The HTTP Workshop is an occasional gathering of HTTP experts and other interested parties to discuss the Web’s foundational protocol.
The fifth HTTP Workshop is a three day event that takes place in Oxford, UK. I’m happy to say that I am attending this one as well, as I have all the previous occasions. This is now more than seven years since the first one.
Attendees
A lot of the people attending this year have attended previous workshops, but in a lot of cases we are now employed by other companies then when we attended our first workshops. Almost thirty HTTP stack implementers, experts and spec authors in a room.
There was a few newcomers and some regulars are absent (and missed). Unfortunately, we also maintain the lack of diversity from previous years. We are of course aware of this, but have still failed to improve things in this area very much.
Setup
All the people gather in the same room. A person talks briefly on a specific topic and then we have a free-form discussion about it. When I write this, the slides from today’s presentations have not yet been made available so I cannot link them here. I will add those later.
Lucas Pardue started the morning with a presentation and discussion around logging, tooling and the difficulty of debugging modern HTTP setups. With binary protocols doing streams and QUIC, qlog and qvis are in many ways the only available options but they are not supported by everything and there are gaps in what they offer. Room for improvements.
Anne van Kesteren showed a proposal from Domenic Denicola for a No-Vary-Search response header. An attempt to specify a way for HTTP servers to tell clients (and proxies) that parts of the query string produces the same response/resource and should be cached and treated as the same.
An issue that is more complicated than what if first might seem. The proposal has some fans in the room but I think the general consensus was that it is a bad name for the header…
HTTP versions. HTTP/3 is used in over a third of the requests both as seen by Cloudflare server-side and measured in Firefox telemetry client-side. Extensible and functional protocols. Nobody is talking about or seeing a point in discussing about a HTTP/4.
WebSocket over h2/h3. There does not seem to be any particular usage and nobody mentioned any strong reason or desired to change the status. Web Transport is probably what instead is going to be the future.
Frames. Discussions around the use and non-use of the origin frame. Note widely used. Could help to avoid extra “SNI leakage” and extra connections.
Anne then took a second round in front of the room and questioned us on the topic of cookies. Or perhaps more specifically about details in the spec and how to possible change the spec going forward. At least one person in the room insisted fairly strongly than any such restructures of said documents should be done after the ongoing 6265bis work is done.
Dinner
A company very generously sponsored a group dinner for us in the evening and I had a great time. I was asked to not reveal the name of said company, but I can tell you that a lot of the conversations at the table, at least in the area where I was parked, kept up the theme from the day and were HTTP oriented. Including oblivious HTTP, IPv4 formatting allowed in URLs and why IP addresses should not be put in the SNI field. Like any good conversion among friends.
When doing HTTP(S) transfers, libcurl might erroneously use the read callback (CURLOPT_READFUNCTION) to ask for data to send, even when the CURLOPT_POSTFIELDS option has been set, if the same handle previously was used to issue a PUT request which used that callback.
This flaw may surprise the application and cause it to misbehave and either send off the wrong data or use memory after free or similar in the subsequent POST request.
The problem exists in the logic for a reused handle when it is changed from a PUT to a POST.
curl can be told to parse a .netrc file for credentials. If that file ends in a line with consecutive non-white space letters and no newline, curl could read past the end of the stack-based buffer, and if the read works, write a zero byte possibly beyond its boundary.
This will in most cases cause a segfault or similar, but circumstances might also cause different outcomes.
If a malicious user can provide a custom .netrc file to an application or otherwise affect its contents, this flaw could be used as denial-of-service.
If curl is told to use an HTTP proxy for a transfer with a non-HTTP(S) URL, it sets up the connection to the remote server by issuing a CONNECT request to the proxy, and then tunnels the rest of protocol through.
An HTTP proxy might refuse this request (HTTP proxies often only allow outgoing connections to specific port numbers, like 443 for HTTPS) and instead return a non-200 response code to the client.
Due to flaws in the error/cleanup handling, this could trigger a double-free in curl if one of the following schemes were used in the URL for the transfer: dict, gopher, gophers, ldap, ldaps, rtmp, rtmps, telnet
curl’s HSTS check could be bypassed to trick it to keep using HTTP.
Using its HSTS support, curl can be instructed to use HTTPS directly instead of using an insecure clear-text HTTP step even when HTTP is provided in the URL. This mechanism could be bypassed if the host name in the given URL uses IDN characters that get replaced to ASCII counterparts as part of the IDN conversion. Like using the character UTF-8 U+3002 (IDEOGRAPHIC FULL STOP) instead of the common ASCII full stop (U+002E) ..
Like this: http://curl?se?
Changes
This time around we add one and we remove one.
NPN support removed
curl no longer supports using NPN for negotiating HTTP/2. The standard way for doing this has been ALPN for a long time and the browsers removed their support for NPN several years ago.
WebSocket API
There is an experimental WebSocket API included in this release. It comes in the form of three new functions and a new setopt option to control behavior. The possibly best introduction to this new API is in everything curl.
I am very interested in feedback on the API.
Bugfixes
Here some of the fixed issues from this cycle that I think are especially worthy to highlight.
aws_sigv4 header computation
The sigv4 code got a significant overhaul and should now do much better than before. This is a fairly complicated setup and there are more improvements coming for future releases.
curl man page details multi-use for each option
Every command line option is documented in its own file, which is then used as input when the huge curl.1 man page is generated. Starting now, each such file needs to specify how the option functions when specified more than once. So from now on, this information is mentioned in the man page for all supported options.
deprecate builds with small curl_off_t
Starting in this release, we deprecate support for building curl for systems without 64 bit data types. Those systems are extremely rare this days and we believe it makes sense to finally simplify a few internals when it hurts virtually no one. This is still only deprecated so users can still build on such systems for a short while longer if they really want to.
the ngtcp2 configure option defaults to ‘no’
You need to explicitly ask for ngtcp2 to be enabled in the build.
reject cookie names or content with TAB characters
Cookies with tabs in names or content are not interoperable and they caused issues when curl saved them to disk, so we decided to rather reject them.
for builds with gcc + want warnings, set gnu89 standard
Just to make better sure we maintain compatibility.
use -O2 as default optimize for clang in configure
It was just a mistake that it did not already do this.
warn for –ssl use, considered insecure
To better highlight for users that this option merely suggests for curl that it should use TLS for the protocol, while --ssl-reqd is the one that requires TLS.
ctype functions converted to macros-only
We replaced the entire function family with macros.
100+ documentation spellfixes
After a massive effort and new CI jobs, we now regularly run a spellcheck on most man pages and as a result we fixed lots of typos and we should now be able to better maintain properly spelled documentation going forward.
make nghttp2 less picky about field whitespace in HTTP/2
If built with a new enough nghttp2 library, curl will now ask it to be less picky about trailing white space after header fields. The protocol spec says they should cause failure, but they are simply too prevalent in live servers responses for this to be a sensible behavior by curl.
use the URL-decoded user name for .netrc parsing
This regression made curl not URL decode the user name provided in a URL properly when it later used a .netrc file to find the corresponding password.
make certinfo available for QUIC
The CURLOPT_CERTINFO option now works for QUIC/HTTP/3 transfers as well.
make forced IPv4 transfers only use A queries
When asking curl to use IPv4-only for transfers, curl now only resolves IPv4 names. Out in the wide world there is a significant share of systems causing problems when asking for AAAA addresses so having this option to avoid them is needed.
schannel: when importing PFX, disable key persistence
Some operations when using the Schannel backend caused leftover files on disk afterward. It really makes you wonder who ever thought designing such a thing was a good idea, but now curl no longer triggers this effect.
add and use Curl_timestrcmp
curl now uses this new constant-time function when comparing secrets in the library in an attempt to make it even less likely for an outsider to be able to use timing as a feedback as to how closely a guessed user name or password match the secret ones.
curl: prevent over-queuing in parallel mode
The command line tool would too eagerly create and queue up pending transfers in parallel mode, making a command line with millions of transfers easily use ridiculous amounts of memory.
url parser: extract scheme better when not guessing
A URL has a scheme and we can use that fact to detect it better and more reliable when not using the scheme-guessing mode.
fix parsing URL without slash with CURLU_URLENCODE
When the URL encode option is set when parsing a URL, the parser would not always properly handle URLs with queries that also lacked a slash in the path. Like https://example.com?moo.
url parser: leaner with fewer allocs
The URL parser is now a few percent faster and makes significantly fewer memory allocations and it uses less memory in total.
url parser: reject more bad characters from the host name field
Another step on the journey of making the parser stricter.
wolfSSL: fix session management bug
The session-id cache handling could trigger a crash due to a missing reference counter.
