--proxy-basic has no short option. This option is closely related to the option --proxy-user, which has as separate blog post.
This option has been provided and supported since curl 7.12.0, released in June 2004.
Proxy
In curl terms, a proxy is an explicit middle man that is used to go through when doing a transfer to or from a server:
curl <=> proxy <=> server
curl supports several different kinds of proxies. This option is for HTTP(S) proxies.
HTTP proxy authentication
Authentication: the process or action of proving or showing something to be true, genuine, or valid.
When it comes to proxies and curl, you typically provide name and password to be allowed to use the service. If the client provides the wrong user or password, the proxy will simply deny the client access with a 407 HTTP response code.
curl supports several different HTTP proxy authentication methods, and the proxy can itself reply and inform the client which methods it supports. With the option of this week, --proxy-basic, you ask curl to do the authentication using the Basic method. “Basic” is indeed very basic but is the actual name of the method. Defined in RFC 7616.
Security
The Basic method sends the user and password in the clear in the HTTP headers – they’re just base64 encoded. This is notoriously insecure.
If the proxy is a HTTP proxy (as compared to a HTTPS proxy), users on your network or on the path between you and your HTTP proxy can see your credentials fly by!
If the proxy is a HTTPS proxy however, the connection to it is protected by TLS and everything is encrypted over the wire and then the credentials that is sent in HTTP are protected from snoopers.
Also note that if you pass in credentials to curl on the command line, they might be readable in the script where you do this from. Or if you do it interactively in a shell prompt, they might be viewable in process listings on the machine – even if curl tries to hide them it isn’t supported everywhere.
Example
Use a proxy with your name and password and ask for the Basic method specifically. Basic is also the default unless anything else is asked for.
With --proxy you specify the proxy to use, and with --proxy-user you provide the credentials.
Also note that you can of course set and use entirely different credentials and HTTP authentication methods with the remote server even while using Basic with the HTTP(S) proxy.
There are also other authentication methods to selected, with --proxy-anyauth being a very practical one to know about.
When I wrote up my looong blog post for the curl’s 22nd anniversary, I vacuumed my home directories for all the leftover scripts and partial hacks I’d used in the past to produce graphs over all sorts of things in the curl project. Being slightly obsessed with graphs, that means I got a whole bunch of them.
I made graphs with libreoffice
I dusted them off and made sure they all created a decent CSV output that I could use. I imported that data into libreoffice’s calc spreadsheet program and created the graphs that way. That was fun and I was happy with the results – and I could also manually annotate them with additional info. I then created a new git repository for the purpose of hosting the statistics scripts and related tools and pushed my scripts to it. Well, at least all the ones that seemed to work and were the most fun.
Having done the hard work once, it felt a little sad to just have that single moment snapshot of the project at the exact time I created the graphs, just before curl’s twenty-second birthday. Surely it would be cooler to have them updated automatically?
How would I update them automatically?
I of course knew of gnuplot since before as I’ve seen it used elsewhere (and I know its used to produce the graphs for the curl gitstats) but I had never used it myself.
How hard can it be?
I have a set of data files and there’s a free tool available for plotting graphs – and one that seems very capable too. I decided to have a go.
Of course I struggled at first when trying to get the basic concepts to make sense, but after a while I could make it show almost what I wanted and after having banged my head against it even more, it started to (partially) make sense! I’m still a gnuplot rookie, but I managed to tame it enough to produce some outputs!
The setup
I have a set of (predominantly) perl scripts that output CSV files. One output file for each script basically.
The statistics scripts dig out data using git from the source code repository and meta-data from the web site repository, and of course process that data in various ways that make sense. I figured a huge benefit of my pushing the scripts to a public repository is that they can be reviewed by anyone and the output should be possible to be reproduced by anyone – or questioned if I messed up somewhere!
The CSV files are then used as input to gnuplot scripts, and each such gnuplot script outputs its result as an SVG image. I selected SVG to make them highly scalable and yet be fairly small disk-space wise.
Different directory names
To spice things up a little, I decided that each new round of generated graph images should be put in a newly created directory with a random piece of string in its name. This, to make sure that we can cache the images on the curl web site very long and still not have a problem when we update the dashboard page on the site.
Automation
On the web site itself, the update script runs once every 24 hours, and it first updates its own clone of the source repo, and the stats code git repo before it runs over twenty scripts to make CSV files and the corresponding SVGs.
