This is the lowercase -m. The long form is called --max-time.
One of the oldest command line options in the curl tool box. It existed already in the first curl release ever: 4.0.
This option also requires a numerical argument. That argument can be an integer number or a decimal number, and it specifies the maximum time – in seconds – that you allow the entire transfer to take.
The intended use for this option is basically to provide a means for a user to stop a transfer that stalls or hangs for a long time due to whatever reason. Since transfers may sometimes be very quick and sometimes be ridiculously slow, often due to factors you cannot control or know about locally, figuring out a sensible maximum time value to use can be challenging.
Since -m covers the whole operation, even a slow name resolve phase can trigger the timeout if you set it too low. Setting a very low max-time value is almost guaranteed to occasionally abort otherwise perfectly fine transfers.
If the transfer is not completed within the given time frame, curl will return with error code 28.
Examples
Do the entire transfer within 10 seconds or fail:
curl -m 10 https://example.com/
Complete the download the file within 2.25 seconds or return error:
curl --max-time 2.25 https://example.com
Caveat
Due to restrictions in underlying system functions, some curl builds cannot specify -m values under one second.
curl up is the main (and only?) event of the year where curl developers and enthusiasts get together physically in a room for a full weekend of presentations and discussions on topics that are centered around curl and its related technologies.
We move the event around to different countries every year to accommodate different crowds better and worse every year – and this time we’re back again in Germany – where we once started the curl up series back in 2017.
The events are typically small with a very friendly spirit. 20-30 persons
Sign up
We will only be able to let you in if you have registered – and received a confirmation. There’s no fee – but if you register and don’t show, you lose karma.
May 9-10 2020. We’ll run the event both days of that weekend.
Agenda
The program is not done yet and will not be so until just a week or two before the event, and then it will be made available => here.
We want as many voices as possible to be heard at the event. If you have done something with curl, want to do something with curl, have a suggestion etc – even just short talk will be much appreciated. Or if you have a certain topic or subject you really want someone else to speak about, let us know as well!
Expect topics to be about curl, curl internals, Internet protocols, how to improve curl, what to not do in curl and similar.
Location
We’ll be in the co.up facilities in central Berlin. On Adalbertstraße 8.
Planning and discussions on curl-meet
Everything about the event, planning for it, volunteering, setting it up, agenda bashing and more will be done on the curl-meet mailing list, dedicated for this purpose. Join in!
The Stockholm edition.
Anti Google?
If you have a problem with filling in the Google-hosted registration form, please email us at curlup@haxx.se instead and we’ll ask you for the information over email instead.
I’m personally familiar with Backblaze as a fine backup solution I’ve helped my parents in law setup and use. I’ve found it reliable and easy to use. I would recommend it to others.
libcurl is MIT licensed (well, a slightly edited MIT license) so there’s really not a lot a company need to do to follow the license, nor does it leave me with a lot of “muscles” or remedies in case anyone would blatantly refuse to adhere. However, the impression I had was that this company was one that tried to do right and this omission could then simply be a mistake.
I sent an email. Brief and focused. Can’t hurt, right?
Immediate response
Brian Wilson, CTO of Backblaze, replied to my email within hours. He was very friendly and to the point. The omission was a mistake and Brian expressed his wish and intent to fix this. I couldn’t ask for a better or nicer response. The mentioned fixup was all that I could ask for.
Fixed it
Today Brian followed up and showed me the changes. Delivering on his promise. Just totally awesome.
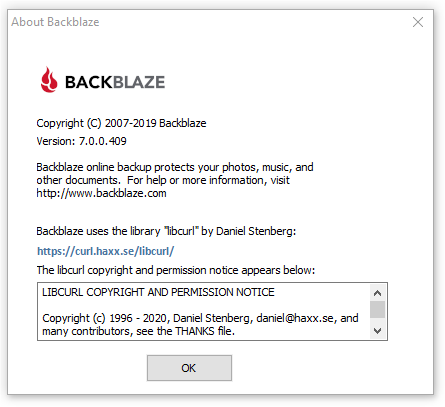
Starting with the Windows build 7.0.0.409, the Backblaze about window looks like this (see image below) and builds for other platforms will follow along.
