In the curl project we keep track of and say thanks to every single contributor. That includes persons who report bugs or security problems, who run infrastructure for us, who assist in debugging or fixing problems as well as those who author code or edit the website. Those who have contributed to make curl to what it is.
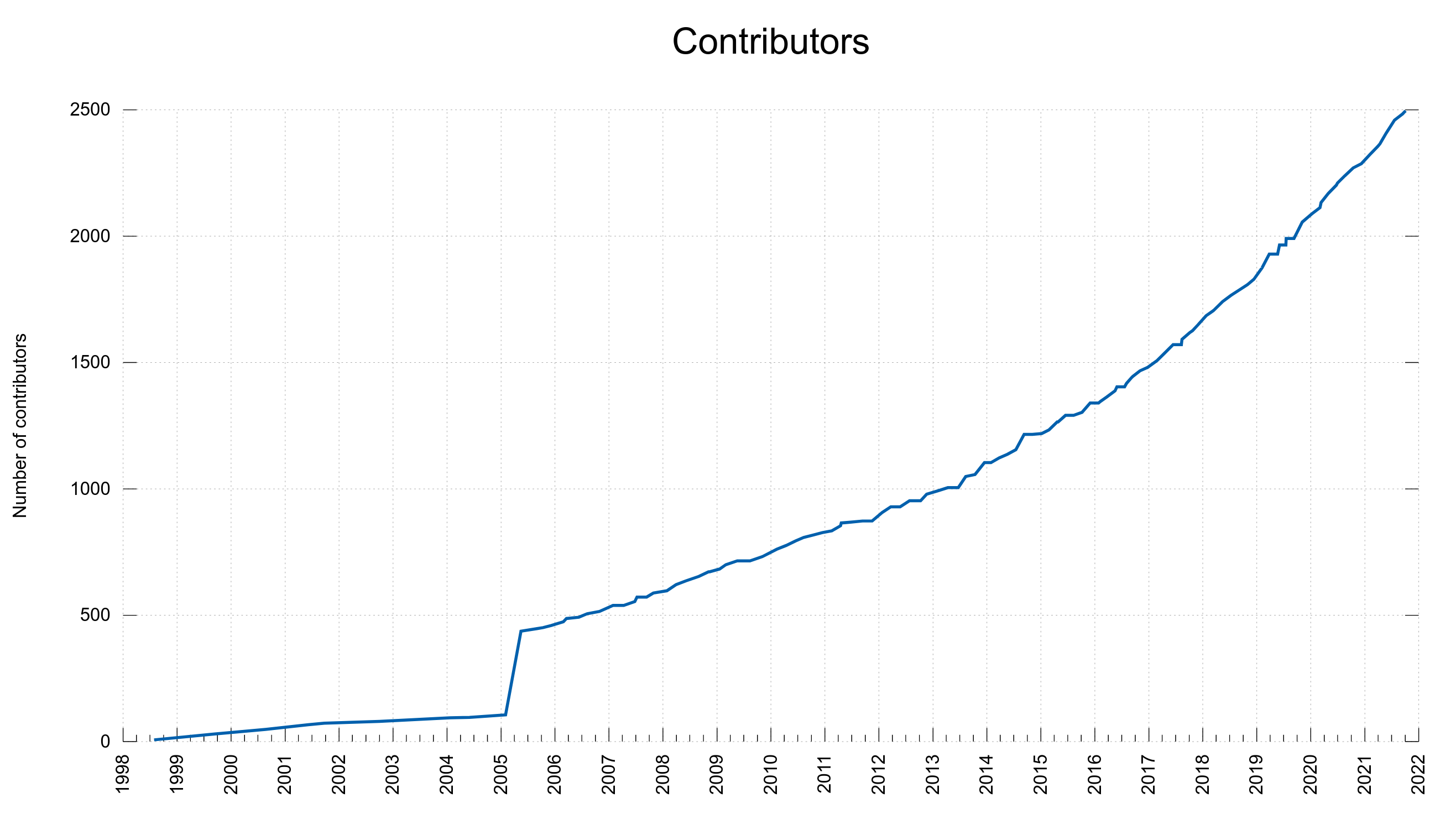
Exactly today October 4th 2021, we reached 2,500 names in this list of contributors for the first time. 2,500 persons since the day curl was created back in March 1998. 2,500 contributors in 8599 days. This means that on average we’ve seen one new contributor helping out in the project every 3.44 days for almost twenty-four years. Not bad at all.
The 2,500th recorded contributor was Ryan Mast who brought pull-request 7809.
Thank you everyone who have helped us so far!
As can be seen on the graph below plotting the number of people in the THANKS file, the rate of newcomers have increased slowly over the years and we’ve added new names at the rate of about two hundred per year recently. There’s a chance that we will add the next 2,500 names to the list faster than twenty-four years. The latest 1,000 contributors have been added since the beginning of 2017, so in less than five years.
