It’s just another meaningless number, but today there are 3,000 forks done of the curl GitHub repository.
This pops up just a little over three years since we reached our first 1,000 forks. Also, 10,000 stars no too long ago.
Why fork?
A typical reason why people fork a project on GitHub, is so that they can make a change in their own copy of the source code and then suggest that change to the project in the form of a pull-request.
The curl project has almost 700 individual commit authors, which makes at least 2,300 forks done who still haven’t had their pull-requests accepted! Of course those are 700 contributors who actually managed to work all the way through to inclusion. We can imagine that there is a huge number of people who only ever thought about doing a change, some who only ever just started to do it, many who ditched the idea before it was completed, some who didn’t actually manage to implement it properly, some who got their idea and suggestion shut down by the project and of course, lots of people still have their half-finished change sitting there waiting for inspiration.
Then there are people who just never had the intention of sending any change back. Maybe they just wanted to tinker with the code and have fun. Some want to do private changes they don’t want to offer or perhaps they already know the upstream project won’t accept.
We just can’t tell.
Many?
Is 3,000 forks a lot or a little? Both. It is certainly more forks than we’ve ever had before in this project. But compared to some of the most popular projects on GitHub, even comparing to some other C projects (on GitHub the most popular projects are never written in C) our numbers are dwarfed by the really popular ones. You can probably guess which ones they are.
In the end, this number is next to totally meaningless as it doesn’t say anything about the project nor about what contributions we get or will get in the future. It tells us we have (or had) the attention of a lot of users and that’s about it.
I will continue to try to make sure we’re worth the attention, both now and going forward!
We announced our glorious return to the “bug bounty club” (projects that run bug bounties) a month ago, and with the curl 7.65.0 release today on May 22nd of 2019 we also ship fixes to security vulnerabilities that were reported within this bug bounty program.
Announcement
Even before we publicly announced the program, it was made public on the Hackerone site. That was obviously enough to get noticed by people and we got the first reports immediately!
We have received 19 reports so far.
Infrastructure scans
Quite clearly some people have some scripts laying around and they do some pretty standard things on projects that pop up on hackerone. We immediately got a number of reports that reported variations of the same two things repeatedly:
Our wiki is world editable. In my world I’ve lived under the assumption that this is how a wiki is meant to be but we ended up having to specifically mention this on curl’s hackerone page: yes it is open for everyone on purpose.
Sending emails forging them to look like the come from the curl web site might work since our DNS doesn’t have SPF, DKIM etc setup. This is a somewhat better report, but our bounty program is dedicated for and focused on the actual curl and libcurl products. Not our infrastructure.
Bounties!
Within two days of the program’s life time, the first legit report had been filed and then within a few more days a second arrived. They are CVE-2019-5435 and CVE-2019-5436, explained somewhat in my curl 7.65.0 release post but best described in their individual advisories, linked to below.
I’m thrilled to report that these two reporters were awarded money for their findings:
Wenchao Li was awarded 150 USD for finding and reporting CVE-2019-5435.
l00p3r was awarded 200 USD for finding and reporting CVE-2019-5436.
Both these issues were rated severity level “Low” and we consider them rather obscure and not likely to hurt very many users.
Donate to help us fund this!
Please notice that we are entirely depending on donated funds to be able to run this program. If you use curl and benefit from a more secure curl, please consider donating a little something for the cause!
After another eight week cycle was been completed, curl shipped a new release into the world. 7.65.0 brings some news and some security fixes but is primarily yet again a set of bug-fixes bundled up. Remember 7.64.1?
As always, download it straight from curl.haxx.se!
One fun detail on this release: we have 500 less lines of source code in the lib/ directory compared to the previous release!
Things that happened in curl since last release:
we announced a new Bug Bounty program and already paid the first rewards
CURLOPT_MAXAGE_CONN is a new option that controls how long to keep a live connection in the connection cache for reuse.
Security
This release comes with fixes for two separate security problems. Both rated low risk. Both reported via the new bug bounty program.