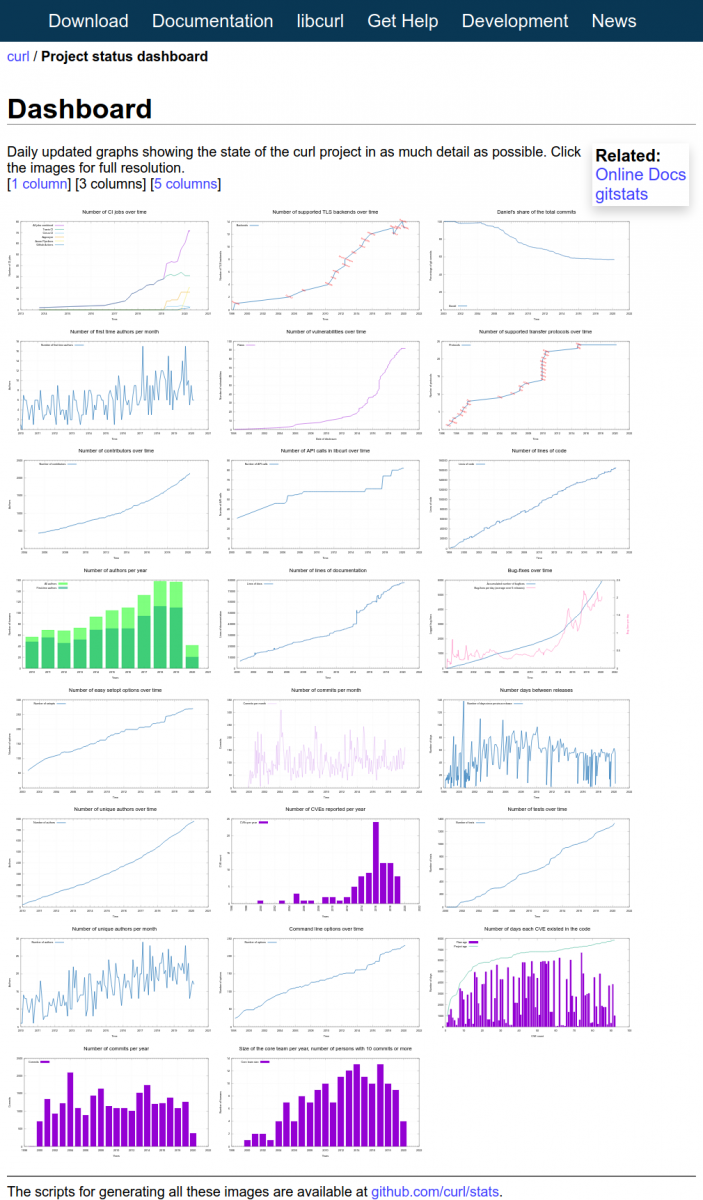
A dashboard
I like to view the final results as a dashboard. With over 20 up-to-date graphs showing the state of development, releases, commits, bug-fixes, authors etc it truly gives the reader an idea of how the project is doing and what the trends look like.
I hope to keep adding to and improving the graphs over time. If you have ideas of what to visualize and add to the collection, by all means let me know!
Screenshot
At the time of me writing this, the dashboard page looks like below. Click the image to go to the live dashboard.
For other projects?
Nothing in this effort makes my scripts particularly unique for curl so they could all be used for other projects as well – with little to a lot of hands on required. My data extraction scripts of course get and use data that we have stored, collected and keep logged in the project etc, and that data and those logs are highly curl specific.
--retry-max-time has no short option alternative and it takes a numerical argument stating the time in seconds. See below for a proper explanation for what that time is.
Retrying
curl supports retrying of operations that failed due to “transient errors”, meaning that if the error code curl gets signals that the error is likely to be temporary and not the fault of curl or the user using curl, it can try again. You enable retrying with --retry [tries] where you tell curl how many times it should retry. If it reaches the maximum number of retries with a successful transfer, it will return error.
A transient error can mean that the server is temporary overloaded or similar, so when curl retries it will by default wait a short while before doing the next “round”. By default, it waits one second on the first retry and then it doubles the time for every new attempt until the waiting time reaches 10 minutes which then is the max waiting time. A user can set a custom delay between retries with the --retry-delay option.
Transient errors
Transient errors mean either: a timeout, an FTP 4xx response code or an HTTP 408 or 5xx response code. All other errors are non-transient and will not be retried with this option.
Retry no longer than this
Retrying can thus go on for an extended period of time, and you may want to limit for how long it will retry if the server really doesn’t work. Enter --retry-max-time.
It sets the maximum number of seconds that are allowed to have elapsed for another retry attempt to be started. If you set the maximum time to 20 seconds, curl will only start new retry attempts within a twenty second period that started before the first transfer attempt.