2,500 contributors to curl
The thanks page on the website is usually synced at release time so it is always a little bit behind compared to what’s recorded in the curl git repository.
2005
The graph bump back in 2005: it was a one-time sweep-up where I went through our entire history and made sure that all names of people who were previously mentioned and who had helped were added correctly to the document. Since then, we’ve kept better track and make sure to add new names as we go along.
Scripting
We of course collect the names of the contributors primarily by the use of scripts, which is also the best way to avoid some slipping through.
We always mention contributors and helpers in git commits, and they should be “marked” correctly for scripts to be able to extract them
We keep a list of contributors per-release in the RELEASE-NOTES document. When we commit updates to RELEASE-NOTES, we use the fixed commit message ‘synced’ to have our tools use that as a marker.
To get the updated list of contributors since the previous update of RELEASE-NOTES, we use the scripts/contributors.sh script.
For some TLS connections you want the secrets you exchange over them to remain private for decades to come.
So what if someone in the future produces a computer system that can crack all the common current encryption algorithms in no time and they already have past secret communications stored?
Such a possible future computer system that might do this is believed to be the quantum computer. There are early and tiny versions of such machines already in existence, but they are far from strong enough to be cracking any strong ciphers today. The question is then how long it takes until they will be able to do that, and thus for how long recorded secret communications can expect to remain secret. 10 years? 20? 30?
If there’s a capable quantum computer made available in let’s say twenty years time, our currently most common TLS ciphers are then rendered next to worthless in twenty years. If you want your communication to remain private even after the introduction of quantum computers, you need post-quantum safe algorithms for your TLS data, and you need a post-quantum curl to use those ciphers for your transfers!
Post-quantum TLS
My colleagues at wolfSSL have recently been working on making sure that the library with the same name has support for a set of ciphers that are post-quantum safe. That work has been merged into wolfSSL’s git repository and will be part of a future pending release. That “future release” is hopefully just a few weeks off now.
In association with that, we’ve also made sure that curl built with wolfSSL can take advantage of these powers. The necessary curl changes for this have landed in git and will be part of the pending curl 7.80.0 release.
Use it with curl
To make your curl transfers post-quantum safe today, all you need to do is:
make sure you have a wolfSSL build and install with the proper algorithms enabled
build curl from git (or wait for the 7.80.0 release) and tell it to use wolfSSL for TLS
specify a post-quantum curve when you invoke curl
Example
curl --curve SABER_LEVEL5 https://example.com
The success of such a TLS 1.3 handshake with a server then of course also requires that you communicate with a server that conversely also supports quantum-safe algorithms. This is not terribly common yet.
Credits
The primary curl pull-request for this feature was authored by Anthony Hu.
I work a lot on my own. I mean, I plan a lot of what to do on a daily basis myself, I execute a lot of it myself and I push my code and changes to various git repositories, often solo. I work quite a lot.
In a lot of the cases, I work together with one or more persons in each individual case, but very often that’s one or a few different persons involved in each and every one.
Yet I work at a company with colleagues, friends, managers and sales people who occasionally wonder what I’ve been up to recently and what I’m working on right now.
Weekly reports
To share information, to combat my feeling of working in complete solitude and to better sync work with colleagues, I’ve been sending out a weekly report every Friday. It briefly explains what I did this week, what I blogged about and what I’m up to the next week.
I’ve done this on and off since I joined wolfSSL, and a while ago it dawned on me that since I do most of my work on open source code and in general in the open, I could just as well just make my “reports” available to the entire world. Or rather: those who care and are interested can find them and read them!
Minor details are still hush hush
Since I do commercial curl work with and for other companies, I need to not spill the beans on things like actual secrets and most company names will be anonymized. I hope that won’t interfere too much.
GitHub
I decided to make it available on GitHub like this:
I’ve been traveling this road for a while. Here’s my collection of 15 of the most common mistakes and issues people will run into when writing applications and services that use libcurl. I’ve also done recorded presentations on this topic that you can watch if you prefer that medium.
Most of these issues are shared among application authors independently of what language the program is written in – as libcurl bindings tend to be very thin and more or less expose the API in the same way the C API does. Some mistakes are however C and C++ specific.
15 mistakes to look out for when using libcurl
1. Skipping the documentation!
Nothing in my list here is magic, hidden or unknown. Everything is documented and well-known. The by far most common mistakes are done by people not reading up, rushing a bit too fast and sometimes making a little too many assumptions. Of course there’s also occasional copy-and-pasting from bad examples going on. The web is full of questionable source snippets to get inspiration from.
We spend a significant amount of time and energy on making sure the documentation is accurate, detailed and thorough. Many mistakes can be avoided by simply reading up a little more first!
This sounds like such an obvious thing but we keep seeing this happen over and over again: users write code that uses libcurl functions but they don’t check the return codes.
