As usual, here’s a set of selected favorite bug-fixes of mine from this cycle:
require “see also” for every documented option in curl.1
When the curl command man page is generated at build time, the script now makes sure that there is a “see also” for each option. This will help users find related info. More mandatory information for each option makes us do better documentation that ultimately helps users.
lazy-alloc the table in Curl_hash_add()
The internal hash functions moved the allocation of the actual hash table from the init() function to when the first add() is called to add something to the table. This delay simplified code (when the init function became infallible ) and does even avoid a few allocs in many cases.
enable haproxy support for hyper backend
Plus a range of code and test cases adjusted to make curl built with hyper run better. There are now less than 30 test cases still disabled for hyper. We are closing in!
mbedTLS: add support for CURLOPT_CAINFO_BLOB
Users of this backend can now also use this feature that allows applications to provide a CA cert store in-memory instead of using an external file.
multi: handle errors returned from socket/timer callbacks
It was found out that the two multi interface callbacks didn’t at all treat errors being returned the way they were documented to do. They are now, and the documentation was also expanded to clarify.
nss:set_cipher don’t clobber the cipher list
Applications that uses libcurl built to use NSS found out that if they would select cipher, they would also effectively prevent connections from being reused due to this bug.
openldap: implement STARTTLS
curl can now switch LDAP transfers into LDAPS using the STARTTLS command much like how it already works for the email protocols. This ability is so far limited to LDAP powered by OpenLDAP.
openssl: define HAVE_OPENSSL_VERSION for OpenSSL 1.1.0+
This little mistake made libcurl use the wrong method to extract and show the OpenSSL version at run-time, which most notably would make libcurl say the wrong version for OpenSSL 3.0.1, which would rather show up as the non-existing version 3.0.0a.
sha256/md5: return errors when init fails
A few internal functions would simply ignore errors from these hashing functions instead of properly passing them back to the caller, making them to rather generate the wrong hash instead of properly and correctly returning an error etc.
curl: updated search for a file in the homedir
The curl tool now searches for personal config files in a slightly improved manner, to among other things make it find the same .known_hosts file on Windows as the Microsoft provided ssh client does.
url: check ssl_config when re-use proxy connection
A bug in the logic for checking connections in the connection pool suitable for reuse caused flaws when doing subsequent HTTPS transfers to servers over the same HTTPS proxy.
ngtcp2: verify server certificate
When doing HTTP/3 transfers, libcurl is now doing proper server certificate verification for the QUIC connection – when the ngtcp2 backend is used. The quiche backend is still not doing this, but really should.
urlapi: accept port number zero
Years ago I wrote a blog post about using port zero in URLs to do transfers. Then it turned out port zero did not work like that with curl anymore so work was done and now order is restored again and port number zero is once again fine to use for curl.
urlapi: provide more detailed return codes
There are a whole range of new error codes introduced that help better identify and pinpoint what the problem is when a URL or a part of a URL cannot be parsed or will not be accepted. Instead of the generic “failed to parse URL”, this can now better tell the user what part of the URL that was found out to be bad.
socks5h: use appropriate ATYP for numerical IP address
curl supports using SOCKS5 proxies and asking the proxy to resolve the host name, what we call socks5h. When using this protocol and using a numerical IP address in the URL, curl would use the SOCKS protocol slightly wrong and pass on the wrong “ATYP” parameter which a strict proxy might reject. Fixed now.
Coming up?
The curl factory never stops. There are many pull-requests already filed and in the pipeline of possibly getting merged. There will also, without any doubts, be more ones coming up that none of us have yet thought about or considered. Existing pending topics might include:
the ManageSieve protocol
--no-clobber
CURLMOPT_STREAM_WINDOW_SIZE
Remove Mesalink support
HAproxy protocol v2
WebSockets
Export/import SSL session-IDs
HTTP/3 fixes
more hyper improvements
CURLFOLLOW_NO_CUSTOMMETHOD
Next release
March 2, 2022 is the scheduled date for what will most probably become curl 7.82.0.
I’m saving my bigger summary for curl’s 24th birthday in March, but when reaching the end of a calendar year it feels natural and even fun to look back and highlight some of the things we accomplished and what happened during this particular lap around the sun. I decided to pick five areas to highlight.
This has been another great curl year and it has been my pleasure to serve this project working full time with it, and I intend to keep doing it next year as well.
Activities, contribution and usage have all grown. I don’t think there has ever before been a more curl year than 2021.
Contributions
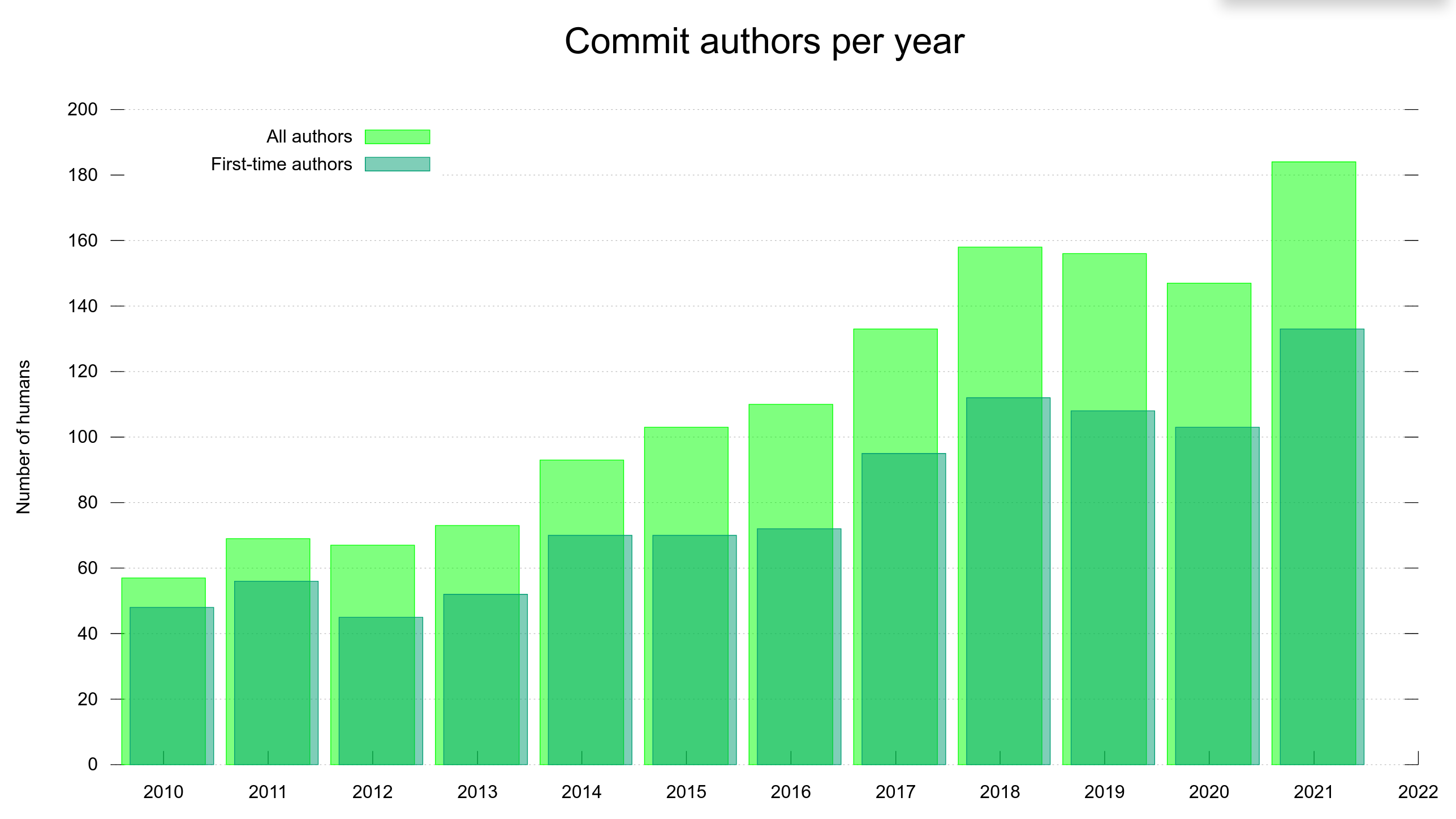
In 2021, the curl project beats all previous project records in terms of contribution. More than 180 individuals authored commits to the source code repository, out of more than 130 persons were first-time committers. Both numbers larger than ever before.
