“Probably the only person in the whole of Sweden whose code is used by all people in the world using a computer /smartphone /ATM/ etc …every day.His contribution to the world is so large that it is impossible tounderstand the breadth.“
Thank you everyone who nominated me. I’m truly grateful, honored and humbled. You, my community, is what makes me keep doing what I do. I love you all!
To list “Sweden’s best developers” (the list and site is in Swedish) seems like a rather futile task, doesn’t it? Yet that’s something the Swedish IT and technology news site Techworld has been doing occasionally for the last several years. With two, three year intervals since 2008.
Everyone reading this will of course immediately start to ponder on what developers they speak of or how they define developers and how on earth do you judge who the best developers are? Or even who’s included in the delimiter “Sweden” – is that people living in Sweden, born in Sweden or working in Sweden?
I’m certainly not alone in having chuckled to these lists when they have been published in the past, as I’ve never seen anyone on the list be even close to my own niche or areas of interest. The lists have even worked a little as a long-standing joke in places.
It always felt as if the people on the lists were found on another planet than mine – mostly just Java and .NET people. and they very rarely appeared to be developers who actually spend their days surrounded by code and programming. I suppose I’ve now given away some clues to some characteristics I think “a developer” should posses…
This year, their fifth time doing this list, they changed the way they find candidates, opened up for external nominations and had a set of external advisors. This also resulted in me finding several friends on the list that were never on it in the past.
Tonight I got called onto the stage during the little award ceremony and I was handed this diploma and recognition for landing at second place in the best developer in Sweden list.
And just to keep things safe for the future, this is how the listing looks on the Swedish list page:
Yes I’m happy and proud and humbled. I don’t get this kind of recognition every day so I’ll take this opportunity and really enjoy it. And I’ll find a good spot for my diploma somewhere around the house.
I’ll keep a really big smile on my face for the rest of the day for sure!
(Photo from the award ceremony by Emmy Jonsson/IDG)
Update
The winner was Joel Ambrahansson, in the middle on the photo above, and on third place and on the right in the photo is Mina Nakicenovic.
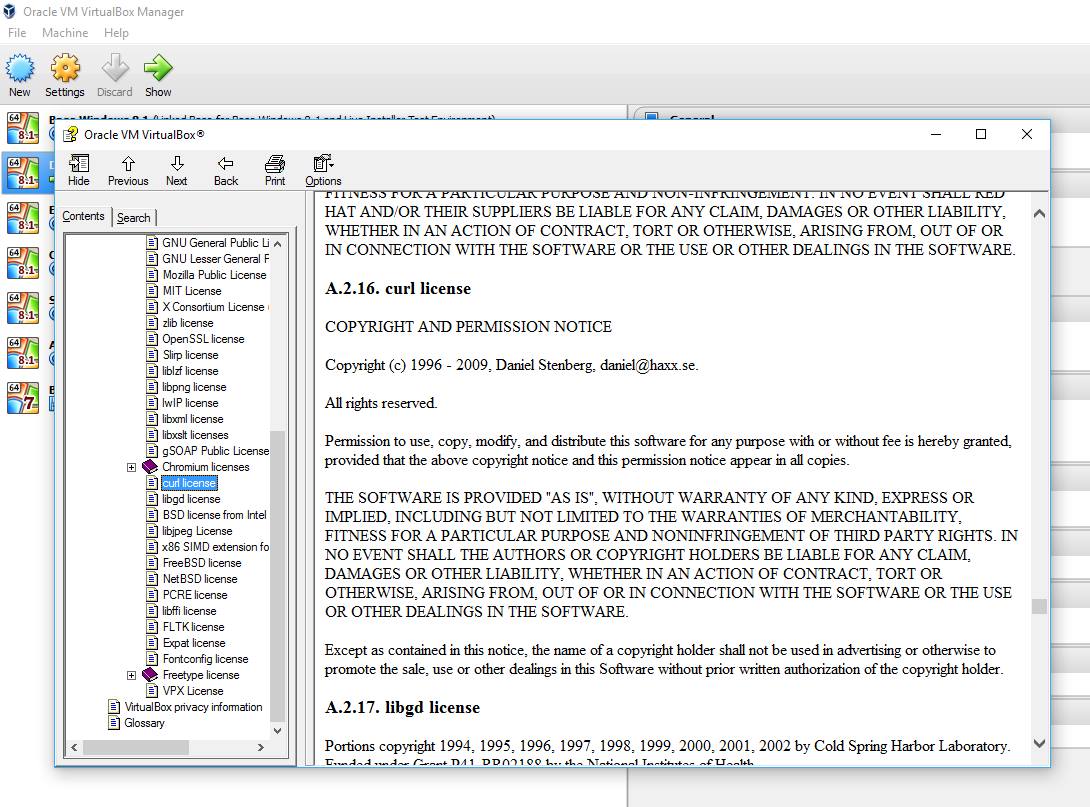
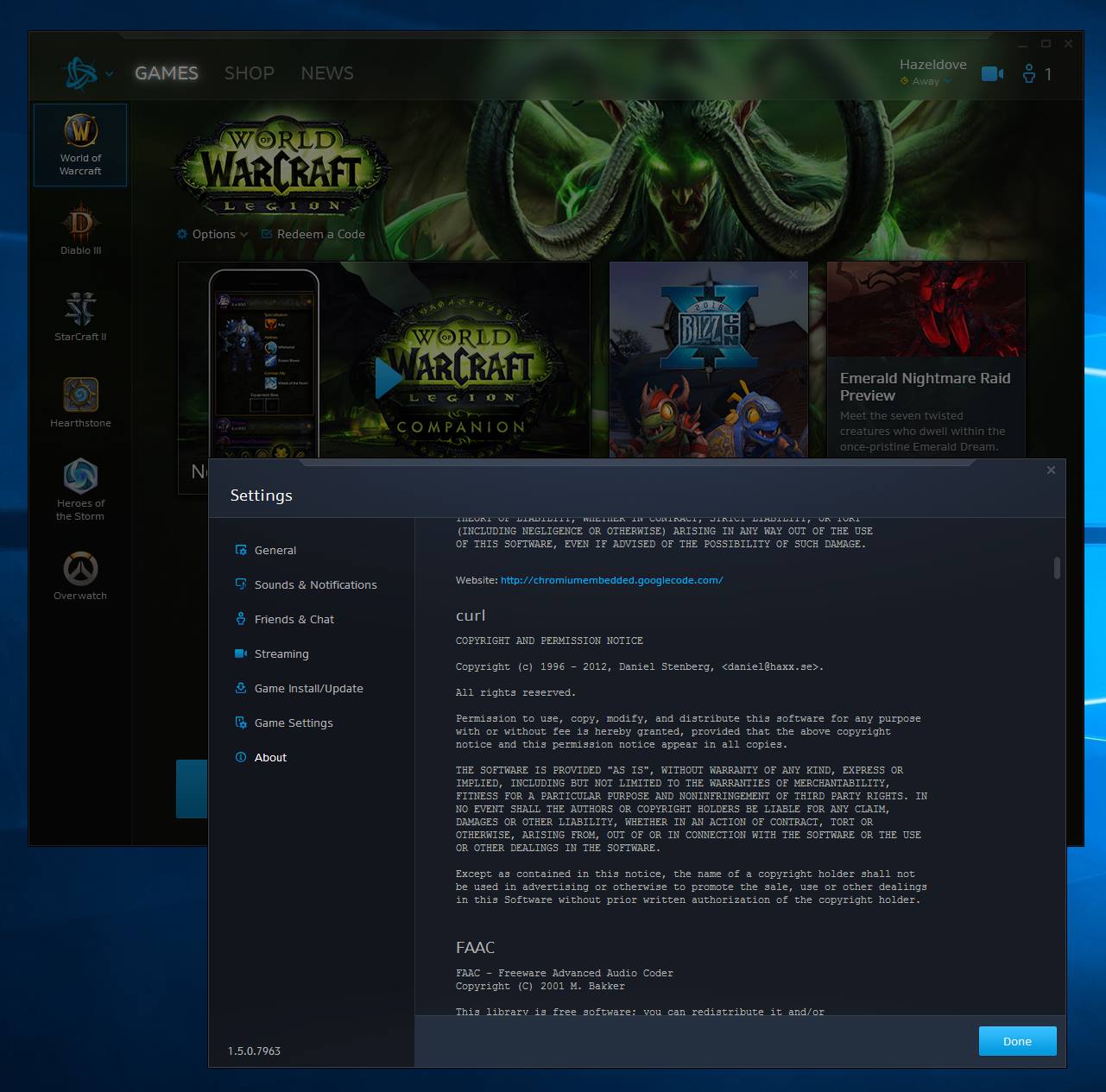
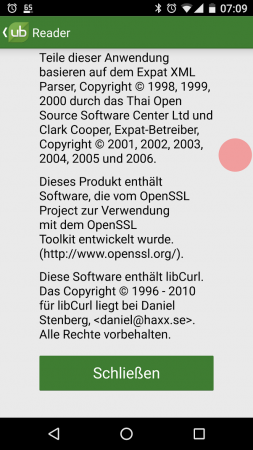
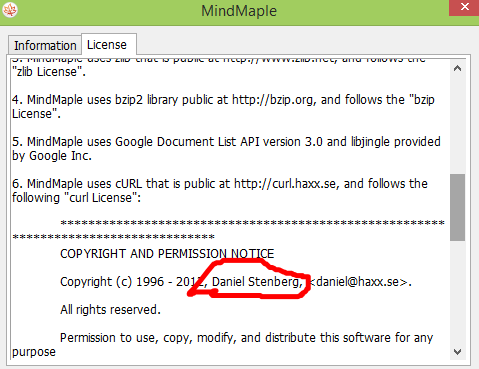
Starting in version 7.52.0 (due to ship December 21, 2016), curl will support HTTPS proxies when doing network transfers, and by doing this it joins the small exclusive club of HTTP user-agents consisting of Firefox, Chrome and not too many others.
Yes you read this correctly. This is different than the good old HTTP proxy.
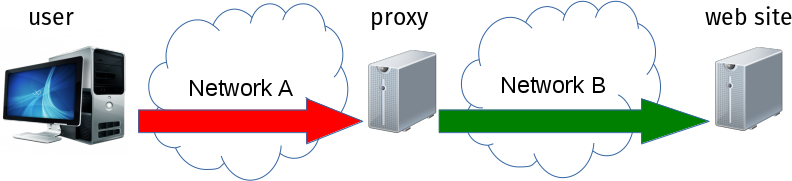
HTTPS proxy means that the client establishes a TLS connection to the proxy and then communicates over that, which is different to the normal and traditional HTTP proxy approach where the clients speak plain HTTP to the proxy.
Talking HTTPS to your proxy is a privacy improvement as it prevents people from snooping on your proxy communication. Even when using HTTPS over a standard HTTP proxy, there’s typically a setting up phase first that leaks information about where the connection is being made, user credentials and more. Not to mention that an HTTPS proxy makes HTTP traffic “safe” to and from the proxy. HTTPS to the proxy also enables clients to speak HTTP/2 more easily with proxies. (Even though HTTP/2 to the proxy is not yet supported in curl.)
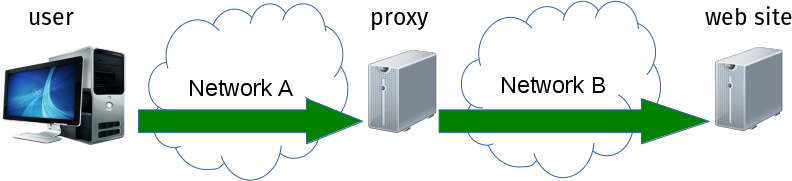
In the case where a client wants to talk HTTPS to a remote server, when using a HTTPS proxy, it sends HTTPS through HTTPS.
Illustrating this concept with images. When using a traditional HTTP proxy, we connect initially to the proxy with HTTP in the clear, and then from then on the HTTPS makes it safe:
to compare with the HTTPS proxy case where the connection is safe already in the first step:
The access to the proxy is made over network A. That network has traditionally been a corporate network or within a LAN or something but we’re seeing more and more use cases where the proxy is somewhere on the Internet and then “Network A” is really huge. That includes use cases where the proxy for example compresses images or otherwise reduces bandwidth requirements.
Actual HTTPS connections from clients to servers are still done end to end encrypted even in the HTTP proxy case. HTTP traffic to and from the user to the web site however, will still be HTTPS protected to the proxy when a HTTPS proxy is used.
A complicated pull request
This awesome work was provided by Dmitry Kurochkin, Vasy Okhin, and Alex Rousskov. It was merged into master on November 24 in this commit.
Doing this sort of major change in the TLS area in curl code is a massive undertaking, much so because of the fact that curl supports getting built with one out of 11 or 12 different TLS libraries. Several of those are also system-specific so hardly any single developer can even build all these backends on his or hers own machines.
In addition to the TLS backend maze, curl and library also offers a huge amount of different options to control the TLS connection and handling. You can switch on and off features, provide certificates, CA bundles and more. Adding another layer of TLS pretty much doubles the amount of options since now you can tweak everything both in the TLS connection to the proxy as well as the one to the remote peer.
This new feature is supported with the OpenSSL, GnuTLS and NSS backends to start with.
Consider it experimental for now
By all means, go ahead and use it and torture the code and file issues for everything bad you see, but I think we make ourselves a service by considering this new feature set to be a bit experimental in this release.
New options
There’s a whole forest of new command line and libcurl options to control all the various aspects of the new TLS connection this introduces. Since it is a totally separate connection it gets a whole set of options that are basically identical to the server connection but with a –proxy prefix instead. Here’s a list:
“the overall impression of the state of security and robustness
of the cURL library was positive.”
I asked for, and we were granted a security audit of curl from the Mozilla Secure Open Source program a while ago. This was done by Mozilla getting a 3rd party company involved to do the job and footing the bill for it. The auditing company is called Cure53.
I applied for the security audit because I feel that we’ve had some security related issues lately and I’ve had the feeling that we might be missing something so it would be really good to get some experts’ eyes on the code. Also, as curl is one of the most used software components in the world a serious problem in curl could have a serious impact on tools, devices and applications everywhere. We don’t want that to happen.
Scans and tests and all
We run static analyzers on the code frequently with a zero warnings tolerance. The daily clang-analyzer scan hasn’t found a problem in a long time and the Coverity once-every-few-weeks occasionally finds something suspicious but we always fix those immediately.
We have thousands of tests and unit tests that we run non-stop on the code on multiple platforms running multiple build combinations. We also use valgrind when running tests to verify memory use and check for potential memory leaks.
Secrecy
The audit itself. The report and the work on fixing the issues were all done on closed mailing lists without revealing to the world what was really going on. All as our fine security process describes.
There are several downsides with fixing things secretly. One of the primary ones is that we get much fewer eyes on the fixes and there aren’t that many people involved when discussing solutions or approaches to the issues at hand. Another is that our test infrastructure is made for and runs only public code so the code can’t really be fully tested until it is merged into the public git repository.
The report
We got the report on September 23, 2016 and it certainly gave us a lot of work.
The audit report has now been made public and is a very interesting work if you’re into security, C code and curl hacking. I find the report very clear, well written and it spells out each problem very accurately and even shows proof of concept code snippets and exploit examples to drive the points home.
Quoted from the report intro:
As for the approach, the test was rooted in the public availability of the source code belonging to the cURL software and the investigation involved five testers of the Cure53 team. The tool was tested over the course of twenty days in August and September of 2016 and main efforts were focused on examining cURL 7.50.1. and later versions of cURL. It has to be noted that rather than employ fuzzing or similar approaches to validate the robustness of the build of the application and library, the latter goal was pursued through a classic source code audit. Sources covering authentication, various protocols, and, partly, SSL/TLS, were analyzed in considerable detail. A rationale behind this type of scoping pointed to these parts of the cURL tool that were most likely to be prone and exposed to real-life attack scenarios. Rounding up the methodology of the classic code audit, Cure53 benefited from certain tools, which included ASAN targeted with detecting memory errors, as well as Helgrind, which was tasked with pinpointing synchronization errors with the threading model.
They identified no less than twenty-three (23) potential problems in the code, out of which nine were deemed security vulnerabilities. But I’d also like to emphasize that they did also actually say this:
At the same time, the overall impression of the state of security and robustness of the cURL library was positive.
Resolving problems
In the curl security team we decided to downgrade one of the 9 vulnerabilities to a “plain bug” since the required attack scenario was very complicated and the risk deemed small, and two of the issues we squashed into treating them as a single one. That left us with 7 security vulnerabilities. Whoa, that’s a lot. The largest amount we’ve ever fixed in a single release before was 4.
I consider handling security issues in the project to be one of my most important tasks; pretty much all other jobs are down-prioritized in comparison. So with a large queue of security work, a lot of bug fixing and work on features basically had to halt.
You can get a fairly detailed description of our work on fixing the issues in the fix and validation log. The report, the log and the advisories we’ve already posted should cover enough details about these problems and associated fixes that I don’t feel a need to write about them much further.
More problems
Just because we got our hands full with an audit report doesn’t mean that the world stops, right? While working on the issues one by one to have them fixed we also ended up getting an additional 4 security issues to add to the set, by three independent individuals.
All these issues gave me a really busy period and it felt great when we finally shipped 7.51.0 and announced all those eleven fixes to the world and I could get a short period of relief until the next tsunami hits.
