Welcome to another curl release. You know the drill…
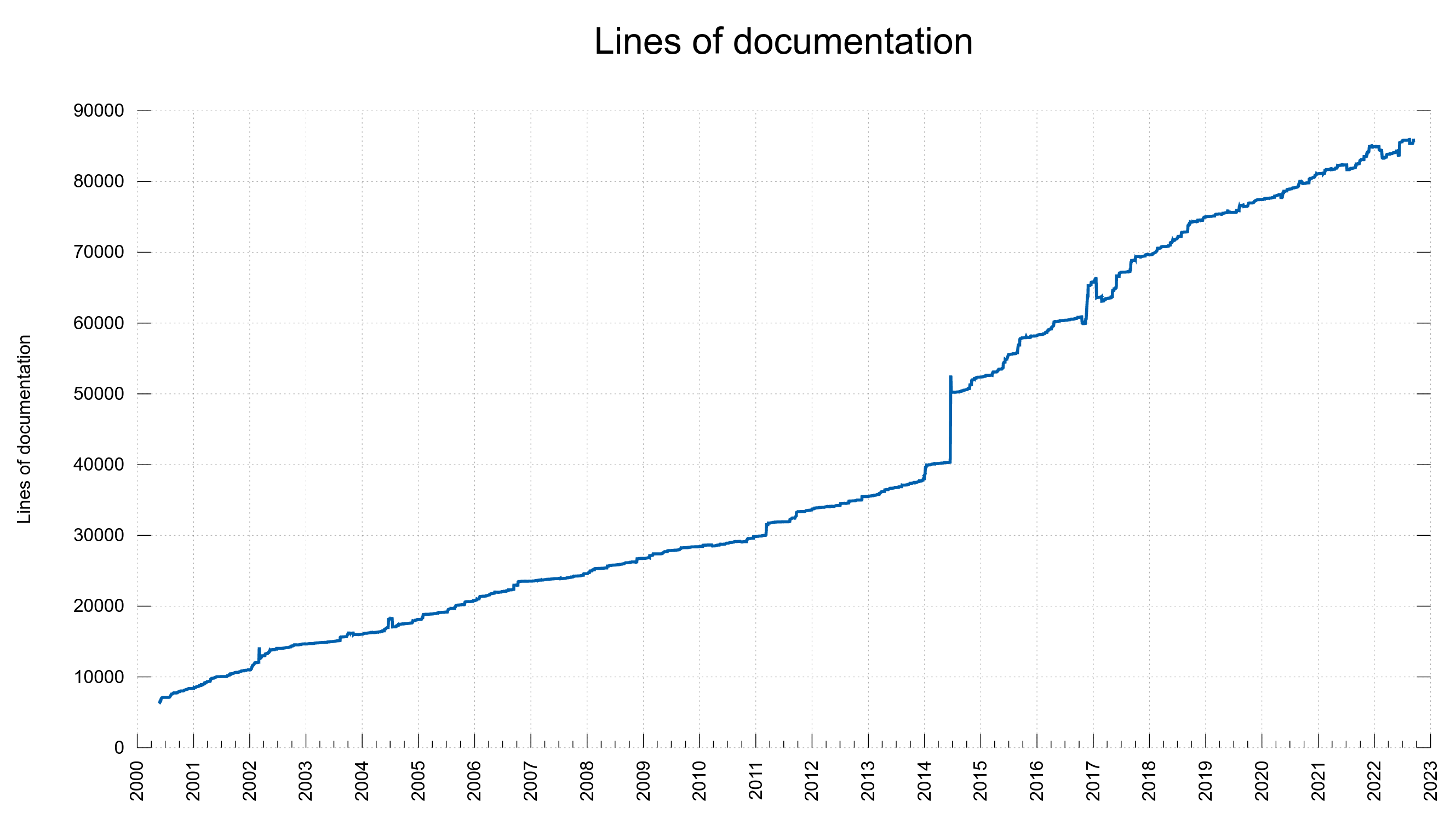
Numbers
the 211th release
2 changes
56 days (total: 8,986)
192 bug-fixes (total: 8,337)
314 commits (total: 29,331)
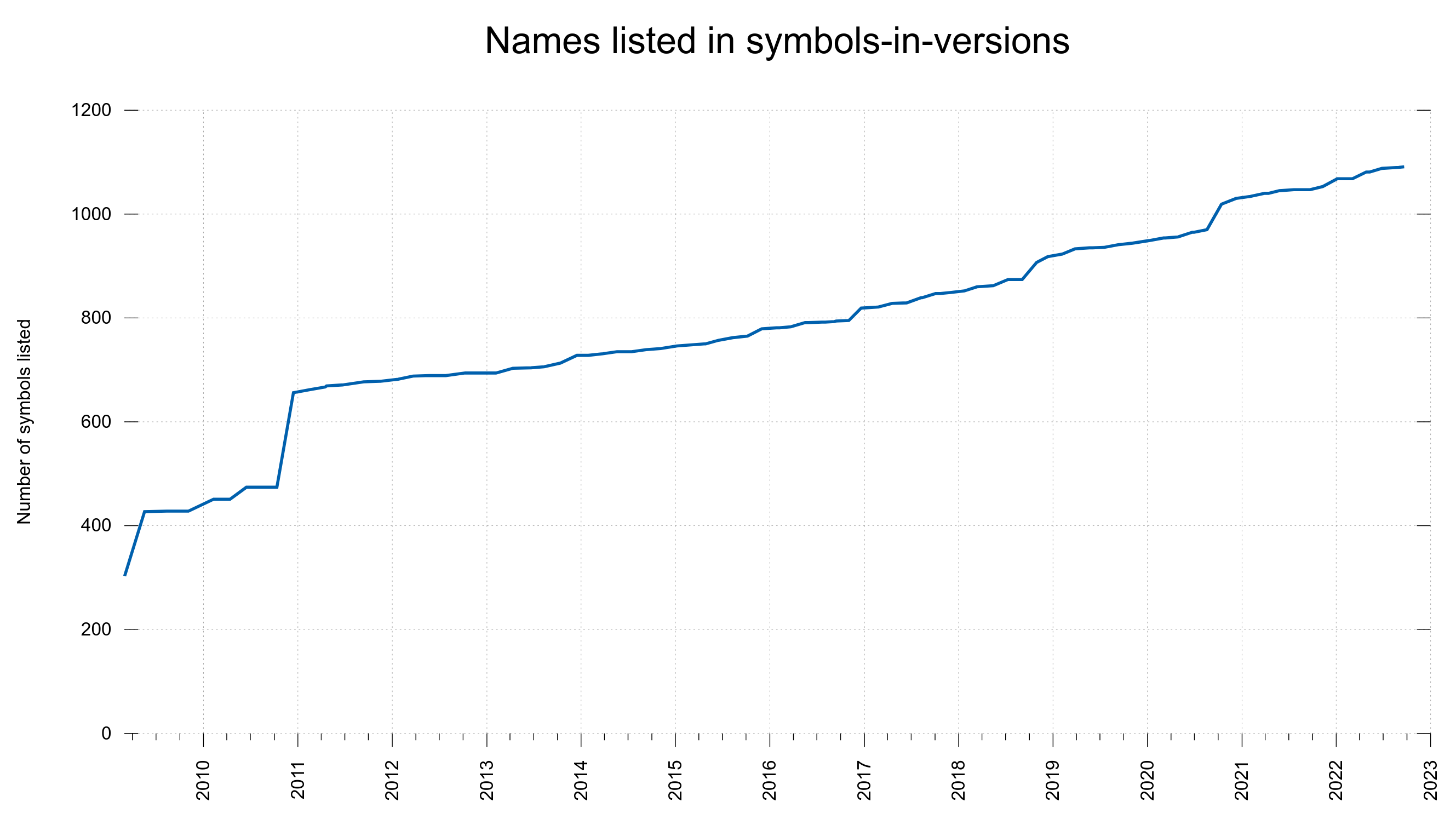
3 new public libcurl function (total: 91)
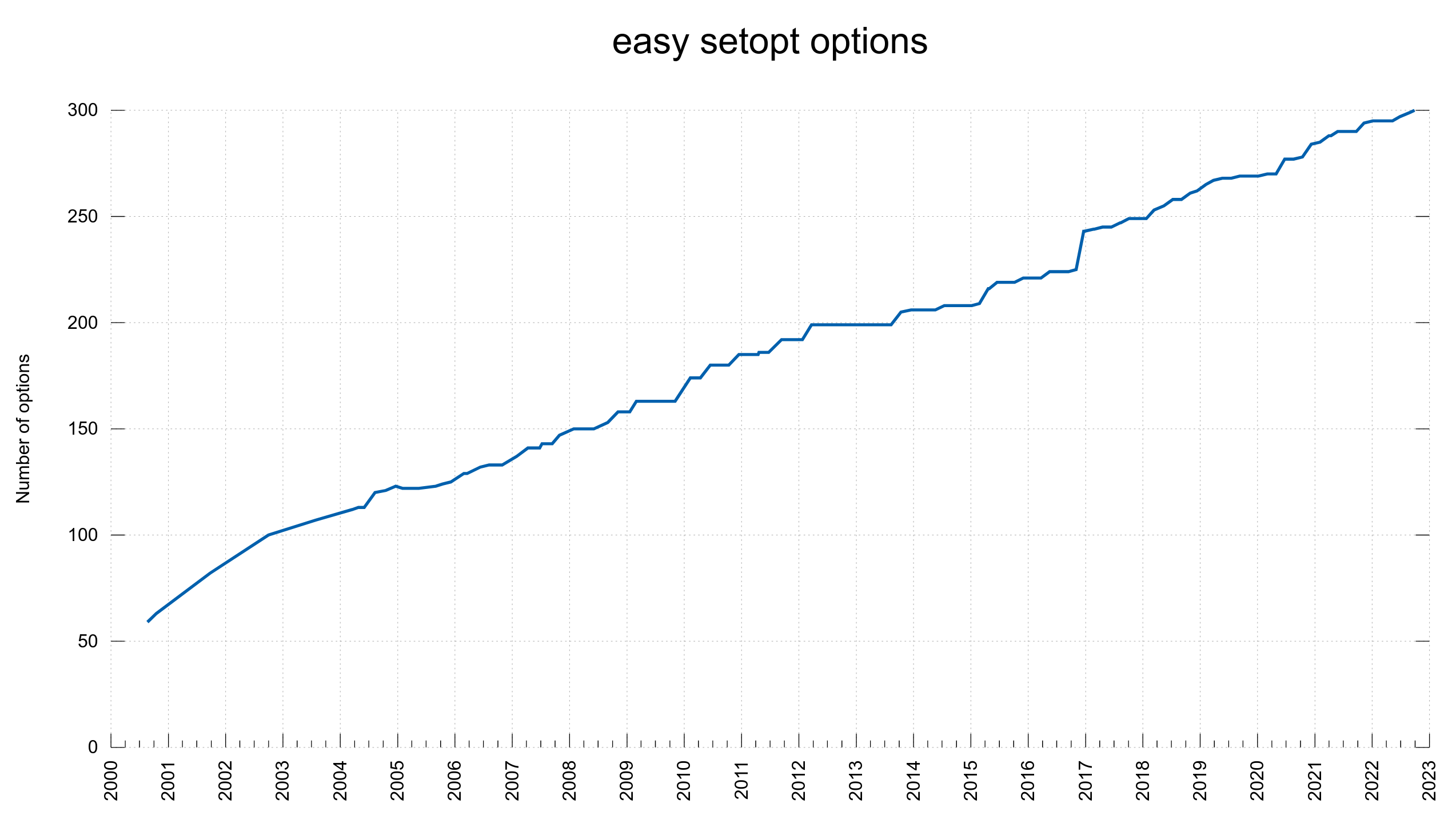
1 new curl_easy_setopt() option (total: 300)