If libcurl detects an error it will return an error code. Whenever libcurl doesn’t do what you expected it to do, it very often turns out to have returned an error code to the application that explains the behavior. We work hard at making sure libcurl functions return the correct return codes!
The libcurl examples we host on the curl web site (and ship in curl tarballs) are mostly done without error checks – for the sole purpose of making them smaller and easier to read as that removes code that isn’t strictly about libcurl.
3. Forgetting the verbose option
CURLOPT_VERBOSE is the libcurl user’s best friend. Whenever your transfer fails or somehow doesn’t do what you expected it to, switching on verbose mode should be one of the first actions as it often gives you a lot of clues about what’s going on under the hood.
Of course, you can also go further and use CURLOPT_DEBUGFUNCTION to get every more details, but usually you can save that for the more complicated issues.
libcurl will detect if you missed to call it, and then call it itself, but that’s not a practice we recommend since then you’ll have a harder time to do it thread-safe.
And there’s a corresponding curl_global_cleanup() to call when all your libcurl use is done.
5. Consider the redirects
HTTP/1.1 301 Moved Permanently Server: M4gic server/3000 Retry-After: 0 Location: https://curl.se/ Content-Length: 0 Accept-Ranges: bytes Date: Thu, 07 May 2020 08:59:56 GMT Connection: close
When you let libcurl handle redirects, consider limiting to what protocols you should allow redirects (CURLOPT_REDIR_PROTOCOLS), and of course you must remember that crafty users will figure out ways to redirect responses to potentially malicious servers given the chance.
Do not set custom HTTP methods on requests that follow redirects.
6. Let users set (parts of) the URL
Don’t do that. Unless you have considered the consequences and make sure you deal with them appropriately.
If you really insist that you need to let your users set the URL, restrict and carefully filter exact what parts and with what they can change it to.
The reason is of course that libcurl often supports other protocols than the one(s) you had in mind when you write your application. And users can do other crafty things to make host names point to other servers (which of course TLS based protocols will reject), abuse free-form URL input fields to pass on unexpected data (sometimes including newlines and other creative things) to your servers or have your application talk to malicious servers.
You can limit what protocols your application supports with CURLOPT_PROTOCOLS and you can parse URLs with the curl_url_set() function family before you pass them to curl to make sure given URLs make sense!
7. Setting HTTP method
Setting the custom HTTP request method with CURLOPT_CUSTOMREQUEST is most often done completely unnecessary, frequently causing problems and only very rarely actually done correctly.
The primarily problems with setting this option are:
if you also ask libcurl to follow redirects, this custom method will be used in follow-up requests as well, even if the server indicate wanting a different one in the HTTP response code
it doesn’t actually change libcurl’s behavior or expectations, it only changes the string libcurl sends in the request.
8. Disabled certificate checks
libcurl allows applications to disable TLS certificate checks with the two options CURLOPT_SSL_VERIFYPEER and CURLOPT_SSL_VERIFYHOST. This is powerful and at times very handy while developing and/or experimenting. It is also a very bad thing to ship in your product or deploy in your live service.
Disabling the certificate check effectively removes the TLS protection from the connections!
Searching for these option names using source code search engines or just on github will show you hundreds or thousands of applications that leave these checks disabled. Don’t be like them!
9. Assume zero terminated data in callbacks
libcurl has a series of different callbacks in its API. Some of these callbacks delivers data to the application and that data is then typically offered with a pointer and a size of that data.
The documentation very clearly stipulates that this data is not zero terminated – you cannot and should not use C functions on the data that works on “C strings” (that assume a terminating, trailing, zero byte). It seems especially common when the data that is delivered is something like HTTP headers, which is text based data and seems to lure people into assuming a zero terminator.
10. C++ strings are not C strings
libcurl is a C library with a C API for maximum portability and availability, yet a large portion of libcurl users are actually writing their programs in C++.
This is not a problem. You can use the libcurl API perfectly fine from C++.
Passing “strings” to libcurl must however be done with the C approach: you pass a pointer to a zero terminated buffer. If you pass a reference to a C++ string object, libcurl will not know what it is and it will not get or use the string correctly. It will fail in mysterious ways!
Something like this:
// Keep the URL as a C++ string object
std::string str("https://example.com/");
// Pass it to curl as a C string!
curl_easy_setopt(curl, CURLOPT_URL, str.c_str());
11. Threading mistakes
libcurl is thread-safe, but there are some basic rules and limitations that you need to follow and adhere to, as detailed in the document linked to:
if you use older TLS libraries, you must setup mutex locks
12. Understanding CURLOPT_NOSIGNAL
Signals is a Unix concept where an asynchronous notification is sent to a process or to a specific thread within the same process in order to notify it of an event that occurred.
What does libcurl use signals for?
