I spend a large portion of my days answering questions and helping people use curl and libcurl. With more than 200 command line options it certainly isn’t always easy to find the correct ones, in combination with the Internet and protocols being pretty complicated things at times… not to mention the constant problem of bad advice. Like code samples on stackoverflow that repeats non-recommended patterns.
The notorious -X abuse is a classic example, or why not the widespread disease called too much use of the –insecure option (at a recent count, there were more than 118,000 instances of “curl --insecure” uses in code hosted by github alone).
Sending HTTP requests with curl

HTTP (and HTTPS) is by far the most used protocol out of the ones curl supports. curl can be used to issue just about any HTTP request you can think of, even if it isn’t always immediately obvious exactly how to do it.
h2c to the rescue!
h2c is a new command line tool and associated web service, that when passed a complete HTTP request dump, converts that into a corresponding curl command line. When that curl command line is then run, it will generate exactly(*) the HTTP request you gave h2c.
h2c stands for “headers to curl”.
Many times you’ll read documentation somewhere online or find a protocol/API description showing off a full HTTP request. “This is what the request should look like. Now send it.” That is one use case h2c can help out with.
Example use
Here we have an HTTP request that does Basic authentication with the POST method and a small request body. Do you know how to tell curl to send it?
The request:
POST /receiver.cgi HTTP/1.1 Host: example.com Authorization: Basic aGVsbG86eW91Zm9vbA== Accept: */* Content-Length: 5 Content-Type: application/x-www-form-urlencoded hello
I save the request above in a text file called ‘request.txt’ and ask h2c to give the corresponding curl command line:
$ ./h2c < request.txt curl --http1.1 --header User-Agent: --user "hello:youfool" --data-binary "hello" https://example.com/receiver.cgi
If we add "--trace-ascii dump” to that command line, run it, and then inspect the dump file after curl has completed, we can see that it did indeed issue the HTTP request we asked for!
Web Site
Maybe you don’t want to install another command line tool written by me in your system. The solution is the online version of h2c, which is hosted on a separate portion of the official curl web site:
The web site lets you paste a full HTTP request into a text form and the page then shows the corresponding curl command line for that request.
h2c “as a service”
Inception alert: you can also use the web version of h2c by sending over a HTTP request to it using curl. You’ll then get nothing but the correct curl command line output on stdout.
To send off the same file we used above:
curl --data-urlencode http@request.txt https://curl.se/h2c/
or of course if you rather want to pass your HTTP request to curl on stdin, that’s equally easy:
cat request.txt | curl --data-urlencode http@- https://curl.se/h2c/
Early days, you can help!
h2c was created just a few days ago. I’m sure there are bugs, issues and quirks to iron out. You can help! Files issues or submit pull-requests!
(*) = barring bugs, there are still some edge cases where the exact HTTP request won’t be possible to repeat, but where we instead will attempt to do “the right thing”.
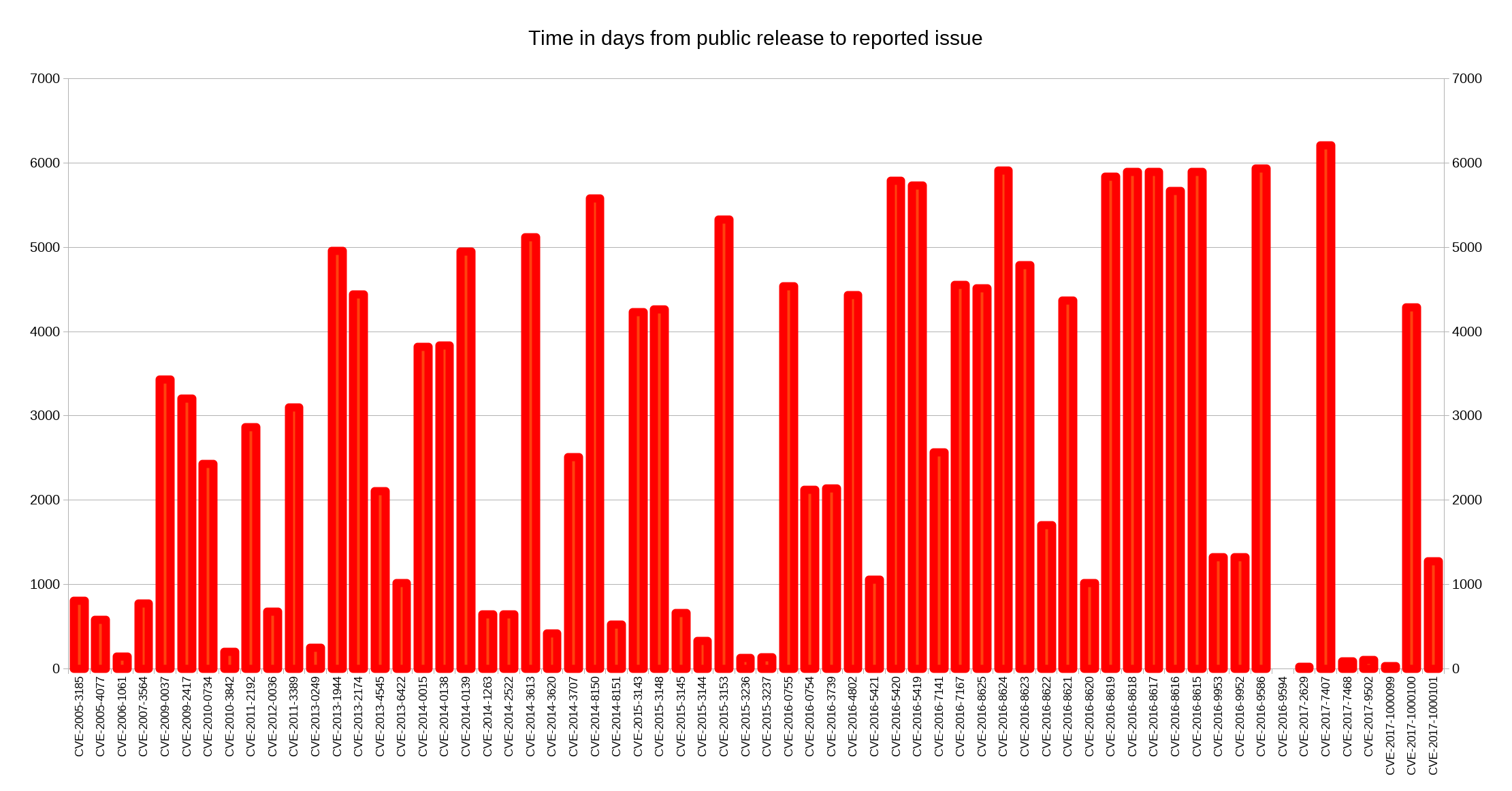
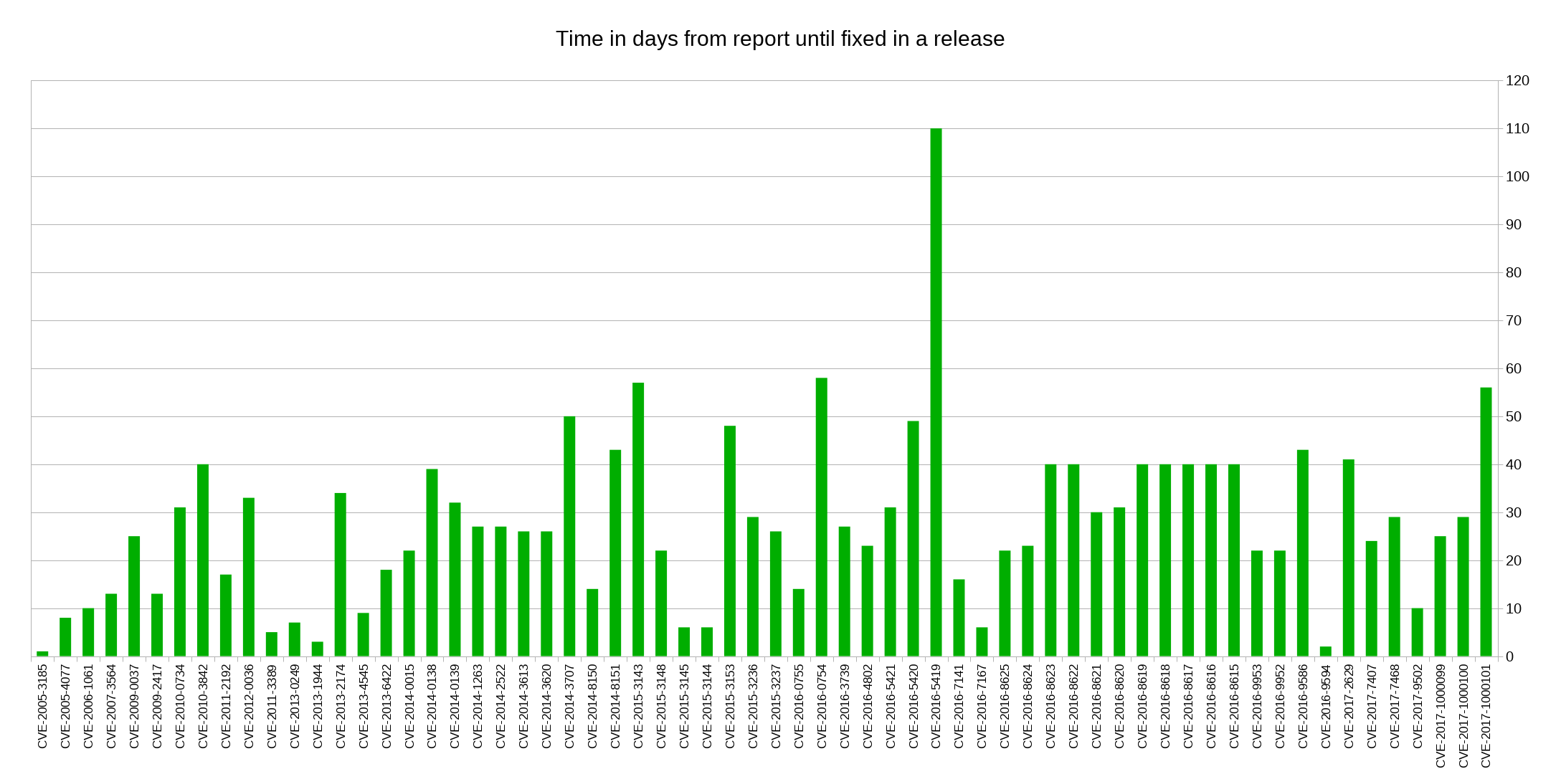
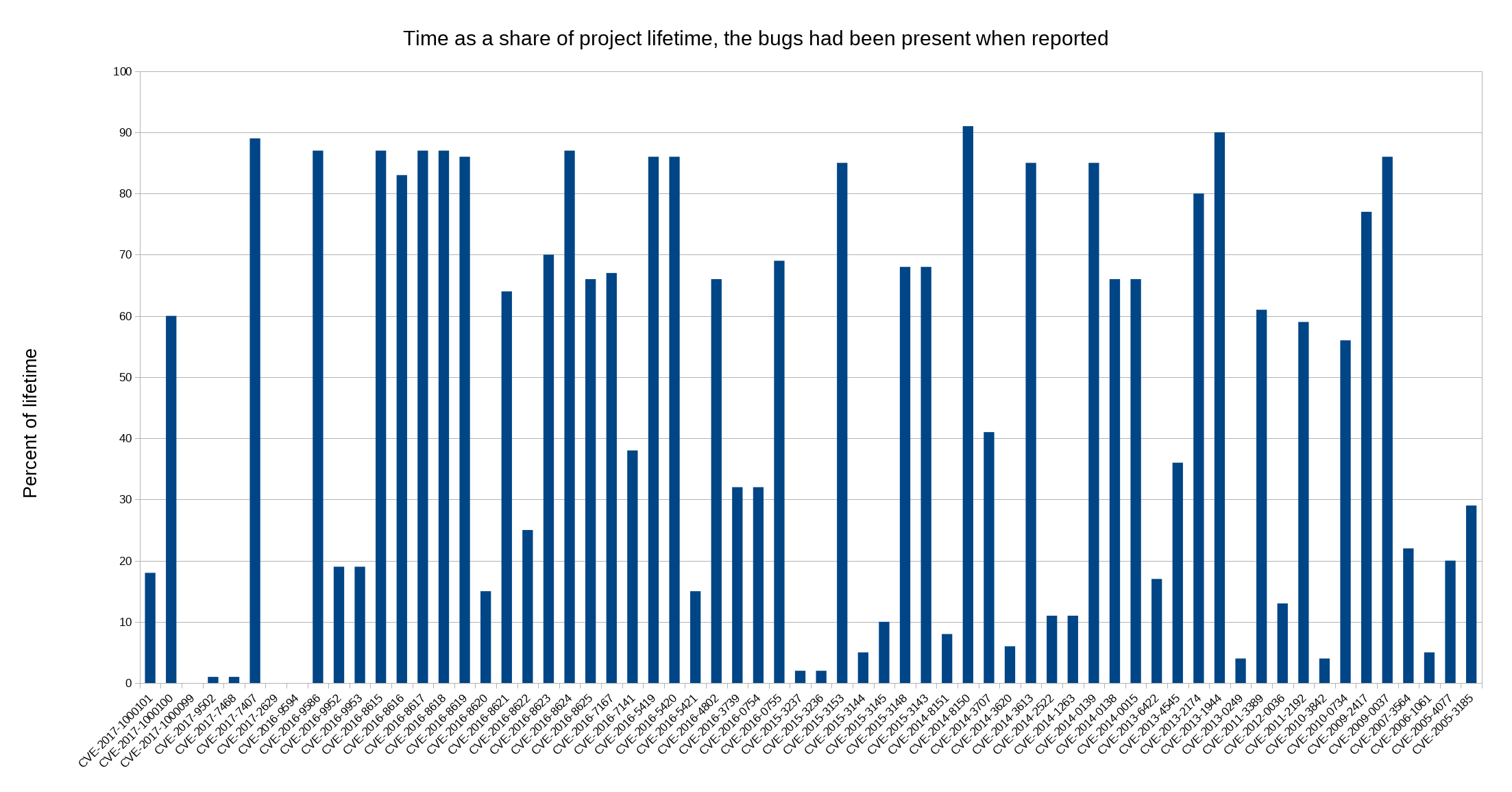
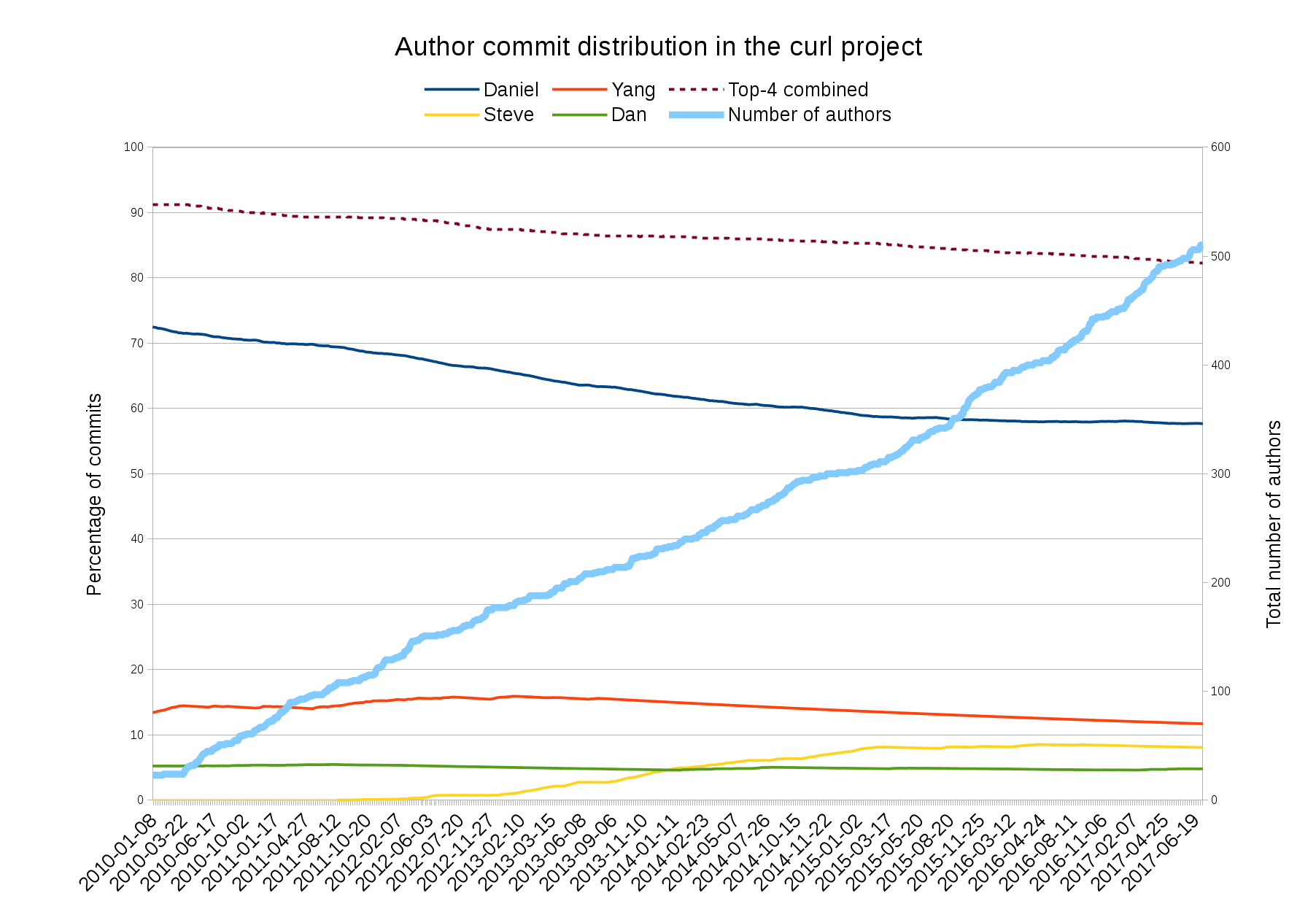
 I decided to look closer at security problems and the age of the reported issues in
I decided to look closer at security problems and the age of the reported issues in