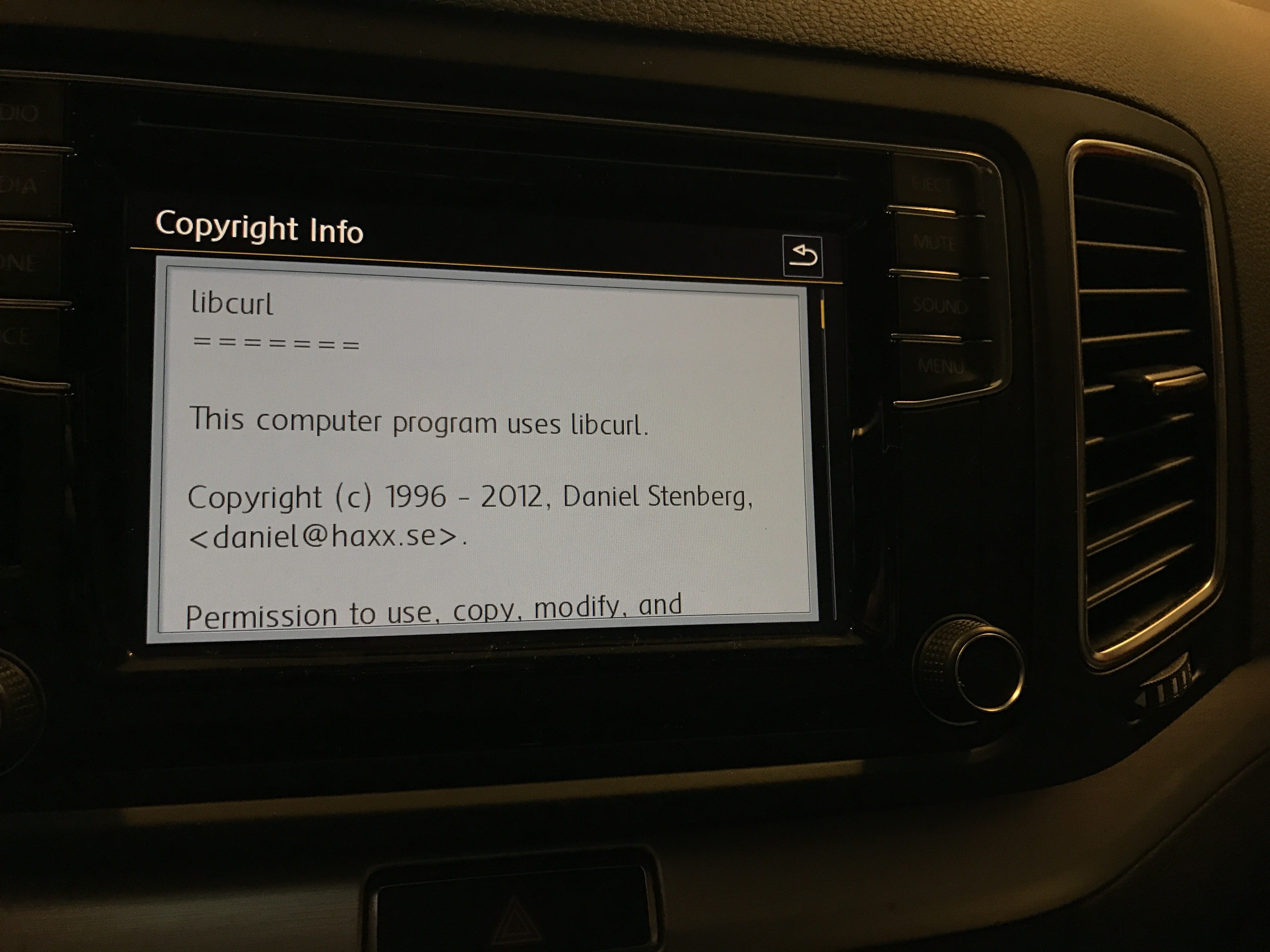
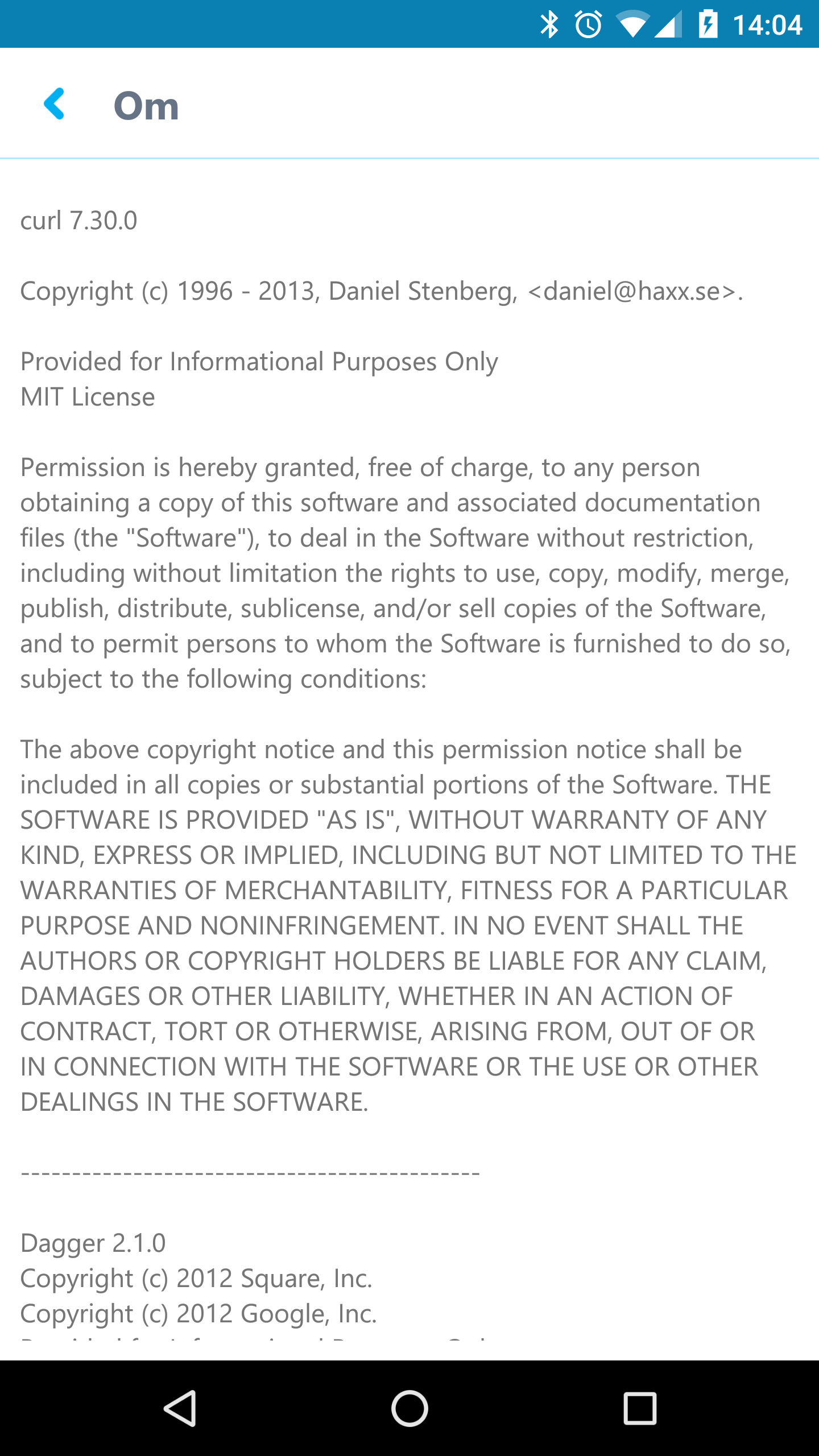
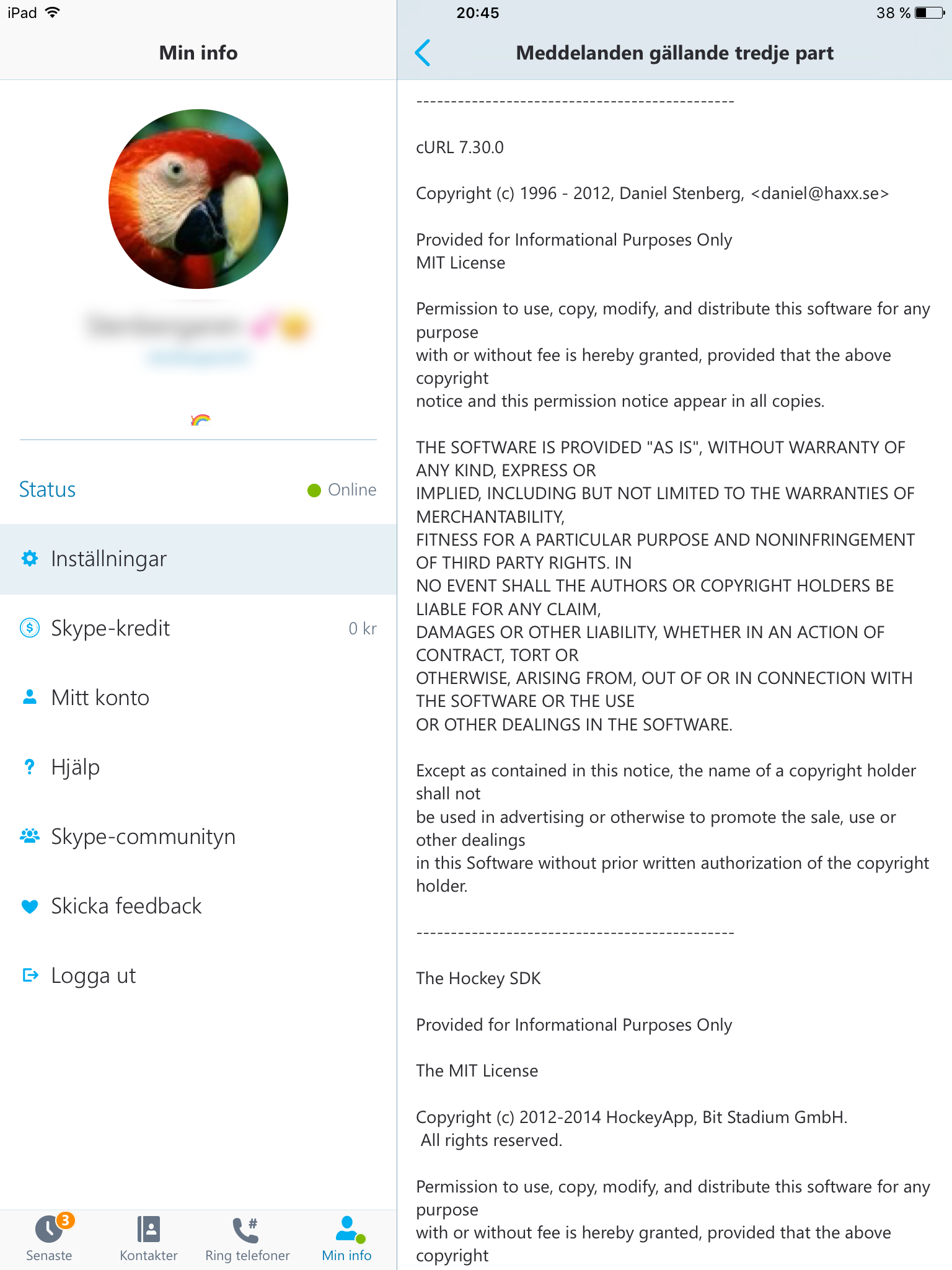
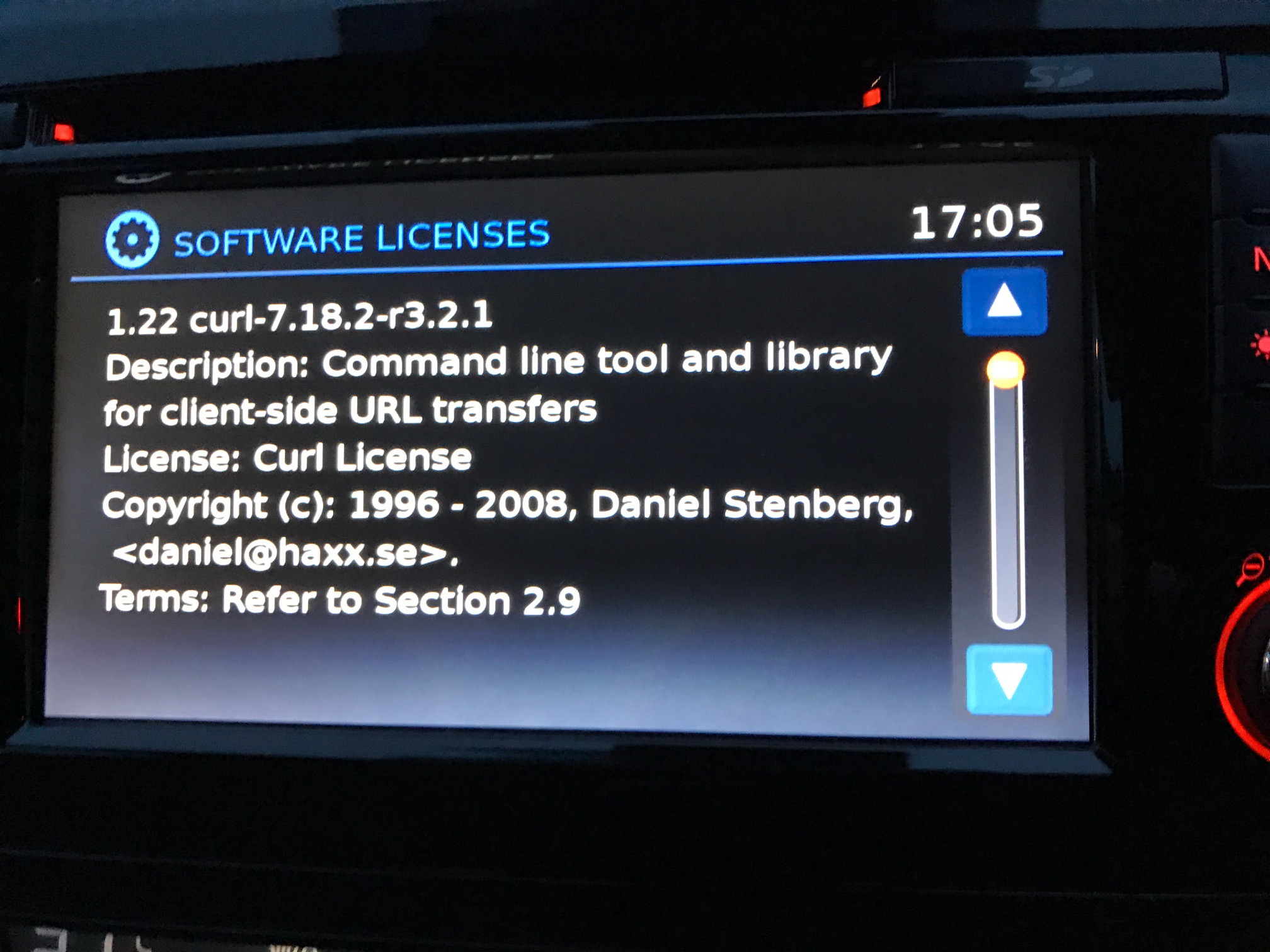
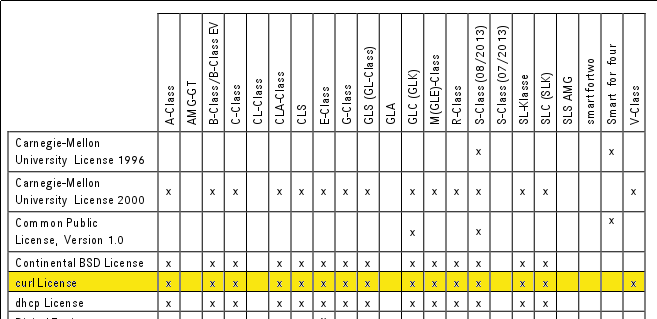
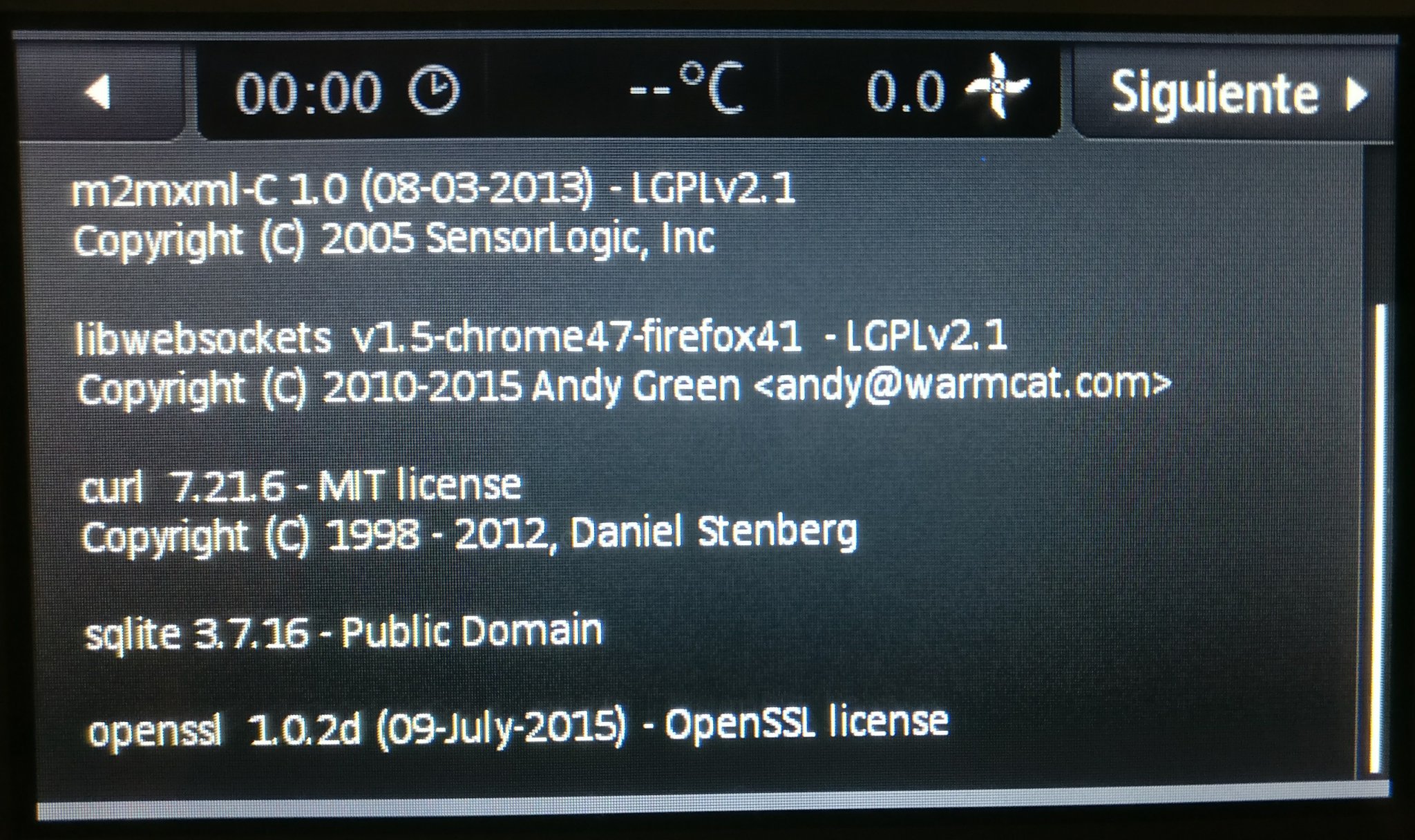
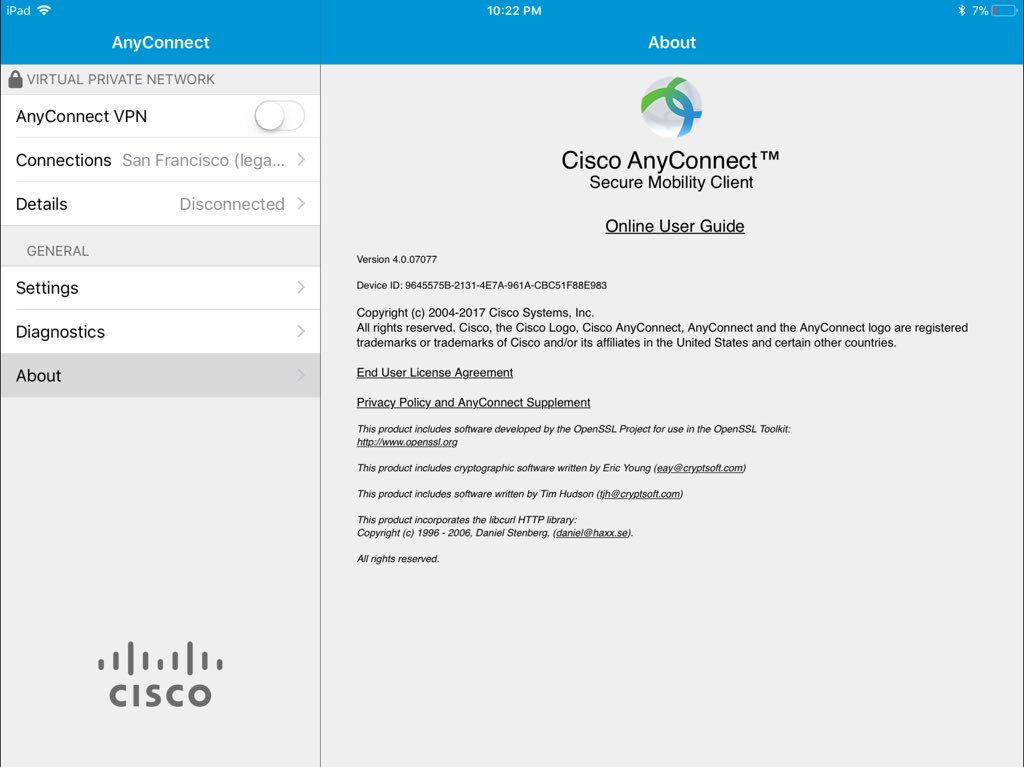
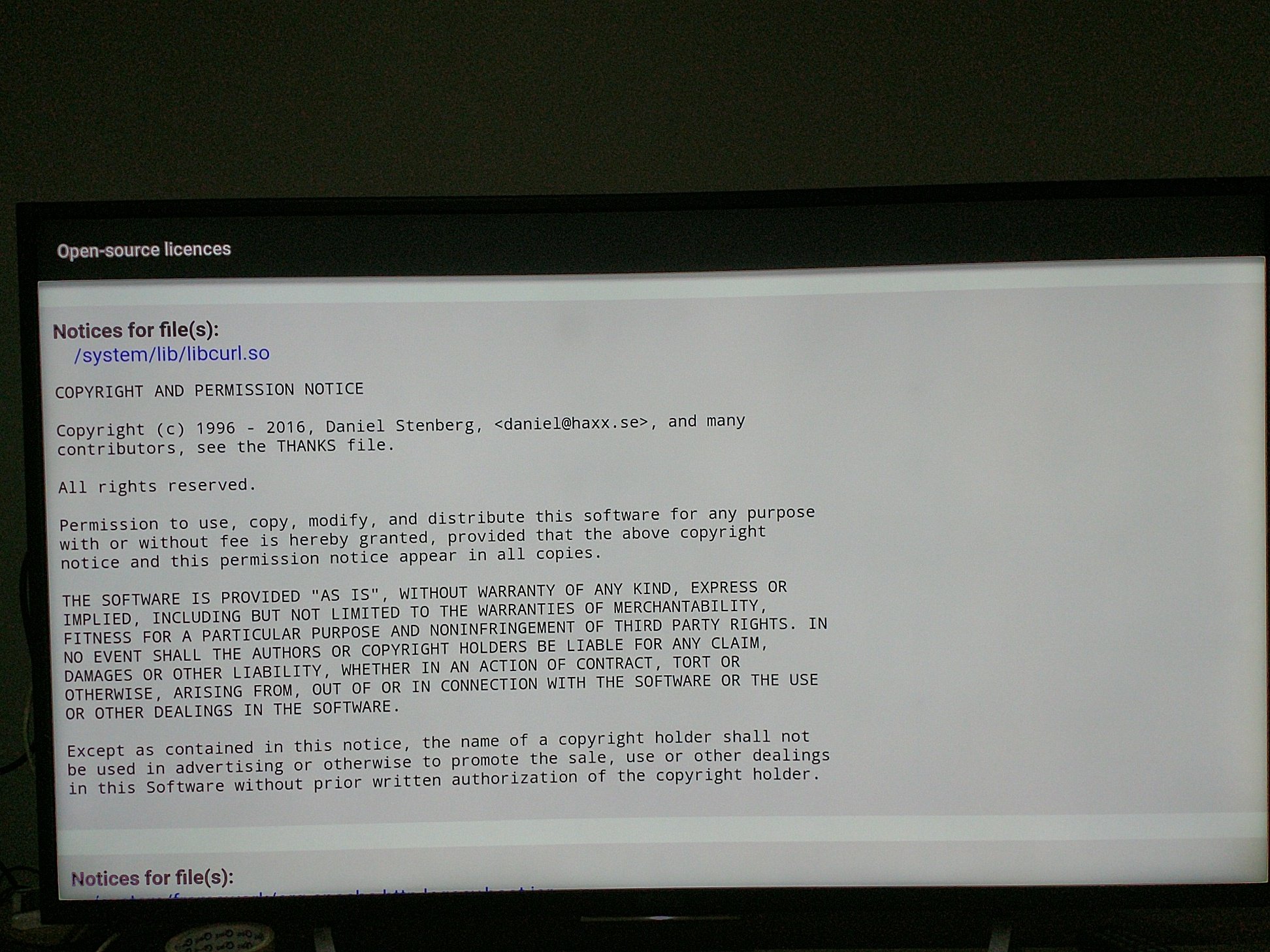