CVE-2019-5435 is an issue in the recently introduced URL parsing API. It is only a problem in 32 bit architectures and only if an application can be told to pass in ridiculously long (> 2GB) strings to libcurl. This bug is similar in nature to a few other bugs libcurl has had in the past, and to once and for all combat this kind of flaw libcurl now (in 7.65.0 and forward) has a “maximum string length” limit for strings that you can pass to it using its APIs. The maximum size is 8MB. (The reporter was awarded 150 USD for this find.)
CVE-2019-5436 is a problem in the TFTP code. If an application decides to uses a smaller “blksize” than 504 (default is 512), curl would overflow a buffer allocated on the heap with data received from the server. Luckily, very few people actually download data from unknown or even remote TFTP servers. Secondly, asking for a blksize smaller than 512 is rather pointless and also very rare: the primary point in changing that size is to enlarge it. (The reporter was awarded 200 USD for this find.)
Bug-fixes
Over one hundred bug-fixes landed in this release, but some of my favorites from release cycle include…
mark connection for close on TLS close_notify
close_notify is a message in the TLS protocol that means that this connection is about to close. In most circumstances that message doesn’t actually provide information to curl that is needed, but in the case the connection is closed prematurely, understanding that this message preceded the closure helps curl act appropriately. This change was done for the OpenSSL backend only as that’s where we got the bug reported and worked on it this time, but I think we might have reasons to do the same for other backends going forward!
show port in the verbose “Trying …” message
The verbose message that says “Trying 12.34.56.78…” means that curl has sent started a TCP connect attempt to that IP address. This message has now been modified to also include the target port number so when using -v with curl 7.65.0, connecting to that same host for HTTPS will instead say “Trying 12.34.56.78:443…”.
To aid debugging really. I think it gives more information faster at a place you’re already looking.
new SOCKS 4+5 test server
The test suite got a brand new SOCKS server! Previously, all SOCKS tests for both version 4 and version 5 were done by firing up ssh (typically openssh). That method was decent but made it hard to do a range of tests for bad behavior, bad protocol replies and similar. With the new custom test server, we can basically add whatever test we want and we’ve already extended the SOCKS testing to cover more code and use cases than previously.
SOCKS5 user name and passwords must be shorter than 256
curl allows user names and passwords provided in URLs and as separate options to be more or less unrestricted in size and that include if the credentials are used for SOCKS5 authentication – totally ignoring the fact that the protocol SOCKS5 has a maximum size of 255 for the fields. Starting now, curl will return an error if the credentials for SOCKS5 are too long.
Warn if curl and libcurl versions do not match
The command line tool and the library are independent and separable, as in you can run one version of the curl tool with another version of the libcurl library. The libcurl API is solid enough to allow it and the tool is independent enough to not restrict it further.
We always release curl the command line tool and libcurl the library together, using the same version number – with the code for both shipped in the same single file.
There should rarely be a good reason to actually run curl and libcurl with different versions. Starting now, curl will show a little warning if this is detected as we have learned that this is almost always a sign of an installation or setup mistake. Hopefully this message will aid people to detect the mistake earlier and easier.
Better handling of “–no-” prefixed options
curl’s command line parser allows users to switch off boolean options by prefixing them with dash dash no dash. For example we can switch off compressed responses by using “–no-compression” since there regular option “–compression” switches it on.
It turned out we stripped the “–no-” thing no regarding if the option was boolean or not and presumed the logic to handle it – which it didn’t. So users could actually pass a proxy string to curl with the regular option “–proxy” as well as “–no-proxy”. The latter of course not making much sense and was just due to an oversight.
In 7.65.0, only actual boolean command line options can be used with “–no-“. Trying it on other options will cause curl to report error for it.
