2019 is special in my heart. 2019 was different than many other years to me in several ways. It was a great year! This is what 2019 was to me.
curl and wolfSSL
I quit Mozilla last year and in the beginning of the year I could announce that I joined wolfSSL. For the first time in my life I could actually work with curl on my day job. As the project turned 21 I had spent somewhere in the neighborhood of 15,000 unpaid spare time hours on it and now I could finally do it “for real”. It’s huge.
Just in November 2018 the name HTTP/3 was set and this year has been all about getting it ready. I was proud to land and promote HTTP/3 in curl just before the first browser (Chrome) announced their support. The standard is still in progress and we hope to see it ship not too long into next year.
curl
Focusing on curl full time allows a different kind of focus. I’ve landed more commits in curl during 2019 than any other year going back all the way to 2005. We also reached 25,000 commits and 3,000 forks on github.
We’ve added HTTP/3, alt-svc, parallel transfers in the curl tool, tiny-curl, fixed hundreds of bugs and much, much more. Ten days before the end of the year, I’ve authored 57% (over 700) of all the commits done in curl during 2019.
We also (re)started our own curl Bug Bounty in 2019 together with Hackerone and paid over 1000 USD in rewards through-out the year. It was so successful we’re determined to raise the amounts significantly going into 2020.
Public speaking
I’ve done 28 talks in six countries. A crazy amount in front of a lot of people.
When Github had their Github Universe event in November and talked about their new sponsors program on stage (which I am part of, you can sponsor me) this huge quote of mine was shown on the big screen.
Maybe not media, but in no less than two Mr Robot episodes we could see curl commands in a TV show!
The Internet Museum translated to Swedish becomes “internetmuseum“. It is a digital, online-only, museum that collects Internet- and Web related historical information, especially focused on the Swedish angle to all of this. It collects stories from people who did the things. The pioneers, the ground breakers, the leaders, the early visionaries. Most of their documentation is done in the form of video interviews.
I was approached and asked to be part of this – as an Internet Pioneer. Me? Internet Pioneer, really?
I’m humbled and honored to be considered and I certainly had a lot of fun doing this interview. To all my friends not (yet) fluent in Swedish: here’s your grand opportunity to practice, because this is done entirely in this language of curl founders and muppet chefs.
Back in the morning of October 18th 2019, two guys showed up as planned at my door and I let them in. One of my guests was a photographer who set up his gear in my living room for the interview, and then me and and guest number two, interviewer Jörgen, sat down and talked for almost an hour straight while being recorded.
The result can be seen here below.
The Science museum was first
This is in fact the second Swedish museum to feature me.
I have already been honored with a display about me, at the Tekniska Museet in Stockholm, the “Science museum” which has an exhibition about past Polhem Prize award winners.
Information displayed about me at the Swedish Science museum in Stockholm. I have a private copy of the cardboard posters.
In the curl project we produce and ship a rock solid and reliable library for the masses, we must never exit, leak memory or do anything in an ungraceful manner. We must free all resources and error out nicely whatever problem we run into at whatever moment in the process.
To help us stay true to this, we have a way of testing we call “torture tests”. They’re very effective error path tests. They work like this:
Torture tests
They require that the code is built with a “debug” option.
The debug option adds wrapper functions for a lot of common functions that allocate and free resources, such as malloc, fopen, socket etc. Fallible functions provided by the system curl runs on.
Each such wrapper function logs what it does and can optionally either work just like it normally does or if instructed, return an error.
When running a torture test, the complete individual test case is first run once, the fallible function log is analyzed to count how many fallible functions this specific test case invoked. Then the script reruns that same test case that number of times and for each iteration it makes another of the fallible functions return error.
First make function 1 return an error. Then make function 2 return and error. Then 3, 4, 5 etc all the way through to the total number. Right now, a typical test case uses between 100 and 200 such function calls but some have magnitudes more.
The test script that iterates over these failure points also verifies that none of these invokes cause a memory leak or a crash.
Very slow
Running many torture tests takes a long time.
This test method is really effective and finds a lot of issues, but as we have thousands of tests and this iterative approach basically means they all need to run a few hundred times each, completing a full torture test round takes many hours even on the fastest of machines.
In the CI, most systems don’t allow jobs to run more than an hour.