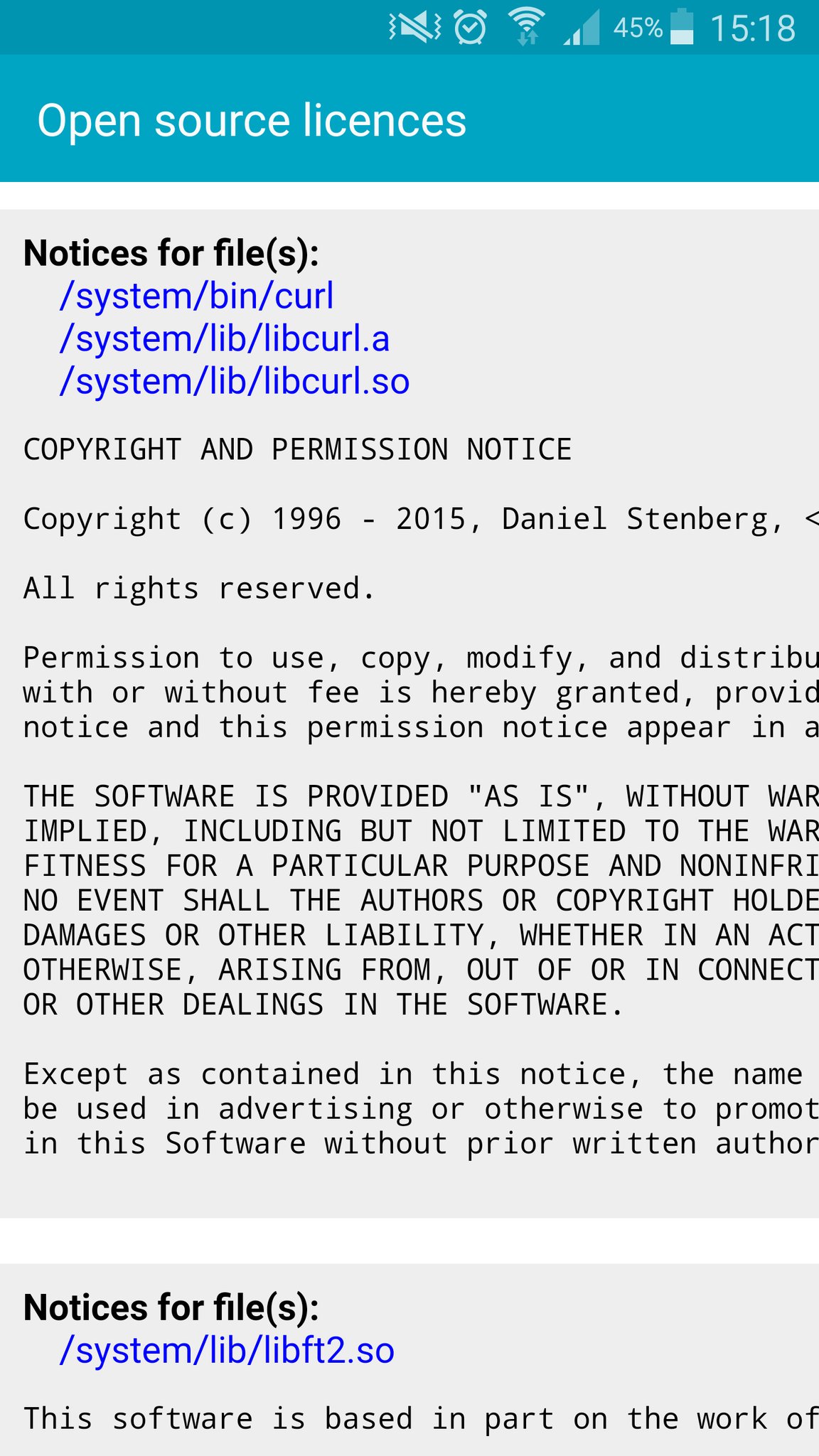
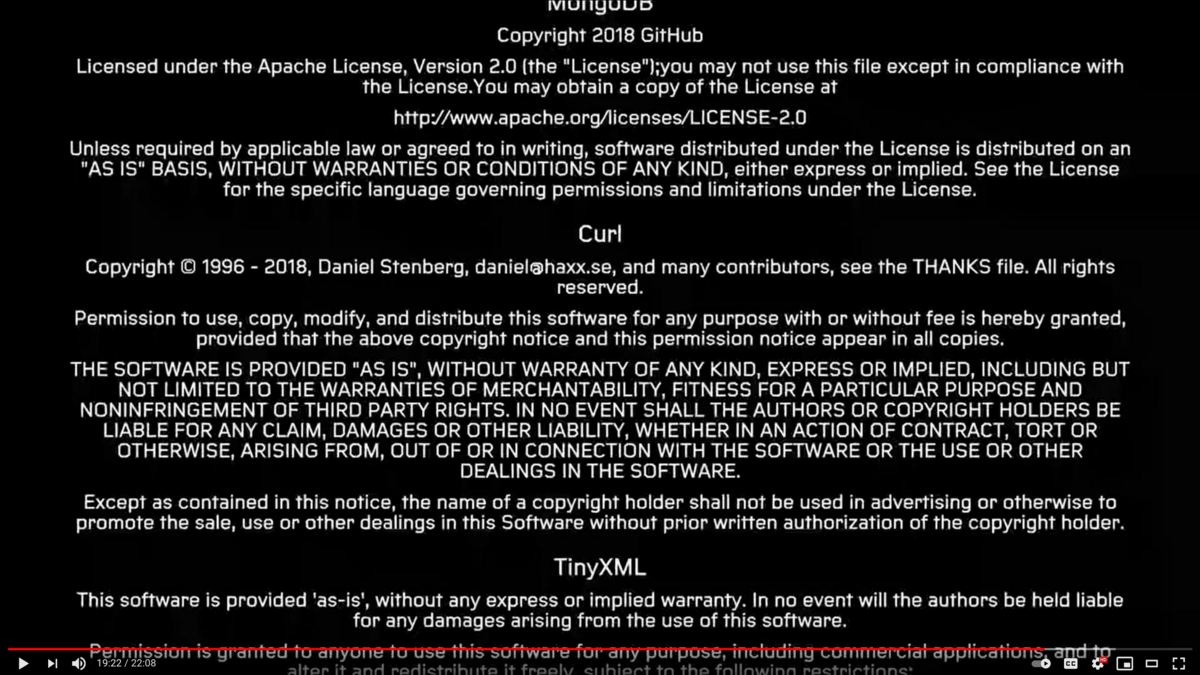
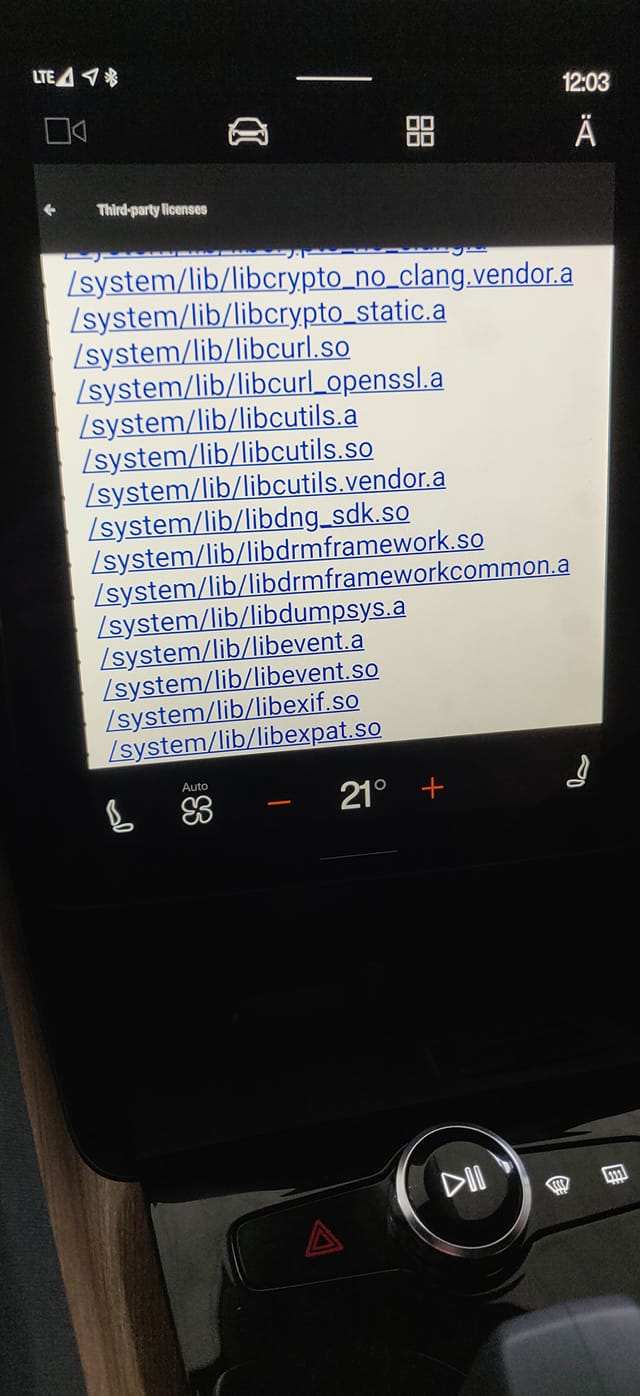
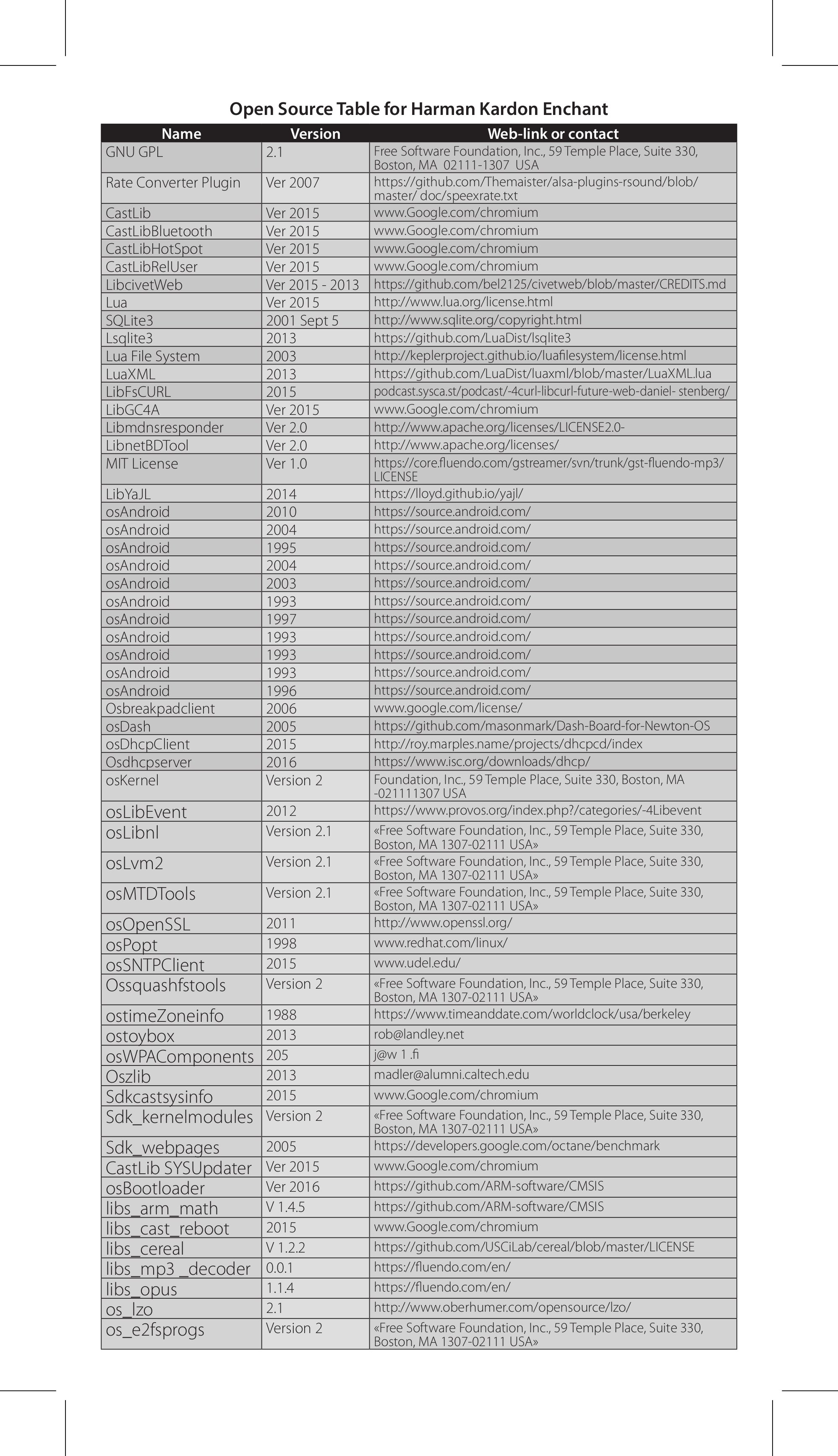
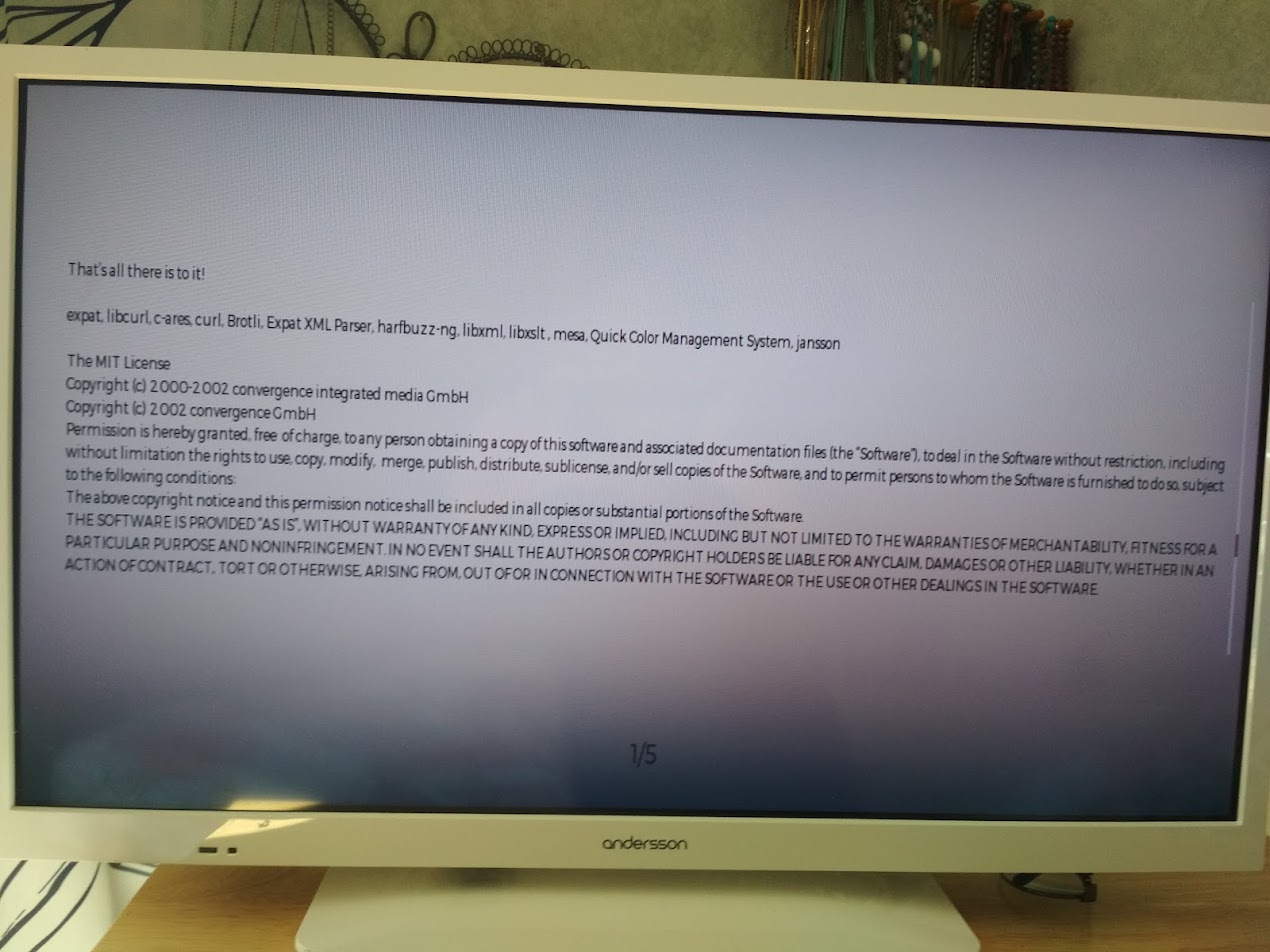
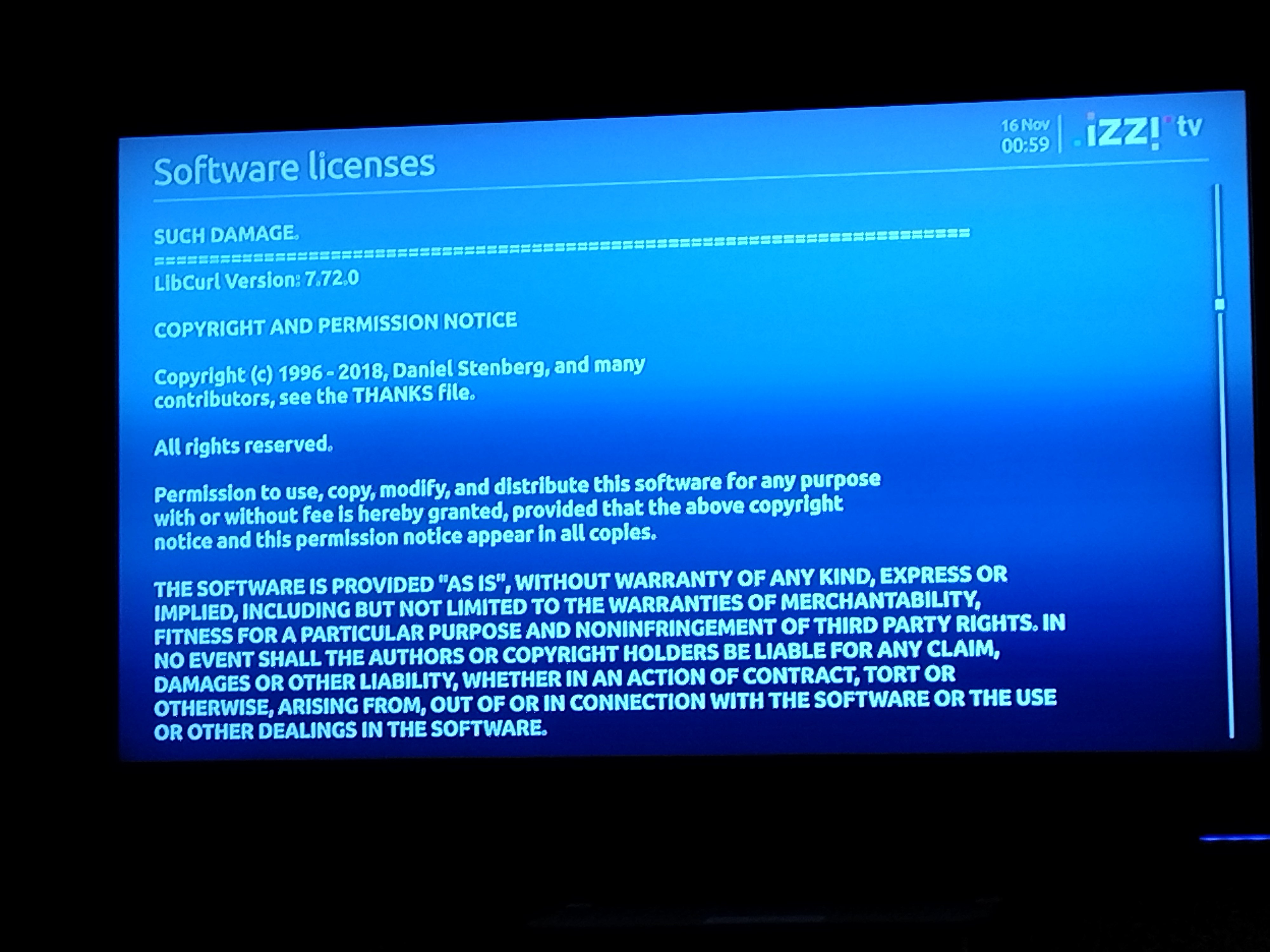
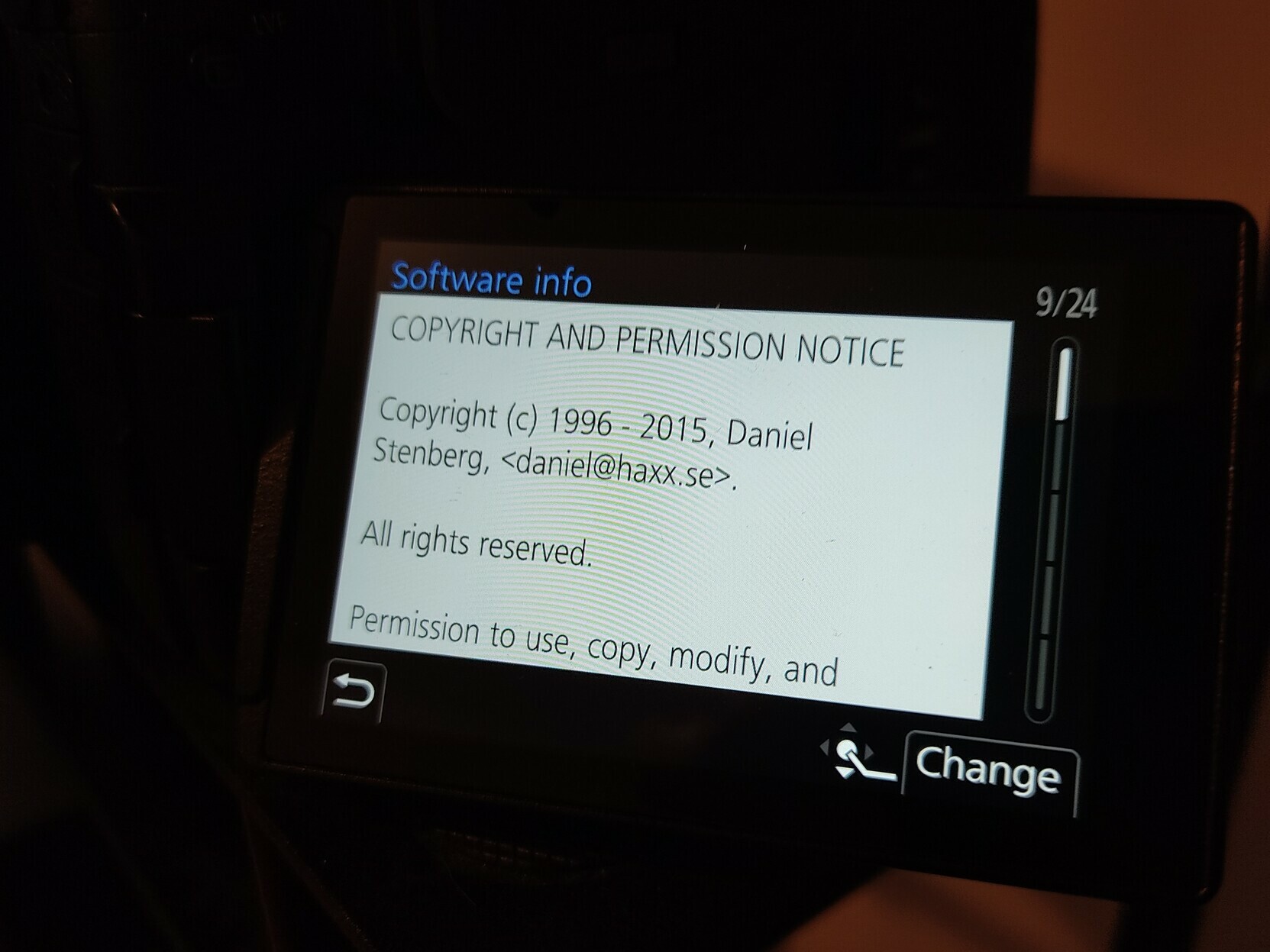
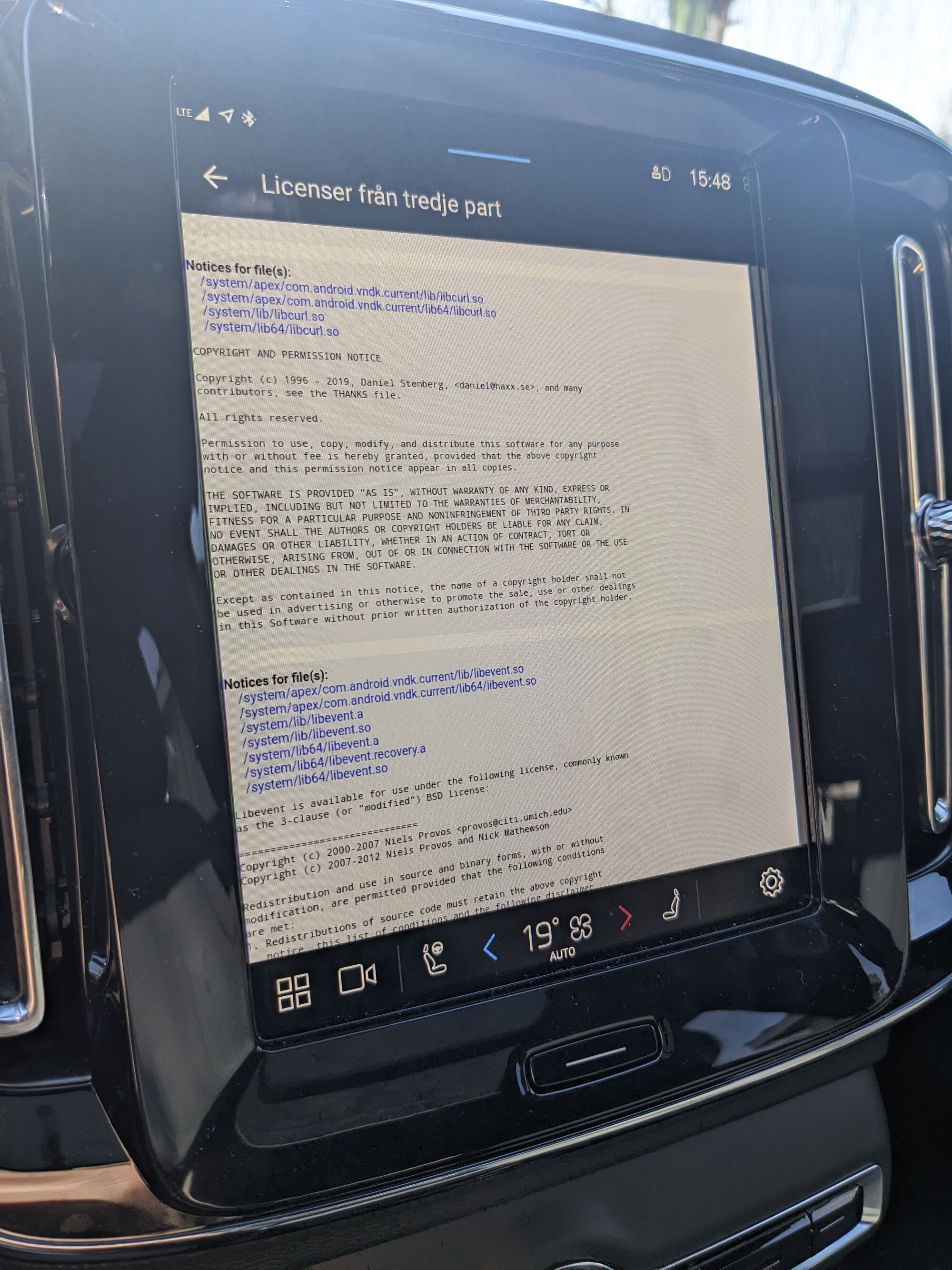
