (denial of service, based on retrying network traffic much more often than is documented/requested).
This is signed CVE Assignment Team, no identifiable human involved.
It is not a Denial of Service. It’s blatant scaremongering and it helps absolutely no one to say that it is.
NVD: Rescore 2020-19909 please
NVD maintains some sort of database and index with all the CVE Ids. They score them and as you may remember, they decided this non-issue is a 9.8 out of 10 severity.
The same evening I learned about this CVE I contacted NVD (nvd@nist.gov), pointed out this silliness and asked them to act on it.
A few days later they responded. From the National Vulnerability Database Team, no identifiable human.
First, they of course think their initial score was a fair assessment:
At the time of analysis, information for this CVE record was particularly sparse. Per NVD policy, if any information is lacking, unclear or conflicts between sources, the NVD policy is to represent the worst-case scenario. The NVD takes this conservative approach to avoid under reporting the possible severity of a given vulnerability.
Meaning: when they don’t know, they make up the worst possible scenario. That is literally what they say and how they act. Panic by default.
However, at this time there are more information sources and clarifications provided that make amendment of the CVSS vector string appropriate. We will break down the various amendments for transparency and to assist in confirmation of the appropriateness of these changes by you or a member of your team.
Meaning: their messed up system requires us to react and provide additional information to them to trigger a reassessment and them updating the score. To lower the panic level.
NVD themselves will not remove any CVE. As long as MITRE says it is a genuine issue, NVD shows it.
Rescore
As a rejection of the CVE was denied, the secondary goal would be to lower NVD’s severity score as much as possible.
The NVD response helped me understand how their research into and analyses of issues are performed.
Their email highlighted three specific items in the CVSS score and how they could maybe re-evaluate them to a lower setting. How do they base and motivate that? Providing links to specific reddit discussions for details of the CVE-2020-19909 problems. Postings done by the ordinary set of pseudonymous persons. Don’t get me wrong, some of those posts are excellent and clearly written by skilled and knowledgeable persons. It just seems a bit… arbitrary.
I did not participate in those discussions and neither did any curl core contributor to my knowledge. There are simply no domain experts involved there.
No reading or pointing to code. No discussions on data input and what changing retry delays mean and not a single word on UB. No mention on why no or a short delay would imply DOS.
Eventually, their proposed updated CVSS ends up with a new score of…
3.3
To be honest, I find CVSS calculations exhausting and I did not care to evaluate their proposal very closely. Again, this is not a security problem.
If you concur with the assessment above based on publicly available information this would change the vector string as follows:
AV:N/AC:L/PR:N/UI:N/S:U/C:H/I:H/A:H - 9.8
AV:L/AC:L/PR:L/UI:N/S:U/C:N/I:N/A:L - 3.3
In my response to NVD I wrote:
I have not personally checked the scoring very closely. I do not agree with the premise that this is a security problem. It is bad, wrong and hostile to insist that non-issues are security problems. It is counter-productive for the entire industry.
As they set it to 3.3 it at least takes the edge off this silliness and I feel a little bit better. They now also link to my blog post from their CVE-2020-19909 info page, which I think is grand of them.