The net result: the CI jobs only run torture tests on a few selected test cases and virtually no human ever runs the full torture test round due to lack of patience. So most test cases end up never getting “tortured” and therefore we miss out verifying error paths even though we can and we have the tests for it!
But what if…
It struck me that when running these torture tests on a large amount of tests, a lot of error paths are actually identical to error paths that were already tested and will just be tested again and again in subsequent tests.
If I could identify the full code paths that were already tested, we wouldn’t have to test them again. But getting that knowledge would require insights that our test script just doesn’t have and it will be really hard to make portable to even a fraction of the platforms we run and test curl on. Not the most feasible idea.
I went with something much simpler.
I simply estimate that most test cases actually have many code paths in common with other test cases. By randomly skipping a few iterations on each test, those skipped code paths might still very well be tested in another test. As long as the skipping is random and we do a large number of tests, chances are we cover most paths anyway. I say most because it certainly will not be all.
Random skips
In my first shot at this (after I had landed to change that allows me to control the torture tests this way) I limited the number of errors to 40 per test case. Now suddenly the CI machines can actually blaze through the test cases at a much higher speed and as a result, they ran torture tests on tests we hadn’t tortured in a long time.
I call this option to the runtests.pl script --shallow.
Already on this my first attempt in doing this, I struck gold and the script highlighted code paths that would create memory leaks or even crashes!
As a direct result of more test cases being tortured, I found and fixed nine independent bugs in curl already before I could land this in the master branch, and there seems to be more failures that pop up after the merge too! The randomness involved may of course delay the detection of some problems.
Room for polishing
The test script right now uses a fixed random seed so that repeated invokes will make it work exactly the same. Which is good when you want to reproduce it elsewhere. It is bad in the way that each test will have the exact same tests skipped every test round – as long as the set of fallible functions are unmodified.
