libcurl has done internet transfers specified as URLs for a long time, but the URLs you’d tell libcurl to use would always just get parsed and used internally.
Applications that pass in URLs to libcurl would of course still very often need to parse URLs, create URLs or otherwise handle them, but libcurl has not been helping with that.
At the same time, the under-specification of URLs has led to a situation where there’s really no stable document anywhere describing how URLs are supposed to work and basically every implementer is left to handle the WHATWG URL spec, RFC 3986 and the world in between all by themselves. Understanding how their URL parsing libraries, libcurl, other tools and their favorite browsers differ is complicated.
By offering applications access to libcurl’s own URL parser, we hope to tighten a problematic vulnerable area for applications where the URL parser library would believe one thing and libcurl another. This could and has sometimes lead to security problems. (See for example Exploiting URL Parser in Trending Programming Languages! by Orange Tsai)
Additionally, since libcurl deals with URLs and virtually every application using libcurl already does some amount of URL fiddling, it makes sense to offer it in the “same package”. In the curl user survey 2018, more than 40% of the users said they’d use an URL API in libcurl if it had one.
Handle based
Create a handle, operate on the handle and then cleanup the handle when you’re done with it. A pattern that is familiar to existing users of libcurl.
So first you just make the handle.
/* create a handle */
CURLU *h = curl_url();
Parse a URL
Give the handle a full URL.
/* "set" a URL in the handle */
curl_url_set(h, CURLUPART_URL,
"https://example.com/path?q=name", 0);
If the parser finds a problem with the given URL it returns an error code detailing the error. The flags argument (the zero in the function call above) allows the user to tweak some parsing behaviors. It is a bitmask and all the bits are explained in the curl_url_set() man page.
A parsed URL gets split into its components, parts, and each such part can be individually retrieved or updated.
Get a URL part
Get a separate part from the URL by asking for it. This example gets the host name:
/* extract host from the URL */
char *host;
curl_url_get(h, CURLUPART_HOST, &host, 0);
/* use it, then free it */
curl_free(host);
As the example here shows, extracted parts must be specifically freed with curl_free() once the application is done with them.
The curl_url_get() can extract all the parts from the handle, by specifying the correct id in the second argument. scheme, user, password, port number and more. One of the “parts” it can extract is a bit special: CURLUPART_URL. It returns the full URL back (normalized and using proper syntax).
curl_url_get() also has a flags option to allow the application to specify certain behavior.
Set a URL part
/* set a URL part */
curl_url_set(h, CURLUPART_PATH, "/index.html", 0);
curl_url_set() lets the user set or update all and any of the individual parts of the URL.
curl_url_set() can also update the full URL, which also accepts a relative URL in case an existing one was already set. It will then apply the relative URL onto the former one and “transition” to the new absolute URL. Like this;
/* first an absolute URL */
curl_url_set(h, CURLUPART_URL,
"https://example.org:88/path/html", 0);
/* .. then we set a relative URL "on top" */
curl_url_set(h, CURLUPART_URL,
"../new/place", 0);
Duplicate a handle
It might be convenient to setup a handle once and then make copies of that…
CURLU *n = curl_url_dup(h);
Cleanup the handle
When you’re done working with this URL handle, free it and all its related resources.
curl_url_cleanup(h);
Ship?
This API is marked as experimental for now and ships for the first time in libcurl 7.62.0 (October 31, 2018). I will happily read your feedback and comments on how it works for you, what’s missing and what we should fix to make it even more usable for you and your applications!
We call it experimental to reserve the right to modify it slightly going forward if necessary, and as soon as we remove that label the API will then be fixed and stay like that for the foreseeable future.
See also
The URL API section in Everything curl.











