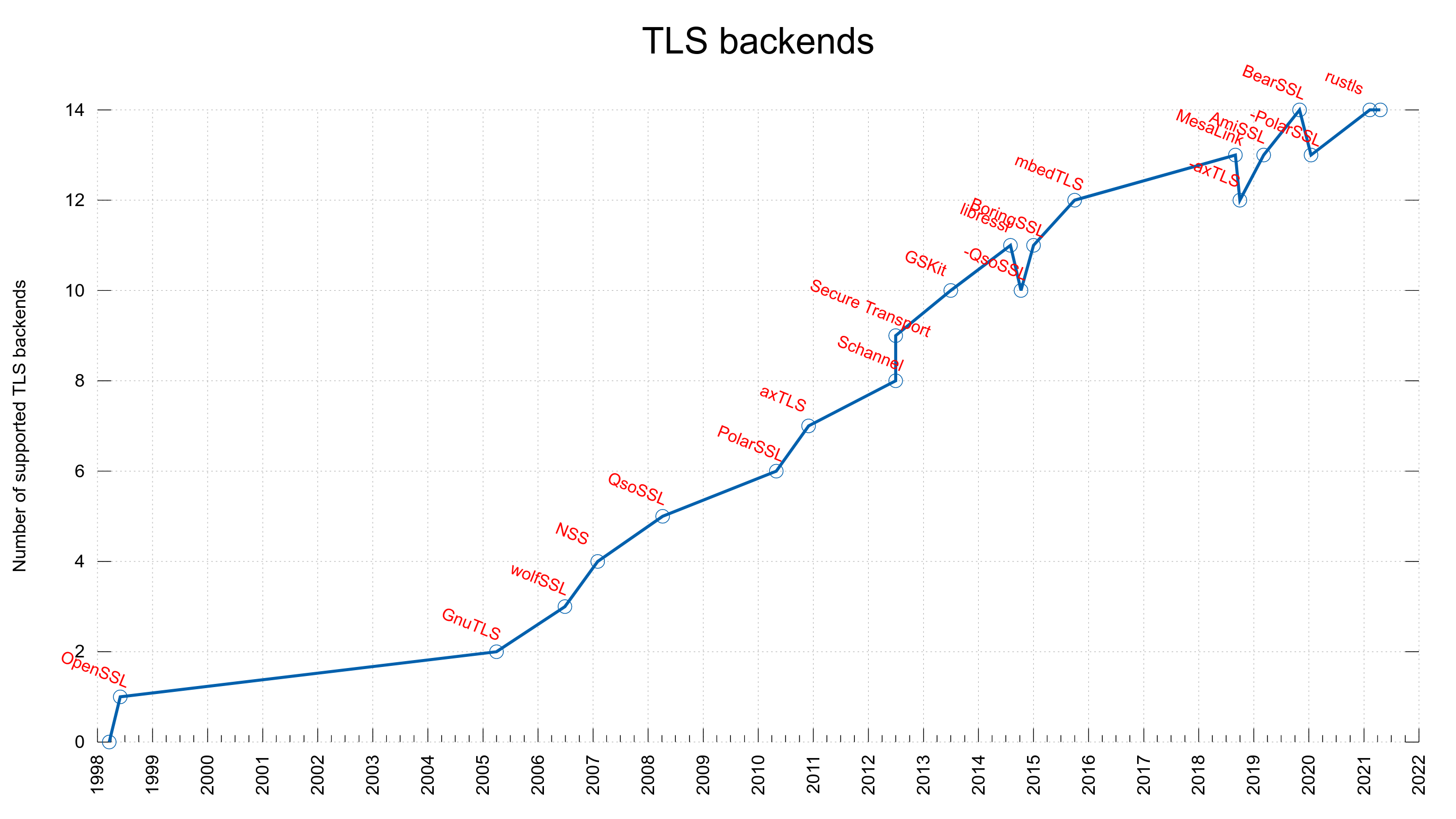
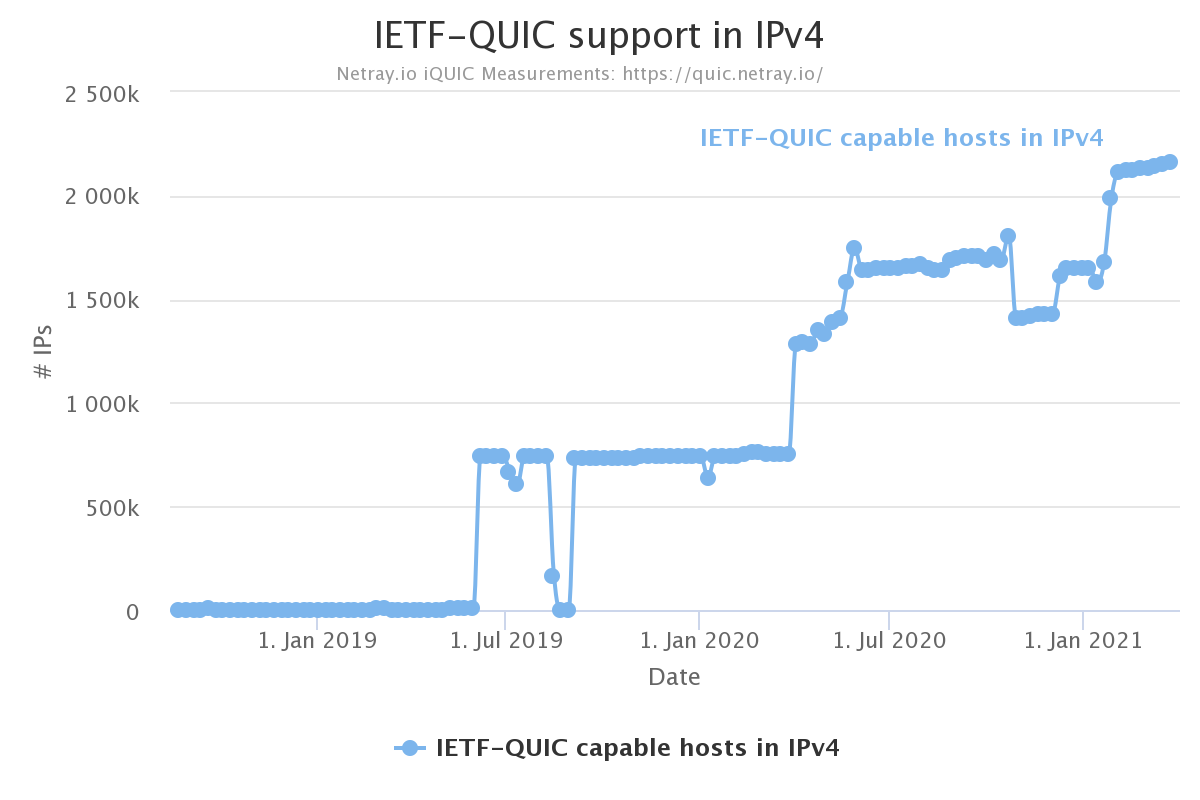
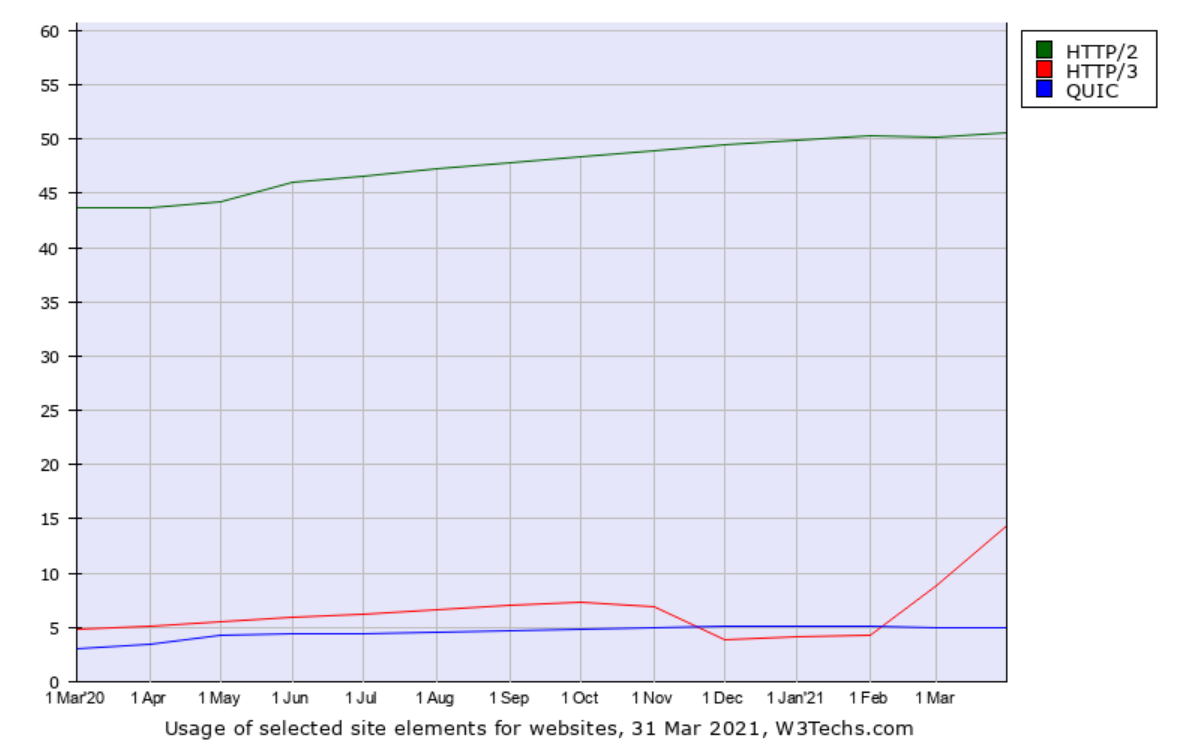
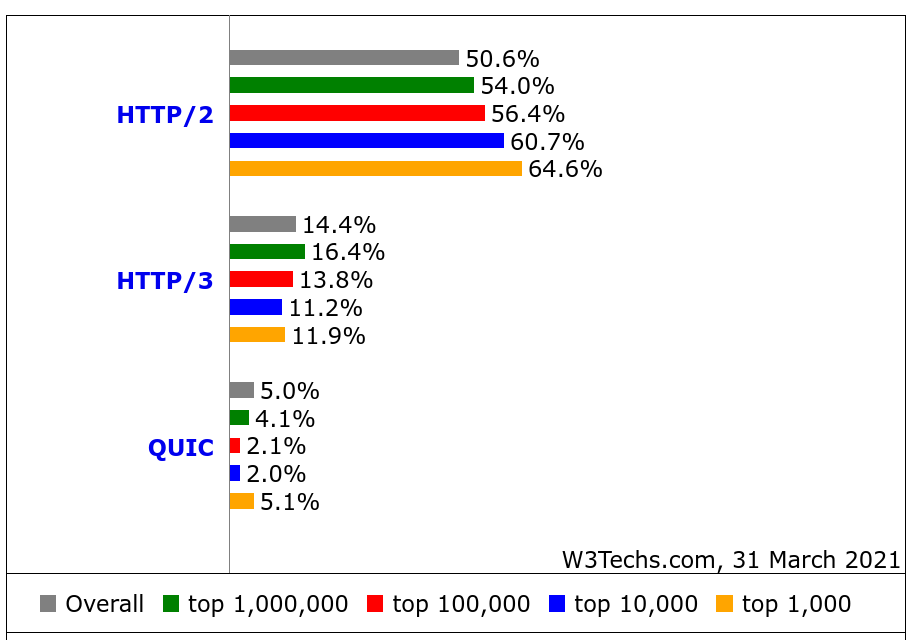
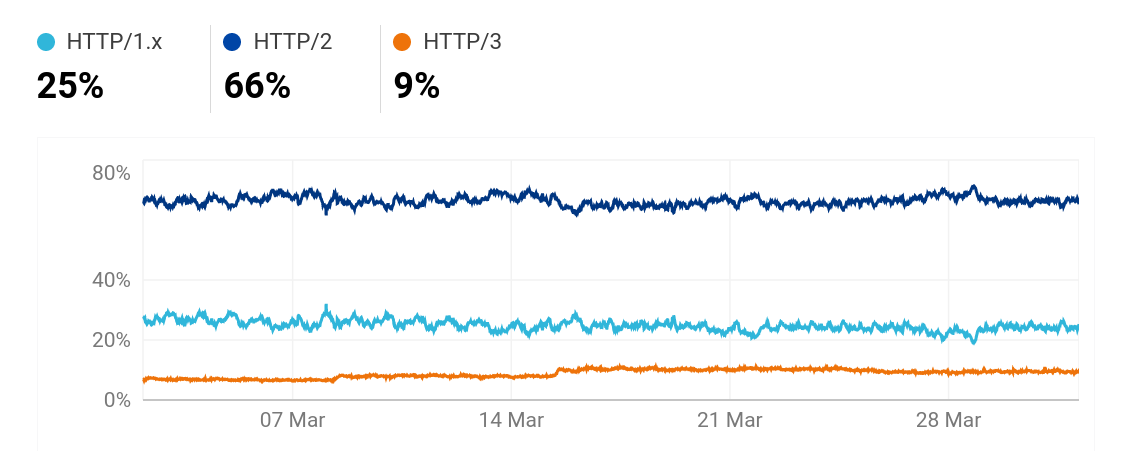