Future
We have several pull-requests in the pipe that will add changes to trigger a minor number bump.
Removals
We are planning to remove the following features in a future-:
support for systems without 64 bit data type
support for the NSS TLS library
If you depend on one of those features, yell at us on the mailing list!
I am happy to announce that curl receives funding from The Sovereign Tech Fund. This funding is directed towards three specific projects that we have identified as interesting and worthwhile to push forward as ways to improve curl and the life of curl users.
This “investment” will fund two developers to work on curl over a period of six months: Stefan Eissing and myself. The three projects are explained at some detail below. Of course everyone and anyone is welcome to join in and help out with these projects. Everything will be done in the open, as usual.
At the end of the period, we will produce some kind of report or summary of how things turned out.
The three projects we are getting funded have been especially created and crafted (by me) to be good solid projects that we really want to see done. This funding is different than many others we have gotten over the years in that we got to decide and plan what we wanted done. These are things that are meant to improve curl as a project and to generally make Internet transfers better and more powerful for a vast amount of users.
Project 1 – known bugs cleanup
The curl project currently lists 120+ items as known bugs (up from 77 just two years ago).
The items in that list are reported problems that were recognized as problems at the time of their submission but as nobody worked on the issues at the time they were added to this list. The list includes everything from smaller irks up to big things that will either take a long time to fix or be (almost) impossible to address.
There is a good chance that the list will be extended during the project period just because some new bugs fall into the description mentioned above.
This project is an effort to go through as many as possible to make sure they are correctly categorized/described and work on fixing the issues or whatever is necessary to get them off the list.
The process would entail an initial proper research round to extend the description and increase the understanding of each entry, followed by a rough assessment of the amount of work it would take to fix them. Possibly with a 1 (easy) to 5 (extreme) scale.
The action would then be to address the issues, possibly in an easy to hard order. Addressing the issues could be to fix the code to remove the issue, dismiss it as not actually intended to work or document it as not working or even moving it over to the TODO document if it is more of a good idea for the future.
The goal being to reduce the list to zero entries and thus polish off numerous rough corners and annoyances in the project.
This will be done by Daniel Stenberg over a period of 6 months.
Project 2 – HTTP/3
Make HTTP/3 release-ready.
curl features experimental HTTP/3 and QUIC support already since a few years back, but there are several details still lacking:
known bugs
proper multiplexing: doing multiple transfers to the same host should be able to reuse an existing connection and multiplex over that, just as curl already does when using HTTP/2
HTTP/3 support for the test suite (and CI jobs) need to be done for us to be able to consider the support release ready. Cooperation can be had with QUIC libraries such as ngtcp2 to consider where/how some of the testing is best performed.
considerations for 0-RTT connection establishments (if anything needs to be done)
support for early data: to send off the HTTP request to the server faster.
connection migration:, a QUIC feature that allows a server to move over a live connection from one server to another without disruption
fallback to h1/h2 if the QUIC connection fails. The failure rate for QUIC connections are still in the 3-7% rate generally, so having a good fallback mechanism or documented for how applications can go back to an older HTTP version instead, is important.
HTTPS RR. This fairly new DNS resource record might contain information about the target server’s support for HTTP/3. If such a record is provided, curl can avoid superfluous round-trips to get the Alt-Svc header and rather connect directly to the HTTP/3 server.
All features and changes need to be documented. Functionality needs to be verified by test cases. Interop with real world servers is of course implied and assumed.
Stefan Eissing will spend 4 months on this project.
Project 3 – HTTP/2 over proxy
curl has provided support for doing network transfers via HTTP proxies since decades, and this is a very commonly used feature and network setup.
curl however only supports using HTTP version 1 over proxies. This makes applications less effective as it sometimes leads to many more TCP connections being used than otherwise would be necessary if HTTP/2 could be used. In particular when applications behind a proxy operate against many different hosts on the other side of the proxy.
It can also be noted that in many enterprise setups, this kind of HTTP proxy is used for all kinds of network operations through the use of the CONNECT method, so this functionality is not limited to plain HTTP(S), it should work for all TCP based protocols libcurl supports and which already work over HTTP/1 proxies.
The project will require adding new options to enable this functionality, to both the library and the command line tool. With associated documentation.
It will require creating or extending the HTTP/2 support in the curl test suite so that this new functionality can be verified and proven to work at a satisfactory level.
Considerations must be taken so that this work does not close the door for future extending this to support HTTP/3 over proxy. Time permitting, work should be taken to pave the road for that or even perhaps gently start the work to support that as well.
Stefan Eissing will spend 2 months on this project.
The outcome(s)
I hope and presume that the results of these projects will appear as a stream of pull-requests for curl that will be done and managed through-out the project period and not saved up to the end or anything. The review, test and merge process of these pull requests will follow our normal and standard project guidelines and procedures.
The projects are fully packed and (over) ambitious. There is a high risk that we will not be able to complete all the details for these projects within the time frame. But we will try.
tldr: we do not particular keep track nor document curl’s exact spec compliance. I cannot fathom how we could.
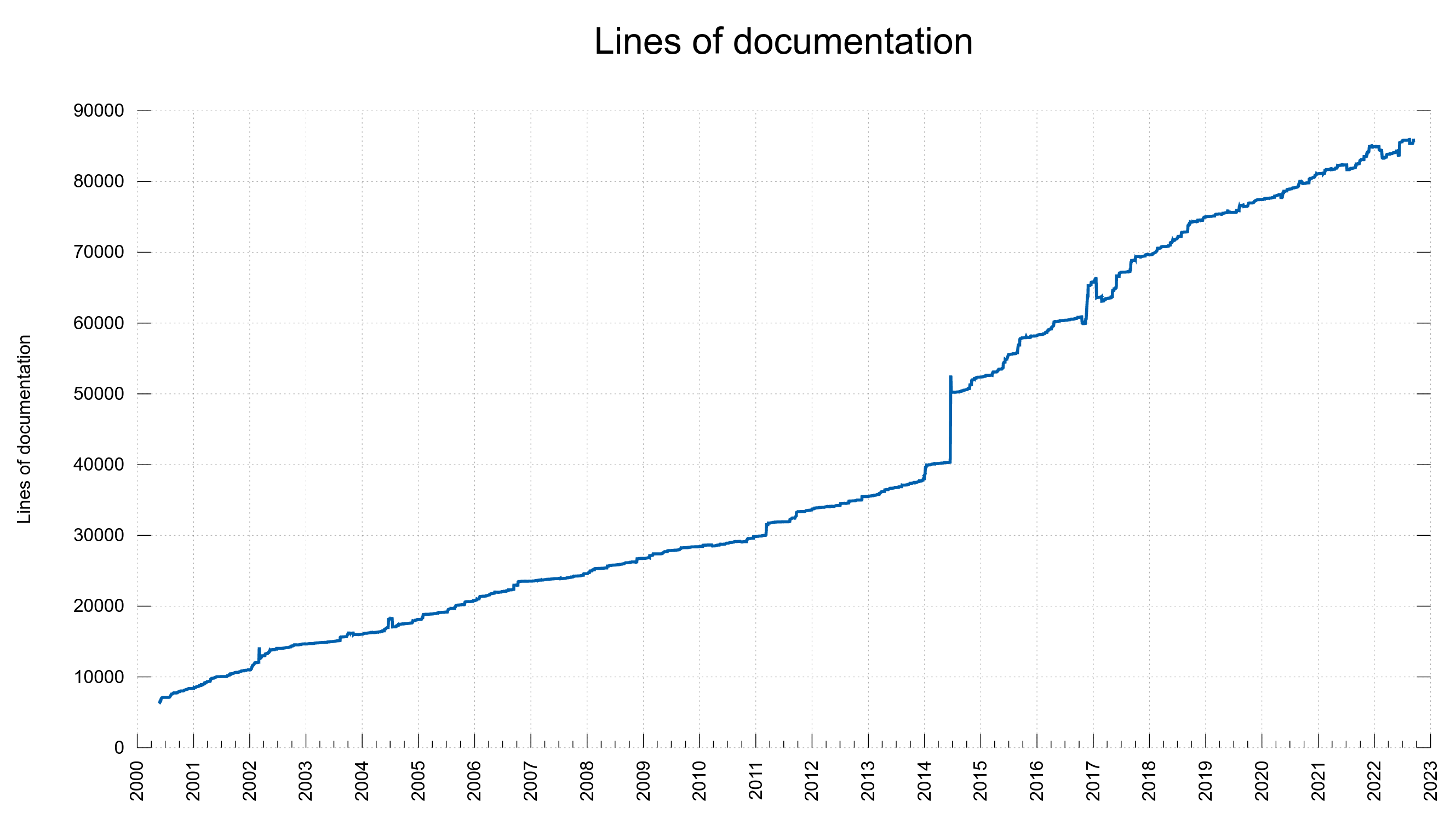
Today, in October 2022, curl and libcurl combined consist of nearly 150,000 lines of source code (not counting blank lines). 19% of those are comments.