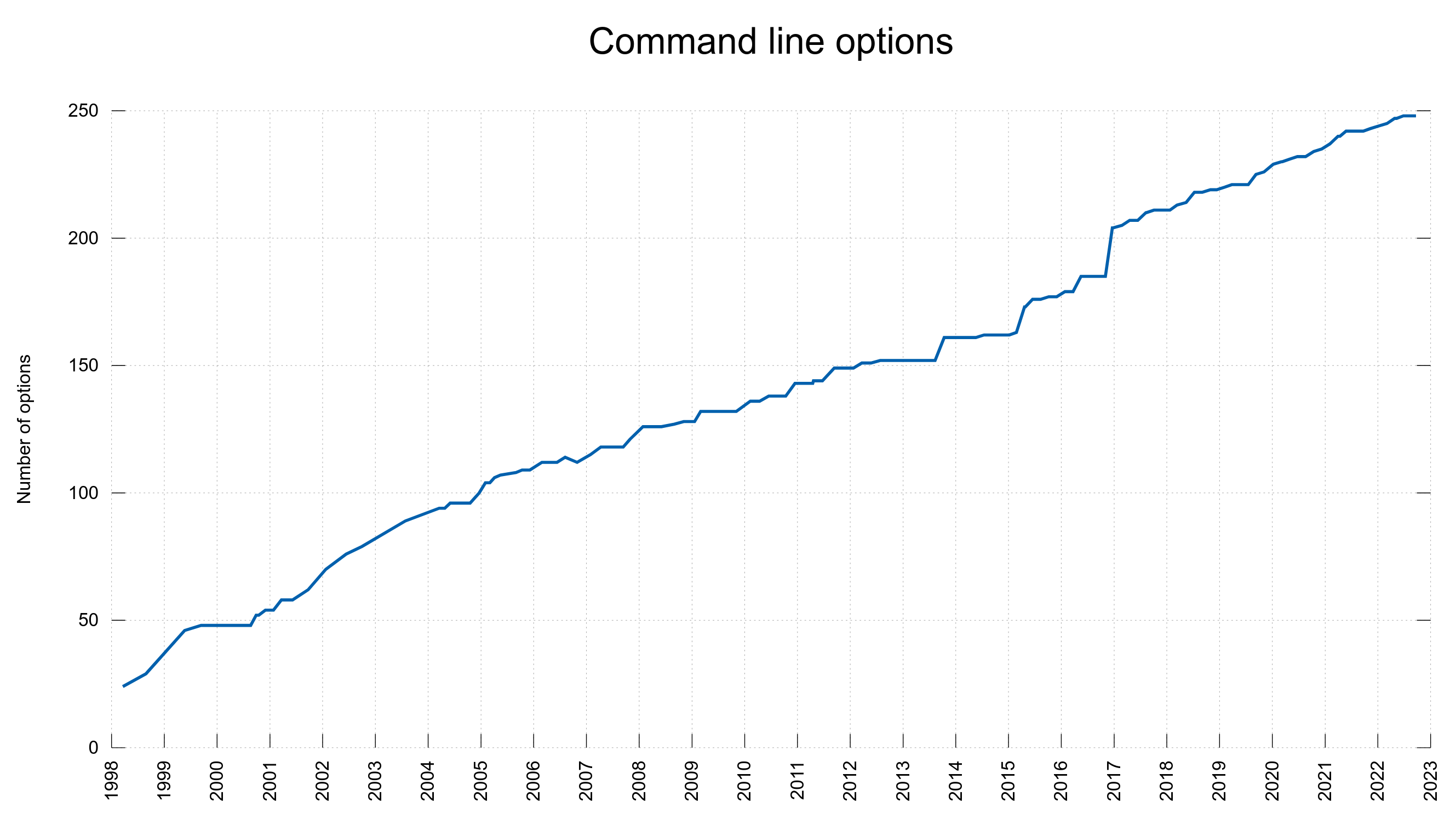
0 new curl command line option (total: 248)
74 contributors, 43 new (total: 2,733)
42 authors, 17 new (total: 1,082)
4 security fixes (total: 130)
Bug Bounties total: 46,180 USD
Release presentation
Security
This release contains fixes for four separate security vulnerabilities.
CVE-2022-32221: POST following PUT confusion
When doing HTTP(S) transfers, libcurl might erroneously use the read callback (CURLOPT_READFUNCTION) to ask for data to send, even when the CURLOPT_POSTFIELDS option has been set, if the same handle previously was used to issue a PUT request which used that callback.
This flaw may surprise the application and cause it to misbehave and either send off the wrong data or use memory after free or similar in the subsequentPOST request.
The problem exists in the logic for a reused handle when it is changed from a PUT to a POST.
CVE-2022-35260: netrc parser out-of-bounds access
curl can be told to parse a .netrc file for credentials. If that file ends in a line with consecutive non-white space letters and no newline, curl could read past the end of the stack-based buffer, and if the read works, write a zero byte possibly beyond its boundary.