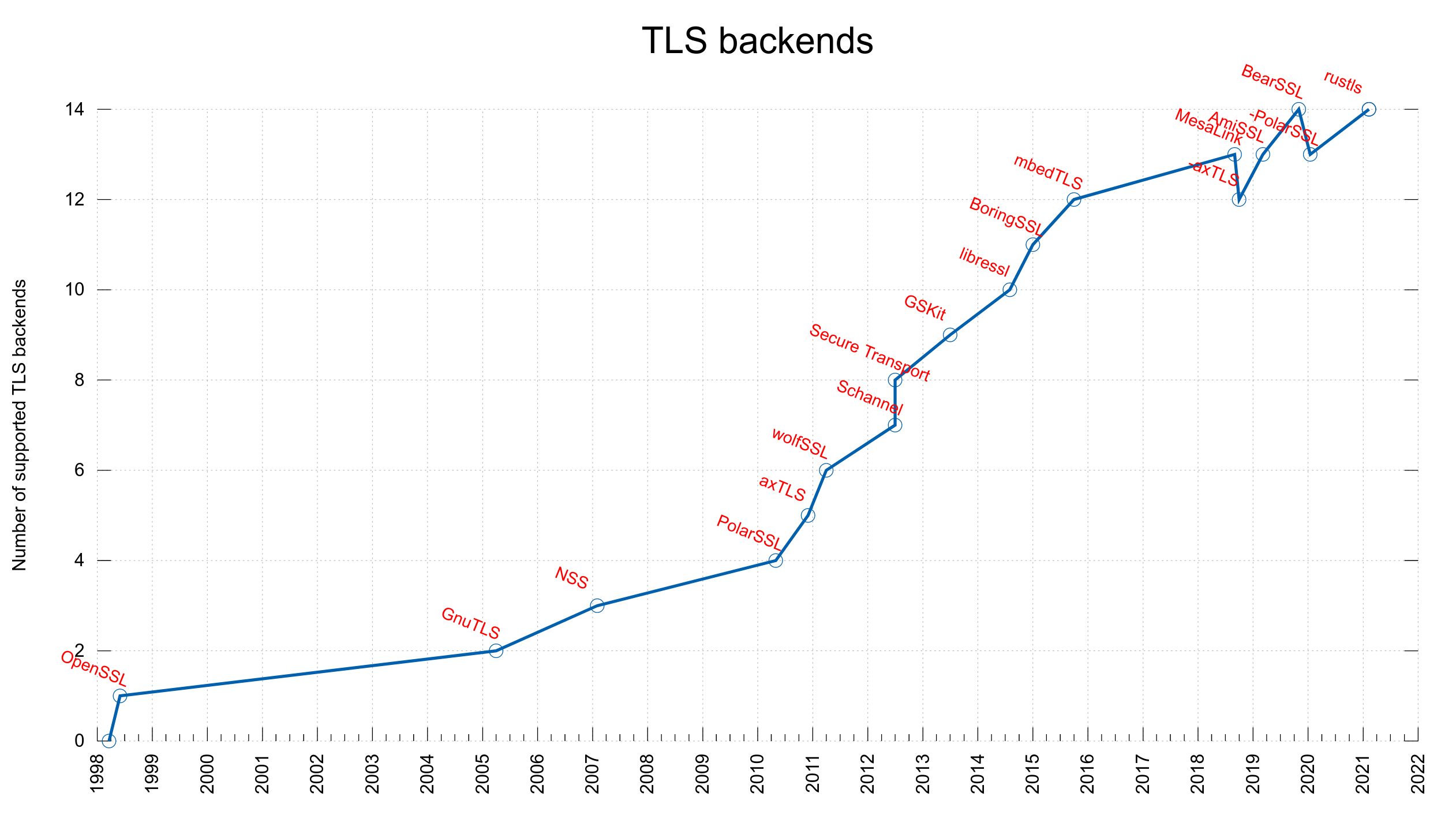
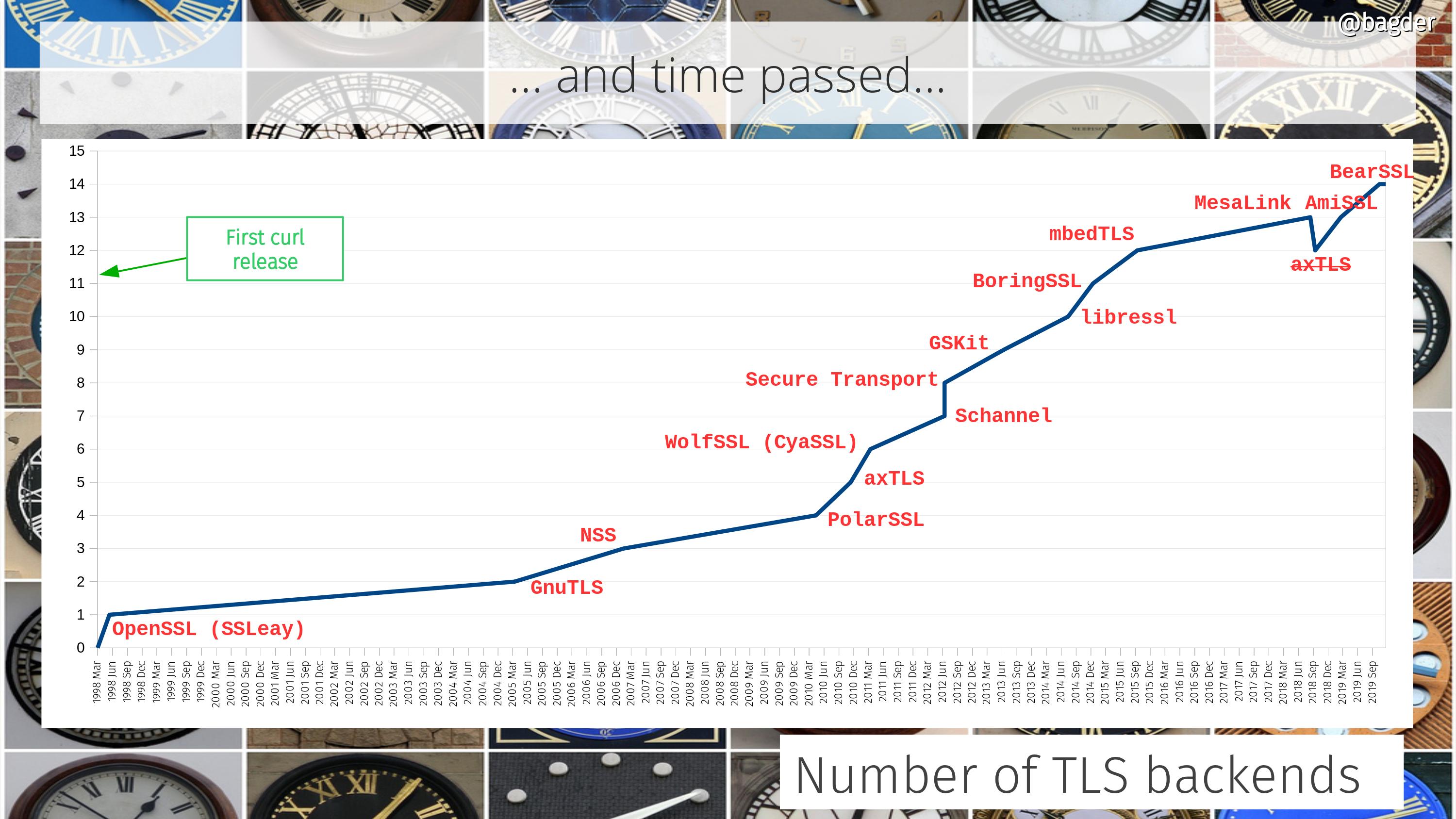
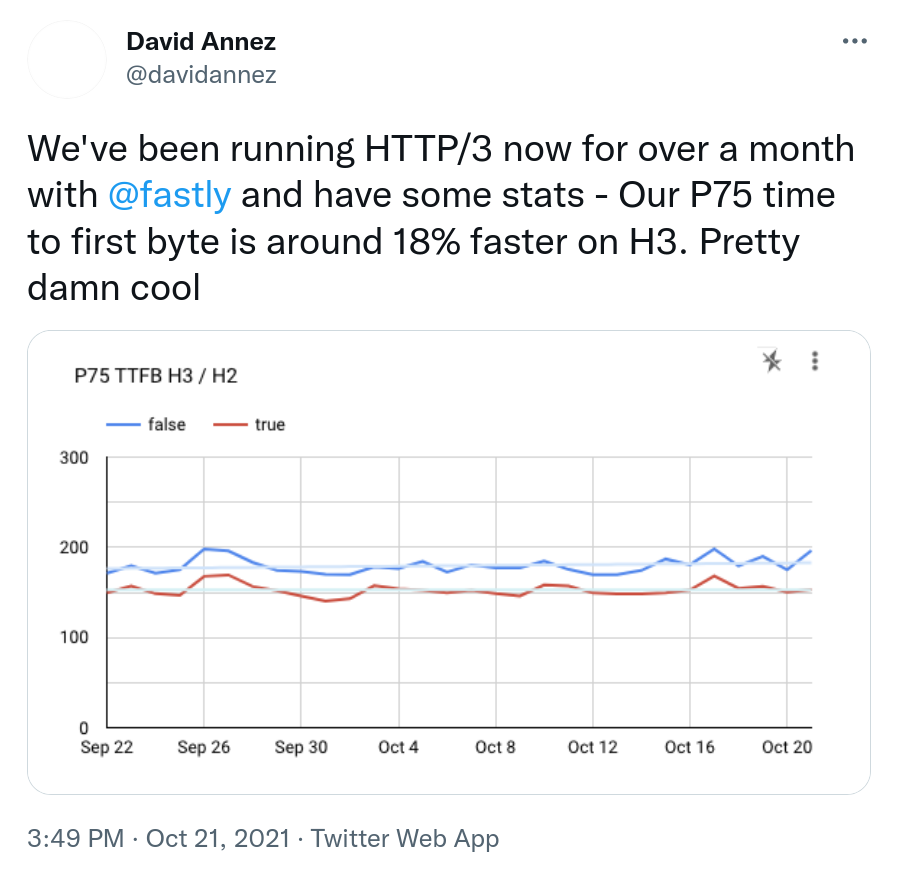
In a world that is now gradually adopting HTTP/3 (which, as you know, is implemented