The number of authors per month was also higher than ever before and we end the year with a monthly average of 25 authors.
The number of committers who authored ten or more commits within a single year lands on 15 this year. A new record, up from the previous 13 in 2014 and 2017.
We end this year with the amazing number of more than 2,550 persons listed as contributors. We are also very close to reaching 1,000 committers. We are just a dozen authors away. Learn how to help us!
I personally have done about 60% of all commits to curl in 2021 and I was awarded a GitHub star earlier this year. I was a guest on eight podcast episodes this year, talking curl at least partly in all of them.
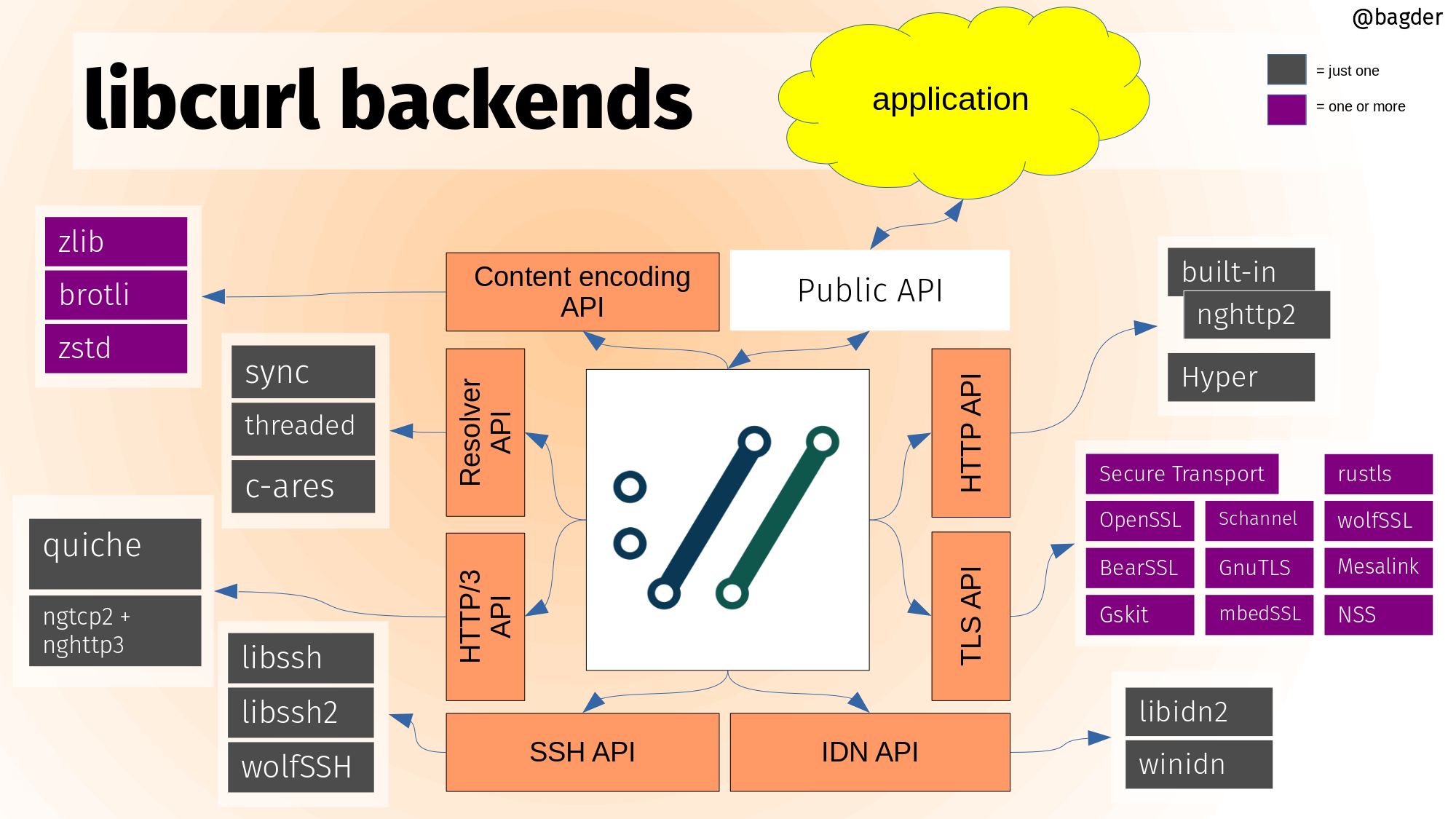
New backends
This year we introduced support for two new backends in curl: hyper and rustls. I suppose it is a sign of the times that both of them are written in Rust and could be a stepping stone into a future with more curl components written in memory safe languages.
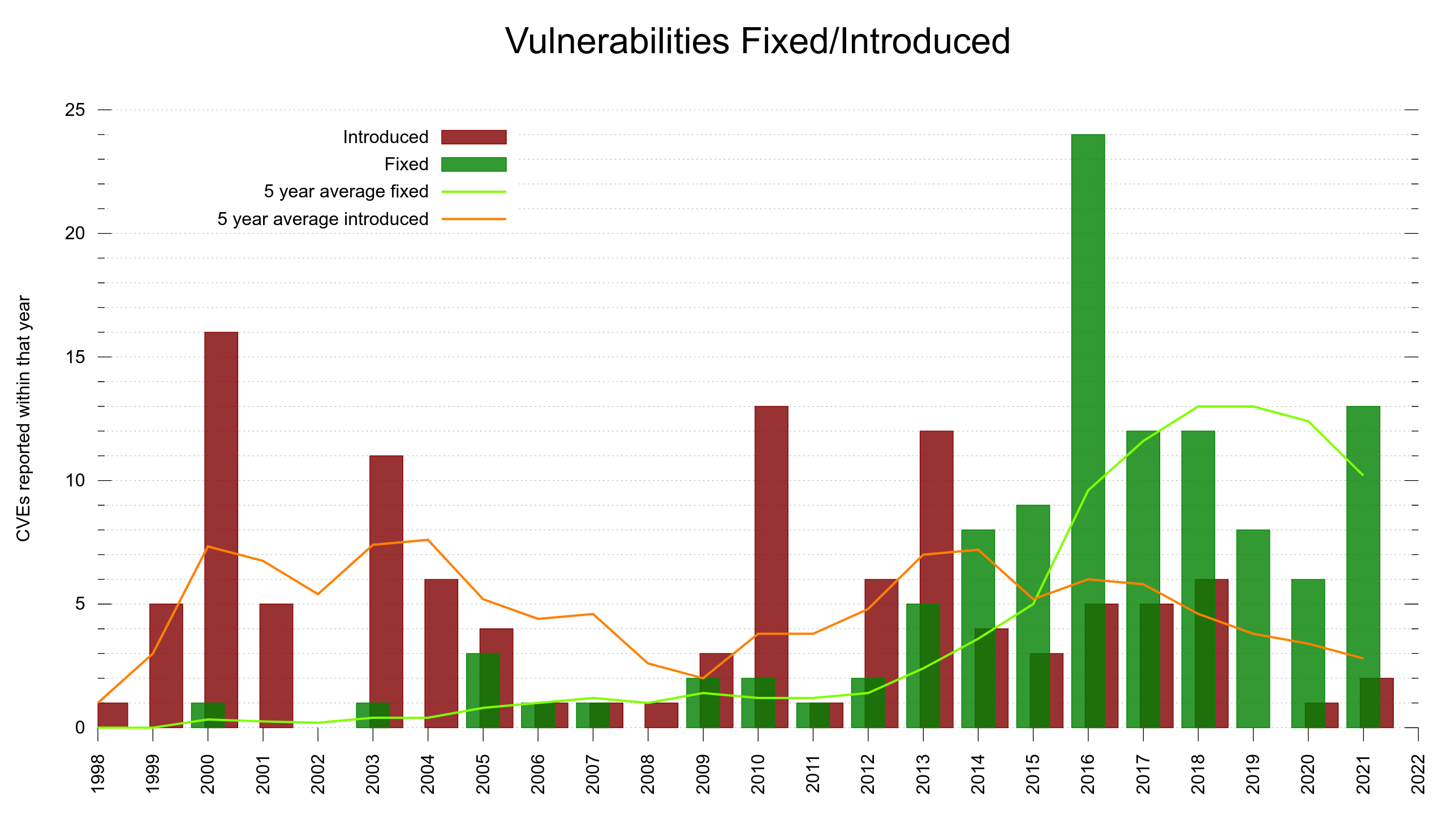
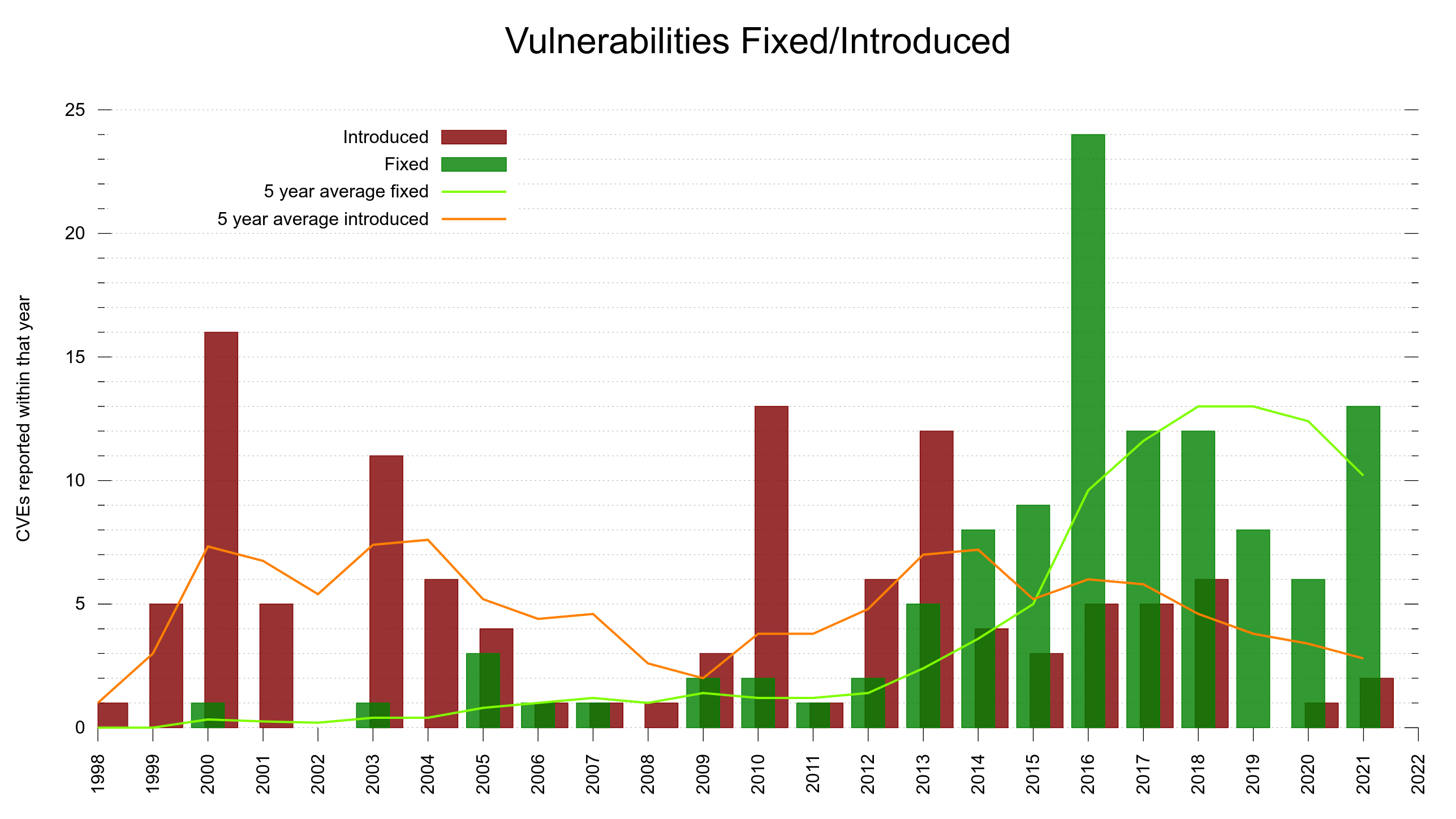
We actually got an increase in number of CVEs reported in 2021, 13 separate ones, after previously having had a decreasing trend the last few years. To remind us that security is still crucial!
Technically we merged the first hyper code already in late 2020 but we’ve worked on it through 2021 and this has made it work almost on par with the native code now.
None of these two new backends are yet used or exercised widely yet in curl, but we are moving in that direction. Slowly but surely.
Also backend related, during 2021 we removed the default TLS library choice when building curl and instead push that decision to get made by the person building curl. It refuses to build unless a choice is made.
The backends in curl provides build-time “pluggable” functionality.
Everything curl
In September 2015 I started to write Everything curl. The book to cover all there is to know and learn about curl. The project, the command line tool and the library.