Add CURLUPART_ZONEID to the URL API
Remember when we added a new URL parsing API to libcurl back in 7.62.0? It wasn’t even a year ago! When we did this, we also changed the internals to use the same code. It turned out we caused a regression when we parsed numerical IPv6 addresses that provide the zone ID within the string. Like this: “https://[ffe80::1%25eth0]/index.html”
Starting in this release, you can both set and get the zone ID in a URL using the API, but of course setting it doesn’t do anything unless the host is a numeric IPv6 address.
parse proxy with the URL parser API
We removed the separate proxy string parsing logic and instead switched that over to more appropriately use the generic URL parser for this purpose as well. This move reduced the code size, made the code simpler and makes sure we have a unified handling of URLs! Everyone is happy!
longer URL schemes
I naively wrote the URL parser to handle scheme names as long as the longest scheme we support in curl: 8 bytes. But since the parser can also be asked to parse URLs with non-supported schemes, that limit was a bit too harsh. I did a quick research, learned that the longest currently registered URI scheme is 36 characters (“microsoft.windows.camera.multipicker”). Starting in this release , curl accepts URL schemes up to 40 bytes long.
Coming up next
There’s several things brewing in the background that might be ready to show in next release. Parallel transfers in the curl tool and deprecating PolarSSL support seem likely to happen for example. Less likely for this release, but still being worked on slowly, is HTTP/3 support.
We’re also likely to get a bunch of changes and fine features we haven’t even thought about from our awesome contributors. In eight weeks I hope to write another one of these blog posts explaining what went into that release…
For the 6th consecutive year, the curl project is running a “user survey” to learn more about what people are using curl for, what think think of curl, what the need of curl and what they wish from curl going forward.
As in most projects, we love to learn more about our users and how to improve. For this, we need your input to guide us where to go next and what to work on going forward.
Please consider donating a few minutes of your precious time and tell me about your views on curl. How do you use it and what would you like to see us fix?
The survey will be up for 14 straight days and will be taken down at midnight (CEST) May 26th. We appreciate if you encourage your curl friends to participate in the survey.
curl, or libcurl specifically, is probably the world’s most popular and widely used HTTP client side library counting more than six billion installs.
curl is a rock solid and feature-packed library that supports a huge amount of protocols and capabilities that surpass most competitors. But this comes at a cost: it is not the smallest library you can find.
Within a 100K
Instead of being happy with getting told that curl is “too big” for certain use cases, I set a goal for myself: make it possible to builda version of curl that can do HTTPS and fit in 100K (including the wolfSSL TLS library) on a typical 32 bit architecture.
As a comparison, the tiny-curl shared library when built on an x86-64 Linux, is smaller than 25% of the size as the default Debian shipped library is.
FreeRTOS
But let’s not stop there. Users with this kind of strict size requirements are rarely running a full Linux installation or similar OS. If you are sensitive about storage to the exact kilobyte level, you usually run a more slimmed down OS as well – so I decided that my initial tiny-curl effort should be done on FreeRTOS. That’s a fairly popular and free RTOS for the more resource constrained devices.
This port is still rough and I expect us to release follow-up releases soon that improves the FreeRTOS port and ideally also adds support for other popular RTOSes. Which RTOS would you like to support for that isn’t already supported?
Offer the libcurl API for HTTPS on FreeRTOS, within 100 kilobytes.
Maintain API
I strongly believe that the power of having libcurl in your embedded devices is partly powered by the libcurl API. The API that you can use for libcurl on any platform, that’s been around for a very long time and for which you can find numerous examples for on the Internet and in libcurl’s extensive documentation. Maintaining support for the API was of the highest priority.
Patch it
My secondary goal was to patch as clean as possible so that we can upstream patches into the main curl source tree for the changes makes sense and that aren’t disturbing to the general code base, and for the work that we can’t we should be able to rebase on top of the curl code base with as little obstruction as possible going forward.
Keep the HTTPS basics
I just want to do HTTPS GET
That’s the mantra here. My patch disables a lot of protocols and features:
No protocols except HTTP(S) are supported
HTTP/1 only
No cookie support
No date parsing
No alt-svc
No HTTP authentication
No DNS-over-HTTPS
No .netrc parsing
No HTTP multi-part formposts
No shuffled DNS support
No built-in progress meter
Although they’re all disabled individually so it is still easy to enable one or more of these for specific builds.