This will in most cases cause a segfault or similar, but circumstances might also cause different outcomes.
If a malicious user can provide a custom .netrc file to an application or otherwise affect its contents, this flaw could be used as denial-of-service.
CVE-2022-42915: HTTP proxy double-free
If curl is told to use an HTTP proxy for a transfer with a non-HTTP(S) URL, it sets up the connection to the remote server by issuing a CONNECT request to the proxy, and then tunnels the rest of protocol through.
An HTTP proxy might refuse this request (HTTP proxies often only allow outgoing connections to specific port numbers, like 443 for HTTPS) and instead return a non-200 response code to the client.
Due to flaws in the error/cleanup handling, this could trigger a double-free in curl if one of the following schemes were used in the URL for the transfer: dict, gopher, gophers, ldap, ldaps, rtmp, rtmps, telnet
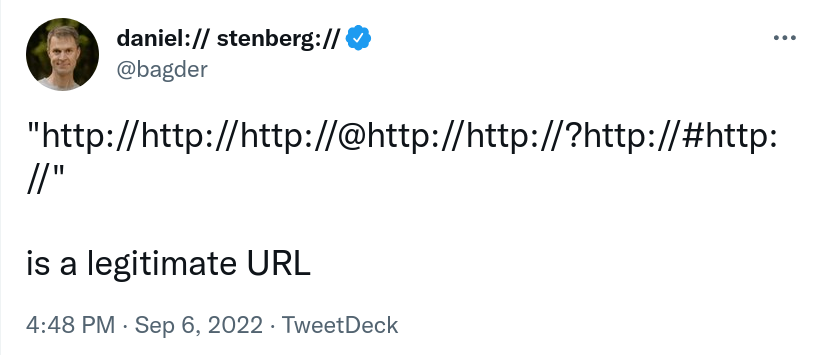
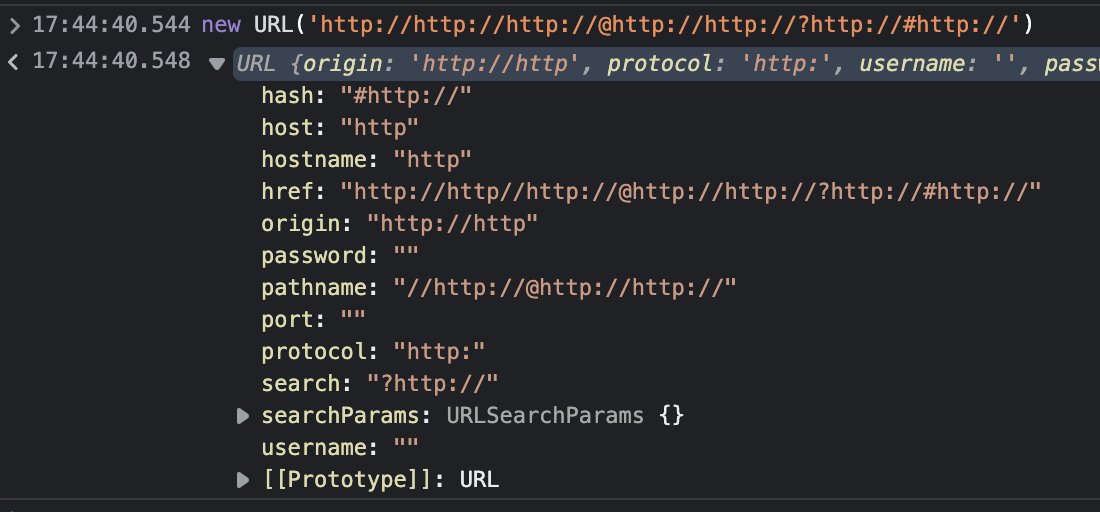
CVE-2022-42916: HSTS bypass via IDN
curl’s HSTS check could be bypassed to trick it to keep using HTTP.
Using its HSTS support, curl can be instructed to use HTTPS directly instead of using an insecure clear-text HTTP step even when HTTP is provided in the URL. This mechanism could be bypassed if the host name in the given URL uses IDN characters that get replaced to ASCII counterparts as part of the IDN conversion. Like using the character UTF-8 U+3002 (IDEOGRAPHIC FULL STOP) instead of the common ASCII full stop (U+002E) ..