15,600 US dollars
At the same time, Backblaze also becomes the new largest single-shot donor to curl when they donated no less than 15,600 USD to the project, making the recent Indeed.com donation fall down to a second place in this my favorite new game of 2020.
Why this particular sum you may ask?
Backblaze was started in my living room on Jan 15, 2007 (13 years ago tomorrow) and that represents $100/month for every month Backblaze has depended on libcurl back to the beginning.
/ Brian Wilson, CTO of Backblaze
I think it is safe to say we have another happy user here. Brian also shared this most awesome statement. I’m happy and proud to have contributed my little part in enabling Backblaze to make such cool products.
Finally, I just want to say thank you for building and maintaining libcurl for all these years. It’s been an amazing asset to Backblaze, it really really has.
(HTTP) When used, it disables all internal HTTP decoding of content or transfer encodings and instead makes them passed on unaltered, raw.
This option is for HTTP(S) and it was brought to curl when someone wanted to use curl in a proxy solution. In that setup the user parsed the incoming headers and acted on them and in the case where for example chunked encoded data is received, which curl then automatically “decodes” so that it can deliver the pure clean data, the user would find that there were headers in the received response that says “chunked” but since libcurl had already decoded the body, it wasn’t actually still chunked when it landed!
The --raw option is the command line version that disable both of those at once.
With --raw, no transfer or content decoding is done and the “raw” stream is instead delivered or saved. You really only do this if you for some reason want to handle those things yourself instead.
Content decoding includes automatice gzip compression, so --raw will also disable that, even if you use --compressed.
It should be noted that chunked encoding is a HTTP/1.1 thing. We don’t do that anymore in HTTP/2 and later – and curl will default to HTTP/2 over HTTPS if possible since a while back. Users can also often avoid chunked encoded responses by insisting on HTTP/1.0, like with the --http1.0 option (since chunked wasn’t included in 1.0).
Example command line
curl --raw https://example.com/dyn-content.cgi
Related options
--compressed asks the server to provide the response compressed and curl will then decompress it automatically. Thus reduce the amount of data that gets sent over the wire.
I’m happy to announce that curl now supports a third SSH library option: wolfSSH. Using this, you can build curl and libcurl to do SFTP transfers in a really small footprint that’s perfectly suitable for embedded systems and others. This goes excellent together with the tiny-curl effort.
SFTP only
The initial merge of this functionality only provides SFTP ability and not SCP. There’s really no deeper thoughts behind this other than that the work has been staged and the code is smaller for SFTP-only and it might be that users on these smaller devices are happy with SFTP-only.
Work on adding SCP support for the wolfSSH backend can be done at a later time if we feel the need. Let me know if you’re one such user!
Build time selection
You select which SSH backend to use at build time. When you invoke the configure script, you decide if wolfSSH, libssh2 or libssh is the correct choice for you (and you need to have the correct dev version of the desired library installed).