When using the synchronous name resolver, libcurl uses alarm() to abort slow name resolves (if a timeout is set), which ultimately sends a SIGALARM to the process and is caught by libcurl
By default, libcurl installs its own sighandler while running, and restores the original one again on return – for SIGALARM and SIGPIPE.
Closing TLS (with OpenSSL etc) can trigger a SIGPIPE if the connection is dead.
Unless CURLOPT_NOSIGNAL is set! (default)
What does CURLOPT_NOSIGNAL do?
It prevents libcurl from triggering signals
When disabled, it prevents libcurl from installing its own sighandler and…
Generated signals must then be handled by the libcurl-using application itself
13. Forgetting -DCURL_STATICLIB
Creating and using libcurl statically is easy and convenient and seems especially popular on Windows
It requires the CURL_STATICLIB define to be set when building your application! This is a little unusual requirement and pattern which is probably why people often miss this.
Omission to use that define causes linker errors: “unknown symbol __imp__curl_easy_init”
This requirement is present because Windows need __declspec to be present or absent in the headers depending on how it links.
Static builds mean chasing deps
libcurl can use many 3rd party dependencies
When linking statically, all those need to be provided to the linker, so the curl build scripts (as well as your application linking) usually need manual help to find them all
14. C++ methods
C++ class methods look very much like functions, but C++ class methods cannot be used as callbacks with libcurl
… since they assume a ‘this’ pointer to the current object and a C program doesn’t pass on such a pointer.
Static class member functions work though. You can thus work around this limitation with a trick like this:
// f is the pointer to your object.
static size_t YourClass::func(void *buffer, size_t sz, size_t n, void *f){
// Call non-static member function.
static_cast(f)->nonStaticFunction();}
// This is how you pass pointer to the static function:
curl_easy_setopt(hcurl, CURLOPT_XFERINFOFUNCTION, YourClass::func);
curl_easy_setopt(hcurl, CURLOPT_XEFRINFODATA, this);
This callback might be called none, one, two or many times. Never assume you will get a certain amount of calls. The number of invokes is independent of the data amount and vary rather because of network, server, kernel or other reasons. Don’t assume the same invocation pattern will repeat!
September 25, 2001 is the official release date for Mac OS X 10.1. Exactly twenty years ago today.
Mac OS X 10.1
This was the first macOS release from Apple that bundled curl. It was a complete surprise to me as well when I realized this had happened. Nobody had told me about it ahead of time. I don’t even recall anymore how I figured this out, as I’m not a mac user and I’ve never had any direct contact with the peeps at Apple Inc who were and are responsible for shipping curl on that platform. Not before then and not after that either.
The general consensus at the time seemed to be that Apple replaced Wget with curl due to licensing reasons as Wget had been included in their previous OS X release. Wget is licensed under GPL and curl comes under an MIT-like license. I’m not sure if they shipped libcurl too already at that point.
Various Apple products have been using libcurl over the years on several of their operating systems.
We ship source, they build and ship binaries
Apple downloaded our source code tarball, built curl from it and shipped it. (They also made the exact code they used available.) If I remember this correctly, they built curl against OpenSSL and shipped a version of that as well in the beginning.
In later macOS releases (you know they later changed the name of their OS from being Mac OS X to macOS), they’ve switched curl to use different TLS backends over time. At one point they converted over to using Secure Transport (their own native TLS library) only to somewhat later switch again and then to libressl – which is what the current most recent macOS version uses for curl’s default TLS backend.
curl 7.7.2
The original cURL logo
The original curl version they bundled in that first release had been released by us in April earlier that same year. It was our 55th curl release but curl was only a little over three years old at the time. It was a young project and it was just in the beginning phase of what it would become.
Early, not first
Apple was certainly early with shipping curl bundled with their operating system but they were not first. curl was already then provided to several Linux distributions. Apple might’ve been one if the first to ship it by default though.
I remember that it felt awesome and as some sort of recognition and acknowledgement of what we’ve done.
Other operating systems
During the early 2000s lots of operating systems would ultimately one by one start to package and provide curl for their platforms. Linux distributions and BSD flavors of course, but soon the legacy Unixes would also follow. If it wasn’t offered by the primary vendor, third party providers would very soon offer packages,
iOS
The third party license screen in iOS (click on the image shown on the right here for the full resolution version) includes the curl license, showing that Apple use it in iPhones and iPads. I don’t know for what.
Releases
Apple has kept updating curl in their subsequent operating updates and has done a somewhat reasonable job at keeping up with our releases. In their most up-to-date macOS version 11.5.2 (release date: August 11, 2021) they ship curl 7.64.1, released from us on 2019-03-27. Our 181st release. It has twenty-two known vulnerabilities.
This can be compared to Windows 10 which keeps shipping OS updates very frequently but is seemingly stuck with curl 7.55.1, released in August 2017.