The seed can be set by a command line argument so I imagine a future improvement would be to set the random seed based on the git commit hash at the point where the tests are run, or something. That way, torture tests on subsequent commits would get a different random spread.
Alternatively, I will let the CI systems use a true random seed to make it test a different set every time independent of git etc – as when it detects an error the informational output will still be enough for a user to reproduce the problem without the need of a seed.
Further, I’ve started out running --shallow=40 (on the Ubuntu version) which is highly unscientific and arbitrary. I will experiment altering this amount both up and down a bit to see what I learn from that.
Torture via strace?
Another idea that’s been brewing in my head for a while but I haven’t yet actually attempted to do this.
The next level of torture testing is probably to run the tests with strace and use its error injection ability, as then we don’t even need to build a debug version of our code and we don’t need to write wrapper code etc.
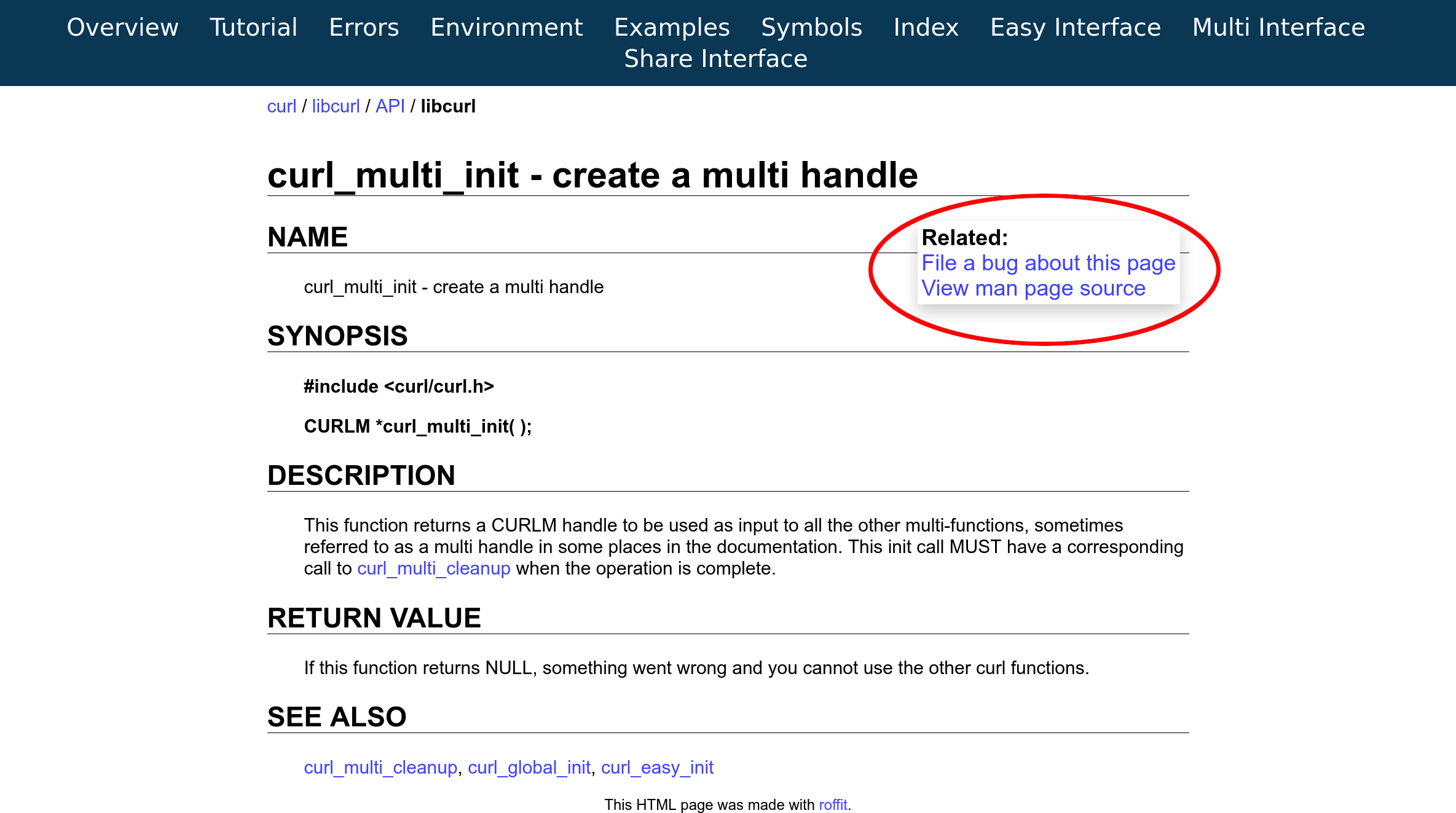
After I watched a talk by Marcus Olsson about docs as code (at foss-sthlm on December 12 2019), I got inspired to provide links on the curl web site to make it easier for users to report bugs on documentation.
Starting today, there are two new links on the top right side of all libcurl API function call documentation pages.
File a bug about this page – takes the user directly to a new issue in the github issue tracker with the title filled in with the name of the function call, and the label preset to ‘documentation’. All there’s left is for the user to actually provide a description of the problem and pressing submit (and yeah, a github account is also required).
View man page source – instead takes the user over to browsing that particular man pages’s source file in the github source code repository.
Click the image for full resolution version.
Since this is also already live on the site, you can also browse the documentation there. Like for example the curl_easy_init man page.
If you find mistakes or omissions in the docs – no matter how big or small – feel free to try out these links!