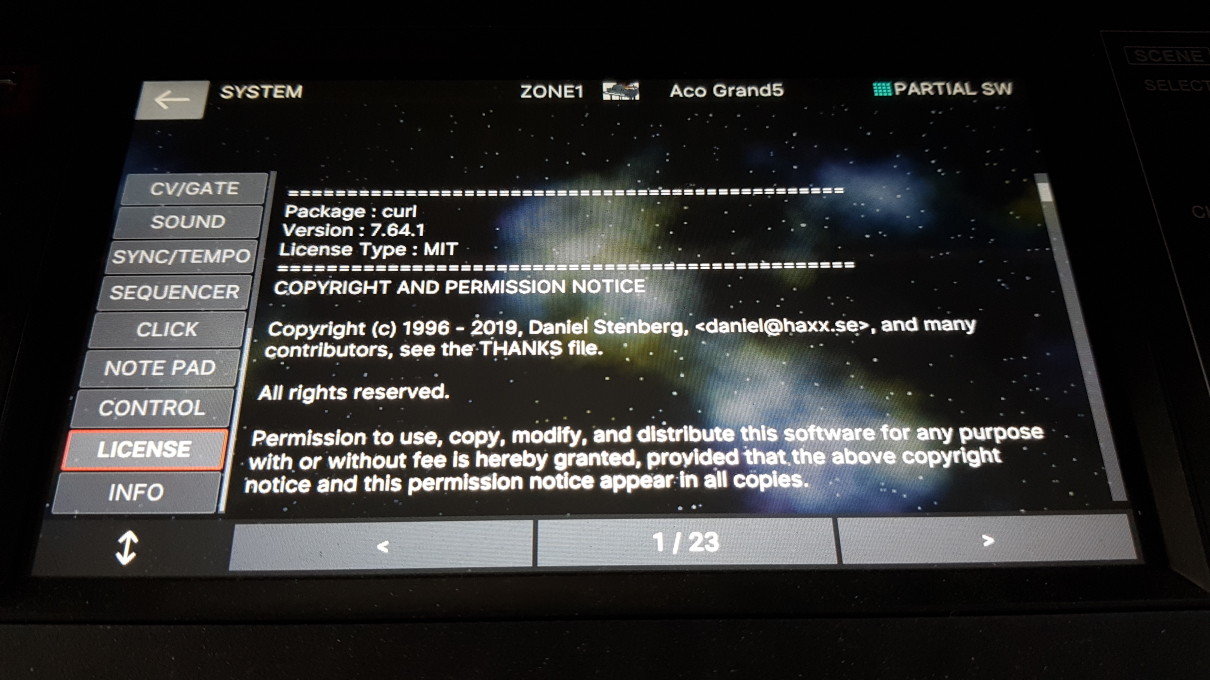
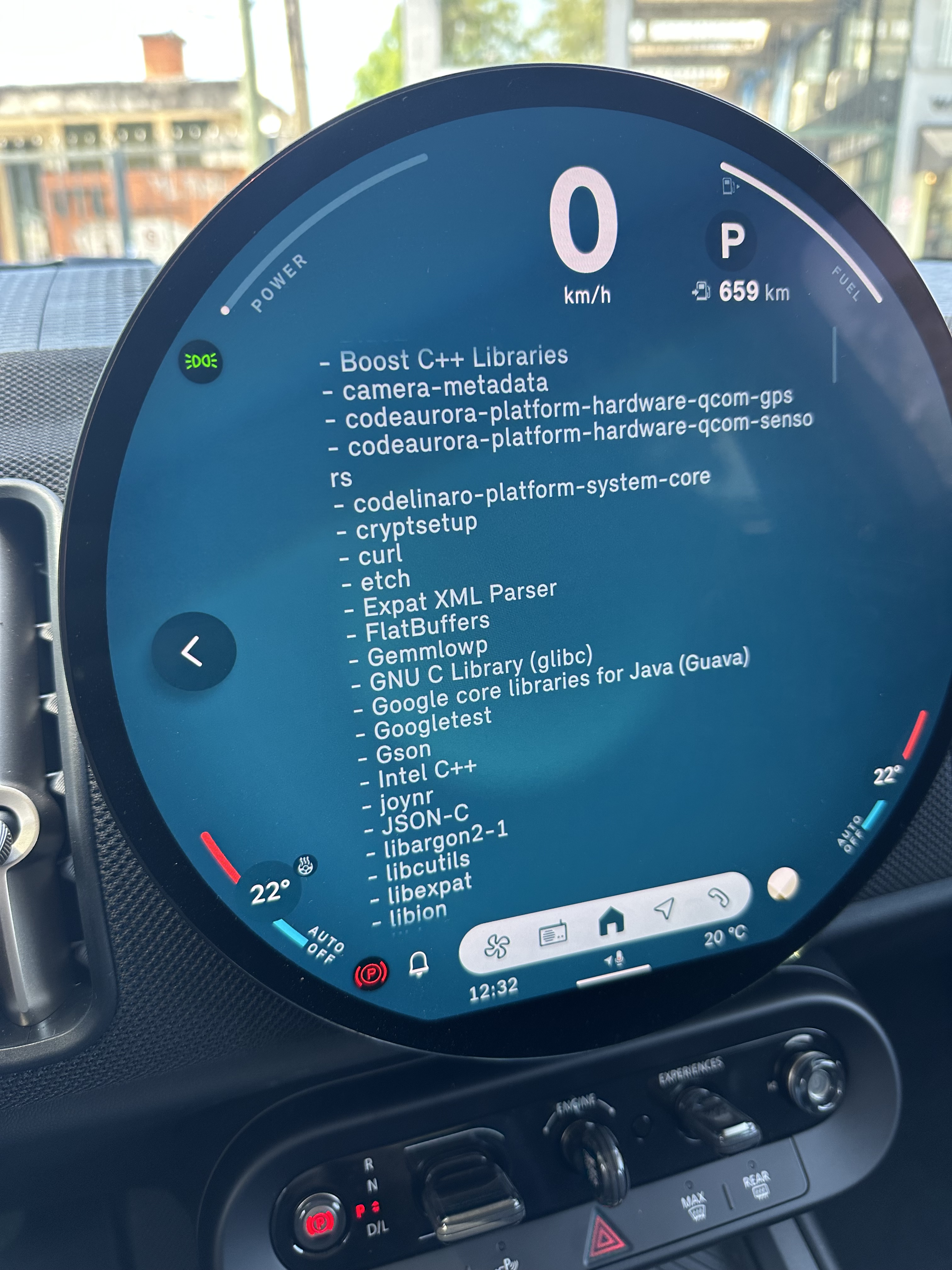
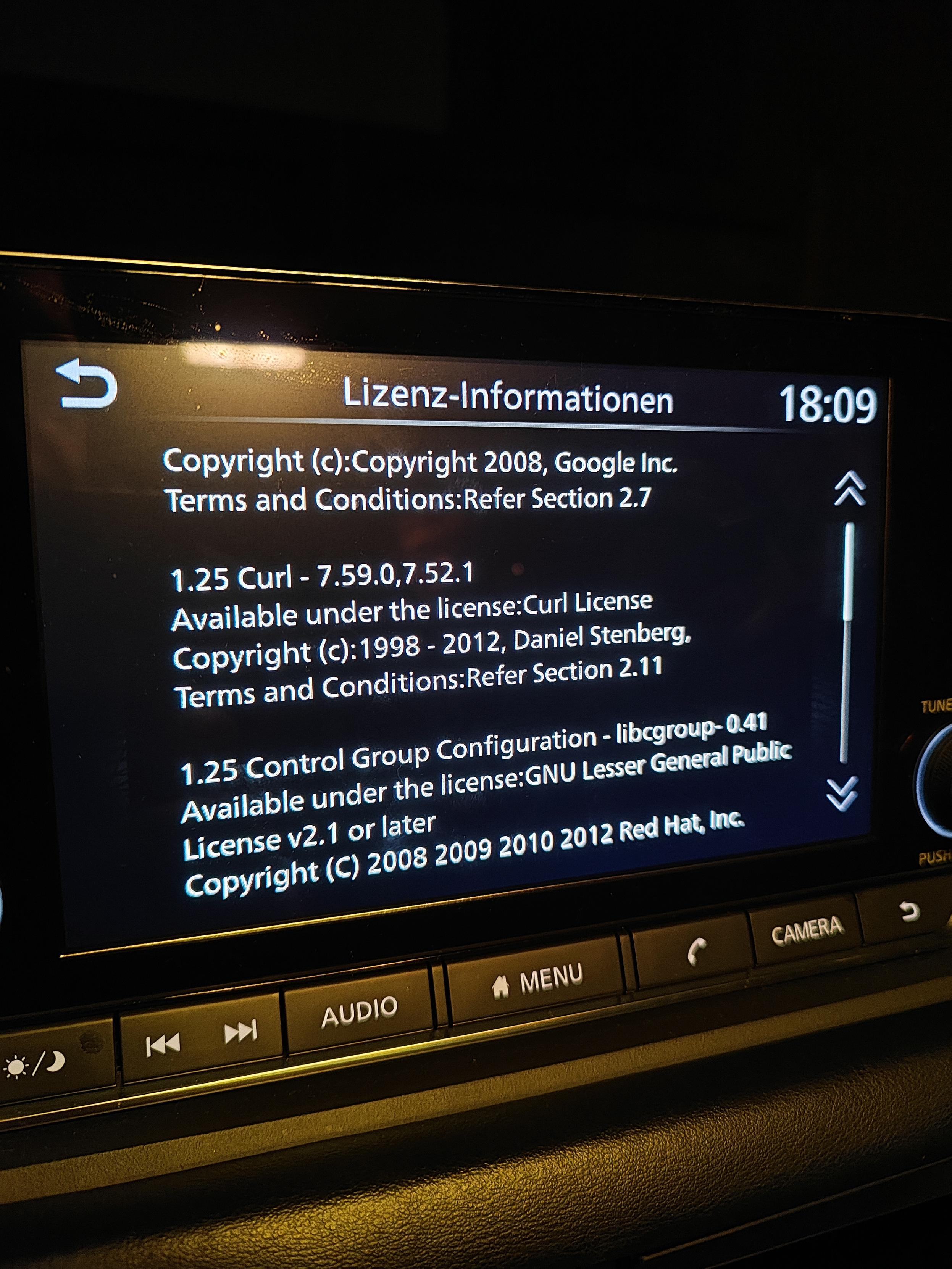
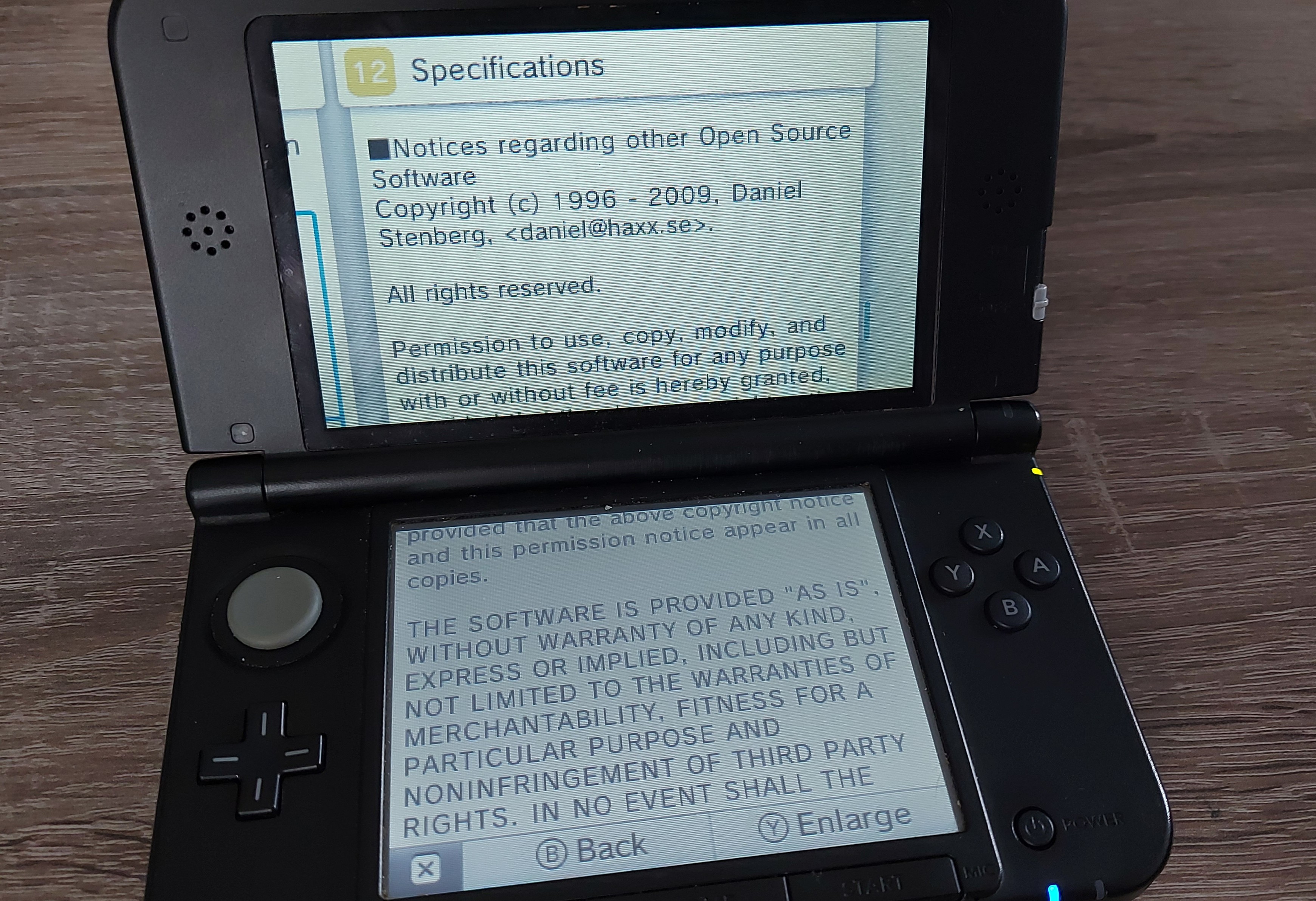
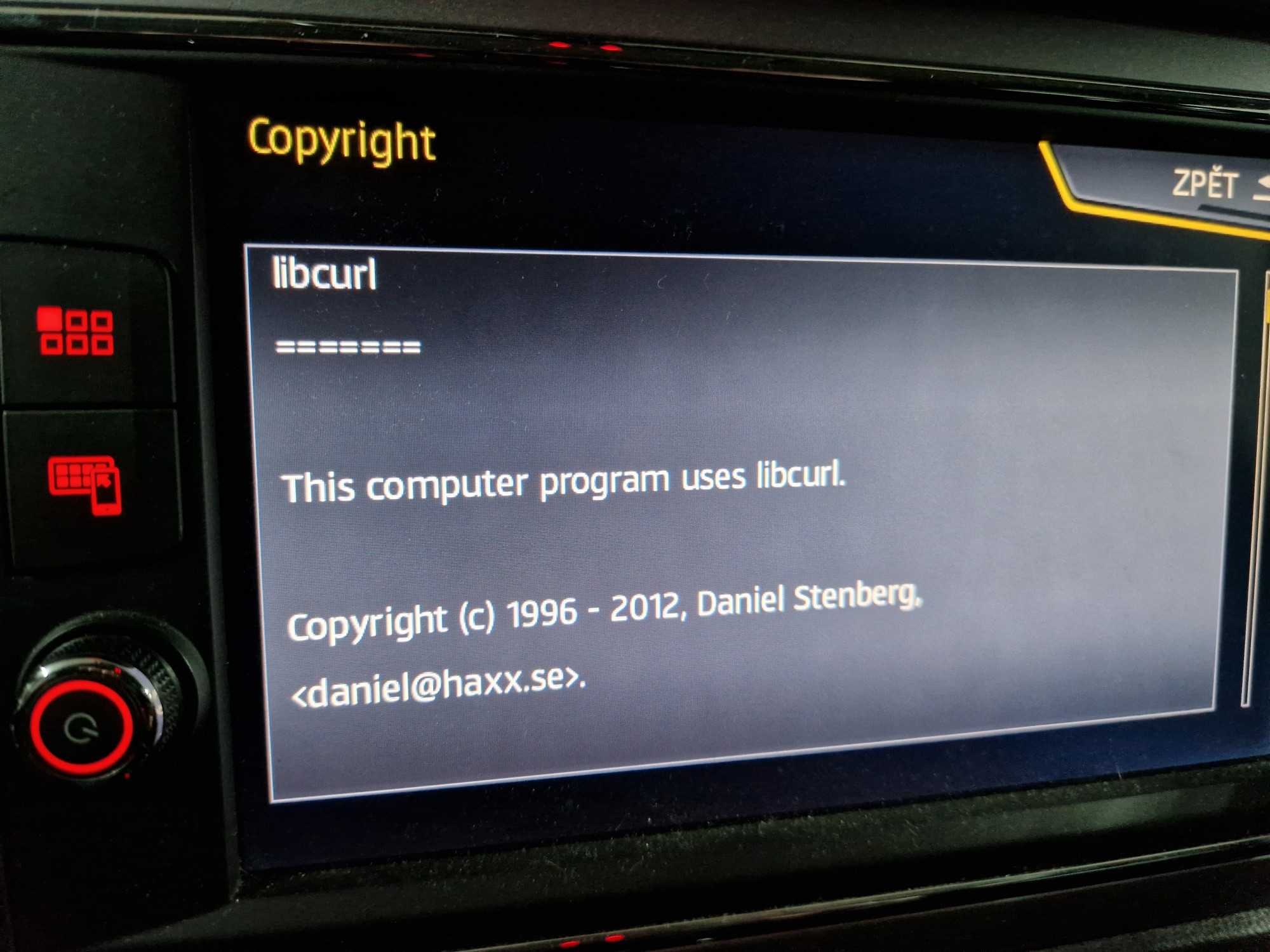
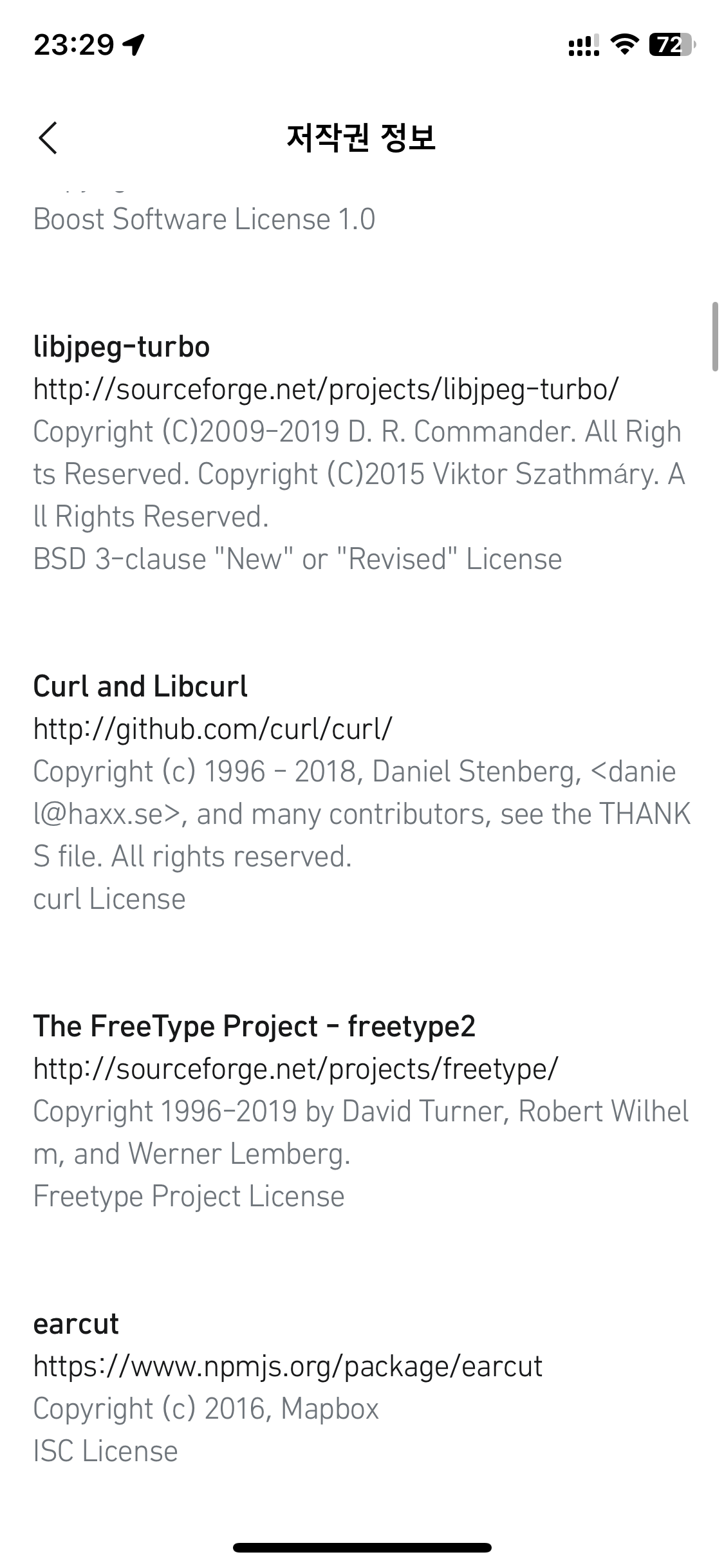
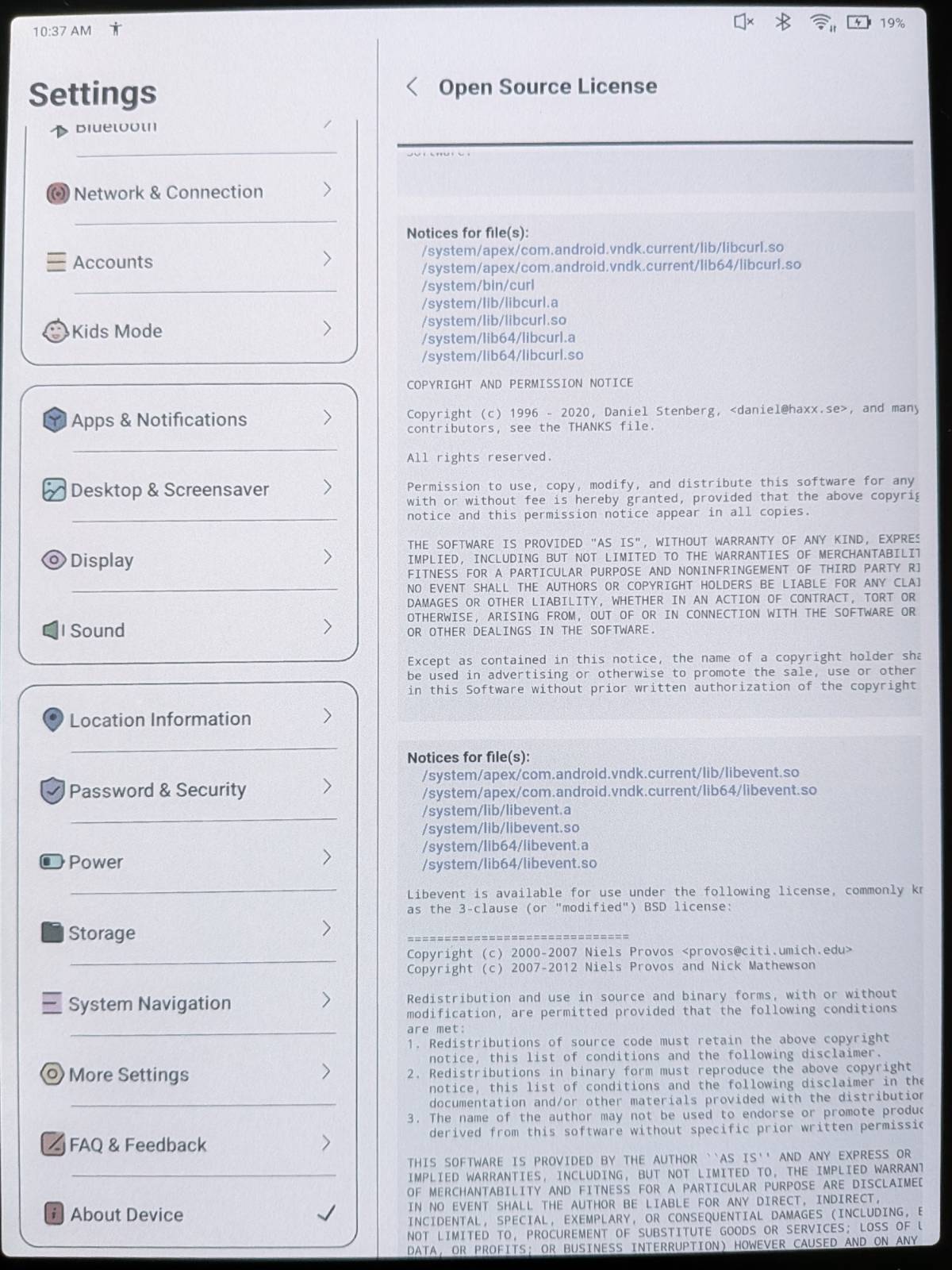
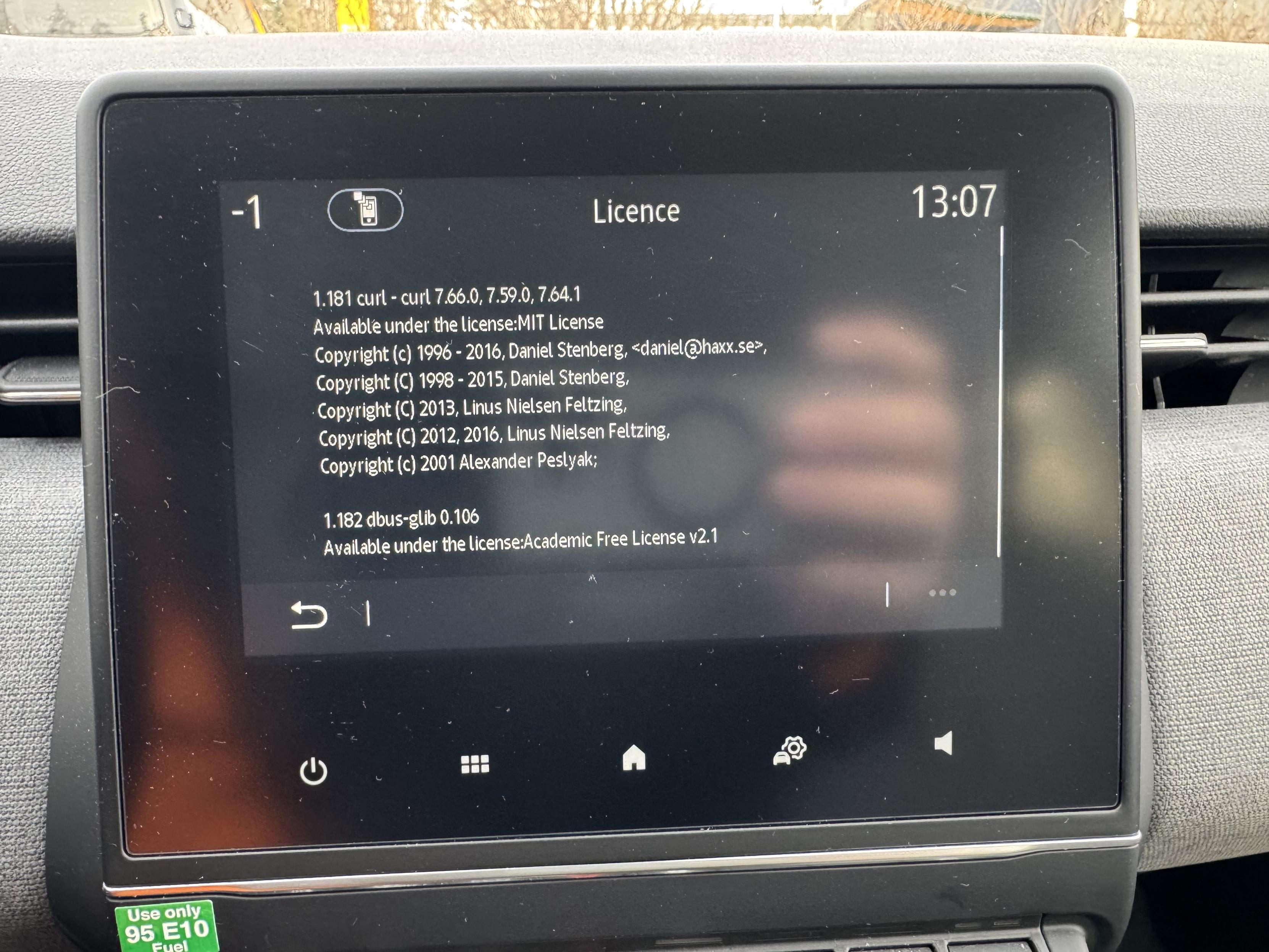
Modern cars have fancy infotainment setups, big screens and all sorts of computers with networked functionality built-in. Part of that fanciness is increasingly often a curl install. curl is a part of the standard GenIVI and Tizen offers for cars and is used in lots of other independent software installs too.