This source code pile was carefully crafted with the sole purpose of performing Internet transfers using one or more of the 28 separate supported protocols. (There are 28 different supported URL schemes, it can be discussed if they are also 28 protocols or not.)
Which specs does curl use
It was recently proposed to me that we should document which RFCs curl adheres to and follows, and what deviants there are. In the name of helping the users understand what to expect from curl and educating the world how curl will behave.
This is indeed a noble idea and a worthy goal. We do not want to surprise users. We want them to know.
It was suggested that it might have a security impact if curl would deviate from a spec and if this is not documented clearly, users could be mislead.
What specs
curl speaks TCP/IP (and UDP or QUIC at times), it does DNS and DNS-over-HTTPS, it speaks over proxies and it speaks a range of various application protocols to perform what asked of it. There are literally hundreds of RFCs to read to catch up on all the details.
A while ago I collected the what I consider most important RFCs to read to figure out how curl works and why. That is right now 149 specification documents at a total of over 300,000 lines of text. (It was not done very scientifically.)
Counting the words in these 149 documents, they add up to a total of many more words than the entire Harry Potter series, and the Lord of the Rings series (including the Hobbit) is far behind together with War and Peace: 1.6 megawords.
Luckily, specs are mostly reference literature and we rarely have to read through them all to start our journey, but we often need to go back to check details.
Everything changes over time
The origins of curl trace back to late 1996 and it has been in constant development since then. curl, the Internet and the specifications have all changed significantly over these years.
The specifications that were around when we started have generally been updated multiple times, while we struggle to maintain behavior and functionality for our users. It is hard to spot and react to minor changes in specification updates. They might have been done to clarify a situation, but sometimes such a clarification ends up triggering a functionality change in our code.
Sometimes an update to a spec is even largely ignored by fellow protocol implementers out there in the world, and for the sake of interoperability we too then need to adjust our interpretations so that we work similarly to our peers.
Expectations from users change as values and terms are established in people’s minds rather than in specs. For example: what exactly is the “URL” you see in the browser’s top bar?
Over time, other tools and programs that also work on URLs and on the Internet, gradually change as they too development and slowly morph into the new beings we did not foresee decades ago. This change perceptions and expectations in the user base at large.
The always changing nature of the Internet creates interoperability challenges ever so often: out of the blue a team of protocol implementers can decide to interpret an existing term or a passage in a specification differently one day. When the whole world takes a turn like that, we are sometimes forced to follow along as that is then the new world view.
Another complication is also that curl uses (several) third party libraries for parts of its operations, and some of those details are of course also covered by RFCs.
Guidelines
Our primary guidelines when performing Internet transfers are:
Follow established standard protocol specifications
Security is a first-tier property
Interop widely
Maintain behavior for existing features
As you can figure out for yourself, these four bullet points often collide with each other. Checking off all four is not always possible. They can be hard enough on their own.
Protocol specifications
There are conflicting specifications. Specifications vary over time. They can be hard to interpret to figure out exactly what they say one should do.
Security
Increasing security might at the same time break existing use cases for existing users. It might violate what the specs say. It might add friction in the ability to interoperate with others. It might not even be allowed according to specifications.
Interop
This often mean to not follow specifications they way we want to read them, because apparently others do not read them the same way or sometimes they just disregard what the specs say. At times, it is hard to increase security levels by default because it would hamper interop with others.
Maintain behavior
The scripts written 15 years ago that use curl should continue working. The applications written to use libcurl can upgrade libcurl and its Internet transfers just continue. We do not break existing established behaviors. This may very well conflict both with interop and protocol updates, and sometimes it is hard to tighten the security because it would hurt a certain share of existing users.
How does curl deviate from which specs?
I consider this question more or less impossible to answer to, to document and to keep accurate over time. At least it would be a huge and energy-consuming effort both to get the list done but it would also be a monster task to maintain. And it would involve a lot of gray zones.
What is important to me is not what RFCs curl follows nor what or how it deviates from them. I have also basically never gotten that question from a user.
Users want reliable Internet transfers that are secure and interoperate correctly and conveniently with other “players” out there. They want consistent behavior and backwards compatibility.
If you use curl to perform feature X over protocol Y version Z, does it matter which set of RFCs that this would touch and does anyone care about the struggles we have been through when we implemented this set? How many users can even grasp or follow the implication of mentioning that for RFC XYX section A.B we decided to disregard a SHOULD NOT at times?
And how on earth would we keep that up-to-date when we do bugfixes and RFCs are updated down the line?
No one else documents this
The browsers have several hundreds of paid engineers on staff involved and they do not provide documentation like this. Neither does any curl alternative or competitor to my knowledge.
I don’t know of any tool or software anywhere that offer such a deviance documentation and I can perfectly understand and sympathize with why that is so.
An HTTP cookie, is just a name + value pair sent from the server to the client. That pair is stored and is sent back to the server in subsequent requests when conditions match.
Cookies were first invented and used in the 1990s. Sources seem to agree that the first browser to support them, was Netscape 0.9beta released in September 1994. Internet Explorer added support in October 1995.
After many years and several failed specification attempts, they were eventually documented in RFC 6265 in 2011. They have been debated, criticized and misunderstood since virtually forever. Mostly because of the abuse/tracking they (used to?) allow in browsers. Less so because of how they actually work over the wire.
curl
curl has supported cookies since the 1990s as well (October 1998 to be specific), and it is a frequently used feature among curl users everywhere. Not the least because the login pattern of the web has become HTTP POST with credentials with a session cookie returned on success – and curl is often used to mimic or reproduce such operations to allow for automated processes and more.
For curl, it is important to remain interoperable and compatible with cookies the same way browsers do them so that users can keep doing these things.
What to accept
Not very long ago, I blogged about a cookie change we had to do because curl’s former liberal attitude towards what a cookie might contain turned out to be a possible vector for mischief. That flaw was basically a direct result of curl never totally adapting to the language in RFC 6265 because we typically do not change what seems to work and has not been reported to be wrong.
In that curl change, we started rejecting incoming cookies that contain “control codes” but we let ASCII code 9 through. ASCII code 9 is the tab character. Generally considered white space. We let it through because we checked the source code for two major browsers and they since they do, curl does as well.
Tab where?
But accepting tabs in the cookie line is one thing. The next question then comes where exactly in the cookie line should it be acceptable?
