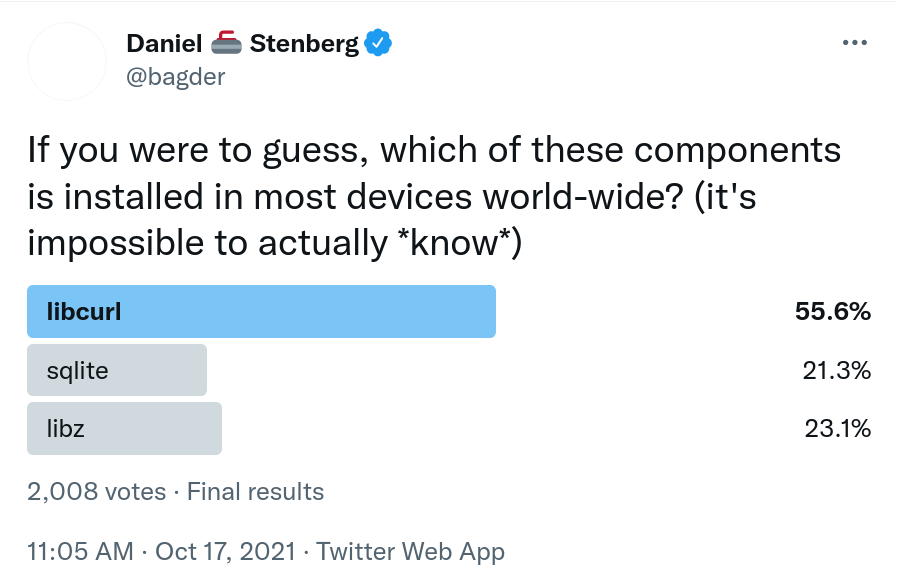
I still remember the RFC number off the top of my head for the first multipart formdata spec that I implemented support for in curl. Added to curl in version 5.0, December 1998. RFC 1867.
Multipart formdata is the name of the syntax for how HTTP clients send data in a HTTP POST when they want to send binary content and multiple fields. Perhaps the most common use case for users is when uploading a file or an image with a browser to a website. This is also what you fire off with curl’s -F command line option.
RFC 1867 was published in November 1995 and it has subsequently been updated several times. The most recent incarnation for this spec is now known as RFC 7578, published in July 2015. Twenty years of history, experiences and minor adjustments. How do they affect us?
I admit to having dozed off a little at the wheel and I hadn’t really paid attention to the little tweaks that slowly had been happening in the multipart formata world until Ryan Sleevi woke me up.
Percent-encoding
While I wasn’t looking, the popular browsers have now all switched over to a different encoding style for field and file names within the format. They now all use percent-encoding, where we originally all used to do backslash-escaping! I haven’t actually bothered to check exactly when they switched, primarily because I don’t think it matters terribly much. They do this because this is now the defined syntax in WHATWG’s HTML spec. Yes, another case of separate specs diverging and saying different things for what is essentially the same format.
curl 7.80.0 is probably the last curl version to do the escaping the old way and we are likely to switch to the new way by default starting in the next release. The work on this is done by Patrick Monnerat in his PR.
For us in the curl project it is crucial to maintain behavior, but it is also important to be standard compliant and to interoperate with the big world out there. When all the major browsers have switched to percent-encoding I suspect it is only a matter of time until servers and server-side scripts start to assume and require percent-encoding. This is a tricky balancing act. There will be users who expect us to keep up with the browsers, but also some that expect us to maintain the way we’ve done it for almost twenty-three years…
libcurl users at least, will be offered a way to switch back to use the old escaping mechanism to make sure applications that know they work with older style server decoders can keep their applications working.
Landing
This blog post is made public before the PR mentioned above has been merged in order for people to express opinions and comments before it is done. The plan is to have it merged and ship in curl 7.81.0, to be released in January 2022.