Futile attempts to help
For a while I reported security issues we found (that would be relevant) to Apple product security ahead of time before our releases went public, to give them time to react and ship fixes, the same way we send alerts to free operating systems.
I stopped doing that because 1. the Apple security people always complained on me for giving them too short time to react (something like two weeks, which is also the maximum notification time allowed by others) and 2. Apple never released any quick updates as a reaction to my notifications anyway. It took them months or years, making my efforts pointless. Basically they were just rude.
Nothing in return
Neither me personally nor the project have ever gotten anything or any compensation from Apple. Nothing. Nada. Perhaps Apple using curl early on was somewhat of a stamp of approval for some, which helped persuade others that curl is a tool to trust. Perhaps.
Apple has not sponsored the project, not paid for feature development, not helped us with hardware and never paid for support. They don’t cooperate with us to help us fix Apple-specific issues nor do they ever report problems to us (which we know they must find occasionally). Apple users who run into problems with curl on Apple’s operating systems regularly contact the curl project to get us to help fix Apple’s products. For free of course. We never even get a thank you.
I have a mac these days (purchased with my own money) that I use to debug and test mac-specific issues and problems on.
Apple is of course far from alone is this almost predatory behavior, but this post is about curl’s twenty years of serving Apple customers. Also: yes curl is open source and the license allows them to do this. We continue to ship a product that runs perfectly on macOS and other Apple operating systems. They continue to ship curl bundled with their operating systems.
Future
The curl project has no drastic course-altering changes planned ahead and we’re not going away, so I believe the tool and library have the potential to continue being used on Apple products going forward as well. Possibly for a long time ahead. I have zero knowledge or visibility into that, so it’s just guessing on my part based on what’s been done in the past twenty years.
In April 2019 we launched the current curl bug-bounty program under the Hackerone umbrella and from my point of view it has been nothing but a raging success. Until today we’ve paid almost 17,000 USD in rewards and and the average payment amount has been increasing all the time.
The reward money in this program have been paid to security reporters sourced from our own funds. Funds that have been donated to the curl project by our generous curl sponsors.
Before that day in 2019, when this program started, we did a few attempts to lean on and piggy-back on other bug-bounty efforts, but that never worked good enough. It mostly made the process unpredictable, outside of our control and ability to influence them and they never paid researchers “proper”.
We even started this latest program in association with a known brand company (that I won’t name here) who promised to chip-in and contribute money to the rewards whenever they would affect one of their use cases – but that similarly just ended up an empty promise for something that apparently never could happen. It feels much more honest and straight forward not giving anyone such false expectations – so they’re no longer involved here.
The original Internet Bug-Bounty
Another “failed program” from the past, at least as far as bounties for curl issues go, was the Hackerone driven bounty program known as IBB. It was an umbrella project to offer bounties for security problems in a set of “internet programs” including curl. I won’t bore you with details why that didn’t work. I think they paid some small bounties to two or three curl related issues.
IBB reborn but different now
The experience from all previous attempts and programs we’ve tried for bounties says that we need to be in control of what reported issues that are considered security related problems and I think it is important that we reward all such issues, without discrimination or other conditions. If the issue is indeed a security problem, then we appreciate getting told about it and we reward the person who did the job, figured it out and told us.
Therefore, skepticism was the initial response I felt when I was briefed about the re-introduction, rebirth if you want, of the IBB program. We’ve been there, we tried that.
But after talking to the people involved, I was subsequently convinced that we should give this effort a chance. There are several reasons that made me think this time can be different, to our benefit. They include:
The IBB program will pay the rewards from their funds, and they will do their own fund raising and “pester “big companies to help out, thus either entirely or mostly remove the need for us to fund the rewards or at least make our spending smaller. Or the rewards larger.
The members of the curl security team will still work with reported issues the exact same way as before and our security team will remain the sole arbiters of what problems that are in-scope and what problems that are not for issues reported on curl. We’ve established a decent working method for that over the last two something years and I feel good about us sticking to this. The IBB program is mostly involved at the end of the process when the reward amount and payout are handled.
We stick to mostly the same work-flow and site for reporting issues and communicating with reporters while the issues are in the initial non-disclosed state. Namely within the nicely working Hackerone issue tracker, which is designed and made specifically for this purpose.
Evaluation
We have not signed up for this new way of doing things for life. If it turns out that it is bad somehow for the curl project or for security researchers filing problems about curl, then we can always just backpedal back to the previous situation and continue as before.
This should be a fairly harmless test and change of process that should be an improvement for us as otherwise we won’t stick to it!
Within 24 hours of the previous release, 7.79.0, we got a bug-report filed that identified a pretty serious regression in the HTTP/2 code that we deemed required a fairly quick fix instead of waiting a full release cycle for it.