In the currently ongoing security audit for curl, our friends at Trail of Bits figured out that if a cookie is sent to curl with a tab in the name (literally inside the name and not before or after, like foo<tab>bar) curl would save that wrongly if saved to a file. This, because curl saves cookies in a tab-separated file format, the so called Netscape cookie file format, and it has no escape mechanism or anything. A tab in the cookie name causes the cookie to later get treated wrongly when the file is later loaded again.
Interop status
The file format curl uses for saving cookies is the same as the original format Netscape and then early Firefox used back in the old days. Since this format does not support tabs, I believe it is reasonable to assume the early browsers did not accept tabs in names or content.
I checked how (current) Chrome and Firefox handle cookies like this by creating a test page that sends cookies to the browser.
Chrome rejects cookies with tabs in name or content. They are simply not accepted or stored.
Firefox rejects cookies with tabs in name, but strangely enough it strips tabs from the content and otherwise let them through.
(Safari doesn’t work on Linux so I ignored that)
This, even if my reading of the RFC 6265 seems to say that they should be fine. They should be kept when “internal” to a name or content. I believe curl followed the spec here better than the browsers.
But clearly tabs in cookie names or content is not an interoperable concept on the web.
I figured that this non-interoperable state and support situation could be worth highlighting or perhaps make a bit stricter in the spec update.
In that issue on GitHub, I was instead informed that recently changed language in their RFC draft rather made browser implementers keen on adding support for this kind of tabs in cookies.
Instead of admitting defeat and documenting that tabs in cookie names and values do not work correctly, we would rather continue limping along pretending this will work.
The HTTP community have supported cookies for almost thirty years without tabs working correctly inside cookies.
Adding (clearer) support for them in a spec would be good in the sense that more defined behavior is a good thing, but since we have decades of this non or perhaps spotty support the already deployed software and long tail of clients will not adapt to any such new wording rapidly. Even if accepted in the new spec, it will take ages until cookies could be done interoperable with tabs inside.
I believe we are better off just documenting that tabs SHOULD NOT be used in cookie name or content as they will not interop. Because that is the truth and will be for a long time no matter what we do today or tomorrow.
My comments in that issue at least seem to have brought reason for maybe reconsider the draft wording. Maybe.
Why!
Someone might ask the excellent question “why would anyone want to use a tab in the name or content?”, but quite frankly, I cannot think of any good or legitimate reason other than maybe laziness or a lack of proper filtering.
There is no sound technical reason why this needs to be done.
We needed to do something. I believe going with the more strict approach is the better one here and now.
If the rfc6265bis draft ends up ultimately keeping the language “encouraging” tab support and browser authors decide to follow, then I presume we will have reason to revisit this decision later on and perhaps take curl in the other direction instead. I think we can handle that, even if I believe it would be the wrong thing for the ecosystem.
Already when the first version of curl shipped in 1998, I had plans and ideas in the back of my head to turn it to a library at some point. I had already before worked on providing libraries with APIs for applications and I appreciated their powers.
During the summer of 2000 I refactored the curl internals so that it would become a library with an exposed API that we could provide to the world and then let applications get the same file transfer capabilities that the curl command line tool has.
libwww
I was not aware of any existing library alternative that provided a plain transfer-oriented functionality. There was libwww, but that seemed to have a rather different focus and other users in mind. I wanted something simpler.
ioctl
I found the inspiration for the libcurl *setopt() concept in how ioctl() and fcntl() work. They set options for generic file descriptors. A primary idea would be to not have to add new function calls or change the API when we invent new options that can be set.
easy
As I designed the first functions for libcurl, I anticipated that we perhaps would want to add a more advanced API at a later point. The first take would make a straight forward way to synchronous internet transfers. As this was the initial basic API I decided to call it the “easy” interface. Several of the functions in libcurl are hence prefixed with “curl_easy”.
curl_easy_setopt() became the foundational function in the libcurl API. The one that sets “options” for a libcurl easy handle.:
We called the first libcurl version 7.1 in August 2000. I decided to skip 7.0 completely just to avoid confusions as I had shipped a series of pre-releases using that version number.
libcurl version 7.1 supported 59 different options for curl_easy_setopt. They were basically all the command line options existing at the time converted to API mechanisms, and then the command line options were mapped to those options. In many ways that mapping has continued since then, as the command line tool remains to a large extent a wrapper to allow the command line tool to set and use the necessary libcurl options.
Growth
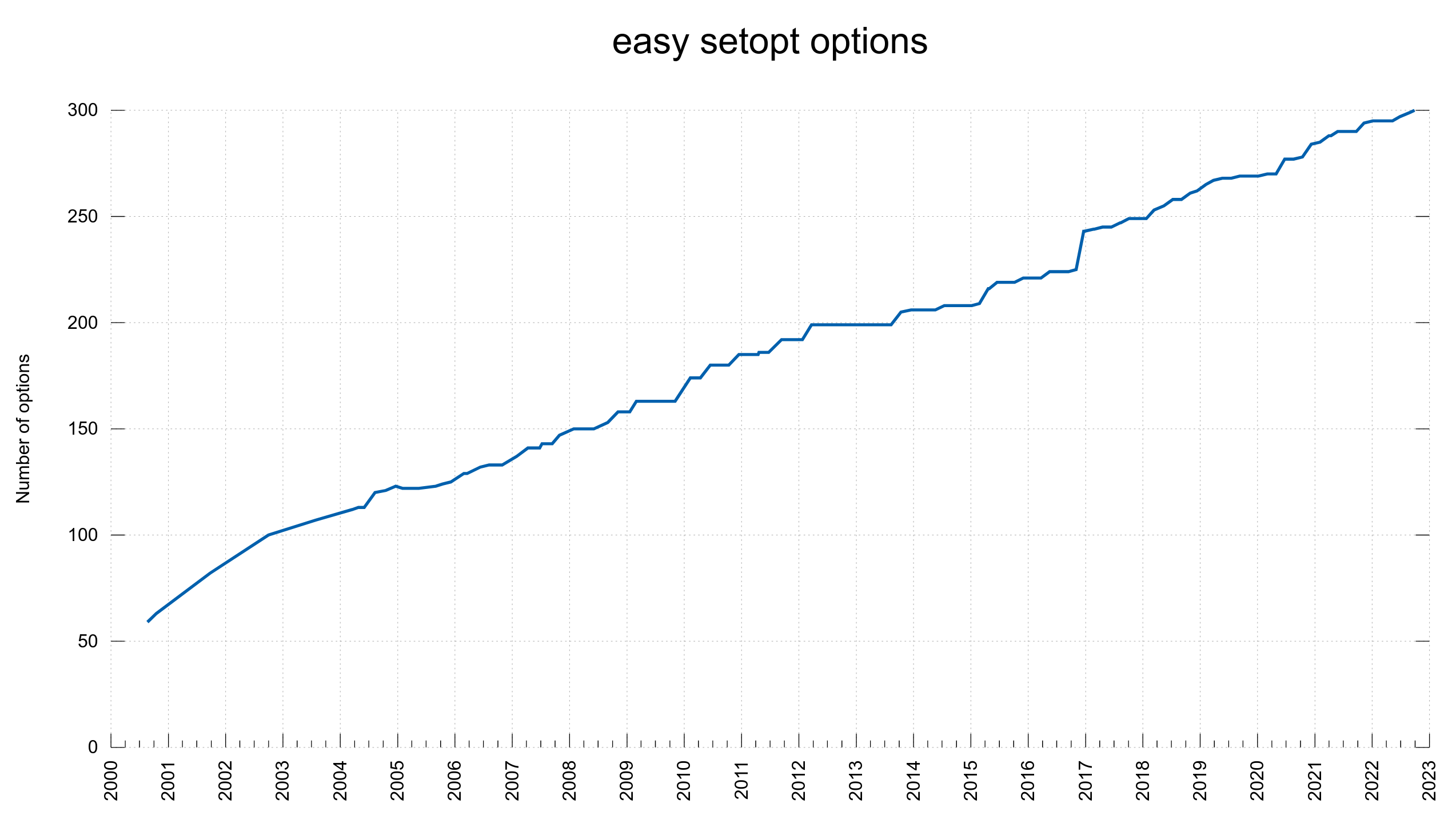
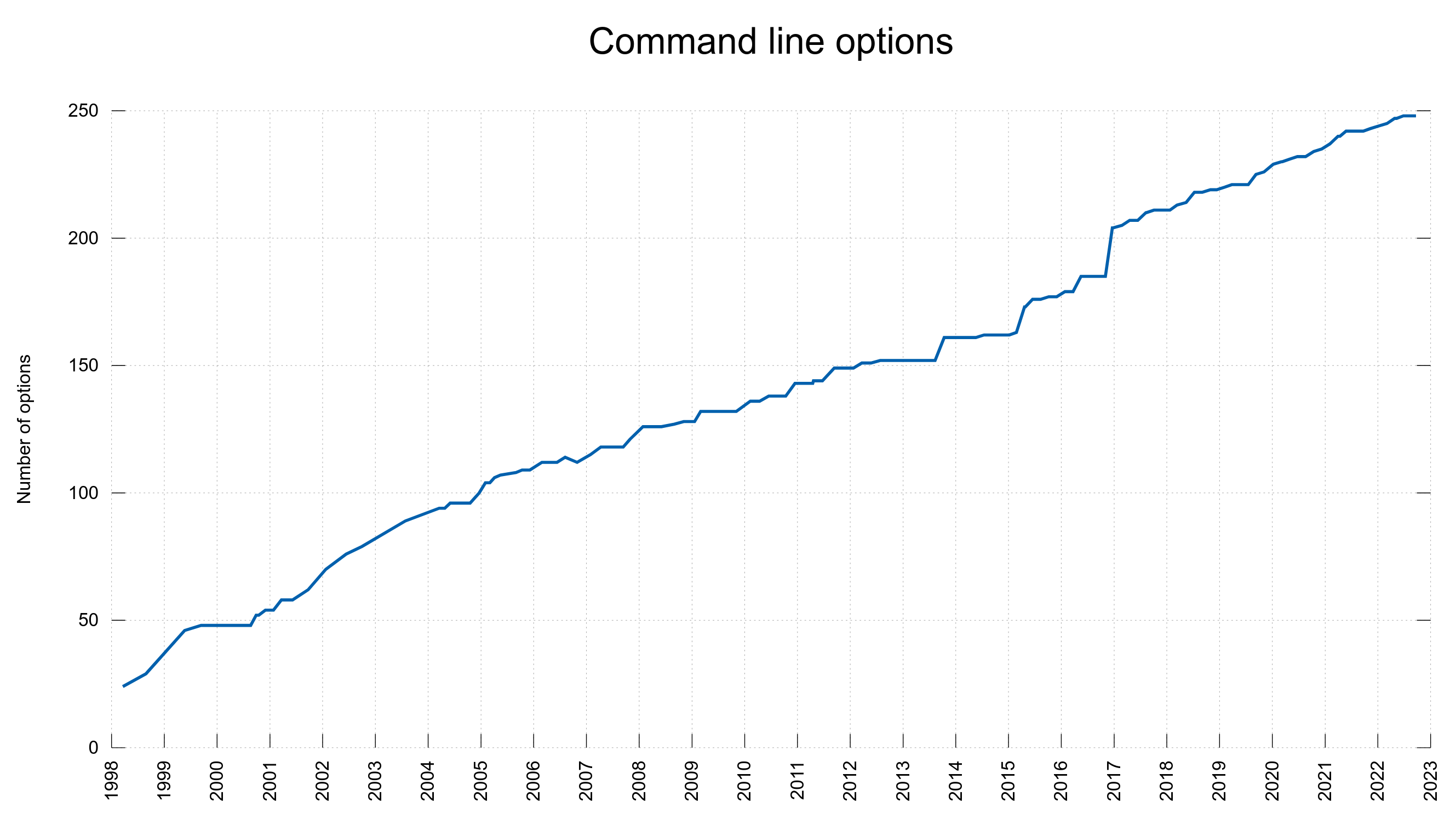
It took four years to double the amount of options and ten years alter the official count was at 180.
Today, in September 2022, we recently merged code that made the setopt counter reach 300 and this is the number of options that will ship in the pending 7.86.0 release. After 22 years we’ve added 241 new options, almost 11 new options per year on average.
Every new option comes with a cost: more code, more tests, more documentation and an even larger forest in which users can get lost when they try to figure out how to tell libcurl to behave the way the want it. The benefit of course being that libcurl gets one more capability and new chances to fulfill users’ wishes. New options certainly are both a blessing and a curse.
Deprecating
We have decided to never break existing behaviors, which means that we don’t remove old options – ever – but we may deprecate them. This also contributes to the large amount, as for many new options we add, we have documented that an older one should not be used but it still exists for backwards compatibility.
Downsides
A benefit with using this API concept is that we can easily add new options without introducing new function calls.
A downside with using this API concept is that I made the function curl_easy_setopt accept a “vararg”, meaning that the third argument passed to this function can be any type, and what type that is supposed to be used is dictated by the particular option that is used as the second argument.
While varargs is a cool C feature, it is bad in the sense that it takes away the compiler’s ability to check the argument at compile-time and instead makes it error-prone for users and forces libcurl to try to work around this limitation. If I would redo the API today, I would probably not do it exactly like this, as too many users shoot themselves in the foot with this.
Future
Predicting what comes next is impossible, but if I were to guess I would say that we are likely to keep on adding options even in the future.
Looking back, we can see a fairly steady growth and I cannot see any recent developments in the project or in the surrounding ecosystems that would make us deviate from this path in the short term future at least.
Tldr; test and verify as much as possible also in the documentation.
I’m a sloppy typist. When I write several words in a row, like for example when creating complete sentences for something like a blog post, one or two of the words end up slightly misspelled.
Sure, many editors and systems have runtime spellchecks these days and they make it easy to quickly fix typos, but not all systems are like that and there are also situations where there are many false positives due to formatting or just the range of “special” words. They also rarely yell at me when I overuse the word “very” or start sentences with “But”.
curl documentation
I work fiercely on making the curl and libcurl documentation top-notch state of the art good and complete. I want my users to feel that. Everything is documented; clearly and with details and examples.
I want and aim for libcurl to be the best documented software library in the world.
Good documentation does not come for free or easily. It requires dedicated work and a lot of effort put into it.
This is of course a never-ending effort as things change over time and we have an almost ridiculous amount of options and details to document.
The key to improve ourselves is of course two good old classics: tests and CI jobs. This works great even for documentation, and perhaps in particular for technical documentation that includes lots of symbols and name references that need to be correct.
As I have recently worked on tightening some bolts and made it harder to land typos, I wanted to take the opportunity to describe some of our ways.
symbols-in-versions
Early 2009 I had some interactions with people in the git project and we discussed their use of libcurl. As we introduce new features to curl over time, users who build with curl may want to write their code to conditionally use the new stuff if they have a new enough libcurl installed, or just skip those features if the installation is too old. git is an application like that. They use libcurl a lot and they offer to build with libcurl installations that are maybe a dozen years old.