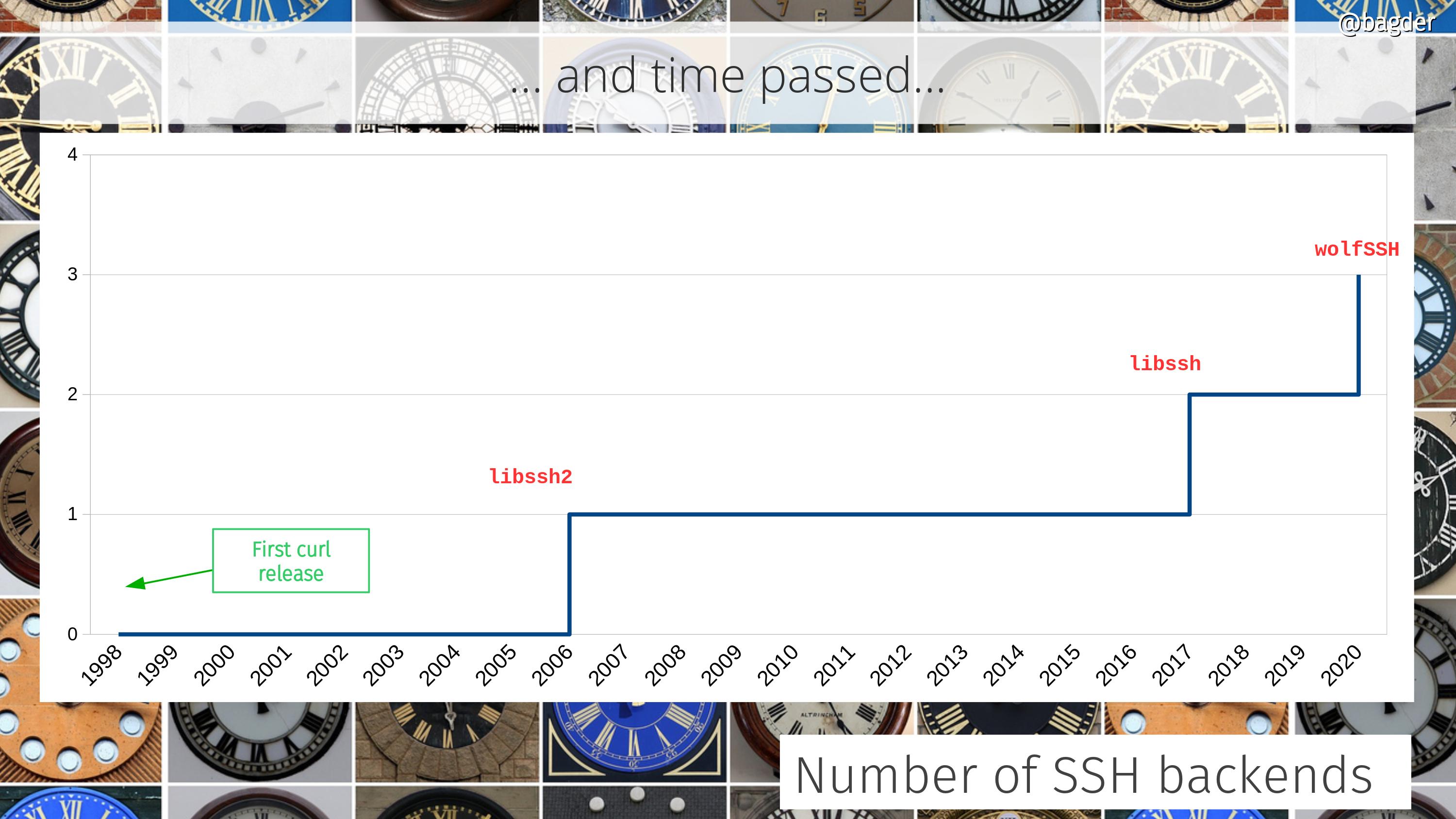
The initial SFTP and SCP support was added to curl in November 2006, powered by libssh2 (the first release to ship it was 7.16.1). Support for getting those protocols handled by libssh instead (which is a separate library, they’re just named very similarly) was merged in October 2017.
Number of supported SSH backends over time in the curl project.
WolfSSH uses WolfSSL functions
If you decide to use the wolfSSH backend for SFTP, it is also possibly a good idea to go with WolfSSL for the TLS backend to power HTTPS and others.