So here’s 7.79.1 with several bug-fixes that we managed to queue up and merge in the seven days since the previous release. Enjoy
Release presentation
Numbers
the 203rd release 0 changes 7 days (total: 8,587) 10 bug-fixes (total: 7,280) 17 commits (total: 27,668) 0 new public libcurl function (total: 85) 0 new curl_easy_setopt() option (total: 290) 0 new curl command line option (total: 242) 11 contributors, 5 new (total: 2,489) 3 authors, 0 new (total: 948) 0 security fixes (total: 111) 0 USD paid in Bug Bounties (total: 16,900 USD)
Bug-fixes
This was a very short release cycle but there were two rather annoying bugs fixed and we also managed to get a few other corrections merged since they arrived perfectly timed…
HTTP/2: don’t change connection data
For one of the HTTP/2 fixes I was happy to land for 7.79.0 I overdid it a little and change a few lines too many. This caused my previous “fix” to also break common use cases and I had to follow up with this additional fix.
The reason this bug managed to sneak in, is that we don’t have test cases exercising this code path that depends on multiple concurrent HTTP/2 streams over a single connection.
fix the broken >3 digit HTTP response code detection
Probably the second worst bug and regression added in the previous release. When I made the HTTP/1 response code parser stricter and made it allow no more than three digits I messed up my sscanf() fu and forgot that %d also skips leading space. This made curl treat responses that had a fine response code that were followed by a leading digit in the “reason phrase” field get detected as badly formatted and rejected! Now we have test cases verifying this.
curl_multi_fdset: make FD_SET() not operate on sockets out of range
This function would wrongly skip the check for a too large file descriptor if libcurl was built to use poll(), which in this case was a totally unrelated and wrong check. Unfortunately, we don’t (yet) have test cases to catch FD_SETSIZE issues.
provide lib/.checksrc in the tarball
When you build curl with --enable-debug or otherwise run ‘make checksrc’, the code style is changed and due to this missing control file, it would erroneously report an error. The error happened because within a source file a specific checksrc-warning is disabled, but since lib/.checksrc was missing the warning was never enabled in the first place and this discrepancy was not allowed. We didn’t catch this before release because we don’t test-build release tarballs with debug enabled in the CI…
CURLSTS_FAIL from hsts read callback should fail transfer
libcurl didn’t properly handle this return code from the HSTS read callback. Instead of failing the transfer it would just continue! Now we have test cases verifying this.
handle unlimited HSTS expiry
When using HSTS and passing in an entry to libcurl that you specify should never expire, libcurl would pass that the maximum time_t value as an argument to the gmtime() function. The problem is then just that on 64 bit systems, the largest possible time_t value is so big that when converted into a struct tm, the number of years would still overflow the year struct field! This causes the function to return a NULL and libcurl would misbehave. Now we have test cases verifying this.
use sys_errlist instead of strerror on Windows
Another little fix to avoid strerror() on Windows as well where it also is documented as not thread-safe.
make the ssh tests work with openssh-8.7p1
The test suite fired up openssh for testing purposes in a way that no longer is accepted by this OpenSSH version.
Next
We will not change the schedule for next release due to this patch version. It means that the next feature window will instead be one week shorter than usual and that the next release remains set to get released on November 10, 2021.
WebSockets has been one of the most requested features and protocol to add to curl and libcurl in the annual user survey. Repeatedly, over the last few years.
WebSockets is not perfectly suitable to be done by libcurl since it’s not really an upload or download transfer protocol, but is more something like “a TCP for JavaScript”. It provides a bidirectional data stream over HTTP. (I was there when it was created, first mentioned on my blog here.)
Ignoring that technicality, WebSockets is often used more or less for a one-directional data stream. Commonly together with the use of other protocols that curl already supports. If libcurl would support it, there will be plenty of applications out there that could simplify their code.
Today, users use a mix of libcurl, custom code on top or “over” libcurl and other WebSockets libraries. There’s no single de-facto way or practice to do WebSockets with libcurl.
WebSockets for libcurl?
I took the topic of drafting a WebSockets API for libcurl to the libcurl mailing list a while ago and after a lot of back and forths and feedback from multiple people, we have a decent beginning of a WebSockets API that might work jotted down.
This is just a potential API described in a document. How it could be made to work. Nobody has actually implemented any of it.
Implement?
We know users ask for WebSockets, repeatedly and several people helped contributing to the tentative API design.
It’s just that this time I decided to pause and see if I couldn’t get some help in implementing this. To create a team of implementers willing to work before I dive in, alternatively to find someone who’d sponsor this work to allow me to spend more and dedicated time on it. I decided to do this, because I already have a lot of other things on my plate and I have to focus on my paying (curl) customers. I estimate that implementing WebSockets support is quite a lot of work.
If nobody is willing to put in the work or money to make it happen, then maybe that’s rather clear message that this is not a feature that is meant to be provided by curl. At least not now.