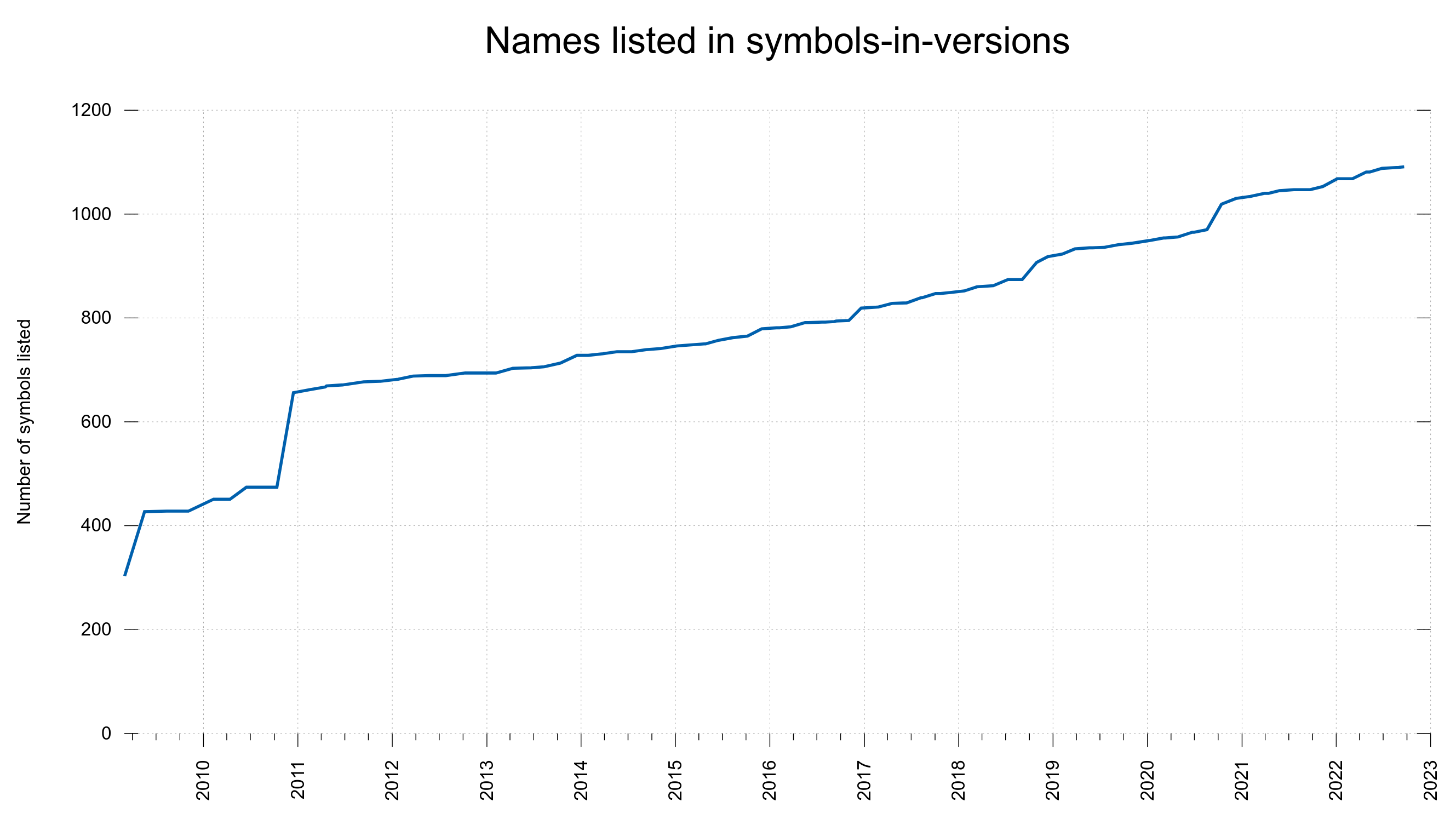
I then created a file in the libcurl git repository that I named symbols-in-versions. It lists all publicly provided curl symbols and in which libcurl release they were introduced. A good resource for libcurl users. It took quite an effort to figure them all out after the fact.
Over time, the number of entries in this file has grown significantly.
Tests
Of course, in order to do good CI jobs, they need to have tests to run so we start there.
I will mention some test numbers below. The test numbers in curl do not have any inherent meaning, they are just unique identifiers. To help us find the test source files and refer to tests and their failures easily.
Test 1119
Test 1119 was introduced in November 2010 as I realized I needed to make sure that symbols-in-versions (SIV) is kept up-to-date. It will be a useless document if it lags behind or misses symbols. It needs to include them all and the info needs to be correct.
I wrote a script that extracts all globally provided symbols in some curl header files and then verifies that they are all listed in SIV.
This test now made it very clear when we forgot to add a name to SIV, and it also pointed out if one of the names in SIV for example had a typo.
Test 1139
Scan SIV, figure out all existing options provided for three key libcurl functions: curl_easy_setopt, curl_multi_setopt and curl_easy_getinfo. Then verify that they all are mentioned in the respective “main” man page (curl_easy_setopt.3 etc), where they refer to the individual separate page for the option.
This test also verifies that the curl tool’s man page (curl.1) lists exactly the same set of command line options as is listed in the tool’s source code file tool_getparam.c and that is shown in the tool’s --help output. Consistency is king.
Test 1167
To make sure the symbols we provide in libcurl header files all use the correct name space we created test 1167. Using the correct name space in this context means that all publicly provided symbols need to start with curl of libcurl, case insensitively. It is important for several reasons, first of course because a good library does not pollute the name space to risk collisions and problems, but also using the correct prefix is important so that test 1119 finds all the symbols correctly. So they need to use the right prefix, and when they do, they are scanned and verified correctly.
Test 1173
For libcurl we have several function calls that take options. In some cases these functions accept a very large amount of different options. Every such option is documented in its own dedicated man page. Over time, with lots of contributors working on the project, the different man pages were not all including the same information in the same order and a huge portion of them even missed one of the most important details in programming documentation: examples.
Test 1173 checks all libcurl man pages and verifies that they have the eight mandatory libcurl sections present (NAME, SYNOPSIS, DESCRIPTION etc) and that they all are in the right order and that there is an example section that is more than 2 lines.
This test also does basic nroff formatting verification so that we know the page will look decent in a man page viewer too.
Helps us greatly – especially when we add new man pages.
Proselint
The tool that taught me to stop using the word “very” also finds a lot of other common bad takes on English is called proselint. Since a while back we run a CI job that runs proselint on all markdown files in the curl git repository. It helps us detect and edit away some amount of bad language.
Spellcheck
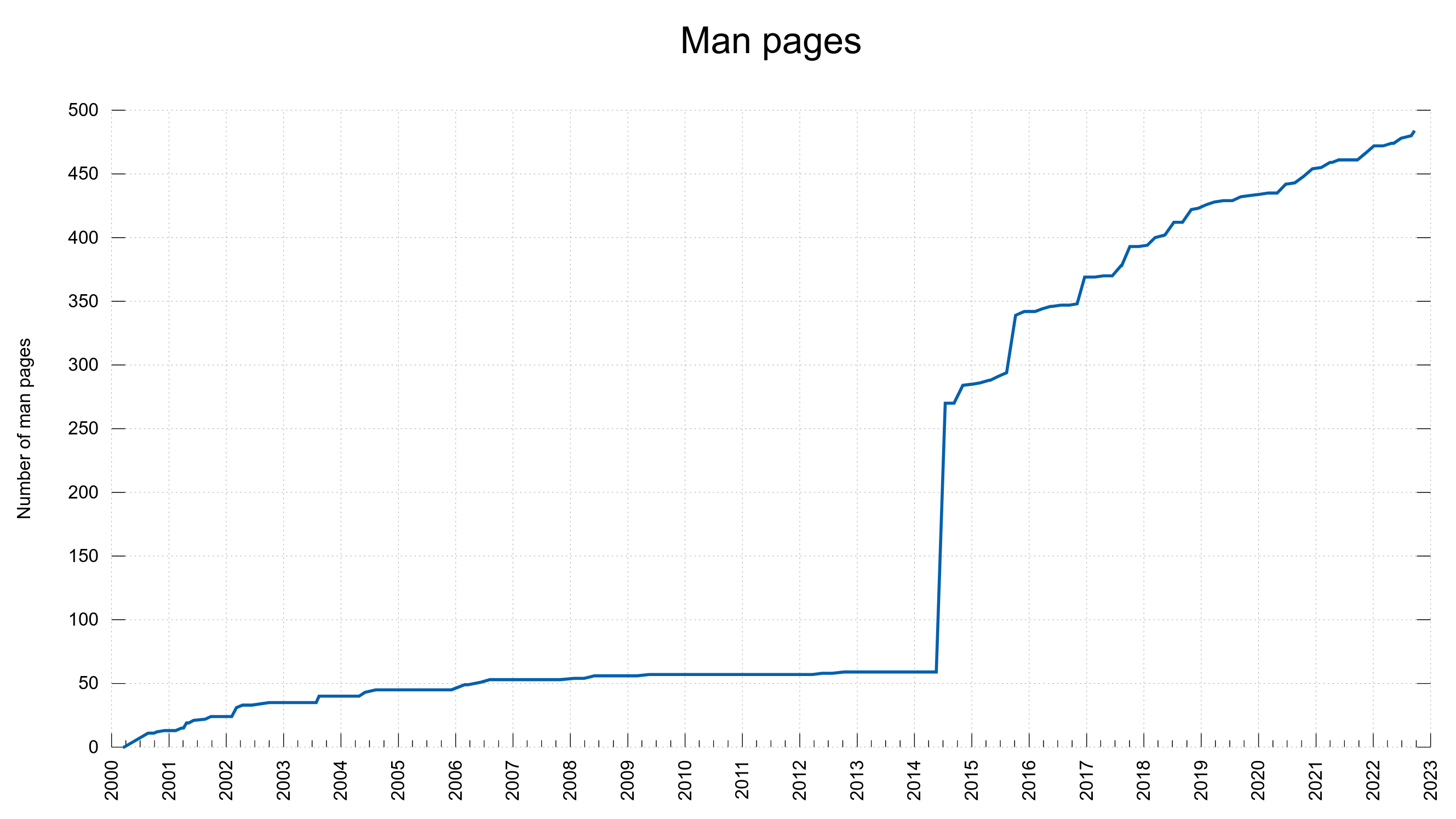
At the time of this writing, there are 482 individual libcurl related man pages and there is a total of around 85,000 lines of documentation in the project. I decided we should run a spellcheck on these man pages in an attempt to reduce the number of typos and mistakes.