Downloads and versions?
Tiny-curl 0.9 is the first shot at this and can be downloaded from wolfSSL. It is based on curl 7.64.1.
Most of the patches in tiny-curl are being upstreamed into curl in the #3844 pull request. I intend to upstream most, if not all, of the tiny-curl work over time.
License
The FreeRTOS port of tiny-curl is licensed GPLv3 and not MIT like the rest of curl. This is an experiment to see how we can do curl work like this in a sustainable way. If you want this under another license, we’re open for business over at wolfSSL!
I view myself as primarily a software developer. Perhaps secondary as someone who’s somewhat knowledgeable in networking and is participating in protocol development and discussions. I do not regularly proclaim myself to be a “speaker” or someone who’s even very good at talking in front of people.
Time to wake up and face reality? I’m slowly starting to realize that I’m actually doing more presentations than ever before in my life and I’m enjoying it.
Since October 2015 I’ve done 53 talks and presentations in front of audiences – in ten countries. That’s one presentation done every 25 days on average. (The start date of this count is a little random but it just happens that I started to keep a proper log then.) I’ve talked to huge audiences and to small. I done presentations that were appreciated and I’ve done some that were less successful.
The room for the JAX keynote, May 2019, as seen from the stage, some 20 minutes before 700 persons sat down in the audience to hear my talk on HTTP/3.
My increased frequency in speaking engagements coincides with me starting to work full-time from home back in 2014. Going to places to speak is one way to get out of the house and see the “real world” a little bit and see what the real people are doing. And a chance to hang out with humans for a change. Besides, I only ever talk on topics that are dear to me and that I know intimately well so I rarely feel pressure when delivering them. 2014 – 2015 was also the time frame when HTTP/2 was being finalized and the general curiosity on that new protocol version helped me find opportunities back then.
Public speaking is like most other things: surprisingly enough, practice actually makes you better at it! I still have a lot to learn and improve, but speaking many times has for example made me better at figuring out roughly how long time I need to deliver a particular talk. It has taught me to “find myself” better when presenting and be more relaxed and the real me – no need to put up a facade of some kind or pretend. People like seeing that there’s a real person there.
I talked HTTP/2 at Techday by Init, in November 2016.
I’m not even getting that terribly nervous before my talks anymore. I used to really get a raised pulse for the first 45 talks or so, but by doing it over and over and over I think the practice has made me more secure and more relaxed in my attitude to the audience and the topics. I think it has made me a slightly better presenter and it certainly makes me enjoy it more.
I’m not “a good presenter”. I can deliver a talk and I can do it with dignity and I think the audience is satisfied with me in most cases, but by watching actual good presenters talk I realize that I still have a long journey ahead of me. Of course, parts of the explanation is that, to connect with the beginning of this post, I’m a developer. I don’t talk for a living and I actually very rarely practice my presentations very much because I don’t feel I can spend that time.
The JAX keynote in May 2019 as seen from the audience. Photo by Bernd Ruecker.
Some of the things that are still difficult include:
The money issue. I actually am a developer and that’s what I do for a living. Taking time off the development to prepare a presentation, travel to a distant place, sacrifice my spare time for one or more days and communicating something interesting to an audience that demands and expects it to be both good and reasonably entertaining takes time away from that development. Getting travel and accommodation compensated is awesome but unfortunately not enough. I need to insist on getting paid for this. I frequently turn down speaking opportunities when they can’t pay me for my time.
Saying no. Oh my god do I have a hard time to do this. This year, I’ve been invited to so many different conferences and the invitations keep flying in. For every single received invitation, I get this warm and comfy feeling and I feel honored and humbled by the fact that someone actually wants me to come to their conference or gathering to talk. There’s the calendar problem: I can’t be in two places at once. Then I also can’t plan events too close to each other in time to avoid them holding up “real work” too much or to become too much of a nuisance to my family. Sometimes there’s also the financial dilemma: if I can’t get compensation, it gets tricky for me to do it, no matter how good the conference seems to be and the noble cause they’re working for.