When I started out, I wrote a lot of titles and sub-titles that I figured should be covered and detailed. For those that I didn’t yet have any text written I just wrote TBD. Over time I thought of more titles so I added more TBDs all over – and I created myself a script that would list which files that had the most number of TBDs outstanding. I added more and more text and explanations over time, but the more content I added I often thought of even more things that were still missing.
It took until December 15, 2021 to erase the final TBD occurrence! Six years and three months.
Presently, everything curl consists of more than 81,000 words in 12,000 lines of text. Done using more than 1,000 commits.
There are and probably always will be details missing and text that can be improved and clarified, but all the sections I once thought out should be there now at least are present and covered! I trust that users will tell us what we miss, and as we continue to grow and develop curl there will of course pop up new things to add to the book.
Death threat
In February 2021 I received a death threat by email. It is curl related because I was targeted entirely because my name is in the curl copyright statement and license and that is (likely) how the person found and contacted me. Months later, the person who sent me the threat apologized for his behavior.
It was something of a brutal awakening for me that reminded me with far too much clarity than I needed, that everything isn’t always just fun and games when people find my email address in their systems.
I filed a police report. I had a long talk with my wife. It shook my world there for a moment and it hinted of the abyss of darkness that lurk out there. I cannot say that it particularly changed my life or how I go about with curl development since then, but I think maybe it took away some of the rosy innocence out of the weird emails I get.