Like this: http://curl?se?
Changes
This time around we add one and we remove one.
NPN support removed
curl no longer supports using NPN for negotiating HTTP/2. The standard way for doing this has been ALPN for a long time and the browsers removed their support for NPN several years ago.
WebSocket API
There is an experimental WebSocket API included in this release. It comes in the form of three new functions and a new setopt option to control behavior. The possibly best introduction to this new API is in everything curl.
I am very interested in feedback on the API.
Bugfixes
Here some of the fixed issues from this cycle that I think are especially worthy to highlight.
aws_sigv4 header computation
The sigv4 code got a significant overhaul and should now do much better than before. This is a fairly complicated setup and there are more improvements coming for future releases.
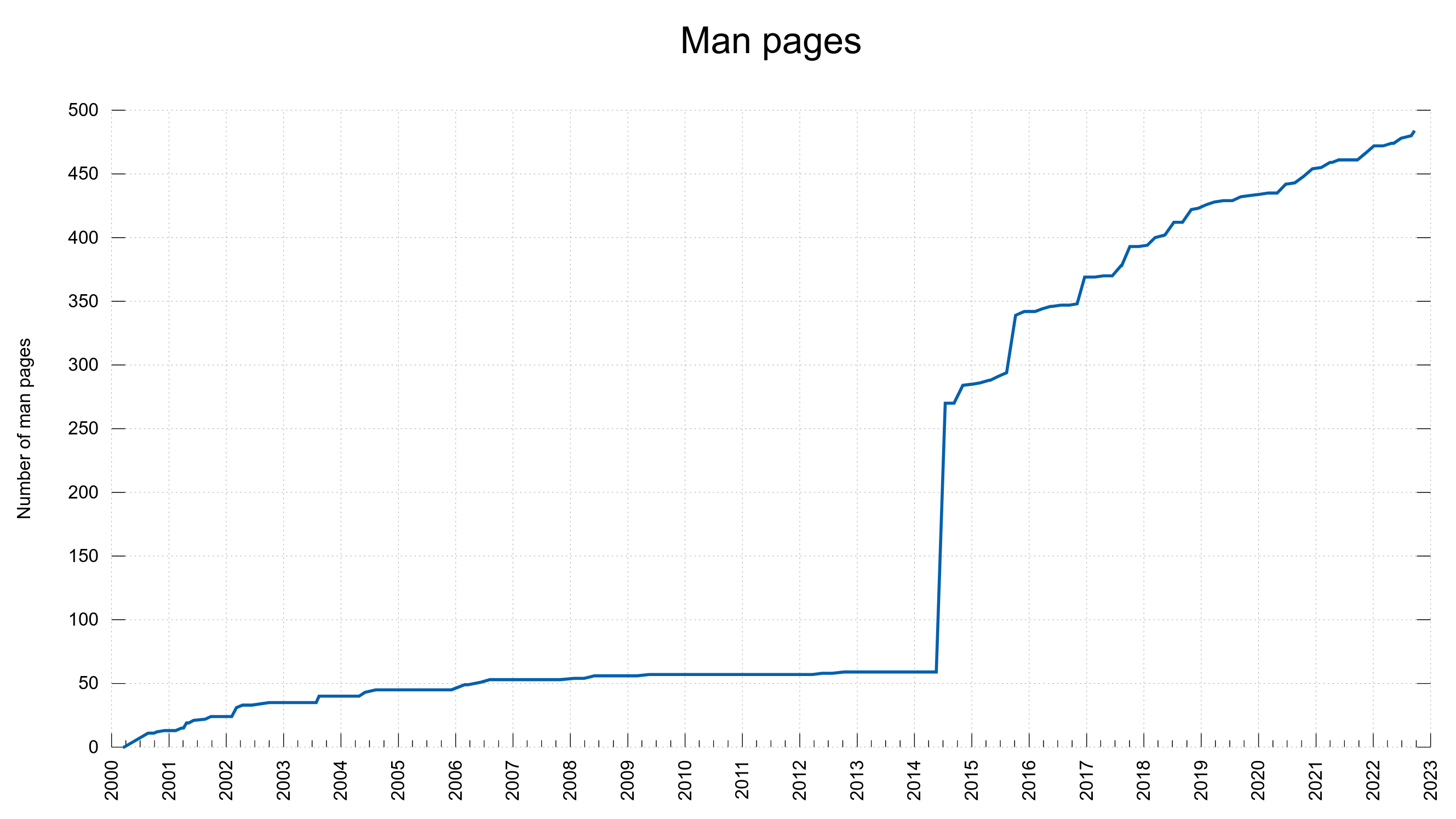
curl man page details multi-use for each option
Every command line option is documented in its own file, which is then used as input when the huge curl.1 man page is generated. Starting now, each such file needs to specify how the option functions when specified more than once. So from now on, this information is mentioned in the man page for all supported options.