over QUIC), the problem with the missing API for QUIC is still a key problem.
There are a number of existing QUIC library implementation now since a few years back, and they are slowly maturing. The QUIC protocol became RFC 9000 and friends, but the most popular TLS libraries still don’t provide the necessary APIs to make QUIC libraries possible to use them.
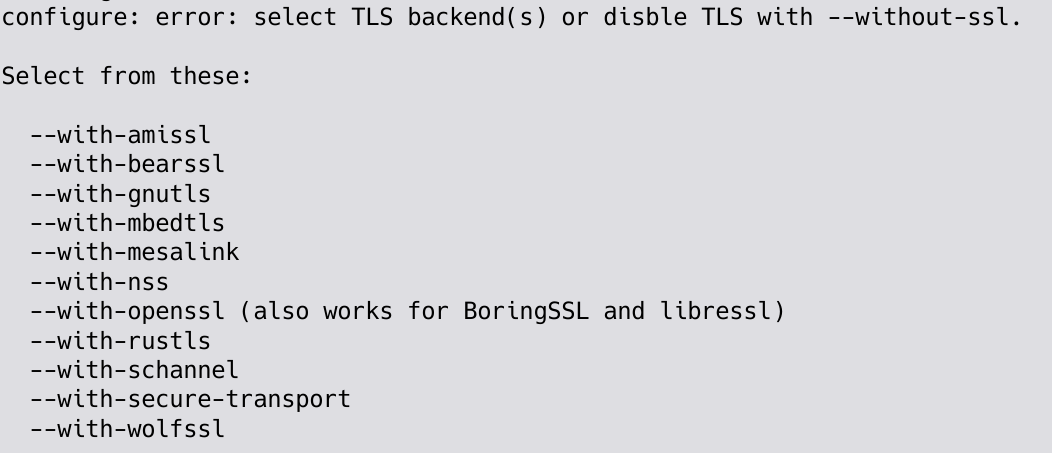
Example that makes people want HTTP/3
OpenSSL PR8797
For a long time, many people and projects (including yours truly) in the QUIC community were eagerly following the OpenSSL Pull Request 8797, which introduced the necessary QUIC APIs into OpenSSL. This change brought the same API to OpenSSL that BoringSSL already provides and as such the API has already been used and tested out by several independent implementations.