WebSockets future
WebSockets was created in the HTTP/1.1 era, and is probably still mostly done using that protocol as bootstrap. There are indications hinting that the future might hold less WebSockets.
It took a long time but eventually a way to do WebSockets over HTTP/2 was provided via RFC 8441, “Bootstrapping WebSockets with HTTP/2”, published in 2018. This allows a WebSockets connection to be done over a single HTTP/2 stream.
The next evolutionary step seems to rather be WebTransport. It is a new take and protocol and is meant to be used over HTTP/3 and QUIC. It is described to “send data to and receive data from servers. It can be used like WebSockets but with support for multiple streams, unidirectional streams, out-of-order delivery, and reliable as well as unreliable transport.”
The curl factory has once again cranked out a new curl release.
Release presentation
Numbers
the 202nd release 3 changes 56 days (total: 8,580) 128 bug-fixes (total: 7,270) 186 commits (total: 27,651) 0 new public libcurl function (total: 85) 0 new curl_easy_setopt() option (total: 290) 0 new curl command line option (total: 242) 62 contributors, 25 new (total: 2,484) 41 authors, 16 new (total: 948) 3 security fixes (total: 111) 3,500 USD paid in Bug Bounties (total: 16,900 USD)
Security
This time we once again announce security advisories in association with the release.
CVE-2021-22945 is a double-free flaw in the MQTT code. Patch your old curl or upgrade to this version if you use it to send MQTT. The reporter of this flaw was awarded 1,000 USD from the curl bug-bounty program.
CVE-2021-22946 is a bug in response handling for several protocols (IMAP, POP3 and FTP) that bypasses the enforced TLS check so that even transfers that are explicitly told to require TLS can accidentally silently be performed in clear text! Rewarded 1,000 USD.
CVE-2021-22947 allows a mitm attacker to inject data into the protocol stream for FTP, IMAP, POP3 or SMTP in a way before the TLS upgrade so that curl accepts that data and uses it after after having upgraded to TLS. The untrusted data slips in and gets treated as trusted! Rewarded 1,500 USD.
These two latter ones came as an indirect result/inspiration from the NO STARTTLS research.
Changes
This release comes with three changes to take note of…
Users of the bearssl TLS backend will appreciate that it too now supports the CURLOPT_CAINFO_BLOB option so that the CA certificate easily can be provided in-memory by applications.
The cookie engine in curl now considers http://localhost to be secure and thus cookies that are marked “secure” will be sent over it – even when not using HTTPS. This is done because curl now since a while back makes sure that localhost is always truly local.
Users of the Secure Transport TLS backend can now use CURLINFO_CERTINFO to extract information about the server’s certificate chain.
Bug-fixes
Some of the most interesting bug-fixes we did this round.
use ares_getaddrinfo()
When you build curl to use the c-ares name resolver backend, curl will now use this function to get improved handling for IPv4+ IPv6. This also ups our requirement on c-ares to 1.16.0.
hyper works better
1xx responses, Transfer-Encoding and more have been fixed. The number of tests that are disabled for hyper builds are even fewer than before, but there’s still plenty of work to do before it can be considered not experimental.
cmake builds: avoid poll() on macOS
We have deliberately not used poll() in macOS builds for a long time when building with configure, and now we realized that cmake builds inadvertently had poll() use enabled, which caused curl to misbehave when for example connecting to a host while that connection got closed by the peer. poll() is now disabled on macOS even when cmake is used.
configure: also check lib64 for the OpenSSL pkg-config file
OpenSSL did a very late change just before they shipped version 3.0.0: they modified the default installation path for the library for 64 bit systems from $prefix/lib to $prefix/lib64, and subsequently we had to update our configure script detection logic accordingly. This helps configure to find OpenSSL v3 installs.
curl.1: provide examples for each option
The documentation now must provide at least one example command line for each command line option curl provides. This is verified in the build and will cause build errors if a file doesn’t comply! Feel free to suggest new, more or better examples when you start to see them in the man page.
HTTP 1.1: disallow >3-digit response codes
The HTTP protocol is defined to only allow three-digit numbers and now curl enforces that check stricter. This was in part made to align behavior when curl is built to use hyper.
HTTP 1.1: ignore content-length if any transfer-encoding is used
Non-chunked transfer-encoded content that also sends Content-Length headers is rare but was incorrectly handled by curl. Found when aligning behavior with hyper builds.
http_proxy: only wait for writable socket while sending request
Due to a mistake in the handling of what socket activity to wait for, curl could accidentally be made to busy-loop from the CONNECT request was sent to the proxy until the first data arrived.
Support mbedTLS 3.0.0
When mbedTLS released a new version with support for TLS 1.3 etc, they also modified the API a bit.