deprecate builds with small curl_off_t
Starting in this release, we deprecate support for building curl for systems without 64 bit data types. Those systems are extremely rare this days and we believe it makes sense to finally simplify a few internals when it hurts virtually no one. This is still only deprecated so users can still build on such systems for a short while longer if they really want to.
the ngtcp2 configure option defaults to ‘no’
You need to explicitly ask for ngtcp2 to be enabled in the build.
reject cookie names or content with TAB characters
Cookies with tabs in names or content are not interoperable and they caused issues when curl saved them to disk, so we decided to rather reject them.
for builds with gcc + want warnings, set gnu89 standard
Just to make better sure we maintain compatibility.
use -O2 as default optimize for clang in configure
It was just a mistake that it did not already do this.
warn for –ssl use, considered insecure
To better highlight for users that this option merely suggests for curl that it should use TLS for the protocol, while --ssl-reqd is the one that requires TLS.
ctype functions converted to macros-only
We replaced the entire function family with macros.
100+ documentation spellfixes
After a massive effort and new CI jobs, we now regularly run a spellcheck on most man pages and as a result we fixed lots of typos and we should now be able to better maintain properly spelled documentation going forward.
make nghttp2 less picky about field whitespace in HTTP/2
If built with a new enough nghttp2 library, curl will now ask it to be less picky about trailing white space after header fields. The protocol spec says they should cause failure, but they are simply too prevalent in live servers responses for this to be a sensible behavior by curl.
use the URL-decoded user name for .netrc parsing
This regression made curl not URL decode the user name provided in a URL properly when it later used a .netrc file to find the corresponding password.
make certinfo available for QUIC
The CURLOPT_CERTINFO option now works for QUIC/HTTP/3 transfers as well.
make forced IPv4 transfers only use A queries
When asking curl to use IPv4-only for transfers, curl now only resolves IPv4 names. Out in the wide world there is a significant share of systems causing problems when asking for AAAA addresses so having this option to avoid them is needed.
schannel: when importing PFX, disable key persistence
Some operations when using the Schannel backend caused leftover files on disk afterward. It really makes you wonder who ever thought designing such a thing was a good idea, but now curl no longer triggers this effect.
add and use Curl_timestrcmp
curl now uses this new constant-time function when comparing secrets in the library in an attempt to make it even less likely for an outsider to be able to use timing as a feedback as to how closely a guessed user name or password match the secret ones.
curl: prevent over-queuing in parallel mode
The command line tool would too eagerly create and queue up pending transfers in parallel mode, making a command line with millions of transfers easily use ridiculous amounts of memory.
url parser: extract scheme better when not guessing
A URL has a scheme and we can use that fact to detect it better and more reliable when not using the scheme-guessing mode.
fix parsing URL without slash with CURLU_URLENCODE
When the URL encode option is set when parsing a URL, the parser would not always properly handle URLs with queries that also lacked a slash in the path. Like https://example.com?moo.
url parser: leaner with fewer allocs
The URL parser is now a few percent faster and makes significantly fewer memory allocations and it uses less memory in total.
url parser: reject more bad characters from the host name field
Another step on the journey of making the parser stricter.
wolfSSL: fix session management bug
The session-id cache handling could trigger a crash due to a missing reference counter.
Future
We have several pull-requests in the pipe that will add changes to trigger a minor number bump.
Removals
We are planning to remove the following features in a future-:
- support for systems without 64 bit data type
- support for the NSS TLS library
If you depend on one of those features, yell at us on the mailing list!