This usually affects my every day very little. Sure I’m thrilled over hundreds of millions of more curl installations in the world but the companies that ship them don’t normally contact me and curl is a really stable product by now so not a lot of them speak up on the issue trackers or mailing lists either (or if they do, they don’t tell us where they come from or what they’re working on).
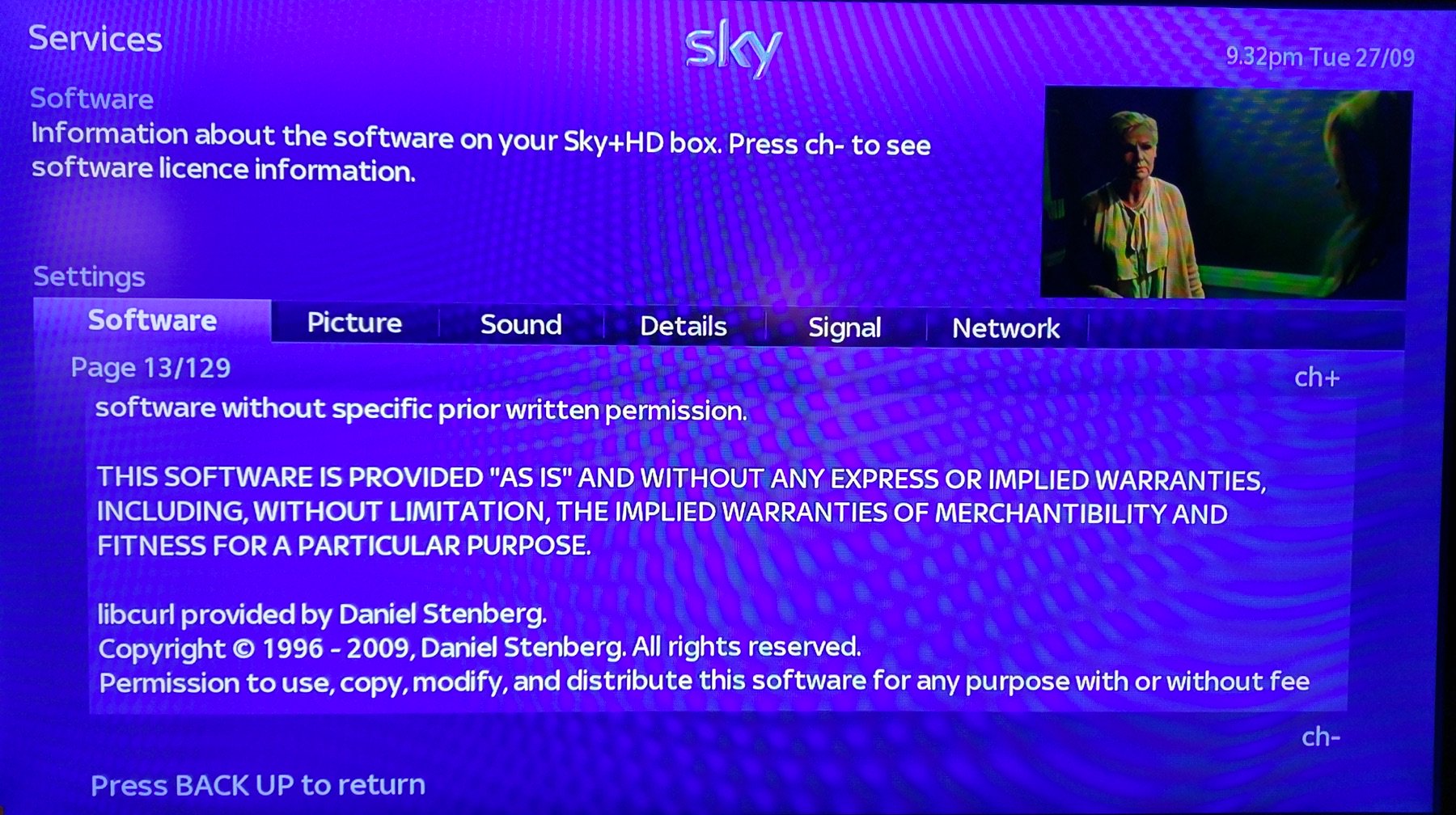
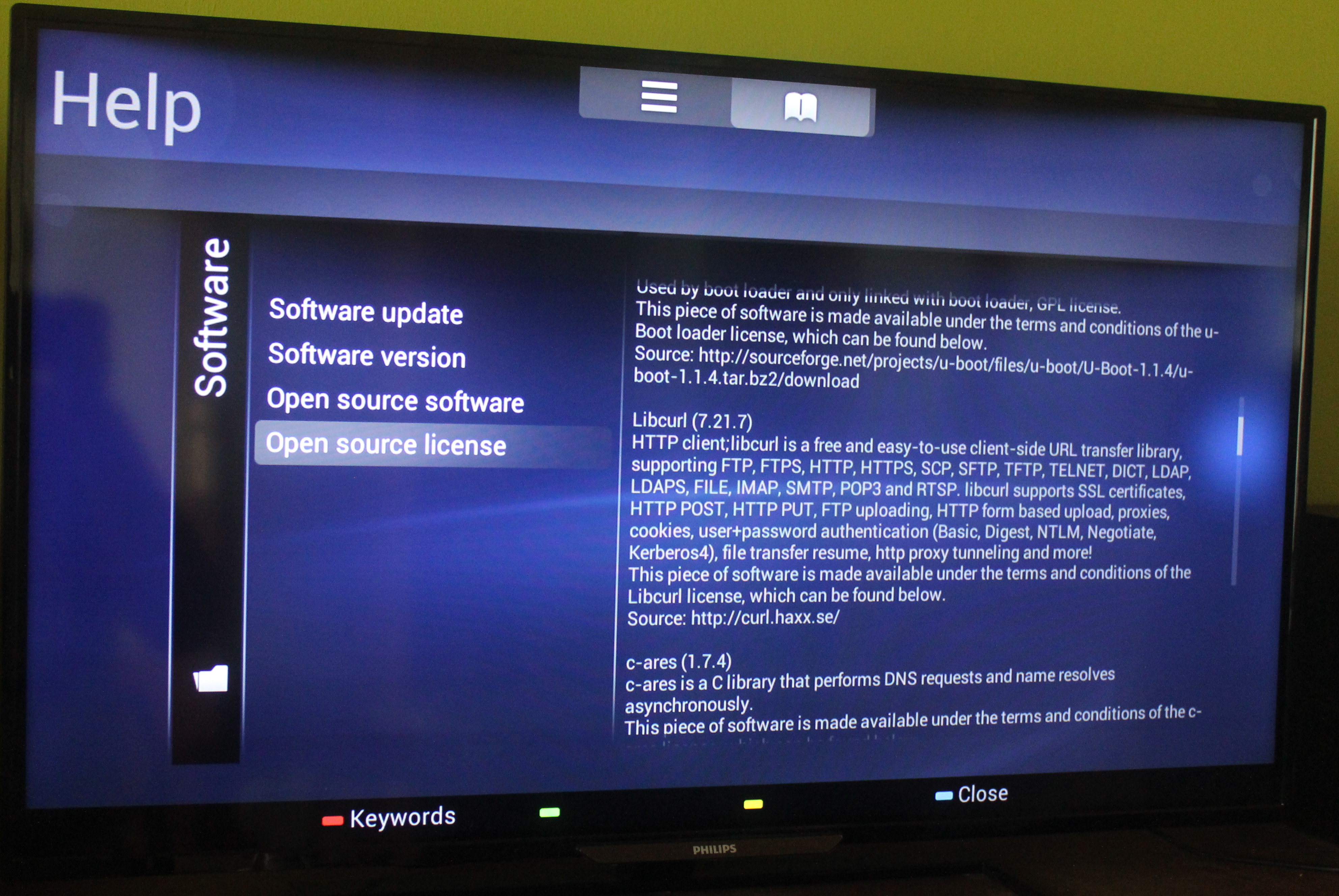
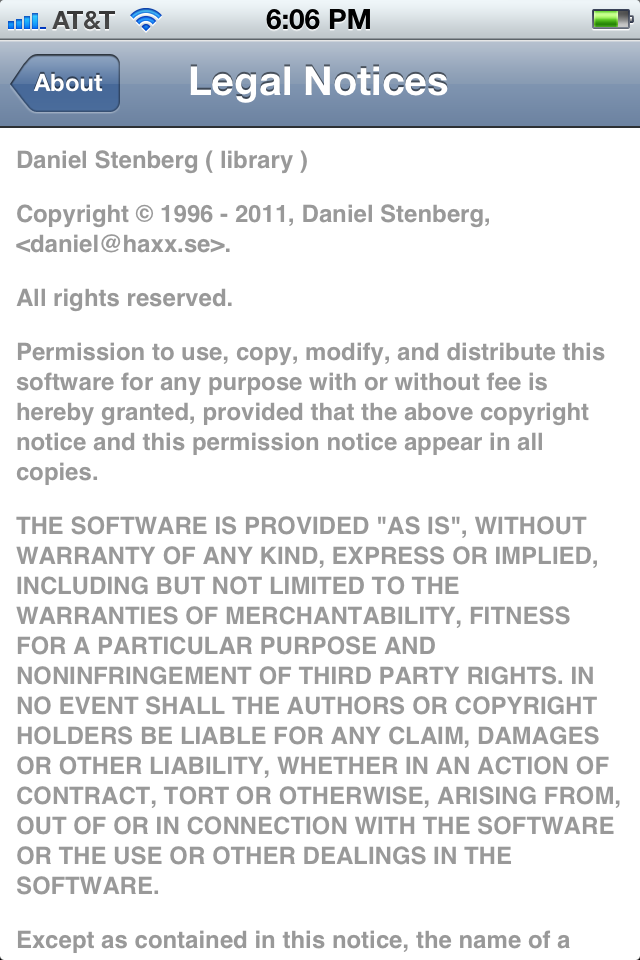
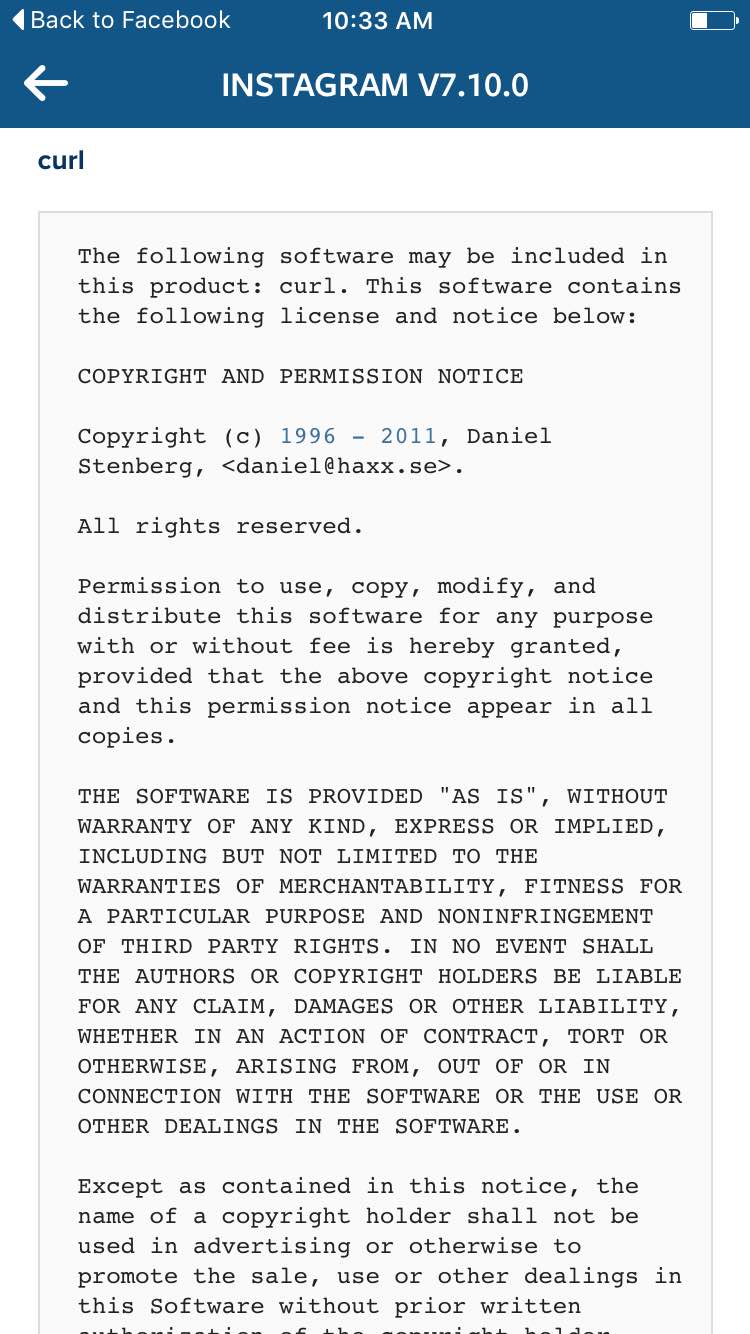
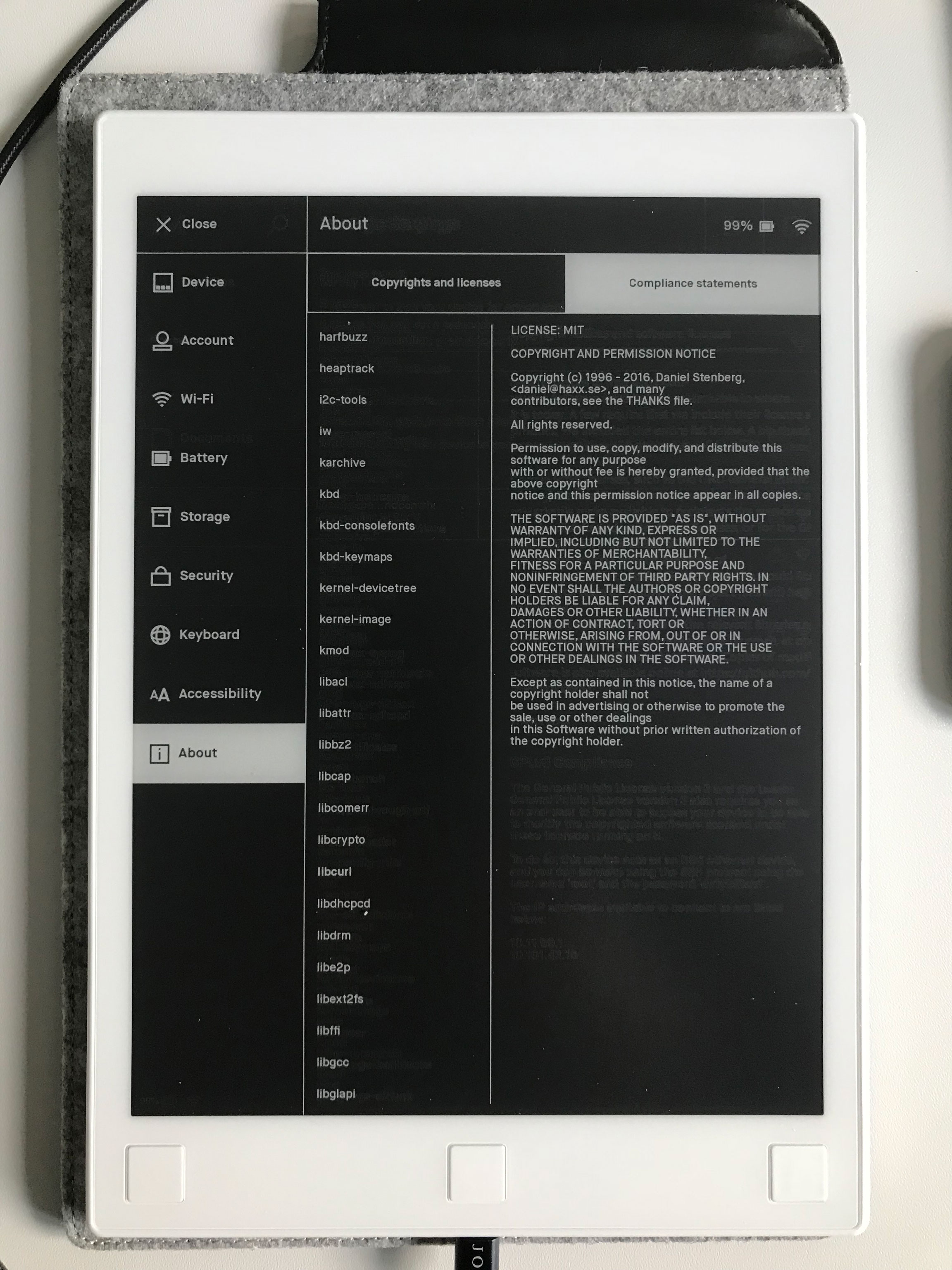
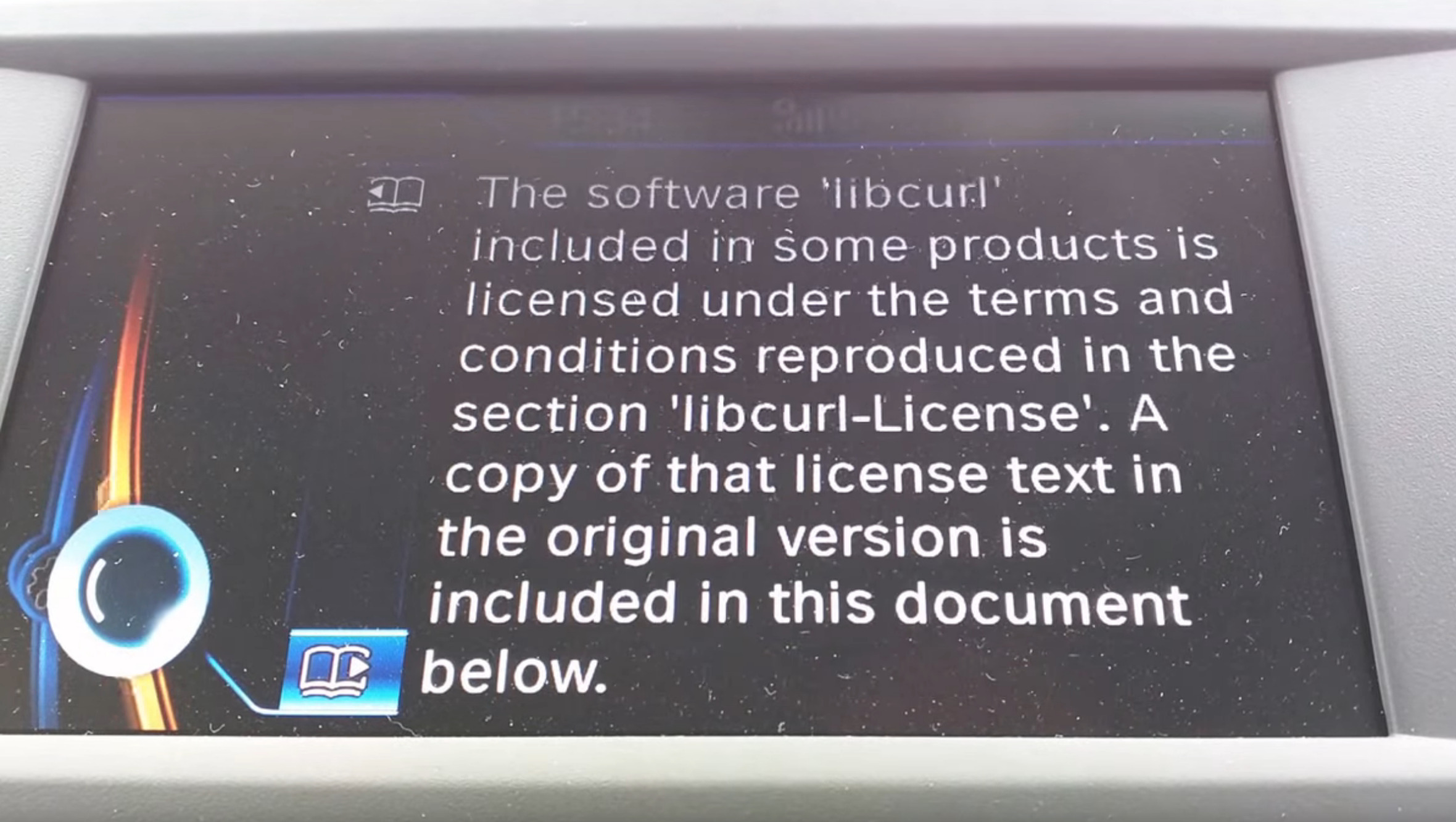
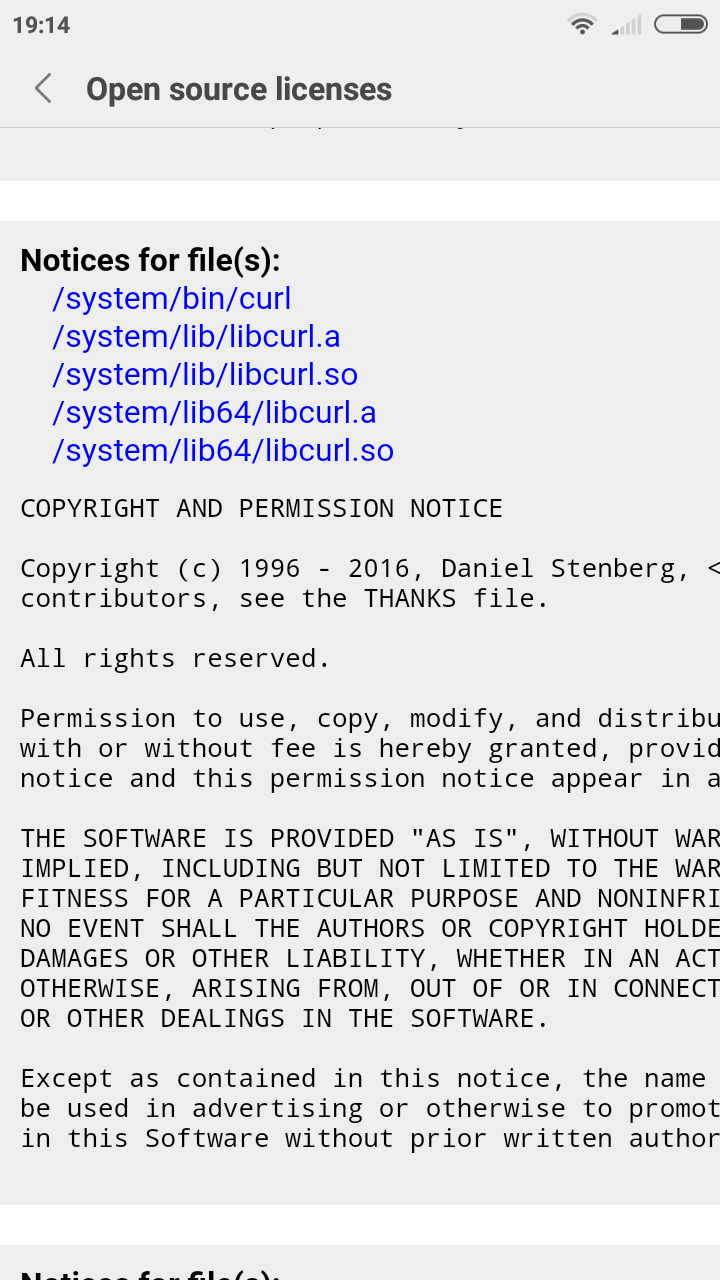
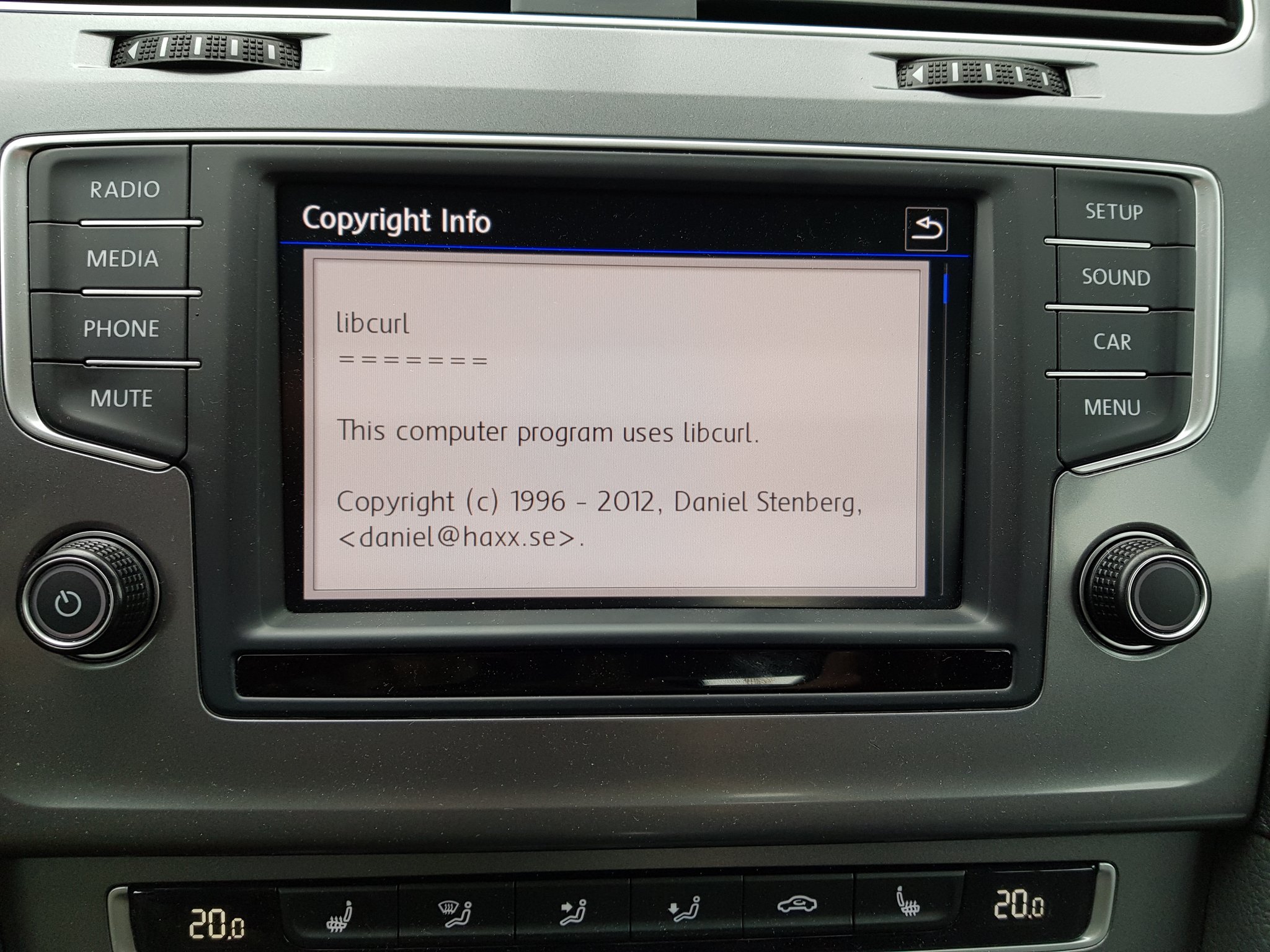
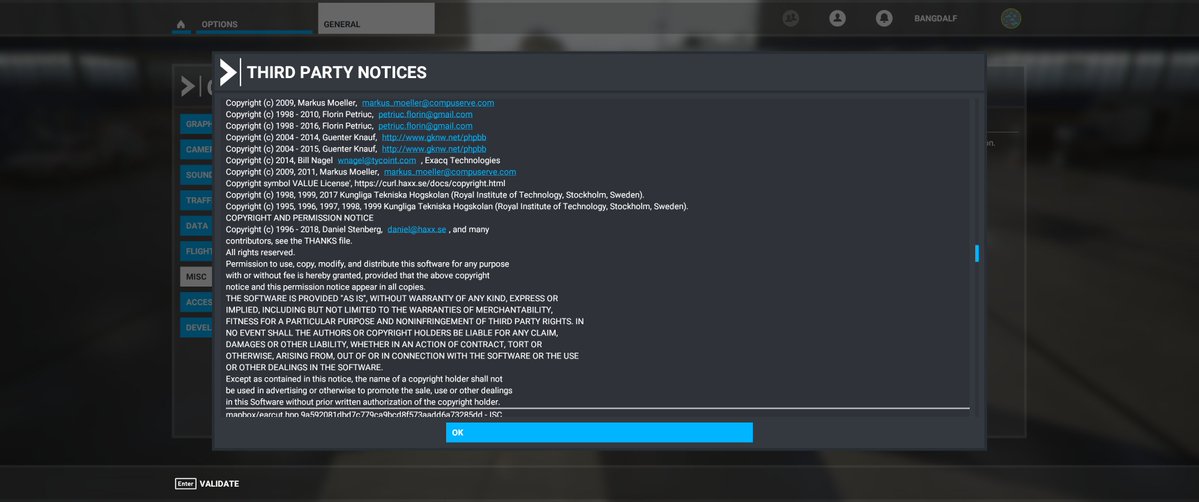
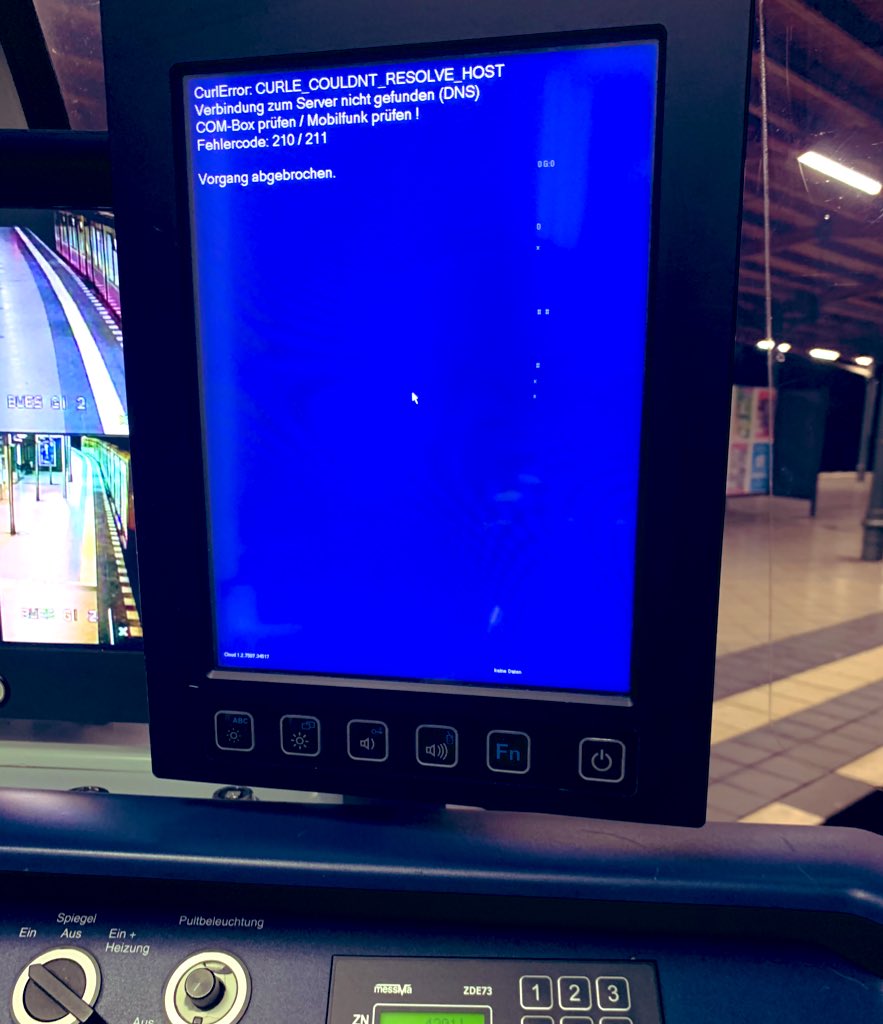
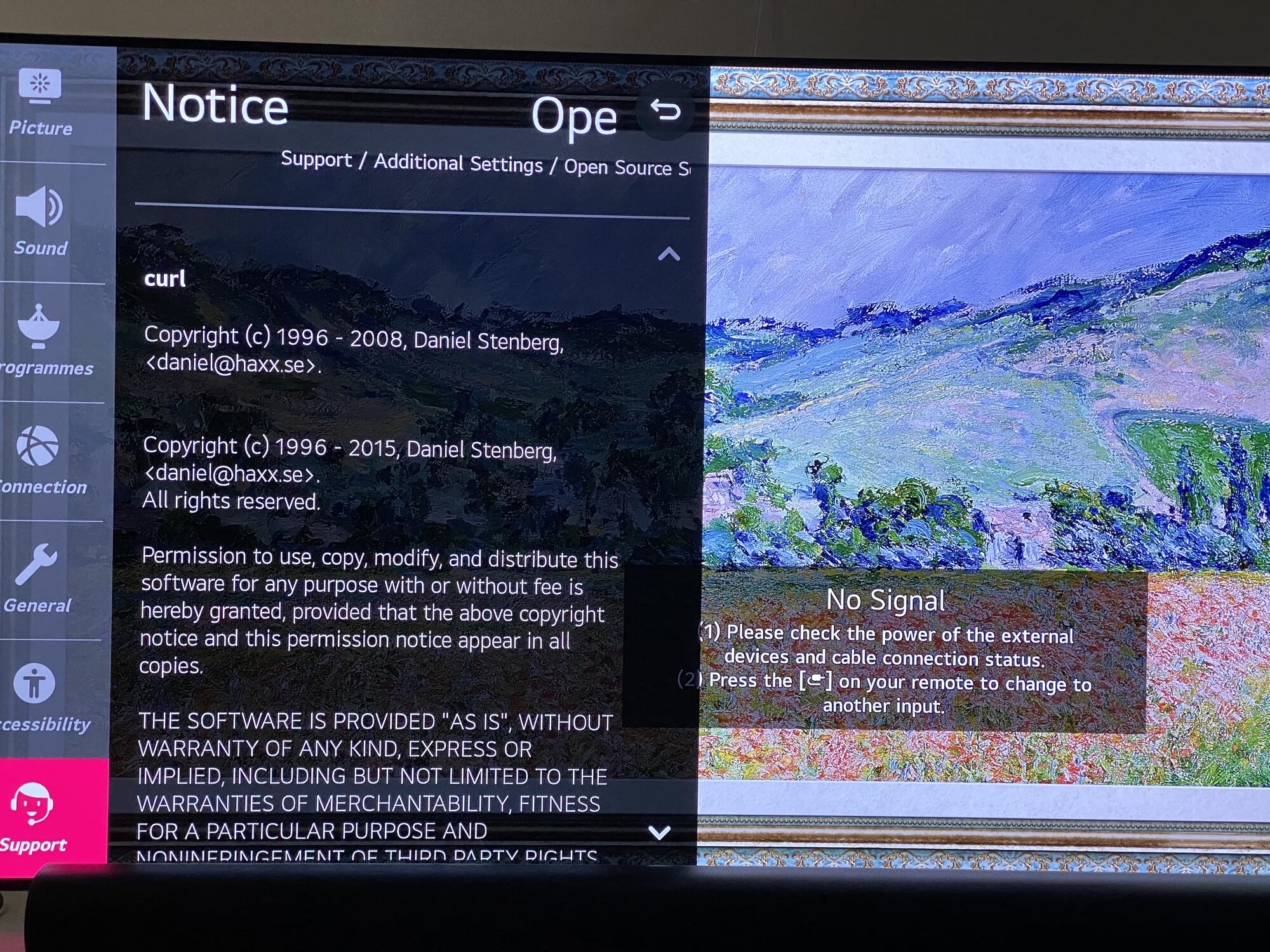
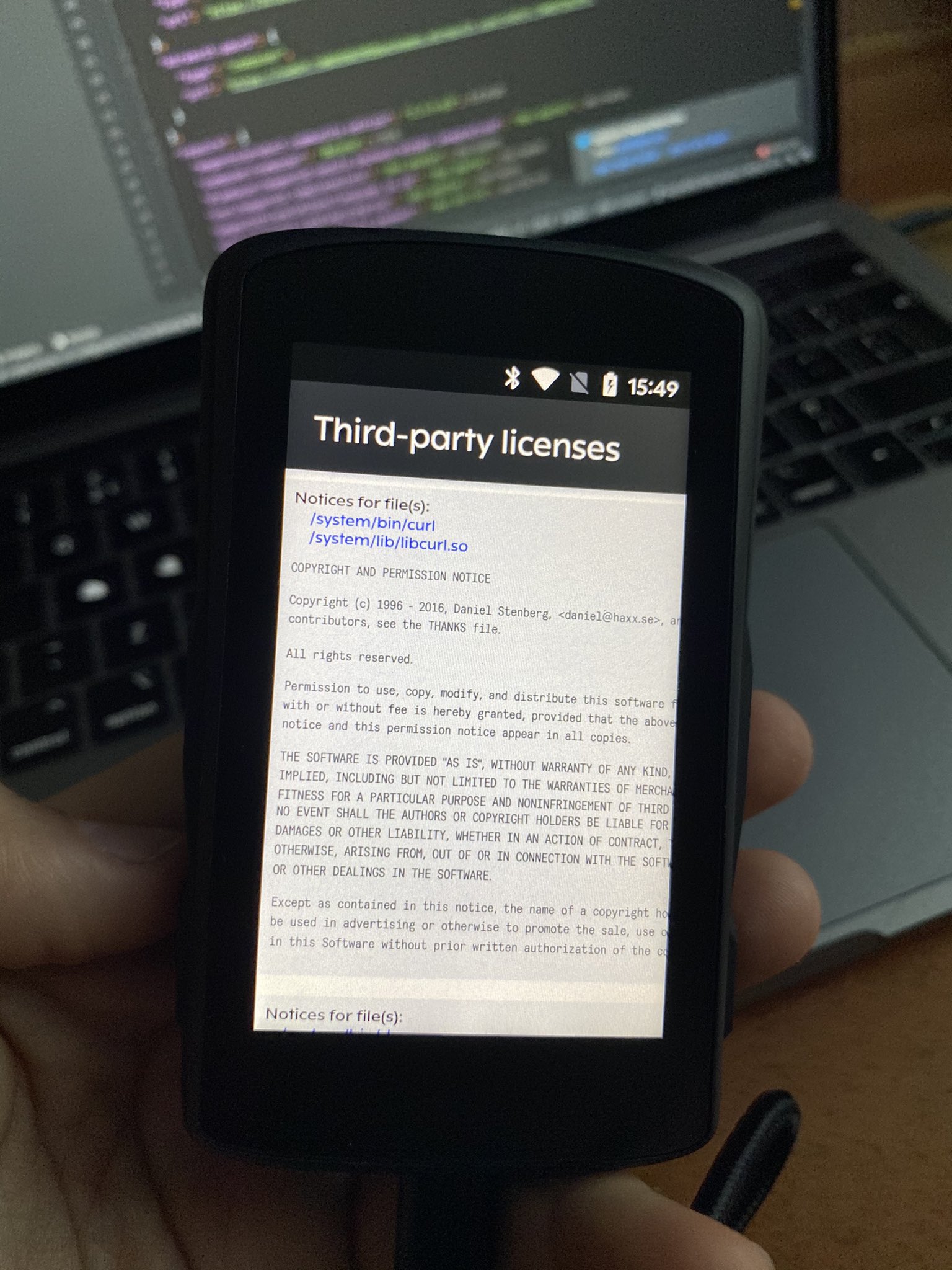
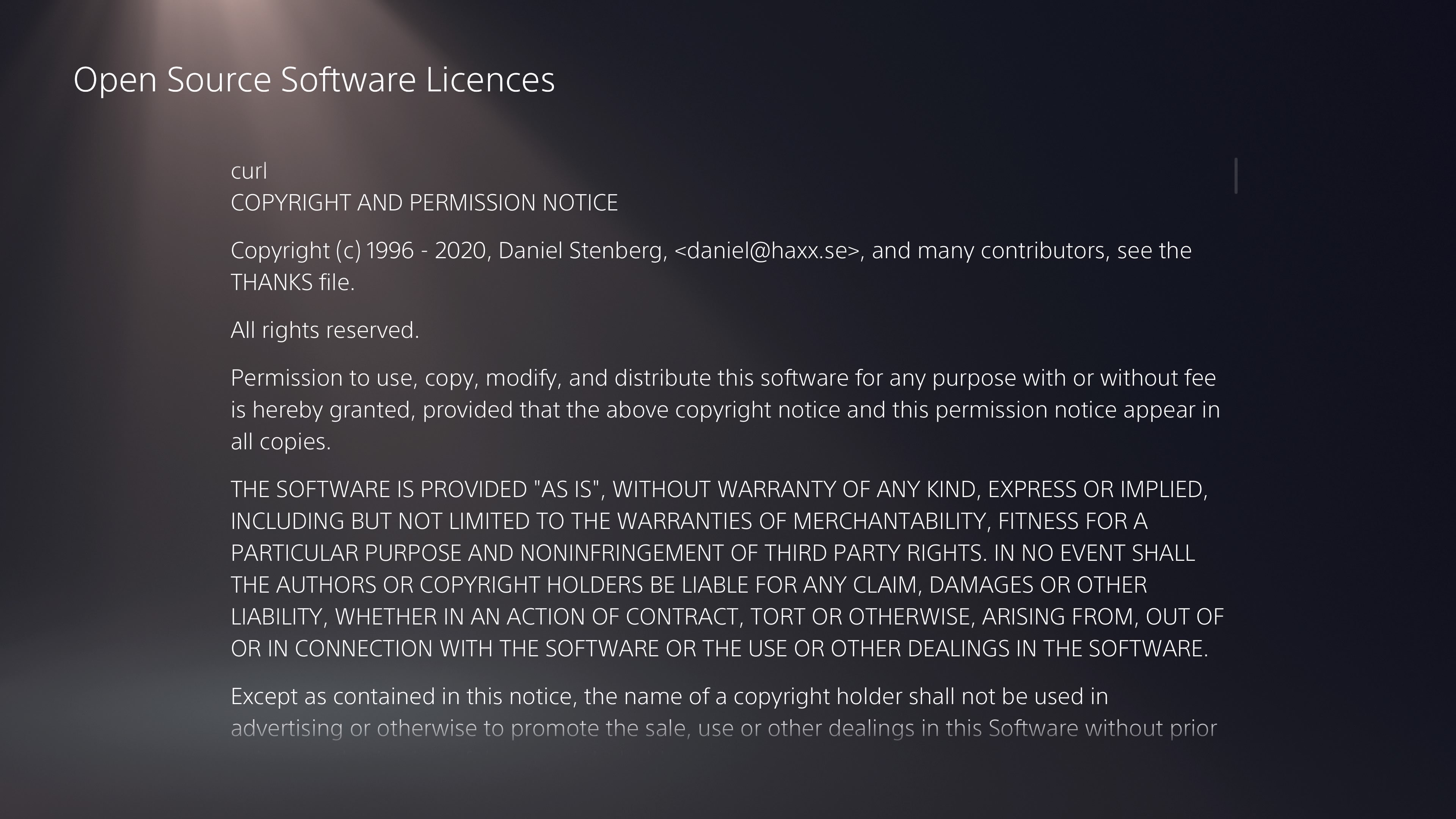
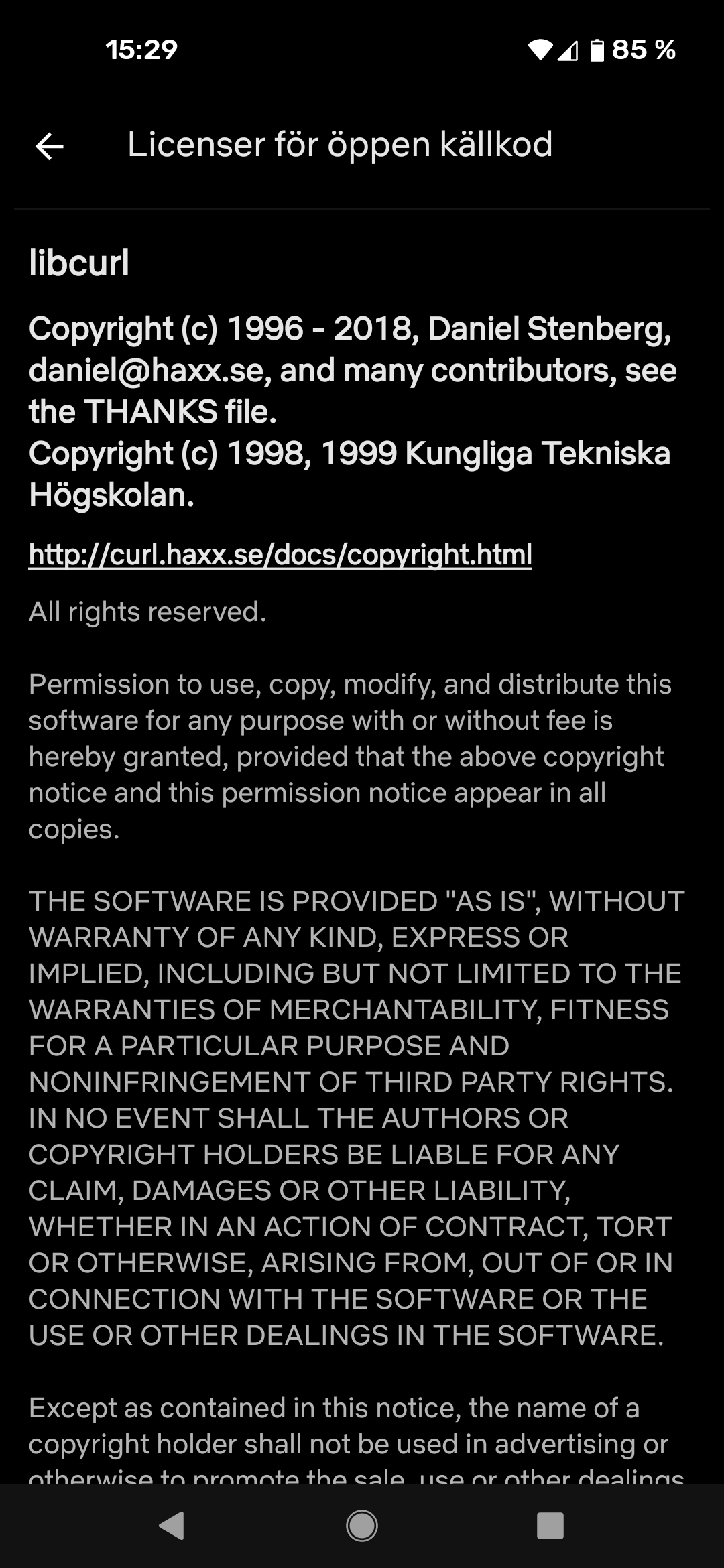
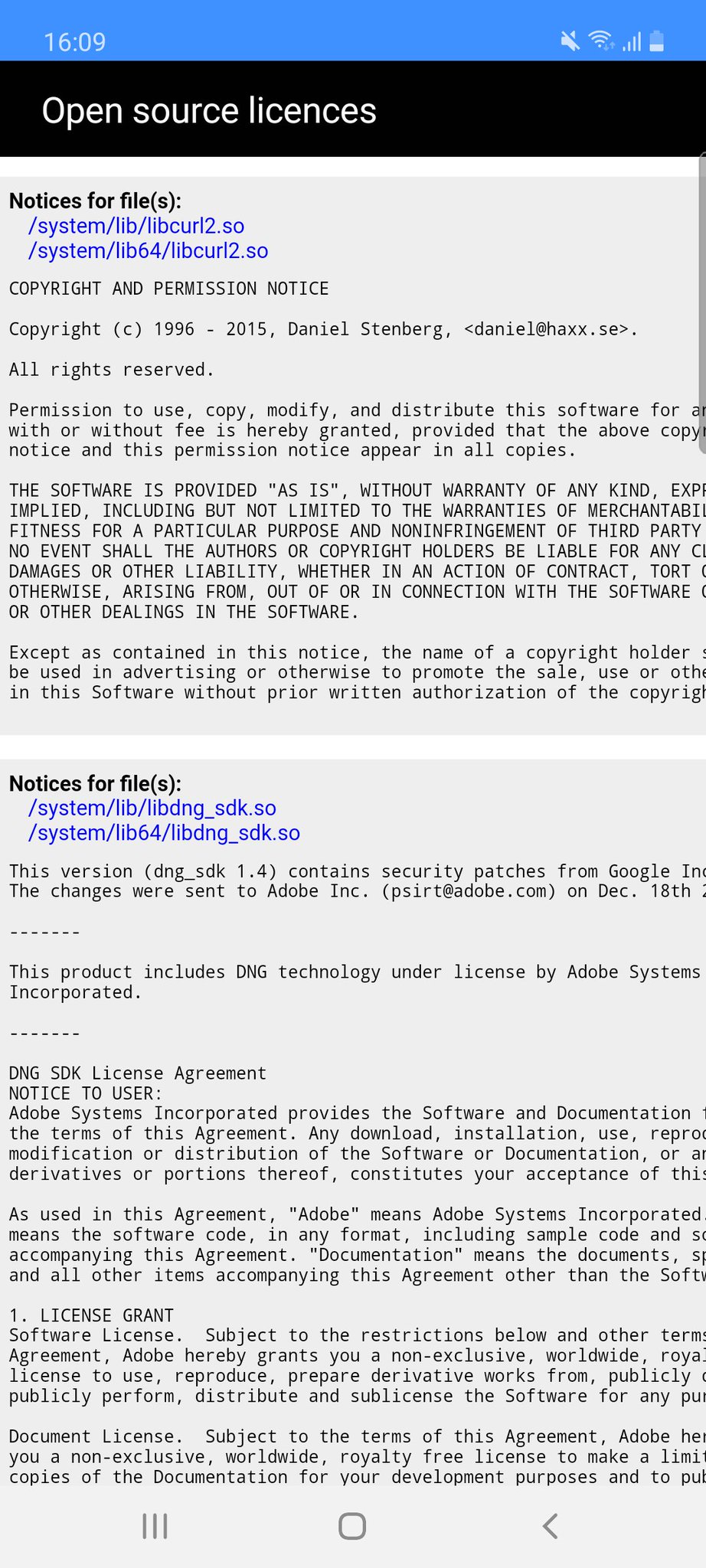
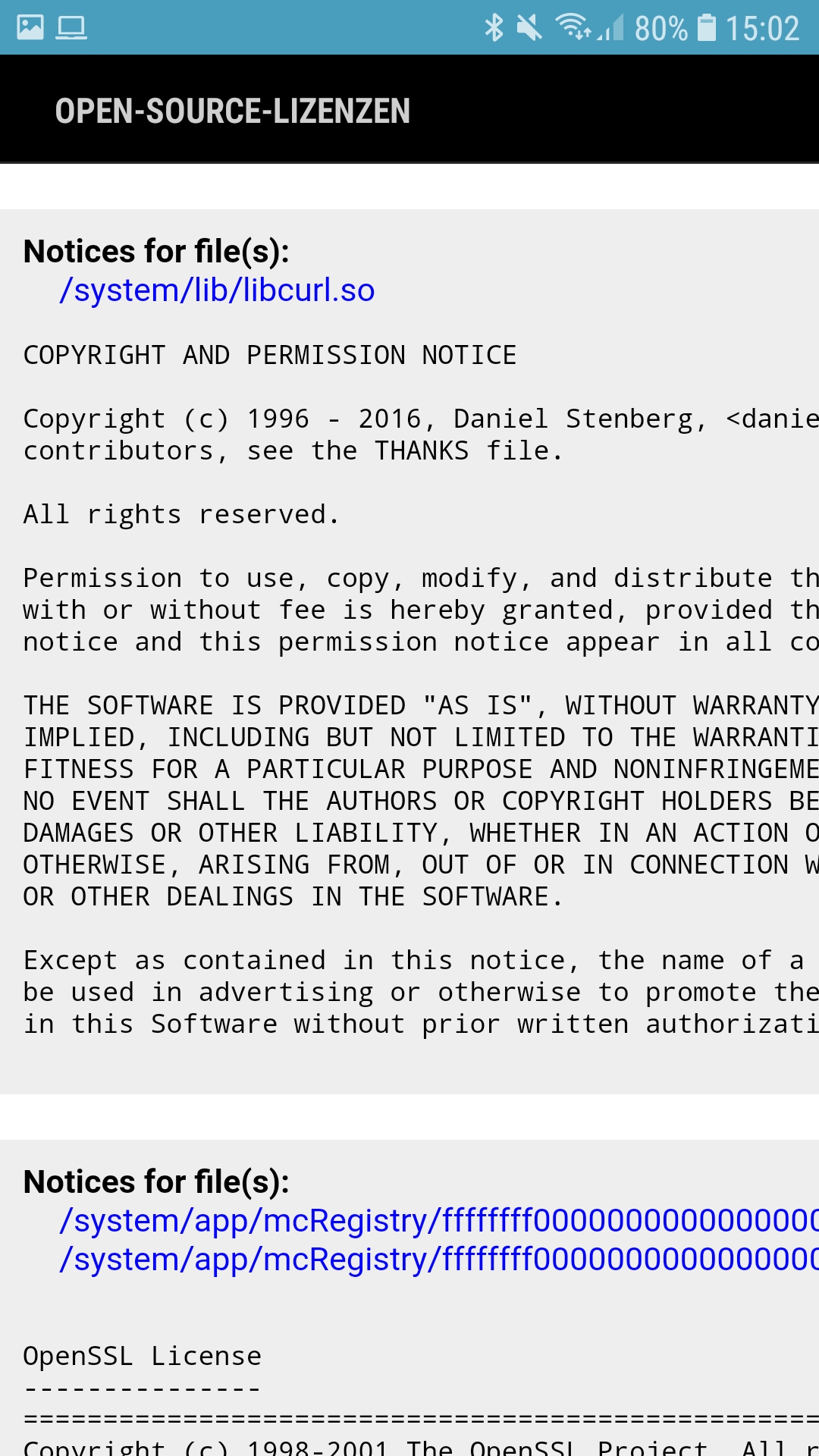
The main effect is that normal end users find my email address via the curl license text in products in cars to a higher degree. They usually find it in the about window or an open source license listing or similar. Often I suspect my email address is just about the only address listed.
This occasionally makes desperate users who have tried everything to eventually reach out to me. They can’t fix their problem but since my email exists in their car, surely I can!
Here are three of my favorite samples that I saved.
November 13, 2016
Hello sir
I have Avalon 2016
Regarding the audio player, why there delay between audio and video when connect throw Bluetooth and how to fix it.
November 5, 2015
Hello,
I am using in a new Ford Mondeo the navigation system with SD Card FM5T-19H449-FC Europe F4.
I can read the card but not write on it. I want to add to the card some POI´s. Can you help me to do it?
June 8, 2015
Hello
I have toyota corola with multimedya system that you have its copyright.
I need a advice to know how to use the gps .
Now i cant use or see maps.
And i want to know how to add hebrew leng.
How do I respond?
I’m sad to say that I rarely respond at all. I can’t help them and I’ve learned over the years that just trying to explain how I have nothing to do with the product they’re using is often just too time consuming and energy draining to be worth it. I hope these people found the answers to the problems via other means.
