

After another eight week cycle was been completed, curl shipped a new release into the world. 7.65.0 brings some news and some security fixes but is primarily yet again a set of bug-fixes bundled up. Remember 7.64.1?
As always, download it straight from curl.haxx.se!
One fun detail on this release: we have 500 less lines of source code in the lib/ directory compared to the previous release!
Things that happened in curl since last release:
- we announced a new Bug Bounty program and already paid the first rewards
- curl up 2019 happened and was awesome
- at wolfSSL we announced the tinycurl effort
- we’re running the annual curl survey right now
- we’ve welcomed new sponsors
Numbers
the 181st release
3 changes
56 days (total: 7,733)
119 bug fixes (total: 5,148)
215 commits (total: 24,326)
0 new public libcurl function (total: 80)
1 new curl_easy_setopt() option (total: 267)
0 new curl command line option (total: 221)
50 contributors, 24 new (total: 1,953)
32 authors, 12 new (total: 681)
2 security fixes (total: 89)
350 USD paid in Bug Bounties
News
- libcurl has deprecated support for the global DNS cache.
- Pipelining support is now completely removed from curl.
- CURLOPT_MAXAGE_CONN is a new option that controls how long to keep a live connection in the connection cache for reuse.
Security
This release comes with fixes for two separate security problems. Both rated low risk. Both reported via the new bug bounty program.
CVE-2019-5435 is an issue in the recently introduced URL parsing API. It is only a problem in 32 bit architectures and only if an application can be told to pass in ridiculously long (> 2GB) strings to libcurl. This bug is similar in nature to a few other bugs libcurl has had in the past, and to once and for all combat this kind of flaw libcurl now (in 7.65.0 and forward) has a “maximum string length” limit for strings that you can pass to it using its APIs. The maximum size is 8MB. (The reporter was awarded 150 USD for this find.)
CVE-2019-5436 is a problem in the TFTP code. If an application decides to uses a smaller “blksize” than 504 (default is 512), curl would overflow a buffer allocated on the heap with data received from the server. Luckily, very few people actually download data from unknown or even remote TFTP servers. Secondly, asking for a blksize smaller than 512 is rather pointless and also very rare: the primary point in changing that size is to enlarge it. (The reporter was awarded 200 USD for this find.)
Bug-fixes
Over one hundred bug-fixes landed in this release, but some of my favorites from release cycle include…
mark connection for close on TLS close_notify
close_notify is a message in the TLS protocol that means that this connection is about to close. In most circumstances that message doesn’t actually provide information to curl that is needed, but in the case the connection is closed prematurely, understanding that this message preceded the closure helps curl act appropriately. This change was done for the OpenSSL backend only as that’s where we got the bug reported and worked on it this time, but I think we might have reasons to do the same for other backends going forward!
show port in the verbose “Trying …” message
The verbose message that says “Trying 12.34.56.78…” means that curl has sent started a TCP connect attempt to that IP address. This message has now been modified to also include the target port number so when using -v with curl 7.65.0, connecting to that same host for HTTPS will instead say “Trying 12.34.56.78:443…”.
To aid debugging really. I think it gives more information faster at a place you’re already looking.
new SOCKS 4+5 test server
The test suite got a brand new SOCKS server! Previously, all SOCKS tests for both version 4 and version 5 were done by firing up ssh (typically openssh). That method was decent but made it hard to do a range of tests for bad behavior, bad protocol replies and similar. With the new custom test server, we can basically add whatever test we want and we’ve already extended the SOCKS testing to cover more code and use cases than previously.
SOCKS5 user name and passwords must be shorter than 256
curl allows user names and passwords provided in URLs and as separate options to be more or less unrestricted in size and that include if the credentials are used for SOCKS5 authentication – totally ignoring the fact that the protocol SOCKS5 has a maximum size of 255 for the fields. Starting now, curl will return an error if the credentials for SOCKS5 are too long.
Warn if curl and libcurl versions do not match
The command line tool and the library are independent and separable, as in you can run one version of the curl tool with another version of the libcurl library. The libcurl API is solid enough to allow it and the tool is independent enough to not restrict it further.
We always release curl the command line tool and libcurl the library together, using the same version number – with the code for both shipped in the same single file.
There should rarely be a good reason to actually run curl and libcurl with different versions. Starting now, curl will show a little warning if this is detected as we have learned that this is almost always a sign of an installation or setup mistake. Hopefully this message will aid people to detect the mistake earlier and easier.
Better handling of “–no-” prefixed options
curl’s command line parser allows users to switch off boolean options by prefixing them with dash dash no dash. For example we can switch off compressed responses by using “–no-compression” since there regular option “–compression” switches it on.
It turned out we stripped the “–no-” thing no regarding if the option was boolean or not and presumed the logic to handle it – which it didn’t. So users could actually pass a proxy string to curl with the regular option “–proxy” as well as “–no-proxy”. The latter of course not making much sense and was just due to an oversight.
In 7.65.0, only actual boolean command line options can be used with “–no-“. Trying it on other options will cause curl to report error for it.