Feedback. To determine what parts of the presentation that should be improved for the next time I speak of the same or similar topic, which parts should be removed and if something should be expanded, figuring what works and what doesn’t work is vital. For most talks I’ve done, there’s been no formal way to provide or receive this feedback, and for the small percentage that had a formal feedback form or a scoring system or similar, taking care of a bunch of distributed grades (for example “your talk was graded 4.2 on a scale between 1 and 5”) and random comments – either positive or negative – is really hard… I get the best feedback from close friends who dare to tell me the truth as it is.
Conforming to silly formats. Slightly different, but some places want me to send me my slides in, either a long time before the event (I’ve had people ask me to provide way over a week(!) before), or they dictate that the slides should be sent to them using Microsoft Powerpoint, PDF or some other silly format. I want to use my own preferred tools when designing presentations as I need to be able to reuse the material for more and future presentations. Sure, I can convert to other formats but that usually ruins formatting and design. Then a lot the time and sweat I put into making a fine and good-looking presentation is more or less discarded! Fortunately, most places let me plug in my laptop and everything is fine!
Upcoming talks?
As a little service to potential audience members and conference organizers, I’m listing all my upcoming speaking engagements on a dedicated page on my web site:
I try to keep that page updated to reflect current reality. It also shows that some organizers are forward-planning waaaay in advance…
Here’s me talking about DNS-over-HTTPS at FOSDEM 2019. Photo by Steve Holme.
Invite someone like me to talk?
Here’s some advice on how to invite a speaker (like me) with style:
Ask well in advance (more than 2-3 months preferably, probably not more than 9). When I agree to a talk, others who ask for talks in close proximity to that date will get declined. I get a surprisingly large amount of invitations for events just a month into the future or so, and it rarely works for me to get those into my calendar in that time frame.
Do not assume for-free delivery. I think it is good tone of you to address the price/charge situation, if not in the first contact email at least in the following discussion. If you cannot pay, that’s also useful information to provide early.
If the time or duration of the talk you’d like is “unusual” (ie not 30-60 minutes) do spell that out early on.
Surprisingly often I get invited to talk without a specified topic or title. The inviter then expects me to present that. Since you contact me you clearly had some kind of vision of what a talk by me would entail, it would make my life easier if that vision was conveyed as it could certainly help me produce a talk subject that will work!
Presenting HTTP/2 at the Velocity conference in New York, October 2015, together with Ragnar Lönn.
What I bring
To every presentation I do, I bring my laptop. It has HDMI and USB-C ports. I also carry a HDMI-to-VGA adapter for the few installations that still use the old “projector port”. Places that need something else than those ports tend to have their own converters already since they’re then used with equipment not being fitted for their requirements.
I always bring my own clicker (the “remote” with which I can advance to next slide). I never use the laser-pointer feature, but I like being able to move around on the stage and not have to stand close to the keyboard when I present.
Presentations
I never create my presentations with video or sound in them, and I don’t do presentations that need Internet access. All this to simplify and to reduce the risk of problems.
I work hard on limiting the amount of text on each slide, but I also acknowledge that if a slide set should have value after-the-fact there needs to be a certain amount. I’m a fan of revealing the text or graphics step-by-step on the slides to avoid having half the audience reading ahead on the slide and not listening.
I’ve settled on 16:9 ratio for all presentations. Luckily, the remaining 4:3 projectors are now scarce.
I always make and bring a backup of my presentations in PDF format so that basically “any” computer could display that in case of emergency. Like if my laptop dies. As mentioned above, PDF is not an ideal format, but as a backup it works.