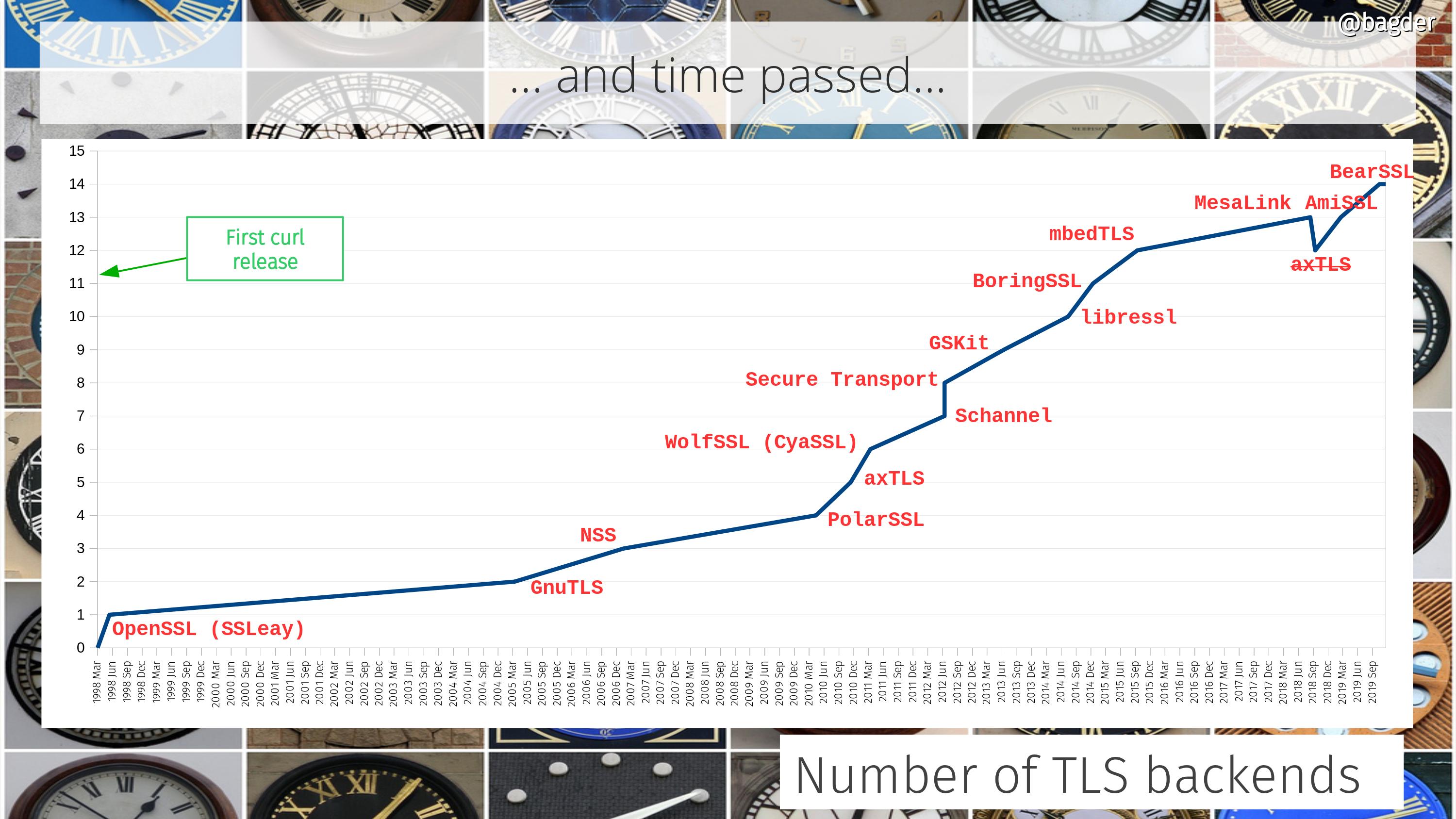
curl supports more TLS libraries than any other software I know of. The current count stops at 14 different ones that can be used to power curl’s TLS-based protocols (HTTPS primarily, but also FTPS, SMTPS, POP3S, IMAPS and so on).
The beginning
The very first curl release didn’t have any TLS support, but already in June 1998 we shipped the first version that supported HTTPS. Back in those days the protocol was still really SSL. The library we used then was called SSLeay. (No, I never understood how that’s supposed to be pronounced)
The SSLeay library became OpenSSL very soon after but the API was brought along so curl supported it from the start.
More than one
In the spring of 2005 we merged the first support for building curl with a different TLS library. It was GnuTLS, which comes under a different license than OpenSSL and had a slightly different feature set. The race had began.
BearSSL
A short while ago and in time to get shipped in the coming 7.68.0 release (set to ship on January 8th 2020), the 14th TLS backend was merged into the curl source tree in the shape of support for BearSSL. BearSSL is a TLS library aimed at smaller devices and is perhaps lacking a bit in features (like no TLS 1.3 for example) but has still been requested by users in the past.
Multi-SSL
Since September 2017, you can even build libcurl to support one or more TLS libraries in the same build. When built that way, users can select which TLS backend curl should use at each start-up. A feature used and appreciated by for example git for Windows.
Time line
Below is an attempt to visualize how curl has grown in this area. Number of supported TLS backends over time, from the first curl release until today. The image comes from a slide I intend to use in a future curl presentation. A notable detail on this graph is the removal of axTLS support in late 2018 (removed in 7.63.0). PolarSSL is targeted to meet the same destiny in February 2020 since it gets no updates anymore and has in practice already been replaced by mbedTLS.
Click the image to enjoy the full resolution version!
QUIC and TLS
If you’ve heard me talk about HTTP/3 (h3) and QUIC (like my talk at Full Stack Fest 2019), you already know that QUIC needs new APIs from the TLS libraries.