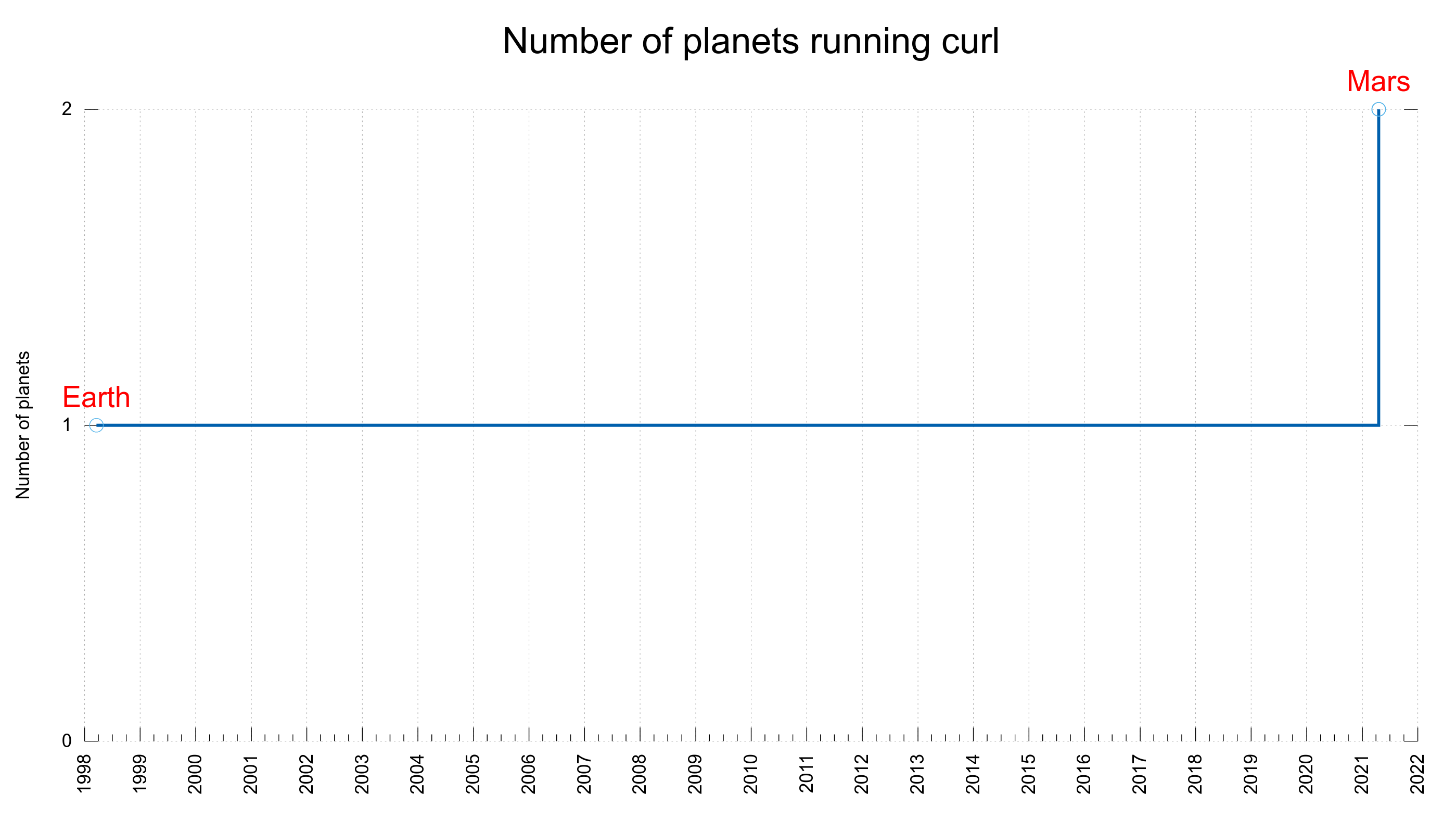
Mars
Not only did we finally get confirmation this year that curl is used in space – we learned that curl was used in the Mars 2020 Helicopter Mission! Quite possibly one of the coolest feats an open source project can pride itself with.
GitHub worked with NASA and have given all contributors to participating projects with a GitHub account a little badge on their profile. Shown here on the right. I think this fact alone might have helped attract more contributors this year. Getting your code into curl gets your contributions to places few other projects go.
There’s no info anywhere as to what function and purpose curl had exactly in the project and we probably will never know, but I think we can live with that. Now we are aiming for more planets.
I’ve talked on this topic before but I realized I never did a proper blog post on the topic. So here it is: how we develop curl to keep it safe. The topic of supply chain security is one that is discussed frequently these days and every so often there’s a very well used (open source) component that gets a terrible weakness revealed.
Don’t get me wrong. Proprietary packages have their share of issues as well, and probably even more so, but for obvious reasons we never get the same transparency, details and insight into those problems and solutions.
If we would find a critical vulnerability in curl, it could potentially exist in every internet-connected device on the globe. We don’t want that.
A critical security flaw in our products would be bad, but we also similarly need to make sure that we provide APIs and help users of our products to be safe and to use curl safely. To make sure users of libcurl don’t accidentally end up getting security problems, to the best of our ability.
In the curl project, we work hard to never have our own version of a “heartbleed moment“. How do we do this?
Always improving
Our method is not strange, weird or innovative. We simply apply all best practices, tools and methods that are available to us. In all areas. As we go along, we tighten the screws and improve our procedures, learning from past mistakes.
There are no short cuts or silver bullets. Just hard work and running tools.
Not a coincidence
Getting safe and secure code into your product is not something that happens by chance. We need to work on it and we need to make a concerned effort. We must care about it.
We all know this and we all know how to do it, we just need to make sure that we also actually do it.
The steps
Write code following the rules
Review written code and make sure it is clear and easy to read.
Test the code. Before and after merge
Verify the products and APIs to find cracks
Bug-bounty to reward outside helpers
Act on mistakes – because they will happen
Writing
For users of libcurl we provide an API with safe and secure defaults as we understand the power of the default. We also document everything with details and take great pride in having world-class documentation. To reduce the risk of applications becoming unsafe just because our API was unclear.
We also document internal APIs and functions to help contributors write better code when improving and changing curl.
We don’t allow compiler warnings to remain – on any platform. This is sometimes quite onerous since we build on such a ridiculous amount of systems.
We encourage use of source code comments and assert()s to make assumptions obvious. (curl is primarily written in C.)
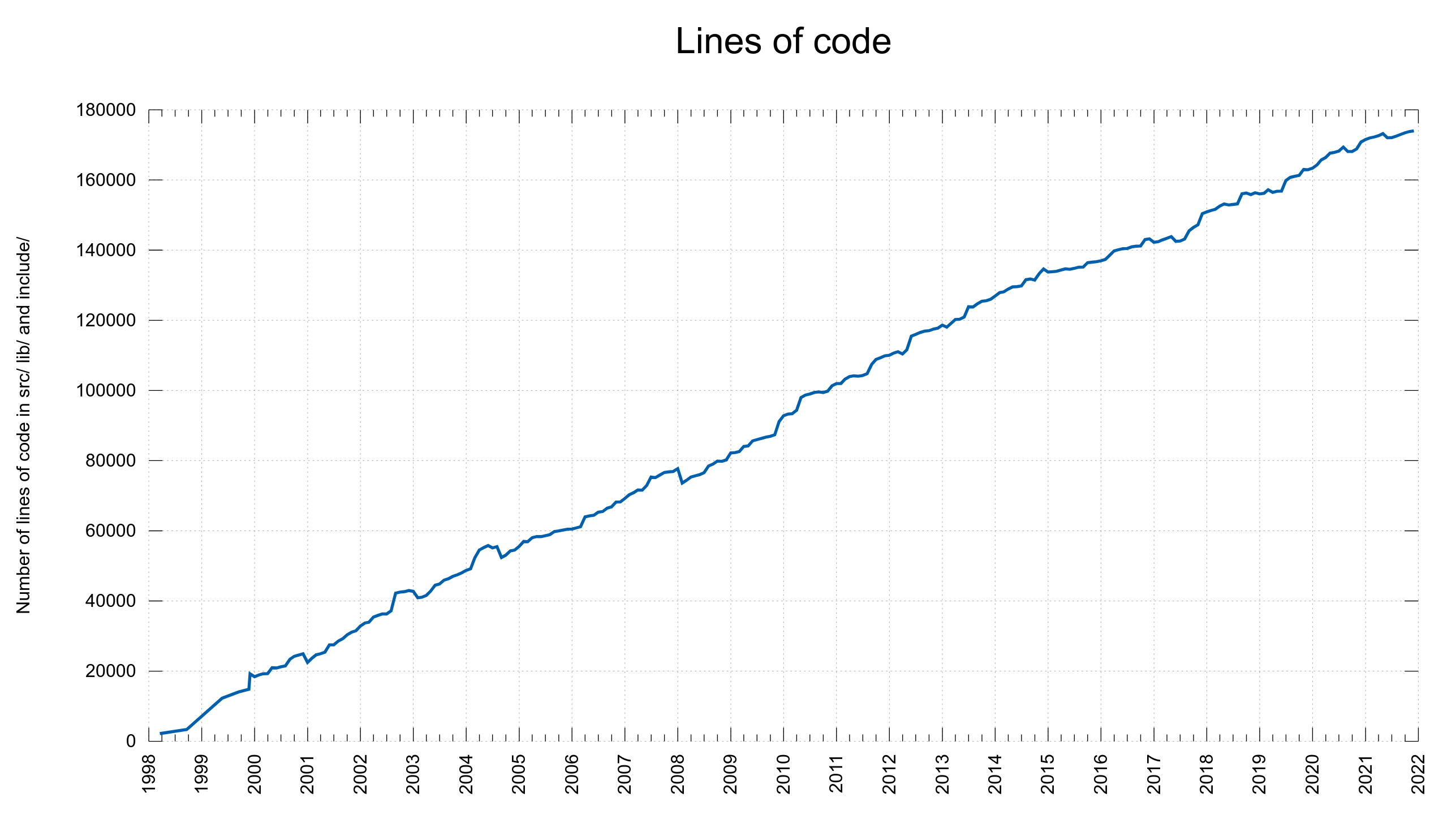
Number of lines of (product) code in the curl project over time.