The CI job I created for this first strips out some sections from the man pages that we deem too hard to spellcheck: the SYNOPSIS and the EXAMPLES sections for example. The script also removes all names that look like public curl symbols, as spellchecking them with a normal spellchecker is just impossible and they need special treatment. See further below for that.
Finally, we convert the stripped man page versions into markdown – because we have no spellchecker tools for nroff – and then spellcheck those.
It took far many more hours than I had anticipated to eradicate all the spelling mistakes and we ended up with an custom dictionary with over 800 words that aspell does not like but that I insist are valid for us.
Verify curl symbols
As I mentioned above, we strip out the curl symbols to hide them from the spellchecker.
Instead I extended the test 1119 mentioned above to also scan through all the libcurl man pages and find every single mention of something that looks like the name of a public curl symbol – and then match those against the names present in SIV and output an error if a symbol was referenced that was not documented already and therefore not actually a public curl symbol. With this, no man page can reference a non-existing curl symbol. Every such typo is detected.
Links for reporting on docs bugs
No matter how hard we try, there will always be errors that sneak in anyway and there will be sentences and phrasing that might have felt good at the time of writing but later, in the view of someone else, do not communicate the right message or maybe mislead users to misunderstand functionality.
Bug reports on documentation is key to finding such warts so that we can correct them. In the curl project we make it as easy as possible to report bugs in documentation by providing direct links on virtually all man pages shown on the website. The link takes you directly to the “new issue” page with a template subject filled in with the man page’s name.
This convenience unfortunately leads to a certain amount of “issue spam” but I think that is still a fairly cheap price to pay.
Everything curl
The book is a treasure trove of additional and complementary curl documentation but it is actually written and maintained outside of the curl repository. It has its own set of CI tests, including proselint and spellchecks.
Further
All these tests have been added gradually and slowly over a long period. It gives us time to polish and work out possible flaws in the tests and lets us make sure the work as intended and don’t block development.
I don’t have any immediate pending new pull requests for checking the curl documentation but if there still are details in there that we can check that we currently do not, I am sure that we will find those over time and make sure we verify them too.
The dash-dash-libcurl is the sometimes missed curl gem that you might want to know about and occasionally maybe even use.
How do I convert
There is a very common pattern in curl land: a user who is writing an application using language L first does something successfully with the curl command line tool and then the person wants to convert that command line into the program they are writing.
How do you convert this curl command line into a transfer using programming language XYZ?
Language bindings
There is a huge amount of available bindings for libcurl. Bindings, as in adjustments and glue code for languages to use libcurl for Internet transfers so that they do not have to write the application in C.
At a recent count I found more than 60 libcurl bindings. They allow authors of virtually any programming language to do internet transfers using the powers of libcurl.
Most of these bindings are “thin” and follow the same style of the original C API: You create a handle for which you set options and then you do the transfer. This way they are fairly easy to keep up to date with the always-changing and always-improving libcurl releases.
Say hi to --libcurl
Most curl command line options are mapped one-to-one to an underlying libcurl option so for some time I tried to help users by explaining what they map to. Until one day I realized that
Hey! curl itself already has this mapping in source code, it just needs a way to show it to users!
How would it best output this mapping?
The --libcurl command line option was added to curl already back in 2007 and has been part of the tool since version 7.16.1.
Show this command line as libcurl code
It is really easy to use too.
Create a complicated curl command line that does what you need it to do.
Append --libcurl example.c to the command line and run it again.
Inspect your newly generated file example.c for how you could write your application to do the same thing with libcurl.
If you want to use a libcurl binding rather than the C API, like perhaps write your code in Python or PHP, you need to convert the example code into your programming language but much thanks to the options keeping their names across the different bindings it is usually a trivial task.
Example
The simplest possible command line:
curl curl.se
It gets HTTP from the site “curl.se”. If you try it, you will not see anything because it just replies with a redirect to the HTTPS version of the page. But ignoring that, you can convert that action into a libcurl program like this:
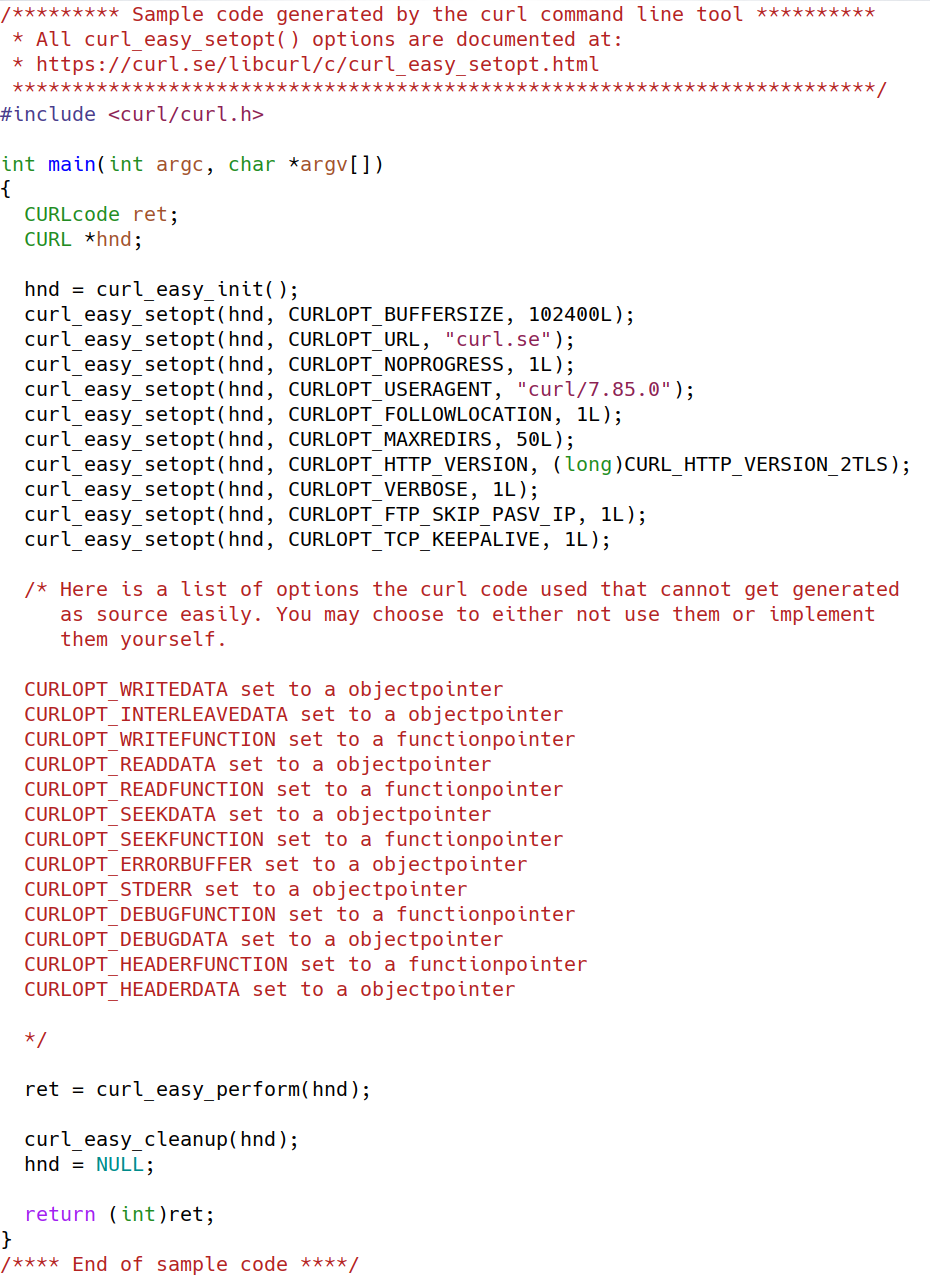
curl curl.se --libcurl code.c
The newly created file code.c now contains a program that you can compile :
gcc -o getit code.c -lcurl
and then run
./getit
You might want your program to rather follow the redirect? Maybe even show debug output? Let’s rerun the command line and get a code update:
Now, if you rebuild your program and run it again, it shows you the front page HTML of the curl website on stdout.