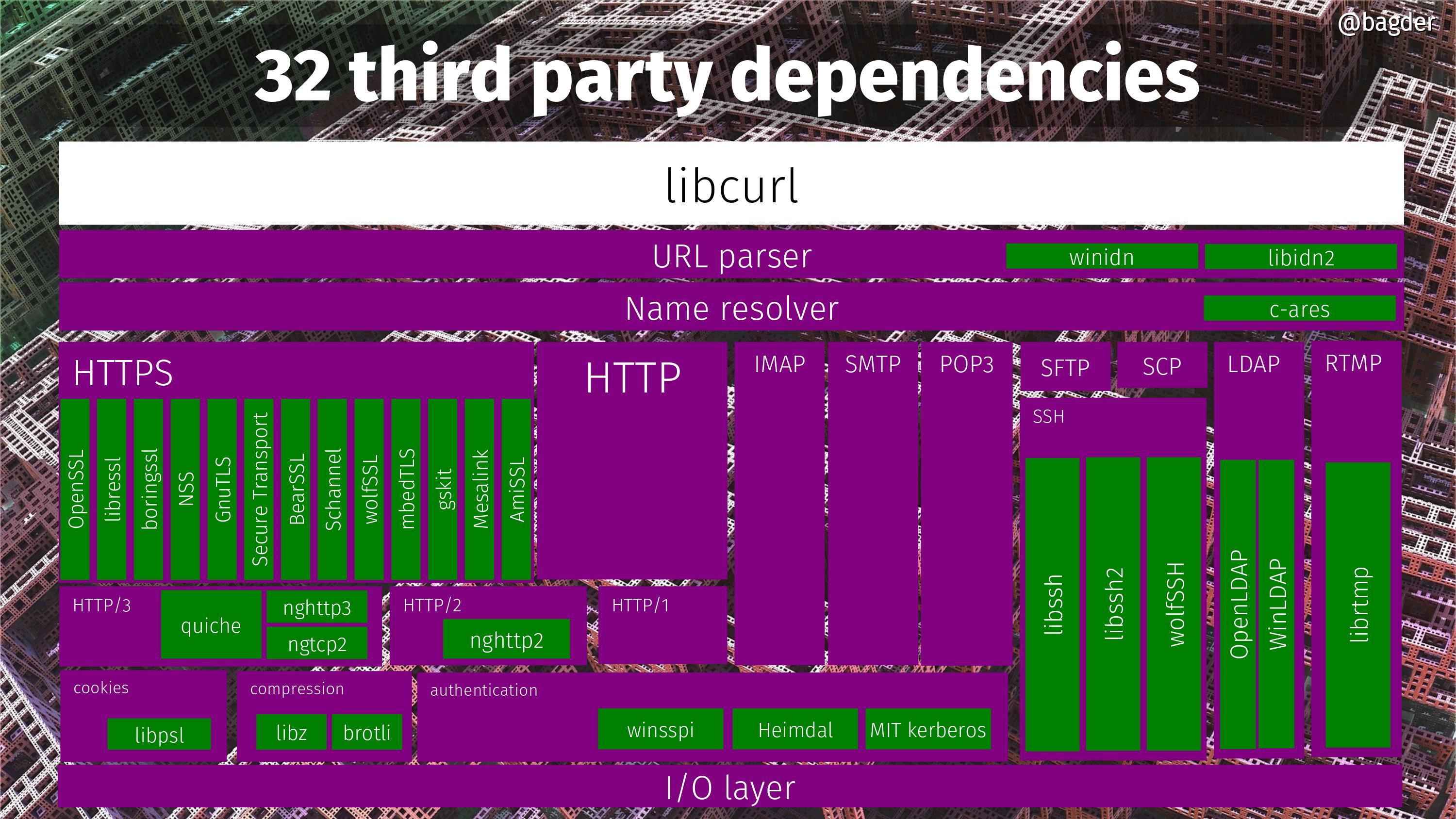
A plethora of third party libs
WolfSSH becomes the 32nd third party component that curl can currently be built to use. See the slide below and click on it to get the full resolution version.
32 possible third party dependencies curl can be built to use
Credits
I, Daniel, wrote the initial new wolfSSH backend code. Merged in this commit.
I’m please to invite you to our live webinar, “Why everyone is using curl and you should too!”, hosted by wolfSSL. Daniel Stenberg (me!), founder and Chief Architect of curl, will be live and talking about why everyone is using curl and you should too!
This is planned to last roughly 20-30 minutes with a following 10 minutes Q&A.
Space is limited so please register early!
When: Jan 14, 2020 08:00 AM Pacific Time (US and Canada) (16:00 UTC)
Register in advance for this webinar!