Review
All code should be reviewed. Maintainers are however allowed to review and merge their own pull-requests for practical reasons.
Code should be easy to read and understand. Our code style must be followed and encourages that: for example, no assignments in conditions, one statement per line, no lines longer than 80 columns and more.
Strict compliance with the code style also means that the code gets a flow and a consistent look, which makes it easier to read and manage. We have a tool that verifies most aspects of the code style, which takes away most of that duty away from humans. I find that PR authors generally take code style remarks better when pointed out by a tool than when humans do it.
A source code change is accompanied with a git commit message that need to follow the template. A consistent commit message style makes it easier to later come back and understand it proper when viewing source code history.
Test
We want everything tested.
Unit tests. We strive at writing more and more unit tests of internal functions to make sure they truly do what expected.
System tests. Do actual network transfers against test servers, and make sure different situations are handled.
Integration tests. Test libcurl and its APIs and verify that they handle what they are expected to.
Documentation tests. Check formats, check references and cross-reference with source code, check lists that they include all items, verify that all man pages have all sections, in the same order and that they all have examples.
“Fix a bug? Add a test!” is a mantra that we don’t always live up to, but we try.
curl runs on 80+ operating systems and 20+ CPU architectures, but we only run tests on a few platforms. This usually works out fine because most of the code is written to run on multiple platforms so if tested on one, it will also run fine on all the other.
curl has a flexible build system that offers many million different build combinations with over 30 different possible third-party libraries in countless version combinations. We cannot test all build combos, but we try to test all the popular ones and at least one for each config option enabled and disabled.
We have many tests, but there are unfortunately still gaps and details not tested by the test suite. For those things we simply have to rely on the code review and then that users report problems in the shipped products.
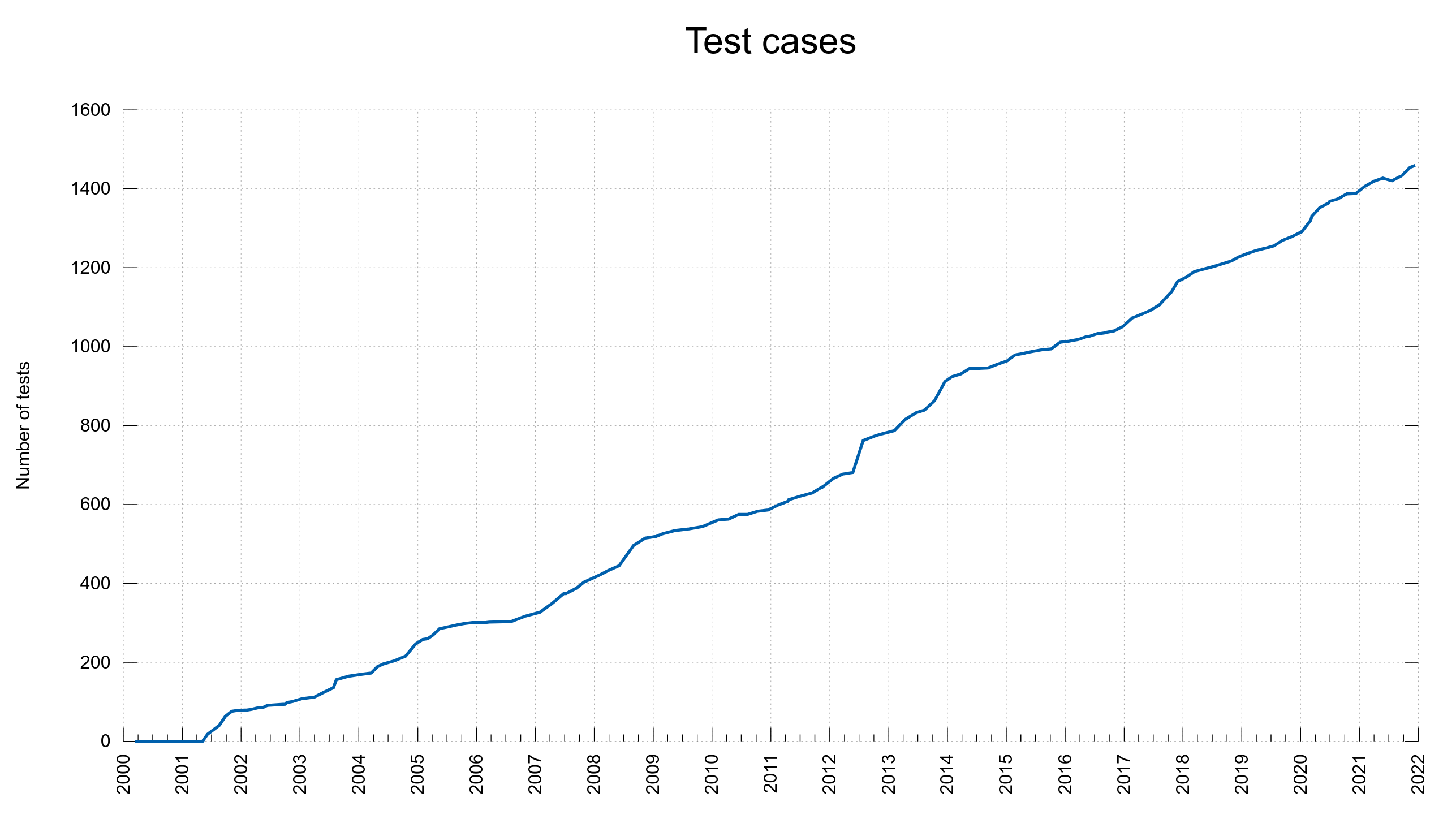
Number of test cases, test files really, over time.
Verify
We run all the tests using valgrind to make sure nothing leaks memory or do bad memory accesses.
We build and run with address, undefined behavior and integer overflow sanitizers.
We are part of the OSS-Fuzz project which fuzzes curl code non-stop, and we run CIFuzz in CI builds, which runs “a little” fuzzing on the curl code in the normal pull-request process.
We do “torture testing“: run a test case once and count the number of “fallible” function calls it makes. Those are calls to memory allocation, file operations, socket read/write etc. Then re-run the test that many times, and for each new iteration we make another one of the fallible functions fail and return error. Verify that no memory leaks or crashes occur. Do this on all tests.