I talked “web transport” in the Mozilla devroom at FOSDEM, February 2017 in front of this audience. Not a single empty seat…
As some of you already found out, I’ve tried live-streaming curl development recently. If you want to catch previous and upcoming episodes subscribe on my twitch page.
Why stream
For the fun of it. I work alone from home most of the time and this is a way for me to interact with others.
To show what’s going on in curl right now. By streaming some of my development I also show what kind of work that’s being done, showing that a lot of development and work are being put into curl and I can share my thoughts and plans with a wider community. Perhaps this will help getting more people to help out or to tickle their imagination.
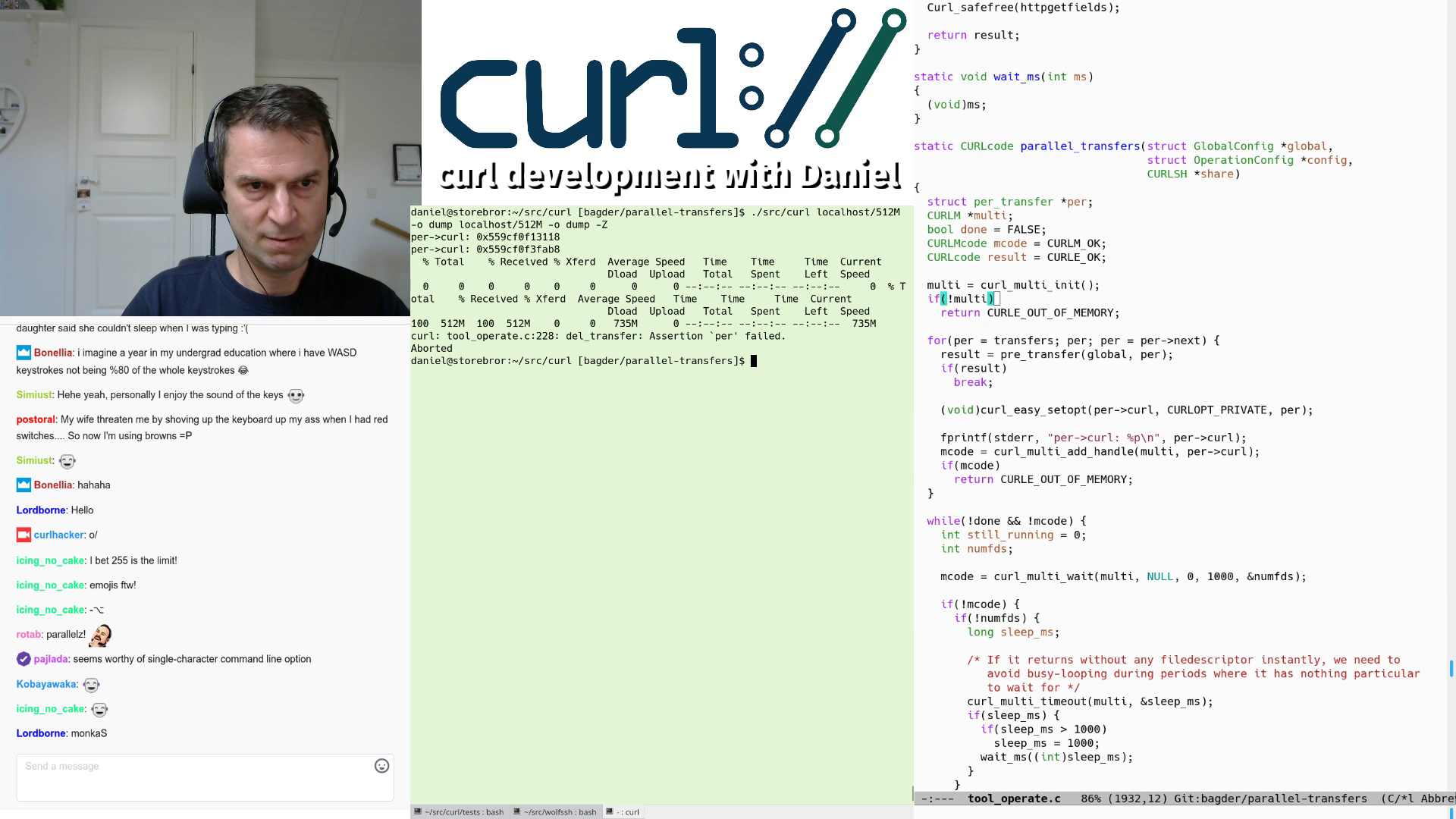
A screenshot from live stream #11 when parallel transfers with curl was shown off for the first time ever!