Implementations have a problem to ship to the world based on BoringSSL since that’s a TLS library without versions and proper releases, so it is not a good choice for the big wide world. OpenSSL is already the most widely used TLS library out there and lots of applications are already made to use that.
Delays made quictls happen
The OpenSSL PR8797 was delayed back in February 2020 on when the OpenSSL management committee (OMC) decreed that they would not deal with that PR until after their pending 3.0.0 release had shipped.
“It is our expectation that once the 3.0 release is done, QUIC will become a significant focus of our effort.”
OpenSSL then proceeded and their 3.0.0 release was delayed significantly compared to their initial time schedule.
In March 2021, Microsoft and Akamai announced quictls, an OpenSSL fork with the express idea to ship OpenSSL + the QUIC API. They didn’t want to wait for OpenSSL to do it.
Several QUIC libraries can now use quictls. quictls has kept their fork up to date and now offers the equivalent of OpenSSL 3.0.0 + the QUIC API.
While we’ve been waiting for OpenSSL to adopt the API.
OpenSSL makes a turn instead
Then came the next blow to everyone’s expectations. An autumn surprise. On October 13, the OpenSSL OMC announces:
The focus for the next releases is QUIC, with the objective of providing a fully functional QUIC implementation over a series of releases (2-3).
OpenSSL has decided to implement a complete QUIC stack on their own and with the given time line it sounds like it will take them a few years (?) to ship. And instead of providing the API lots of implementers have been been waiting for so long, they explicitly say that it is a non-goal at the start:
The MVP will not contain a library API for an HTTP/3 implementation (it is a non-goal of the initial release).
I didn’t write my own QUIC implementation but I’ve followed the work of several of the implementations fairly closely and it is fairly complicated journey they set out for themselves – for very unclear reasons. There already exist several high quality QUIC libraries, why does OpenSSL think they need to make yet another one? They seem to be overloaded with work already before, which the long delays of the 3.0.0 release seemed to show, how are they going to be able to add a complete new stack implementation of top of this? The future will tell.
PR8797 closed
On October 20 2021, the pull request that was created in April 2019, is finally closed for real as a “won’t fix”.
Where are we now?
The lack of a QUIC API in OpenSSL has held us back and with this move from OpenSSL, it will continue to hold us back for an uncertain amount of time going forward.
QUIC stacks will have to stick to using or switching to other libraries.
I’m disappointed.
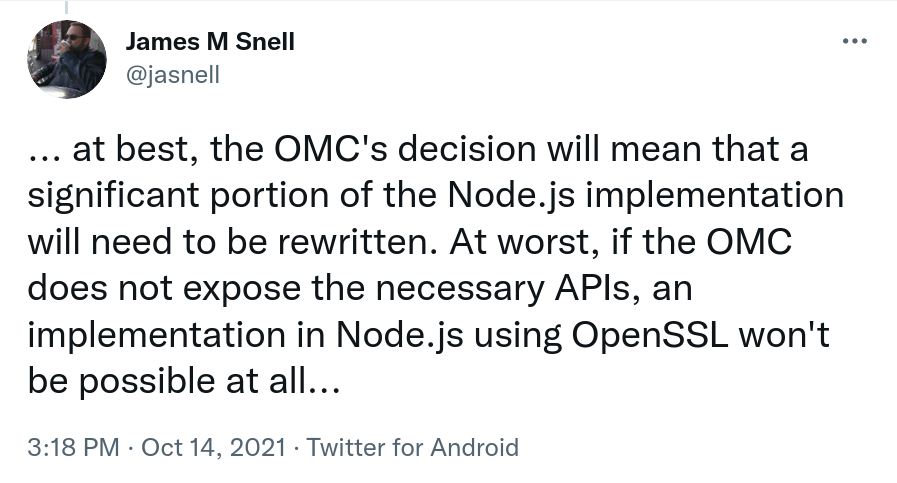
James Snell, one of the key contributors on the QUIC and HTTP/3 work in nodejs tweeted:
Credits
Image by Marzena P. from Pixabay