We use several different static code analyzers to scan the code checking for flaws and we always fix or otherwise handle every reported defect. Many of them for each pull-request and commit, some are run regularly outside of that process:
scan-build
clang tidy
lgtm
CodeQL
Lift
Coverity
The exact set has varied and will continue to vary over time as services come and go.
Bug-bounty
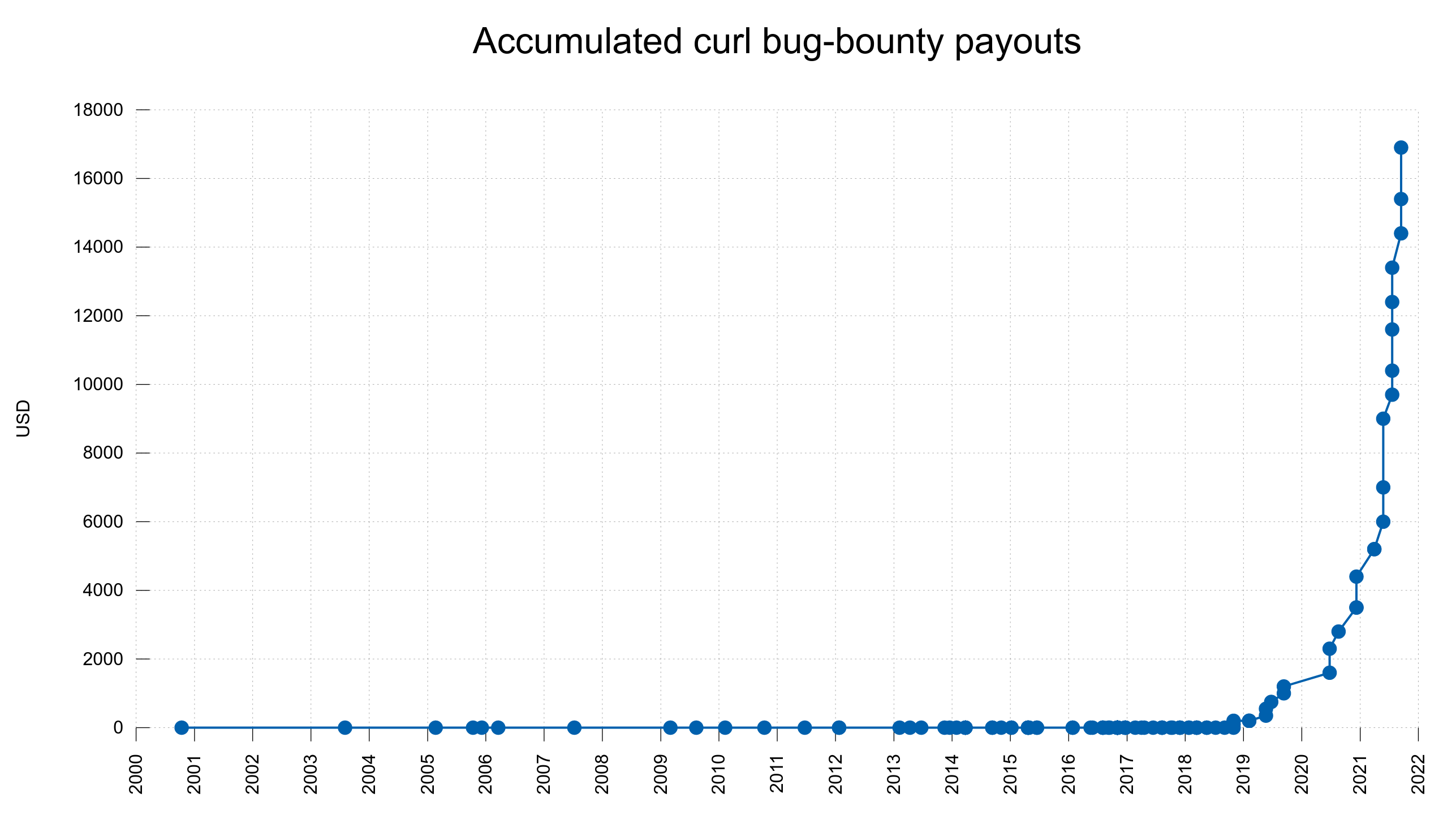
No matter how hard we try, we still ship bugs and mistakes. Most of them of course benign and harmless but some are not. We run a bug-bounty program to reward security searchers real money for reported security vulnerabilities found in curl. Until today, we have paid almost 17,000 USD in total and we keep upping the amounts for new findings.
Accumulated bug-bounty payouts over time
When we report security problems, we produce detailed and elaborate advisories to help users understand every subtle detail about the problem and we provide overview information that shows exactly what versions are vulnerable to which problems. The curl project aims to also be a world-leader in security advisories and related info.
Act on mistakes
We are not immune, no matter how hard we try. Bad things will happen. When they do, we:
Act immediately.
Own the problem, responsibly
Fix it and announce it – as soon as possible
Learn from it
Make it harder to do the same or similar mistakes again
Does it work? Do we actually learn from our history of mistakes? Maybe. Having our product in ten billion installations is not a proof of this. There are some signs that might show we are doing things right:
We were reporting fewer CVEs/year the last few years but in 2021 we went back up. It could also be the result of more people looking, thanks to the higher monetary rewards offered. At the same time the number of lines of code have kept growing at a rate of around 6,000 lines per year.
We get almost no issues reported by OSS-Fuzz anymore. The first few years it ran it found many problems.
We are able to increase our bug-bounty payouts significantly and now pay more than one thousand USD almost every time. We know people are looking hard for security bugs.
Security vulnerabilities. Fixed vs Introduced over the years.
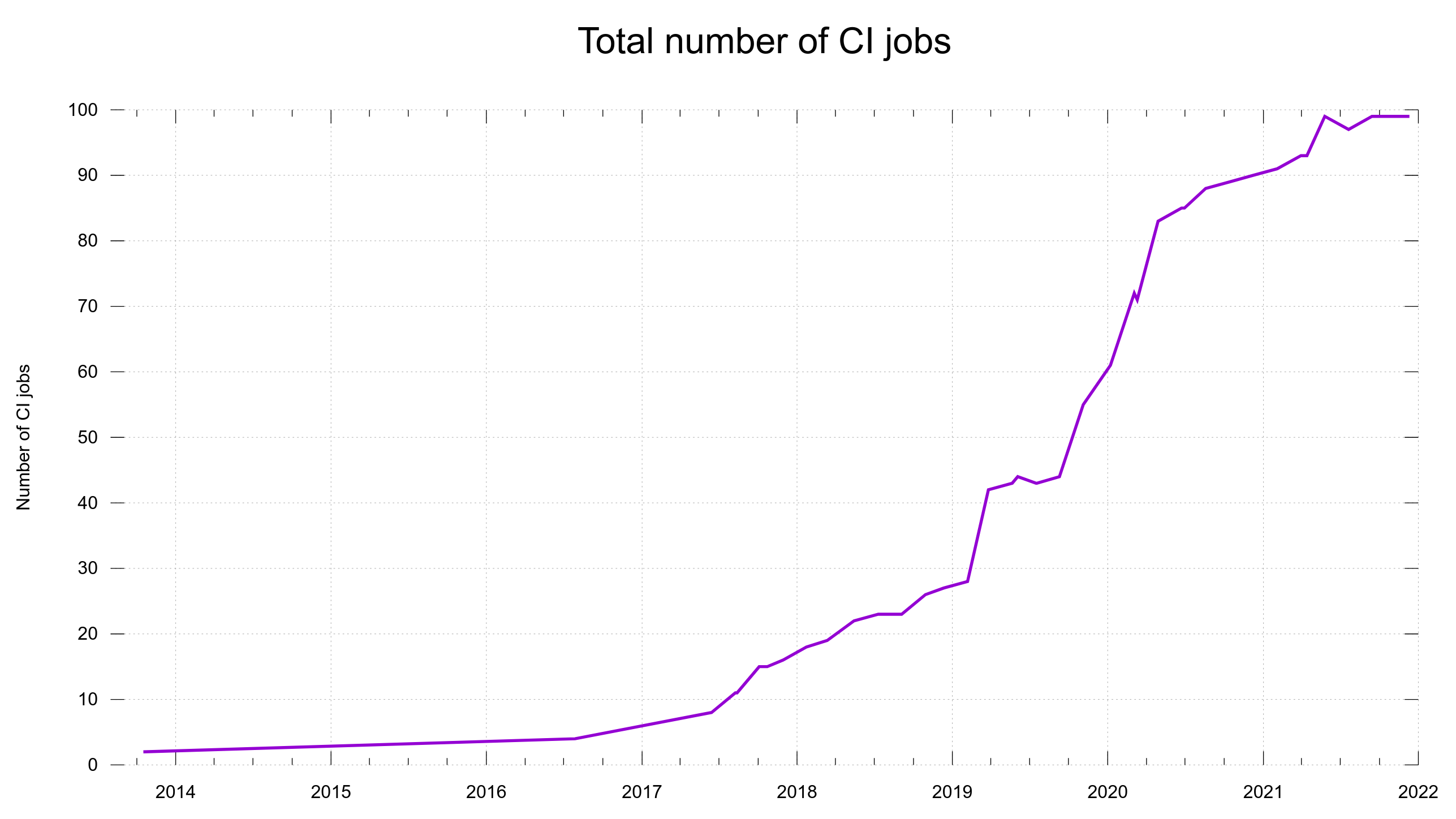
Continuous Integration
For every pull-request and commit done in the project, we run about 100 different builds + test rounds.