For the feedback and interaction. It is immediately notable that one of the biggest reasons I enjoy live-streaming is the chat with the audience and the instant feedback on mistakes I do or thoughts and plans I express. It becomes a back-and-forth and it is not at all just a one-way broadcast. The more my audience interact with me, the more fun I have! That’s also the reason I show the chat within the stream most of the time since parts of what I say and do are reactions and follow-ups to what happens there.
I can only hope I get even more feedback and comments as I get better at this and that people find out about what I’m doing here.
And really, by now I also think of it as a really concentrated and devoted hacking time. I can get a lot of things done during these streaming sessions! I’ll try to keep them going a while.
Twitch
I decided to go with twitch simply because it is an established and known live-streaming platform. I didn’t do any deeper analyses or comparisons, but it seems to work fine for my purposes. I get a stream out with video and sound and people seem to be able to enjoy it.
As of this writing, there are 1645 people following me on twitch. Typical recent live-streams of mine have been watched by over a hundred simultaneous viewers. I also archive all past streams on Youtube, so you can get almost the same experience my watching back issues there.
I announce my upcoming streaming sessions as “events” on Twitch, and I announce them on twitter (@bagder you know). I try to stick to streaming on European day time hours basically because then I’m all alone at home and risk fewer interruptions or distractions from family members or similar.
Challenges
It’s not as easy as it may look trying to write code or debug an issue while at the same time explaining what I do. I learnt that the sessions get better if I have real and meaty issues to deal with or features to add, rather than to just have a few light-weight things to polish.
I also quickly learned that it is better to now not show an actual screen of mine in the stream, but instead I show a crafted set of windows placed on the output to look like it is a screen. This way there’s a much smaller risk that I actually show off private stuff or other content that wasn’t meant for the audience to see. It also makes it easier to show a tidy, consistent and clear “desktop”.
Streaming makes me have to stay focused on the development and prevents me from drifting off and watching cats or reading amusing tweets for a while
Trolls
So far we’ve been spared from the worst kind of behavior and people. We’ve only had some mild weirdos showing up in the chat and nothing that we couldn’t handle.
Equipment and software
I do all development on Linux so things have to work fine on Linux. Luckily, OBS Studio is a fine streaming app. With this, I can setup different “scenes” and I can change between them easily. Some of the scenes I have created are “emacs + term”, “browser” and “coffee break”.
When I want to show off me fiddling with the issues on github, I switch to the “browser” scene that primarily shows a big browser window (and the chat and the webcam in smaller windows).
When I want to show code, I switch to “emacs + term” that instead shows a terminal and an emacs window (and again the chat and the webcam in smaller windows), and so on.
OBS has built-in support for some of the major streaming services, including twitch, so it’s just a matter of pasting in a key in an input field, press ‘start streaming’ and go!
The rest of the software is the stuff I normally use anyway for developing. I don’t fake anything and I don’t make anything up. I use emacs, make, terminals, gdb etc. Everything this runs on my primary desktop Debian Linux machine that has 32GB of ram, an older i7-3770K CPU at 3.50GHz with a dual screen setup. The video of me is captured with a basic Logitech C270 webcam and the sound of my voice and the keyboard is picked up with my Sennheiser PC8 headset.
How else am I supposed to have my coffee while developing?
This is my home office standard setup. On the left is my video conference laptop and on the right is my regular work laptop. The two screens in the middle are connected to the desktop computer.