For h3 support to become reality in curl shipped in distros etc, the TLS library curl is set to use needs to provide a QUIC compatible API and the QUIC/h3 library curl uses then needs to support that.
It is likely that some TLS libraries are going to be fast with providing such APIs and some are going be (very) slow. Their particular individual abilities combined with the desire to ship curl with h3 support is likely going to affect what TLS library you will see used by curl in your distro will affect what TLS library you will build your own curl builds to use in the future.
Credits
The recently added BearSSL backend was written by Michael Forney. Top image by LEEROY Agency from Pixabay
The Mr Robot TV series features a security expert and hacker lead character, Elliot.
Season 4, episode 8
Vasilis Lourdas reported that he did a “curl sighting” in the show and very well I took a closer peek and what do we see some 37 minutes 36 seconds into episode 8 season 4…
(I haven’t followed the show since at some point in season two so I cannot speak for what actually has happened in the plot up to this point. I’m only looking at and talking about what’s on the screenshots here.)
Elliot writes Python. In this Python program, we can see two curl invokes, both unfortunately a blurry on the right side so it’s hard to see them exactly (the blur is really there in the source and I couldn’t see/catch a single frame without it). Fortunately, I think we get some additional clues later on in episode 10, see below.
He invokes curl with -i to see the response header coming back but then he makes some questionable choices. The -k option is the short version of --insecure. It truly makes a HTTPS connection insecure since it completely switches off the CA cert verification. We all know no serious hacker would do that in a real world use.
Perhaps the biggest problem for me is however the following -X POST. In itself it doesn’t have to be bad, but when taking the second shot from episode 10 into account we see that he really does combine this with the use of -d and thus the -X is totally superfluous or perhaps even wrong. The show technician who wrote this copied a bad example…
The -b that follows is fun. That sets a specific cookie to be sent in the outgoing HTTP request. The random look of this cookie makes it smell like a session cookie of some sorts, which of course you’d rarely then hard-code it like this in a script and expect it to be of use at a later point. (Details unfold later.)
Season 4, episode 10
Lucas Pardue followed-up with this second sighting of curl from episode 10, at about 23:24. It appears that this might be the python program from episode 8 that is now made to run on or at least with a mobile phone. I would guess this is a session logged in somewhere else.
In this shot we can see the command line again from episode 8.
We learn something more here. The -b option didn’t specify a cookie – because there’s no = anywhere in the argument following. It actually specified a file name. Not sure that makes anything more sensible, because it seems weird to purposely use such a long and random-looking filename to store cookies in…
Here we also see that in this POST request it passes on a bank account number, a “coin address” and amountOfCoins=3684210526.31579 to this URL: https://buy-crypto-coin.net/purchase, and it gets 200 OK back from a HTTP/1.1 server.
I don’t have the cookie file so it can’t be repeated completely. What did I learn?
First: OpenSSL 1.1.1 doesn’t even want to establish a TLS connection against this host and says dh key too small. So in order to continue this game I took to a curl built with a TLS library that didn’t complain on this silly server.
Next: I learned that the server responding on this address (because there truly is a HTTPS server there) doesn’t have this host name in its certificate so -k is truly required to make curl speak to this host!
Then finally it didn’t actually do anything fun that I could notice. How boring. It just responded with a 301 and Location: http://www.buy-crypto-coin.net. Notice how it redirects away from HTTPS.
What’s on that site? A rather good-looking fake cryptocurrency market site. The links at the bottom all go to various NBC Universal and USA Network URLs, which I presume are the companies behind the TV series. I saved a screenshot below just in case it changes.
curl_multi_wakeup() is a new friend in the libcurl API family. It will show up for the first time in the upcoming 7.68.0 release, scheduled to happen on January 8th 2020.
Sleeping is important
One of the core functionalities in libcurl is the ability to do multiple parallel transfers in the same thread. You then create and add a number of transfers to a multi handle. Anyway, I won’t explain the entire API here but the gist of where I’m going with this is that you’ll most likely sooner or later end up calling the curl_multi_poll() function which asks libcurl to wait for activity on any of the involved transfers – or sleep and don’t return for the next N milliseconds.
Calling this waiting function (or using the older curl_multi_wait() or even doing a select() or poll() call “manually”) is crucial for a well-behaving program. It is important to let the code go to sleep like this when there’s nothing to do and have the system wake up it up again when it needs to do work. Failing to do this correctly, risk having libcurl instead busy-loop somewhere and that can make your application use 100% CPU during periods. That’s terribly unnecessary and bad for multiple reasons.