The hacker news discussions on this post took off. I just want to emphasize that this post is not a complaint. I’m not whining over this. I’m just showing some interesting side-effects of my email in the license text. I actually find these emails interesting, sometimes charming and they help me connect to the reality many people experience out there.
Already now, both Firefox and Chrome have test versions out with TLS 1.3 enabled. Firefox 52 will have it by default, and while Chrome will ship it, I couldn’t figure out exactly when we can expect it to be there by default.
Over the last few days we’ve merged TLS 1.3 support to curl, primarily in this commit by Kamil Dudka. Both the command line tool and libcurl will negotiate TLS 1.3 in the next version (7.52.0 – planned release date at the end of December 2016) if built with a TLS library that supports it and told to do it by the user.
The two current TLS libraries that will speak TLS 1.3 when built with curl right now is NSS and BoringSSL. The plan is to gradually adjust curl over time as the other libraries start to support 1.3 as well. As always we will appreciate your help in making this happen!
Right now, there’s also the minor flux in that servers and clients may end up running implementations of different draft versions of the TLS spec which contributes to a layer of extra fun!
TLS 1.3 offers a few new features that allow clients such as curl to do subsequent TLS connections much faster, with only 1 or even 0 RTTs, but curl has no code for any of those features yet.
I talked with Ed Hoover on the between screens podcast a while ago and that episode has now been published. It is a dense 12 minutes as the good Ed edited it massively.
Everyone interested in curl, libcurl and related matters is invited to participate. We only ask of you to register and pay the small fee. The fee will be used for food and more at the event.
You’ll find the full and detailed description of the event and the specific location in the curl wiki.
The agenda for the weekend is purposely kept loose to allow for flexibility and unconference-style adding things and topics while there. You will thus have the chance to present what you like and affect what others present. Do tell us what you’d like to talk about or hear others talk about! The sign-up for the event isn’t open yet, as we first need to work out some more details.
We have a dedicated mailing list for discussing the meeting, called curl-meet, so please consider yourself invited to join in there as well!
Thanks a lot to SUSE for hosting!
Feel free to help us make a cool logo for the event!
(The 19th birthday of curl is suitably enough the day after, on March 20.)