Add CURLUPART_ZONEID to the URL API
Remember when we added a new URL parsing API to libcurl back in 7.62.0? It wasn’t even a year ago! When we did this, we also changed the internals to use the same code. It turned out we caused a regression when we parsed numerical IPv6 addresses that provide the zone ID within the string. Like this: “https://[ffe80::1%25eth0]/index.html”
Starting in this release, you can both set and get the zone ID in a URL using the API, but of course setting it doesn’t do anything unless the host is a numeric IPv6 address.
parse proxy with the URL parser API
We removed the separate proxy string parsing logic and instead switched that over to more appropriately use the generic URL parser for this purpose as well. This move reduced the code size, made the code simpler and makes sure we have a unified handling of URLs! Everyone is happy!
longer URL schemes
I naively wrote the URL parser to handle scheme names as long as the longest scheme we support in curl: 8 bytes. But since the parser can also be asked to parse URLs with non-supported schemes, that limit was a bit too harsh. I did a quick research, learned that the longest currently registered URI scheme is 36 characters (“microsoft.windows.camera.multipicker”). Starting in this release , curl accepts URL schemes up to 40 bytes long.
Coming up next
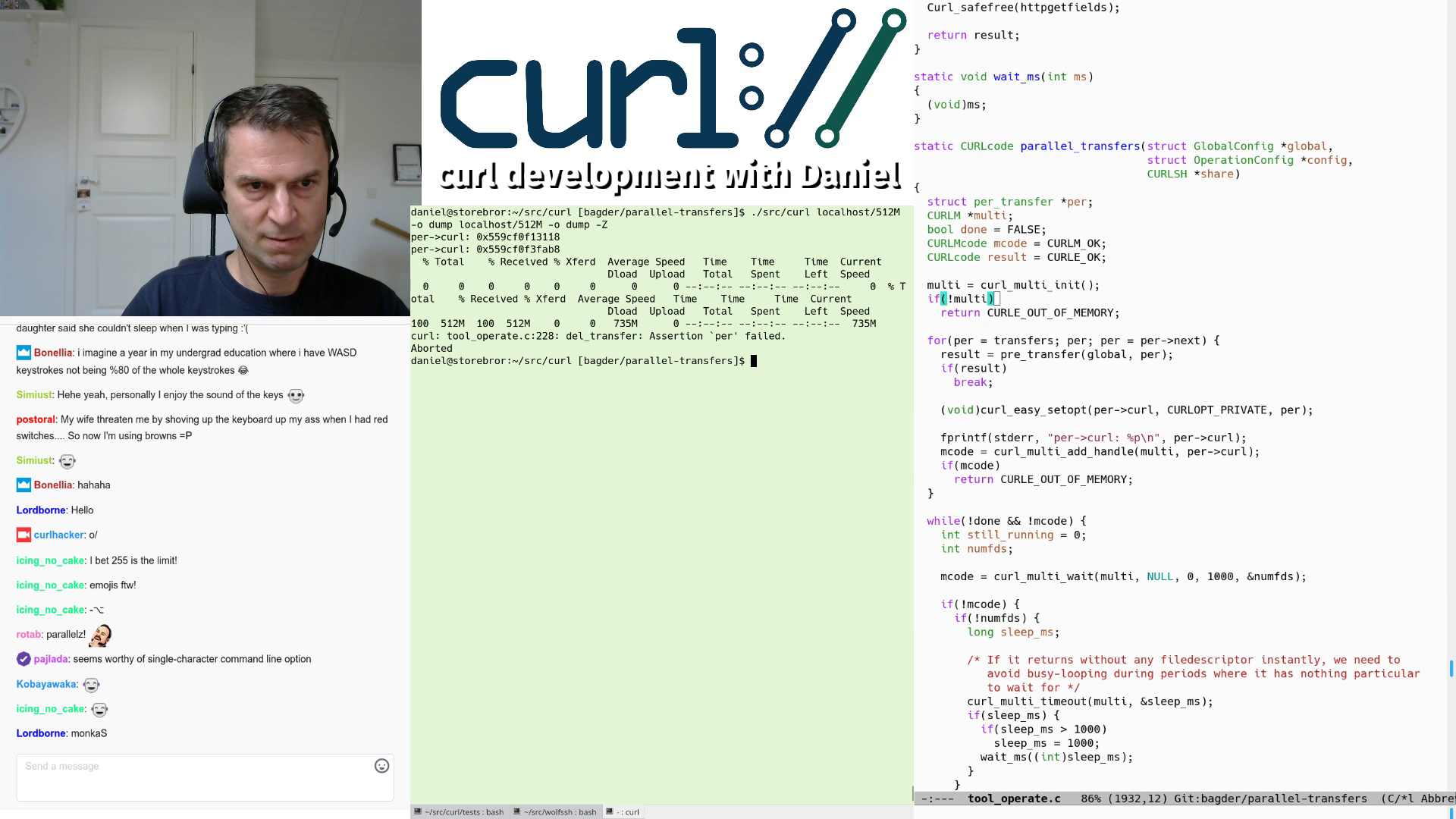
There’s several things brewing in the background that might be ready to show in next release. Parallel transfers in the curl tool and deprecating PolarSSL support seem likely to happen for example. Less likely for this release, but still being worked on slowly, is HTTP/3 support.
We’re also likely to get a bunch of changes and fine features we haven’t even thought about from our awesome contributors. In eight weeks I hope to write another one of these blog posts explaining what went into that release…










{kind=link}