After registering, you will receive a confirmation email containing information about joining the webinar.
Not able to attend? Register now and after the event you will receive an email with link to the recorded presentation.
The year is still young, and we’re here to really kick off 2020 with a brand new curl release! curl 7.68.0 is available at curl.haxx.se as always. Once again we’ve worked hard and pushed through another release cycle to bring you the very best we could do in the 63 days since 7.67.0.
the 188th release 6 changes 63 days (total: 7,964) 124 bug fixes (total: 5,788) 193 commits (total: 25,124) 1 new public libcurl function (total: 82) 0 new curl_easy_setopt() option (total: 269) 3 new curl command line option (total: 229) 70 contributors, 32 new (total: 2,088) 31 authors, 13 new (total: 756) 1 security fixes (total: 93) 400 USD paid in Bug Bounties
Security Vulnerability
CVE-2019-15601: SMB access smuggling via FILE URL on Windows.
Simply put: you could provide a FILE:// URL to curl that could trick it to try to access a host name over SMB – on Windows machines. This could happen because Windows apparently always do this automatically if given the correct file name and curl had no specific filter to avoid it.
For this discovery and report, the curl Bug Bounty program has rewarded Fernando Muñoz 400 USD.
We changed the default handling in libcurl with OpenSSL for verifying certificates. We now allow “partial chains” by default, meaning that you can use an intermediate cert to verify the server cert, not necessarily the whole chain to the root, like you did before. This brings the OpenSSL backend to work more similar to the other TLS backends, and we offer a new option for applications to switch back on the old behavior (CURLSSLOPT_NO_PARTIALCHAIN).
The progress callback has a new feature: if you return CURL_PROGRESSFUNC_CONTINUE from the callback, it will continue and call the internal progress meter.
The new command line option --parallel-immediate is added, and if used will make curl do parallel transfers like before 7.68.0. Starting with 7.68.0, curl will default to defer new connections and rather try to multiplex new transfer over an existing connection if more than one transfer is specified to be done from the same host name.
Bug-fixes
Some of my favorite fixes done since the last release include…
Azure CI and torture
This cycle we started running a bunch of CI tests on Azure Pipelines, both Linux and macOS tests. We also managed to get torture tests running thanks to the new shallow mode.
Azure seem to run faster and more reliable than Travis CI, so moving a few jobs over has made a total build run often complete in less total time now.
prefer multiplexing to using new connections
A regression was found that made the connection reuse logic in libcurl to prefer new connections to multiplexing more than what was actually intended and once fixed we should see libcurl-using application do more and better HTTP/2 multiplexing.
support for ECDSA and ed25519 knownhost keys with libssh2
libssh2 is the primary SSH backend people use with curl. While the library itself has supported these new “knownhost” keys for a while, we hadn’t previously adjusted curl to play nicely with them. Until now.
openssl: Revert to less sensitivity for SYSCALL errors
Another regression in the OpenSSL backend code made curl overly sensitive to some totally benign TLS messages which would cause a curl error when they should just have been silently handled and closed the connection cleanly.
openssl: set X509_V_FLAG_PARTIAL_CHAIN by default
The OpenSSL backend now behaves more similar to other TLS backends in curl and now accepts “partial” certificate chains. That means you don’t need to have the entire chain locally all the way to the root in order to verify a server certificate. Unless you set CURLSSLOPT_NO_PARTIALCHAIN to enforce that behavior.
parsedate: offer a getdate_capped() alternative
The date parser was extended to make curl handle dates beyond 2038 better on 32 bit systems, which primarily seems to happen with cookies. Now the parser understands that they’re too big and will use the max time value it can hold instead of failing and using a zero, as that would make the cookies into “session cookies” which would have slightly different behavior.
The curl command line tool has a lot of options. And I really mean a lot, as in more than two hundred of them. After the pending release, I believe the exact count is 229.
Starting now, I intend to write and blog about a specific curl command line option per week (or so). With details, examples, maybe history and whatever I can think of is relevant to the option. Quite possibly some weeks will just get shorter posts if I don’t have a lot to say about it.
curl command line option of the week; ootw.