When Mac OS X first launched they did so without an existing poll function. They later added poll() in Mac OS X 10.3, but we quickly discovered that it was broken (it returned a non-zero value when asked to wait for nothing) so in the curl project we added a check in configure for that and subsequently avoided using poll() in all OS X versions to and including Mac OS 10.8 (Darwin 12). The code would instead switch to the alternative solution based on select() for these platforms.
With the release of Mac OS X 10.9 “Mavericks” in October 2013, Apple had fixed their poll() implementation and we’ve built libcurl to use it since with no issues at all. The configure script picks the correct underlying function to use.
Enter macOS 10.12 (yeah, its not called OS X anymore) “Sierra”, released in September 2016. Quickly we discovered that poll() once against did not act like it should and we are back to disabling the use of it in preference to the backup solution using select().
The new error looks similar to the old problem: when there’s nothing to wait for and we ask poll() to wait N milliseconds, the 10.12 version of poll() returns immediately without waiting. Causing busy-loops. The problem has been reported to Apple and its Radar number is 28372390. (There has been no news from them on how they plan to act on this.)
If none of the defined events have occurred on any selected file descriptor, poll() waits at least timeout milliseconds for an event to occur on any of the selected file descriptors.
We pushed a configure check for this in curl, to be part of the upcoming 7.51.0 release. I’ll also show you a small snippet you can use stand-alone below.
Apple is hardly alone in the broken-poll department. Remember how Windows’ WSApoll is broken?
Here’s a little code snippet that can detect the 10.12 breakage:
This poll bug has been confirmed fixed in the macOS 10.12.2 update (released on December 13, 2016), but I’ve found no official mention or statement about this fact.
Chevrolet Traverse 2018 uses curl according to its owners manual on page 403. It is mentioned almost identically in other Chevrolet model manuals such as for the Corvette, the 2018 Camaro, the 2018 TRAX, the 2013 VOLT, the 2014 Express and the 2017 BOLT.
The curl license is also in owner manuals for other brands and models such as in the GMC Savana, Cadillac CT6 2016, Opel Zafira, Opel Insignia, Opel Astra, Opel Karl, Opel Cascada, Opel Mokka, Opel Ampera, Vauxhall Astra … (See 100 million cars run curl).
The Onkyo TX-NR609 AV-Receiver uses libcurl as shown by the license in its manual. (Thanks to Marc Hörsken)







 The main effect is that normal end users find my email address via the
The main effect is that normal end users find my email address via the  shed at the end of October 2016.
shed at the end of October 2016.