Total number of CI builds per pull-request and commit, over time
Done using several different CI services for maximum performance, widest possible coverage and shortest time to completion.
We currently use the following CI services: Cirrus CI, AppVeyor, Azure Pipelines, GitHub Actions, Circle CI and Zuul CI.
We also have a separate autobuild system with systems run by volunteers that checkout the latest code, build, run all the tests and report back in a continuous manner a few times or maybe once per day.
New habits past mistakes have taught us
We have done several changes to curl internals as direct reactions to past security vulnerabilities and their root causes. Lessons learned.
Unified dynamic buffer functions
These days we have a family of functions for working with dynamically sized buffers. Be using the same set for this functionality we have it well tested and we reduce the risk that new code messes up. Again, nothing revolutionary or strange, but as curl had grown organically over the decades, we found ourselves in need of cleaning this up one day. So we did.
Maximum string sizes
Several past mistakes came from possible integer overflows due to libcurl accepting input string sizes of unrestricted lengths and after doing operations on such string sizes, they would sometimes lead to overflows.
Since a few years back now, no string passed to curl is allowed to be larger than eight megabytes. This limit is somewhat arbitrarily set but is meant to be way larger than the largest user names and passwords ever used etc. We could also update the limit in a future, should we want. It’s not a limit that is exposed in the API or even mentioned. It is there to trap mistakes and malicious use.
Avoid reallocs
Thanks to the previous points we now avoid realloc as far as possible outside of those functions. History shows that realloc in combination with integer overflows have been troublesome for us. Now, both reallocs and integer overflows should be much harder to mess up.
Code coverage
A few years ago we ran code coverage reports for one build combo on one platform. This generated a number that really didn’t mean a lot to anyone but instead rather mislead users to drawing funny conclusions based on the report. We stopped that. Getting a “complete” and representative number for code coverage for curl is difficult and nobody has yet gone back to attempt this.
The impact of security problems
Every once in a while someone discovers a security problem in curl. To date, those security vulnerabilities have been limited to certain protocols and features that are not used by everyone and in many cases even disabled at build-time among many users. The issues also often rely on either a malicious user to be involved, either locally or remotely and for a lot of curl users, the environments it runs in limit that risk.
To date, I’m not aware of any curl user, ever, having been seriously impacted by a curl security problem.
This is not a guarantee that it will not ever happen. I’m only stating facts about the history so far. Security is super hard and I can only promise that we will keep working hard on shipping secure products.
Is it scary?
Changes done to curl code today will end up in billions of devices within a few years. That’s an intimidating fact that could truly make you paralyzed by fear of the risk that the world will “burn” due to a mistake of mine.
Rather than instilling fear by this outlook, I think the proper way to think it about it, is respecting the challenge and “shouldering the responsibility”. Make the changes we deem necessary, but make them according to the guidelines, follow the rules and trust that the system we have setup is likely to detect almost every imaginable mistake before it ever reaches a release tarball. Of course we plug holes in the test suite that we spot or suspect along the way.
The back-door threat
I blogged about that recently. I think a mistake is much more likely to slip-in and get shipped to the world than a deliberate back-door is.
Memory safe components might help
By rewriting parts of curl to use memory safe components, such as hyper for HTTP, we might be able to further reduce the risk of future vulnerabilities. That’s a long game to make reality. It will also be hard in the future to actually measure and tell for sure if it truly made an impact.
How can you help out?
Pay for a curl support contract. This is what enables me to work full time on curl.
Help out with reviews and adding new tests to curl
Help out with fixing issues and improving the code
An unexpected or undocumented feature in a piece of computer software, included as a joke or a bonus.
There are no Easter eggs in curl. For the good.
I’ve been asked about this many times. Among the enthusiast community, people seem to generally like the concept of Easter eggs and hidden treasures, features and jokes in software and devices. Having such an embedded surprise is considered fun and curl being a cool and interesting project should be fun too!
With the risk of completely ruining my chances of ever being considered a fun person, I’ll take you through my thought process on why curl does not feature any such Easter eggs and why it will not have any in the future either.
Trust
The primary and main reason is the question of trust.
We deliver products with known and documented functionality. Everything is known and documented. There’s nothing secret or hidden. The users see it all, can learn it all and it all is documented. We are always 100% transparent.
curl is installed in some ten billion installations to date and we are doing everything we can to be responsible and professional to make sure curl can and will be installed in many more places going forward.
Having an Easter egg in curl would violate several of the “commandments” we live by. If we could hide an Easter egg, what else is there that we haven’t shown or talked about?
Security
Everything in curl needs to be scrutinized, poked at, “tortured” and reviewed for security. An Easter egg would as well, as otherwise it would be an insecure component and therefor a security risk. This makes it impossible to maintain an Easter egg even almost secret.
Adding code to perform an Easter egg would mean adding code that potentially could cause problems to users by the plain unexpected nature of an Easter egg. Unexpected behavior is not a good foundation for security and secure procedures.
Boring is good
curl is not meant to be “fun” (on that fun scale). curl is here to perform its job, exactly as documented and expected and it is not meant to be fun. Boring is good and completely predictable. Boring is to deliver nothing else than the expected.
Even more security
If we would add an Easter egg, which by definition would be a secret or surprise to many, it would need to be hidden or sneaked in somehow and remain undocumented. We cannot allow code or features to get “snuck in” or remain undocumented.
If we would allow some features to get added like that, where would we draw the line? What other functionality and code do we merge into curl without properly disclosing and documenting it?
Useless work
If we would allow an Easter egg to get merged, we would soon start getting improvements to the egg code and people would like to add more eggs and to change the existing one. We would spend time and effort on the silly parts and we would need to spend testing and energy on these jokes instead of the real thing. We already have enough work without adding irrelevant work to the pile.
“Unintended Easter eggs”
We frequently ship bugs and features that go wrong. Due to fluke or random accidents, some of those mistakes can perhaps at times almost appear as Easter eggs, if you try hard. Still, when they are not done on purpose they are just bugs – not Easter eggs – and we will fix them as soon as we get them reported and have the chance.
A cover-up?
Yes, some readers will take this denial as a sign that there actually exists an Easter egg in curl and I am just doing my best to hide it. My advice to you, if you are one of those thinking this, is to read the code. We all benefit if more people read and carefully investigate the code so we will just be happy if you do and then ask us about whatever you think is unclear or “suspicious”.