 servers on the Internet. curl and libcurl comes pre-installed on some Linux distributions and for those that it doesn’t, most users and sysadmins install it. My estimate says there are few such servers out there without curl on them.
servers on the Internet. curl and libcurl comes pre-installed on some Linux distributions and for those that it doesn’t, most users and sysadmins install it. My estimate says there are few such servers out there without curl on them. I wrote about this in a
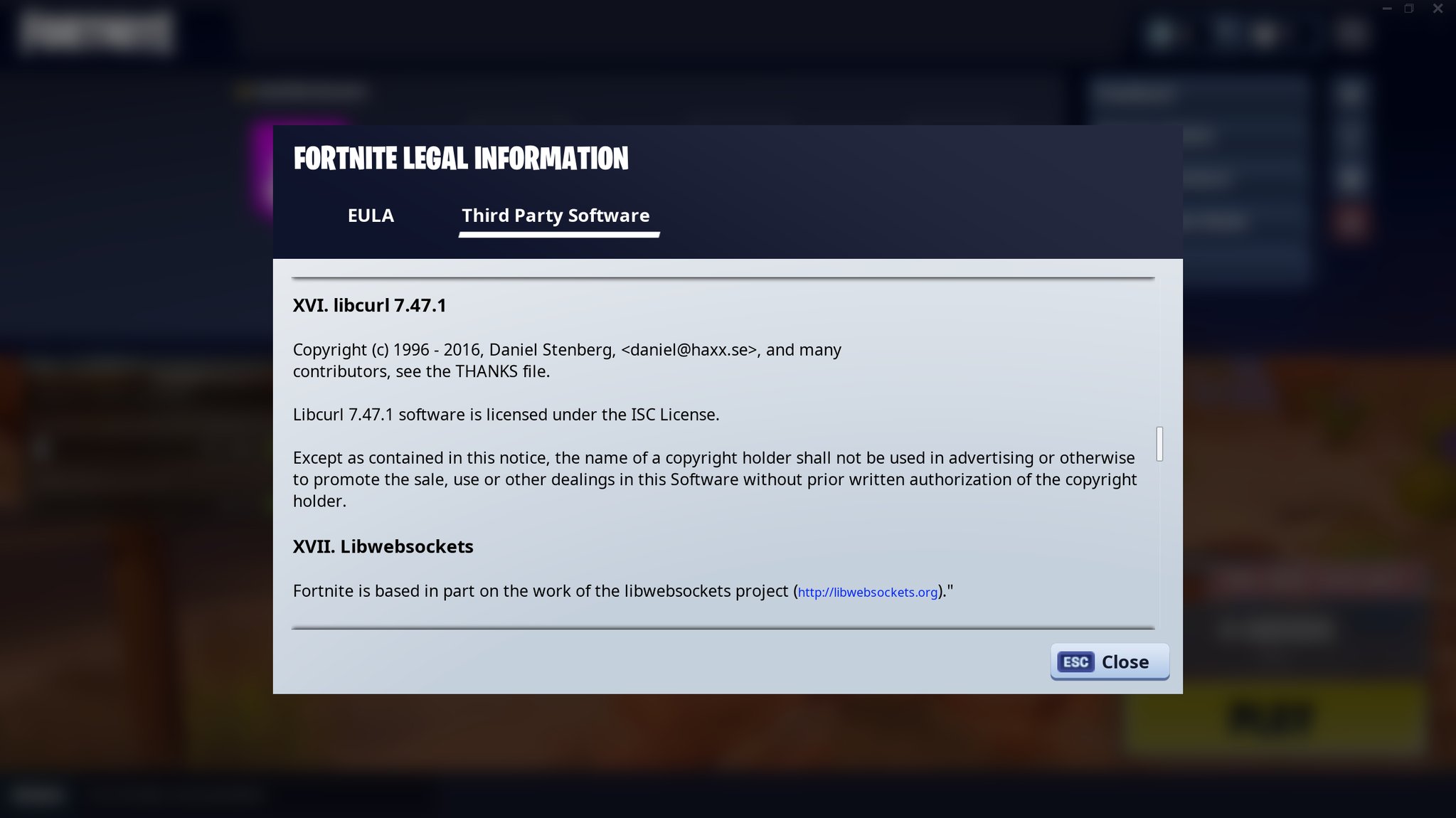
I wrote about this in a  This game is made by Epic Games and credits curl in their
This game is made by Epic Games and credits curl in their  We know curl is used in television sets made by Sony, Philips, Toshiba, LG, Bang & Olufsen, JVC, Panasonic, Samsung and Sharp – at least.
We know curl is used in television sets made by Sony, Philips, Toshiba, LG, Bang & Olufsen, JVC, Panasonic, Samsung and Sharp – at least. I posit that there are almost no smart phones or tablets in the world that doesn’t run curl.
I posit that there are almost no smart phones or tablets in the world that doesn’t run curl.


 Old readers of this blog may remember my ramblings on
Old readers of this blog may remember my ramblings on 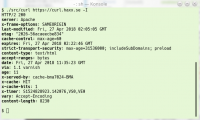


 Over time, we’ve slowly been adjusting the
Over time, we’ve slowly been adjusting the 
{kind=link}
{kind=link}
{kind=link}