Ban strerror
We’ve had our own internal strerror replacement function for a long time (primarily due to it not being thread-safe), but a recent code review revealed that a lot of uses of this function had still crept in. Starting now, our code check tool (checksrc) will error if strerror is used in libcurl code.
The mailing lists move from cool.haxx.se to lists.haxx.se
Our old decommissioned server hosted 29 mailing lists. We moved most of them and killed off a few. All our mailing lists are now hosted on lists.haxx.se, including all the curl related ones of course! The old server name will simply redirect to the new one if you go there with a browser.
There’s a plan for version 8 being forged! Let me just take you back a bit in time first..
The early days
When we first created libcurl, we bumped the major version number of the project from the previous version 6 to version 7. In late summer of 2000 we shipped curl and libcurl 7.1 as the first ever release that featured a separate library for Internet transfer powers. Everything before version 7 was just the command line tool, curl. That was the moment in time we decided we should leave kindergarten and we were ready to take on some tougher loads.
I had the main approach to the API worked out already from the start. It would be transfer-oriented, it would be built up around URLs and shouldn’t necessarily require that the users are themselves protocol experts to use it. I used inspiration from ioctl and fcntl when I made curl_easy_setopt and curl_easy_getinfo. They’re fixed functions with flexible arguments. The idea was that by doing that, we wouldn’t have to add new functions for new features but we would “just” add options and new options would simply just not work with older libcurls.
The first API we shipped also only provided synchronous single transfers. The “easy” interface.
I had no anticipations or particular hopes on the library then. It would be cool if someone found good use for it and it would be even cooler if someone would help out to improve it further.
It grew, I learned
I had never before developed and shipped a library for the world to use. I hadn’t really fully grasped and considered the impact of APIs and ABI stability etc.
We gradually improved the library over time. We bumped the SONAME several times in the first few years as we modified internals. In the same time the library caught on a bigger and bigger audience and in September 2006 as I ripped out code for what is commonly referred to as “FTP third party transfers” I once again bumped the ABI number (to 4) since the older libcurl was no longer compatible with the new release.
People don’t like SONAME bumps
That bump was met with quite a lot of resistance and objections among users. Changing SONAME of a widely used library it turns out causes a lot of pain, agony and squeaking. Possibly this was one of the earlier signs that libcurl had grown up and I decided that we should try to avoid going through this again. We shall not break ABI compatibility again. Ever.
No bumps, no worries
In this world with no SONAME bumps I wanted to keep that solidity visible in the major number of the project so even though the version number of the releases aren’t strictly related to the SONAME we kept shipping curl version seven. In September 2021, we reach curl 7.79.0.
We’ve managed to stick to our goals and a binary libcurl using application built after September 2006 can run with the latest libcurl with no modification needed! This is one of the biggest edges and “selling points” we have in libcurl: We take compatibility and unmodified behavior very seriously.
We bump the minor version number every time we “change” something in the project, or add features. If we only do bug-fixes we only bump the patch number. You know, in classic “major,minor.patch” style.
As we do curl releases at least every 8 weeks and most releases have changes added, we bump the minor number very frequently, up to 6 times a year or so.
We provide version number information for libcurl provided as a 24 bit number, using 8 bits for each field. This implies that none of the numbers can ever go above 255. We can’t ship a 7.256.0 for this practical reason.
But also, from what I’ve seen people do with and think about version numbers before, I’m concerned that increasing the minor number beyond 99 will cause confusions. Version 7.100.0 risks gettinged confused and mixed up with 7.1 or 7.10.0, two versions that are terribly old. And frankly that’s a very large minor number and it starts becoming many digits in that release version.
There exists a solution to this!
Reset minor, bump major, keep SONAME
The idea is simply to do “a Linux kernel”. We change to version 8.0.0 at a given point in time, but we stick to the same SONAME as before.
We don’t break any compatibility, there will no no API or functionality cleanups. There will just be a version number bump to lower the minor number and let us start over that journey. Reset the counter so to speak.
When do we do this? We have roughly 20 releases left before the minor counter can reach 100, 20 releases take at least 6*20 = 120 weeks. 120 weeks is 2.3 years.
Another event within this period
On March 20, 2023. About 18 months into the future, the curl project turns 25 years old. Here’s a golden opportunity! Let’s top off the 25 year celebrations with a major version number bump!
The plan
Independently of what version number we have reached to at that point, independently of if we add features or not in that release, independently of exactly how that date fits within the pre-determined release cycle and without changing any APIs, we ship curl version 8.0.0 on that day.
Turning 25 and bumping the major version number on the same day should be fun.
Version 8
I hope that a small side-effect of bumping the major number will make users still left on version 7 to slightly faster feel outdated and push for getting up to 8. It could work as a minor push to get users to catch up a bit.
The minor number will of course immediately start “climbing” again and in a worst-case scenario, we risk reaching minor number 100 again within another 17 years. Maybe we can plan another bump for the 40th birthday?