This should keep me occupied for a while.
Options
This will later feature the list of options with links to the dedicate blog posts about them. If you have preferences of what options to cover, do let me know and I can schedule them early on, otherwise I plan to go over them in a mostly random order.
For a long time, the curl changelog on the web site showed the history of changes in the curl project all the way back to curl 6.0. Released on September 13 1999. Older changes were not displayed.
The reason for this was always basically laziness. The page in its current form was initially created back in 2001 and then I just went back a little in history and filled up with a set of previous releases. Since we don’t have pre-1999 code in our git tree (because of a sloppy CVS import), everything before 1999 is a bit of manual procedure to extract so we left it like that.
Until now.
I decided to once and for all fix this oversight and make sure that we get a complete changelog from the first curl release all the way up until today. The first curl release was called 4.0 and was shipped on March 20, 1998.
Before 6.0 we weren’t doing very careful release notes and they were very chatty. I got the CHANGES file from the curl 6.0 tarball and converted them over to the style of the current changelog.
Notes on the restoration work
The versions noted as “beta” releases in the old changelog are not counted or mentioned as real releases.
For the released versions between 4.0 and 4.9 there are no release dates recorded, so I’ve “estimated” the release dates based on the knowledge that we did them fairly regularly and that they probably were rather spread out over that 200 day time span. They won’t be exact, but close enough.
Complete!
The complete changelog is now showing on the site, and in the process I realized that I have at some point made a mistake and miscounted the total number of curl releases. Off-by one actually. The official count now says that the next release will become the 188th.
As a bonus from this work, the “releaselog” page is now complete and shows details for all curl releases ever. (Also, note that we provide all that info in a CSV file too if you feel like playing with the data.)
There’s a little caveat on the updated vulnerability information there: when we note how far vulnerabilities go, we have made it a habit to sometimes mark the first vulnerable version as “6.0” if the bad code exists in the first ever git imported code – simply because going back further and checking isn’t easy and usually isn’t worth the effort because that old versions are not used anymore.
Therefore, we will not have accurate vulnerability information for versions before 6.0. The vulnerability table will only show versions back to 6.0 for that reason.
Many bug-fixes
With the complete data, we also get complete numbers. Since the birth of curl until version 7.67.0 we have fixed exactly 5,664 bugs shipped in releases, and there were exactly 7,901 days between the 4.0 the 7.67.0 releases.
The largest ever single-shot monetary donation to the curl project just happened when indeed.com graciously boosted our economy with 10,000 USD. (It happened before the new year but as I was away then I haven’t had the chance to blog about it until now.)
curl remains a small project with no major financial backing, with no umbrella organization (*) and no major company sponsorships.
curl is not a legal, registered organization or company or anything that can actually hold on to assets such as money. In any country.
What we do have however, is a “collective” over at Open Collective. Skip over there to make monetary donations. Over there you also get a complete look into previous donations with full transparency as to what funds we have and spend in the project.
Money donated to us will only be spent on project related activities.
Other ways to donate to the project is of course to donate time and effort. Allow your employees to help out or spend your own time at writing code, fixing bugs or extend the documentation. Every little bit helps and will be appreciated!
We currently have two primary expenses in the project that aren’t already covered by sponsors:
The curl bug bounty. We’ve already discussed internally that we should try to raise the amounts we hand out as rewards for the flaws we get reported going forward. We started out carefully since we didn’t want to drain the funds immediately, but time has shown that we haven’t received so many reports and the funds are growing. This means we will raise the rewards levels to encourage researchers to dig deeper.
The annual curl up developers conference. I’d like us to sponsor top contributors’ and possibly student developers’ travels to enable a larger attendance – and a social development team dinner! The next curl up will take place in Berlin in May 2020.
(*) = curl has previously applied for membership in both Software Freedom Conservancy and Linux Foundation as they seemed like suitable stewards, but the first couldn’t accept us due to work load and the latter didn’t even bother to respond. It’s not a big bother, just reality.