Wakey wakey
When your application calls libcurl to say “sleep for a second or until something happens on these N transfers” and something happens and the application for example needs to shut down immediately, users have been asking for a way to do a wake up call.
– Hey libcurl, wake up and return early from the poll function!
You could achieve this previously as well, but then it required you to write quite a lot of extra code, plus it would have to be done carefully if you wanted it to work cross-platform etc. Now, libcurl will provide this utility function for you out of the box!
curl_multi_wakeup()
This function explicitly makes a curl_multi_poll() function return immediately. It is designed to be possible to use from a different thread. You will love it!
curl_multi_poll()
This is the only call that can be woken up like this. Old timers may recognize that this is also a fairly new function call. We introduced it in 7.66.0 back in September 2019. This function is very similar to the older curl_multi_wait() function but has some minor behavior differences that also allow us to introduce this new wakeup ability.
Credits
This function was brought to us by the awesome Gergely Nagy.
The ETag HTTP response header is an identifier for a specific version of a resource. It lets caches be more efficient and save bandwidth, as a web server does not need to resend a full response if the content has not changed. Additionally, etags help prevent simultaneous updates of a resource from overwriting each other (“mid-air collisions”).
In short, a server can include this header when it responds with a resource, and in subsequent requests when a client wants to get an updated version of that document it sends back the same ETag and says “please give me a new version if it doesn’t match this ETag anymore”. The server will then respond with a 304 if there’s nothing new to return.
It is a better way than modification time stamp to identify a specific resource version on the server.
ETag options
Starting in version 7.68.0 (due to ship on January 8th, 2020), curl will feature two new command line options that makes it easier for users to take advantage of these features. You can of course try it out already now if you build from git or get a daily snapshot.
The ETag options are perfect for situations like when you run a curl command in a cron job to update a file if it has indeed changed on the server.
--etag-save <filename>
Issue the curl command and if there’s an ETag coming back in the response, it gets saved in the given file.
--etag-compare <filename>
Load a previously stored ETag from the given file and include that in the outgoing request (the file should only consist of the specific ETag “value” and nothing else). If the server deems that the resource hasn’t changed, this will result in a 304 response code. If it has changed, the new content will be returned.
Update the file if newer than previously stored ETag:
The other method to accomplish something similar is the -z (or --time-cond) option. It has been supported by curl since the early days. Using this, you give curl a specific time that will be used in a conditional request. “only respond with content if the document is newer than this”:
curl -z "5 dec 2019" https:/example.com
You can also do the inversion of the condition and ask for the file to get delivered only if it is older than a certain time (by prefixing the date with a dash):
curl -z "-1 jan 2003" https://example.com
Perhaps this is most conveniently used when you let curl get the time from a file. Typically you’d use the same file that you’ve saved from a previous invocation and now you want to update if the file is newer on the remote site:
It could be noted that these new features are built entirely in the curl tool by using libcurl correctly with the already provided API, so this change is done entirely outside of the library.
Credits
The idea for the ETag goodness came from Paul Hoffman. The implementation was brought by Maros Priputen – as his first contribution to curl! Thanks!
By late 2019, there’s an estimated amount of ten billion curl installations in the world. Of course this is a rough estimate and depends on how you count etc.
There are several billion mobile phones and tablets and a large share of those have multiple installations of curl. Then there all the Windows 10 machines, web sites, all macs, hundreds of millions of cars, possibly a billion or so games, maybe half a billion TVs, games consoles and more.
How much data are they transferring?
In the high end of volume users, we have at least two that I know of are doing around one million requests/sec on average (and I’m not even sure they are the top users, they just happen to be users I know do high volumes) but in the low end there will certainly be a huge amount of installations that barely ever do any requests at all.
If there are two users that I know are doing one million requests/sec, chances are there are more and there might be a few doing more than a million and certainly many that do less but still many.
Among many of the named and sometimes high profiled apps and users I know use curl, I very rarely know exactly for what purpose they use curl. Also, some use curl to do very many small requests and some will use it to do a few but very large transfers.