I am not judging
This is not a judgement on projects that ship Easter eggs. I respect and acknowledge that different projects and people resonate differently on these topics.
When I speak of curl in this post, I lump curl the command line tool and libcurl the library into one, and I just call them curl. Related: my webinar titled “Why everyone is using curl and you should too“.
I believe just about every curl user has their own story and explanation about why they use curl in their product or device. I think there are several good reasons why users, including many of the world’s largest and most successful tech giants, decide they can lean on curl for Internet transfers.
curl is used in mobile phone and tablet apps, it is used in TVs, cars, motorcycles, fridges, settop boxes, printers, smart watches, medical devices and computer games, both on desktop and in game consoles and of course in just about every web or Internet server out there. It was also used to land on mars. Put simpler: in almost every internet-connected device.
Buy why use curl?
I want to highlight these four main properties:
In each of these areas, curl is one of the top alternatives if you compare against competitors.
It maintains this position because of its standing on a very firm foundation; a backbone built on Open Source, Leadership, Testing and Security.
Reliable
Solid code and product – most people and users never experience any bugs or problems with it. They keep using it over decades without any glitch.
Secure, means we deliver products that are safe and secure by default and we keep a strong focus and care about security related flaws in the project.
Stable API and ABI. Our users know they can always upgrade to a later version without worry. Things that worked before will continue to work tomorrow and forever.
Constantly refined. curl keeps up with the Internet, our users, new protocols and evolving standards. We never stop.
Available
It runs everywhere. Whatever platform of choice you go with, you can trust that curl can run there too. With the same API.
curl is here and has been around since decades. The same trustworthy product and API you knew in the past is still here and we do not plan to go anywhere. We have a long and proven track record that holds for all and any scrutinizing you do.
Often pre-installed on and with operating systems, making it easy to access and use.
Thoroughly documented. A library and its API is only as good as its documentation. Users need to be able to figure out available options and how the API is to be used to make effective and secure applications. curl has world-class documentation, including all the tiny details you might need. Online and offline.
Capable
Powerful. The provided API is versatile enough to power the Internet transfers for virtually all kinds of applications and use cases.
Fast. Speed is important.
curl supports “all the protocols” a modern application needs and the implementation is interoperable, proven and battle-tested in the wild and over the Internet for a long time.
The Internet is a crazy place and there are countless ways to do transfers. curl offers a myriad of features to please the most demanding users.
The flexible build allows users to streamline and control exactly what their curl build supports and provides.
Affordable
curl is free and open source under a liberal license. You don’t have to pay anyone to use or run it. We also provide free help and support on the mailing lists.
We offer commercial support to help users use curl and solve any related issues you might run into. Using curl does not waste your engineers’ time.
curl is also easy to contribute to, for the cases where you want to fix a bug or add a feature. We are a no-friction, no-bureaucracy project with a positive attitude and low bar for newcomers.
The Foundation
All of this is possible because of a solid and firm project foundation. We are Open Source, with full transparency and ability for everyone to inspect and follow along. To verify every claim.
I think we have a good Leadership, in which I of course bang my own drum a little bit, but we have managed to steer this boat for a long time in a direction that has made curl able power a world of Internet transfers. Rules, enforcement, knowledge, communication, guidelines, concepts and atmosphere are important factors. We lead by example.
There’s a strong emphasis on testing the products in a non-stop way as much as possible with numerous tools, from the first pull-requests, to the merging of commits into the main branch and onward, in order to find and fix as many nits as possible before the code reach users.
Almost no project can match the level of detail and information we provide with each and every security vulnerability we have published. We run a generous Bug Bounty program and pay a growing amount of monetary rewards to those who can identify new security problems.
The cycle of curl
When discussing the different qualities and properties of curl and the curl project, none of them were of course built-up or created separately from the others. They all tie in together and we have iteratively built and created curl gradually and little by little over a very long time.
One thing lead to another that leads to the next in a positive spiral that never ends. They are all interconnected and improving curl in one of these areas can definitely have a direct positive effect in one the other areas.
The cycle of curl is about improving curl all over for the benefit of everyone and the entire project, which leads to it just getting better and more used. Which leads to more developers, more features and more users etc. On and on and on without an end.
Imagine running a trillion dollar company that bundles various open source components into your products, making billions of dollars of profit annually. When one of your users reach out and ask for help, with the product you ship to your customers, you instead refer the user to the open source project. The project which is run by volunteers which you never sponsored with a cent.
The webinar will be live and we end with a Q&A session where you can ask me anything, in particular about this release and curl post quantum, but not necessarily limited to that…
I still remember the RFC number off the top of my head for the first multipart formdata spec that I implemented support for in curl. Added to curl in version 5.0, December 1998. RFC 1867.
Multipart formdata is the name of the syntax for how HTTP clients send data in a HTTP POST when they want to send binary content and multiple fields. Perhaps the most common use case for users is when uploading a file or an image with a browser to a website. This is also what you fire off with curl’s -F command line option.
RFC 1867 was published in November 1995 and it has subsequently been updated several times. The most recent incarnation for this spec is now known as RFC 7578, published in July 2015. Twenty years of history, experiences and minor adjustments. How do they affect us?
I admit to having dozed off a little at the wheel and I hadn’t really paid attention to the little tweaks that slowly had been happening in the multipart formata world until Ryan Sleevi woke me up.
Percent-encoding
While I wasn’t looking, the popular browsers have now all switched over to a different encoding style for field and file names within the format. They now all use percent-encoding, where we originally all used to do backslash-escaping! I haven’t actually bothered to check exactly when they switched, primarily because I don’t think it matters terribly much. They do this because this is now the defined syntax in WHATWG’s HTML spec. Yes, another case of separate specs diverging and saying different things for what is essentially the same format.
curl 7.80.0 is probably the last curl version to do the escaping the old way and we are likely to switch to the new way by default starting in the next release. The work on this is done by Patrick Monnerat in his PR.
For us in the curl project it is crucial to maintain behavior, but it is also important to be standard compliant and to interoperate with the big world out there. When all the major browsers have switched to percent-encoding I suspect it is only a matter of time until servers and server-side scripts start to assume and require percent-encoding. This is a tricky balancing act. There will be users who expect us to keep up with the browsers, but also some that expect us to maintain the way we’ve done it for almost twenty-three years…
libcurl users at least, will be offered a way to switch back to use the old escaping mechanism to make sure applications that know they work with older style server decoders can keep their applications working.
Landing
This blog post is made public before the PR mentioned above has been merged in order for people to express opinions and comments before it is done. The plan is to have it merged and ship in curl 7.81.0, to be released in January 2022.
The official gitstats page shows that I’ve committed changes on almost 4,600 separate days since the year 2000.
16,000 commits is 13,413 commits more than the person with the second-most number of commits: Yang Tse (2587 commits). He has however not committed anything in curl since he vanished from the project in 2013.
I have also done 4,700 commits in the curl-www repository, but that’s another story.
I like figuring out even or somehow particularly aligned numbers and dates to celebrate. Here’s another one: today marks the day when httpget 0.1 was released in 1996.
httpget 0.1 was a tiny command line tool written by Rafael Sagula. It was less than 300 lines of C code. (Today, the product code is 173,000 lines!)
I found httpget just days after it was released when I was searching for a tool to use for downloading currency rates with from an HTTP site. This was the time before Google existed so I assume I used Altavista or something. I can’t remember actually.
The httpget source code was my initial step into the HTTP world. In many ways, reading that code opened my eyes.
Of course there was some issues with the code that I can’t remember any longer, but I very soon sent Rafael my first patches to improve it. A few weeks later I took over maintenance of the little tool. The rest is documented elsewhere. The oldest httpget source code I still have around is httpget 1.3, released sometime between April and August 1997.
I have since been working with HTTP pretty much daily. For twenty-five years.
If someone tries to tell you that HTTP is an easy or simple protocol, don’t believe them.