The code
The exact code my curl version 7.85.0 produced in the command line above is shown below.
You see several options that are commented out. Those were used by the command line tool but there is no easy or convenient way to show their use in the example. Often you can start out by just skipping those .
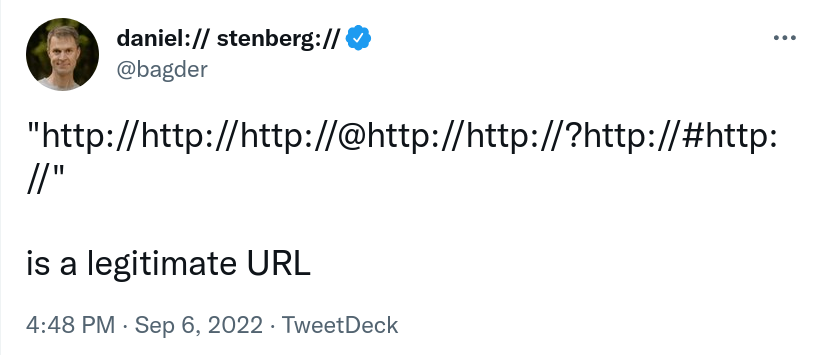
As it took off, got an amazing attention and I received many different comments and replies, I felt a need to elaborate a little. To add some meat to this.
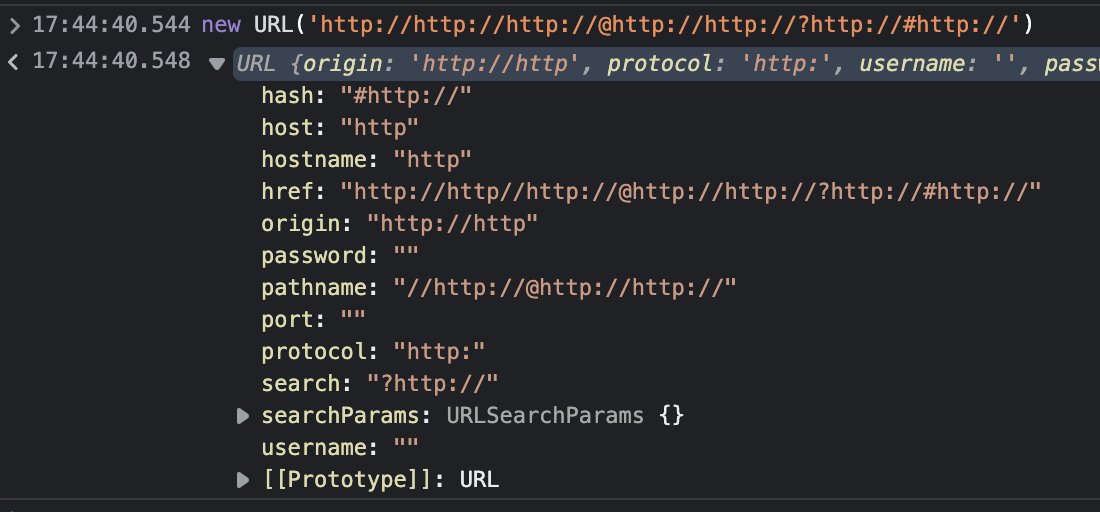
Is this string really a legitimate URL? What is a URL? How is it parsed?
http – the scheme of the URL. This speaks HTTP. The “://” separates the scheme from the following authority part (that’s basically everything up to the path).
http – the user name up to the first colon
//http:// – the password up to the at-sign (@)
http: – the host name, with a trailing colon. The colon is a port number separator, but a missing number will be treated by curl as the default number. Browsers also treat missing port numbers like this. The default port number for the http scheme is 80.
//http:// – the path. Multiple leading slashes are fine, and so is using a colon in the path. It ends at the question mark separator (?).
http:// – the query part. To the right of the question mark, but before the hash (#).
http:// – the fragment, also known as “anchor”. Everything to the right of the hash sign (#).
To use this URL with curl and serve it on your localhost try this command line:
The curl parser has been around for decades already and do not break existing scripts and applications is one of our core principles. Thus, some of the choices in the URL parser we did a long time ago and we stand by them, even if they might be slightly questionable standards wise. As if any standard meant much here.
The curl parser started its life as lenient as it could possibly be. While it has been made stricter over the years, traces of the original design still shows. In addition to that, we have also felt that we have been forced to make adaptions to the parser to make it work with real world URLs thrown at it. URLs that maybe once was not deemed fine, but that have become “fine” because they are accepted in other tools and perhaps primarily in browsers.
There is the URI (not URL!) definition from IETF RFC 3986, there is the WHATWG URL Specification that browsers (try to) adhere to and there are numerous different implementations of parsers being more or less strict when following one or both of the above mentioned specifications.
You will find that when you scrutinize them into the details, hardly any two URL parsers agree on every little character.
Therefore, if you throw the above mentioned URL on any random URL parser they may reject it (like the Twitter parser didn’t seem to think it was a URL) or they might come to a different conclusion about the different parts than curl does. In fact, it is likely that they will not do exactly as curl does.
Python’s urllib
April King threw it at Python’s urllib. A valid URL! While it accepted it as a URL, it split it differently:
(the second colon from the left is removed, everything else is the same)
… but still considered it a valid URL and showed the contents from my web server.
Chrome behaved exactly the same. A valid URL according to it, and a rewrite of the URL like Firefox does.
RFC 3986
Some commenters mentioned that the unencoded “unreserved” letters in the authority part make it not RFC 3986 compliant. Section 3.2 says:
The authority component is preceded by a double slash ("//") and is terminated by the next slash ("/"), question mark ("?"), or number sign ("#") character, or by the end of the URI.
Meaning that the password should have its slashes URL-encoded as %2f to make it valid. At least. So maybe not a valid URL?
Update: it actually still qualifies as “valid”, it just is parsed a little differently than how curl does it. I do not think there is any question that curl’s interpretation is not matching RFC 3986.
It made it 7 characters longer for no obvious extra fun
It is harder to prove working by serving your own content as you would need curl -k or similar to make the host name ‘https’ be OK vs the name used in the actual server you would target.
The URL Buffalo buffalo
A surprisingly large number of people thought it reminded them of the old buffalo buffalo thing.