Additionally, and this really complicates the ability to do any good estimates, I suppose a number of curl users are doing transfers that aren’t typically considered to be part of “the Internet”. Like when curl is used for doing HTTP requests for every single subway passenger passing ticket gates in the London underground, I don’t think they can be counted as Internet transfers even though they use internet protocols.
How much data are browsers driving?
According to some data, there is today around 4.388 billion “Internet users” (page 39) and the world wide average time spent “on the Internet” is said to be 6 hours 42 minutes (page 50). I think these numbers seem credible and reasonable.
According to broadbandchoices, an average hour of “web browsing” spends about 25MB. According to databox.com, an average visit to a web site is 2-3 minutes. httparchive.org says the median page needs 74 HTTP requests to render.
So what do users do with their 6 hours and 42 minutes “online time” and how much of it is spent in a browser? I’ve tried to find statistics for this but failed.
@chuttenc (of Mozilla) stepped up and helped me out with getting stats from Firefox users. Based on stats from users that used Firefox on the day of October 1, 2019 and actually used their browser that day, they did 2847 requests per client as median with the median download amount 18808 kilobytes. Of that single day of use.
I don’t have any particular reason to think that other browsers, other days or users of other browsers are very different than Firefox users of that single day. Let’s count with 3,000 requests and 20MB per day. Interestingly, that makes the average data size per request a mere 6.7 kilobytes.
A median desktop web page total size is 1939KB right now according to httparchive.org (and the mobile ones are just slightly smaller so the difference isn’t too important here).
Based on the median weight per site from httparchive, this would imply that a median browser user visits the equivalent of 15 typical sites per day (30MB/1.939MB).
If each user spends 3 minutes per site, that’s still just 45 minutes of browsing per day. Out of the 6 hours 42 minutes. 11% of Internet time is browser time.
3000 requests x 4388000000 internet users, makes 13,164,000,000,000 requests per day. That’s 13.1 trillion HTTP requests per day.
The world’s web users make about 152.4 million HTTP requests per second.
(I think this is counting too high because I find it unlikely that all internet users on the globe use their browsers this much every day.)
The equivalent math to figure out today’s daily data amounts transferred by browsers makes it 4388000000 x 30MB = 131,640,000,000 megabytes/day. 1,523,611 megabytes per second. 1.5 TB/sec.
30MB/day equals a little under one GB/month per person. Feels about right.
Back to curl usage
The curl users with the highest request frequencies known to me (*) are racing away at one million requests/second on average, but how many requests do the others actually do? It’s really impossible to say. Let’s play the guessing game!
First, it feels reasonable to assume that these two users that I know of are not alone in doing high frequency transfers with curl. Purely based on probability, it seems reasonable to assume that the top-20 something users together will issue at least 10 million requests/second.
Looking at the users that aren’t in that very top. Is it reasonable to assume that each such installed curl instance makes a request every 10 minutes on average? Maybe it’s one per every 100 minutes? Or is it 10 per minute? There are some extremely high volume and high frequency users but there’s definitely a very long tail of installations basically never doing anything… The grim truth is that we simply cannot know and there’s no way to even get a ballpark figure. We need to guess.
Let’s toy with the idea that every single curl instance on average makes a transfer, a request, every tenth minute. That makes 10 x 10^9 / 600 = 16.7 million transfers per second in addition to the top users’ ten million. Let’s say 26 million requests per second. The browsers of the world do 152 million per second.
If each of those curl requests transfer 50Kb of data (arbitrarily picked out of thin air because again we can’t reasonably find or calculate this number), they make up (26,000,000 x 50 ) 1.3 TB/sec. That’s 85% of the data volume all the browsers in the world transfer.
The world wide browser market share distribution according to statcounter.com is currently: Chrome at 64%, Safari at 16.3% and Firefox at 4.5%.
This simple-minded estimate would imply that maybe, perhaps, possibly, curl transfers more data an average day than any single individual browser flavor does. Combined, the browsers transfer more.
Guesses, really?
Sure, or call them estimates. I’m doing them to the best of my ability. If you have data, reasoning or evidence to back up modifications my numbers or calculations that you can provide, nobody would be happier than me! I will of course update this post if that happens!
(*) = I don’t name these users since I’ve been given glimpses of their usage statistics informally and I’ve been asked to not make their numbers public. I hold my promise by not revealing who they are.
Thanks
Thanks to chuttenc for the Firefox numbers, as mentioned above, and thanks also to Jan Wildeboer for helping me dig up stats links used in this post.