

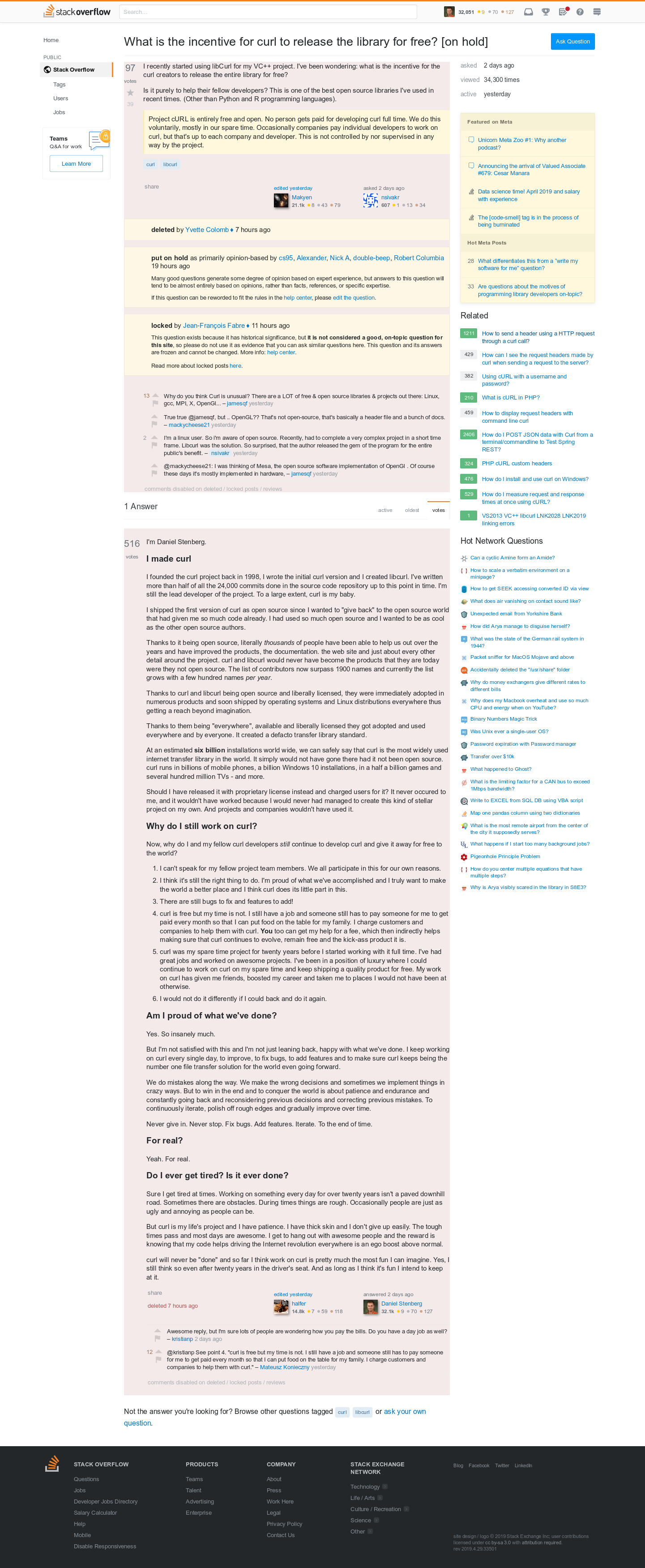
(This is a repost of the answer I posted on stackoverflow for this question. This answer immediately became my most ever upvoted answer on stackoverflow with 516 upvotes during the 48 hours it was up before a moderator deleted it for unspecified reasons. It had then already been marked “on hold” for being “primarily opinion- based” and then locked but kept: “exists because it has historical significance”. But apparently that wasn’t good enough. I’ve saved a screenshot of the deletion. Debated on meta.stackoverflow.com. Status now: it was brought back but remains locked.)
I’m Daniel Stenberg.
I made curl
I founded the curl project back in 1998, I wrote the initial curl version and I created libcurl. I’ve written more than half of all the 24,000 commits done in the source code repository up to this point in time. I’m still the lead developer of the project. To a large extent, curl is my baby.
I shipped the first version of curl as open source since I wanted to “give back” to the open source world that had given me so much code already. I had used so much open source and I wanted to be as cool as the other open source authors.
Thanks to it being open source, literally thousands of people have been able to help us out over the years and have improved the products, the documentation. the web site and just about every other detail around the project. curl and libcurl would never have become the products that they are today were they not open source. The list of contributors now surpass 1900 names and currently the list grows with a few hundred names per year.
Thanks to curl and libcurl being open source and liberally licensed, they were immediately adopted in numerous products and soon shipped by operating systems and Linux distributions everywhere thus getting a reach beyond imagination.
Thanks to them being “everywhere”, available and liberally licensed they got adopted and used everywhere and by everyone. It created a defacto transfer library standard.
At an estimated six billion installations world wide, we can safely say that curl is the most widely used internet transfer library in the world. It simply would not have gone there had it not been open source. curl runs in billions of mobile phones, a billion Windows 10 installations, in a half a billion games and several hundred million TVs – and more.
Should I have released it with proprietary license instead and charged users for it? It never occured to me, and it wouldn’t have worked because I would never had managed to create this kind of stellar project on my own. And projects and companies wouldn’t have used it.
Why do I still work on curl?
Now, why do I and my fellow curl developers still continue to develop curl and give it away for free to the world?
- I can’t speak for my fellow project team members. We all participate in this for our own reasons.
- I think it’s still the right thing to do. I’m proud of what we’ve accomplished and I truly want to make the world a better place and I think curl does its little part in this.
- There are still bugs to fix and features to add!
- curl is free but my time is not. I still have a job and someone still has to pay someone for me to get paid every month so that I can put food on the table for my family. I charge customers and companies to help them with curl. You too can get my help for a fee, which then indirectly helps making sure that curl continues to evolve, remain free and the kick-ass product it is.
- curl was my spare time project for twenty years before I started working with it full time. I’ve had great jobs and worked on awesome projects. I’ve been in a position of luxury where I could continue to work on curl on my spare time and keep shipping a quality product for free. My work on curl has given me friends, boosted my career and taken me to places I would not have been at otherwise.
- I would not do it differently if I could back and do it again.
Am I proud of what we’ve done?
Yes. So insanely much.
But I’m not satisfied with this and I’m not just leaning back, happy with what we’ve done. I keep working on curl every single day, to improve, to fix bugs, to add features and to make sure curl keeps being the number one file transfer solution for the world even going forward.
We do mistakes along the way. We make the wrong decisions and sometimes we implement things in crazy ways. But to win in the end and to conquer the world is about patience and endurance and constantly going back and reconsidering previous decisions and correcting previous mistakes. To continuously iterate, polish off rough edges and gradually improve over time.
Never give in. Never stop. Fix bugs. Add features. Iterate. To the end of time.
For real?
Yeah. For real.
Do I ever get tired? Is it ever done?
Sure I get tired at times. Working on something every day for over twenty years isn’t a paved downhill road. Sometimes there are obstacles. During times things are rough. Occasionally people are just as ugly and annoying as people can be.
But curl is my life’s project and I have patience. I have thick skin and I don’t give up easily. The tough times pass and most days are awesome. I get to hang out with awesome people and the reward is knowing that my code helps driving the Internet revolution everywhere is an ego boost above normal.
curl will never be “done” and so far I think work on curl is pretty much the most fun I can imagine. Yes, I still think so even after twenty years in the driver’s seat. And as long as I think it’s fun I intend to keep at it.














{kind=link}