If curl gets a transient error code back after 18 seconds, it will be allowed to do another retry and if that operation then takes 4 seconds, there will be no more attempts but if it takes 1 second, there will be time for another retry.
Of course the primary --retry option sets the number of times to retry, which may reach the end before the maximum time is met. Or not.
Retry-After:
Since curl 7.66.0 (September 2019), the server’s Retry-After: HTTP response header will be used to figure out when the subsequent retry should be issued – if present. It is a generic means to allow the server to control how fast clients will come back, so that the retries themselves don’t become a problem that causes more transient errors…
–retry-connrefused
In curl 7.52.0 curl got this additional retry switch that adds “connection refused” as a valid reason for doing a retry. If not used, a connection refused is not considered a transient error and will cause a regular error exit code.
Related options
--max-time limits the entire time allowed for an operation, including all retry attempts.
tldr: join in and watch/discuss the curl 2020 roadmap live on Thursday March 26, 2020. Sign up here.
The roadmap is basically a list of things that we at wolfSSL want to work on for curl to see happen this year – and some that we want to mention as possibilities.(Yes, the word “webinar” is used, don’t let it scare you!)
If you can’t join live, you will be able to enjoy a recorded version after the fact.
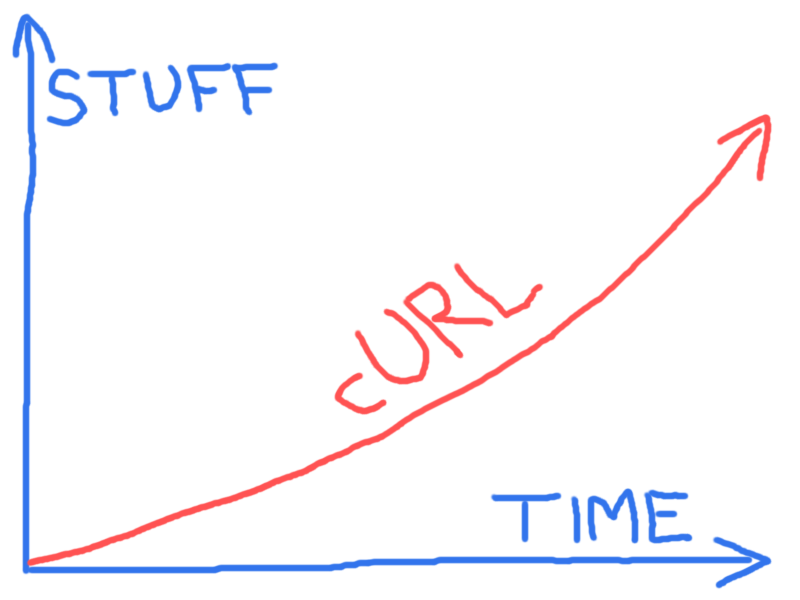
I shown the image below in curl presentation many times to illustrate the curl roadmap ahead:
The point being that we as a project don’t really have a set future but we know that more things will be added and fixed over time.
Daniel, wolfSSL and curl
This is a balancing act where there I have several different “hats”.
I’m the individual who works for wolfSSL. In this case I’m looking at things we at wolfSSL want to work on for curl – it may not be what other members of the team will work on. (But still things we agree are good and fit for the project.)
We in wolfSSL cannot control or decide what the other curl project members will work on as they are volunteers or employees working for other companies with other short and long term goals for their participation in the curl project.
We also want to try to communicate a few of the bigger picture things for curl that we want to see done, so that others can join in and contribute their ideas and opinions about these features, perhaps even add your preferred subjects to the list – or step up and buy commercial curl support from us and get a direct-channel to us and the ability to directly affect what I will work on next.
As a lead developer of curl, I will of course never merge anything into curl that I don’t think benefits or advances the project. Commercial interests don’t change that.
Webinar
Sign up here. The scheduled time has been picked to allow for participants from both North America and Europe. Unfortunately, this makes it hard for all friends not present on these continents. If you really want to join but can’t due to time zone issues, please contact me and let us see what we can do!
curl turns twenty-two years old today. Let’s celebrate this by looking at its development, growth and change over time from a range of different viewpoints with the help of graphs and visualizations.
This is the more-curl-graphs-than-you-need post of the year. Here are 22 pictures showing off curl in more detail than anyone needs.
I founded the project back in the day and I remain the lead developer – but I’m far from alone in this. Let me take you on a journey and give you a glimpse into the curl factory. All the graphs below are provided in hires versions if you just click on them.
Below, you will learn that we’re constantly going further, adding more and aiming higher. There’s no end in sight and curl is never done. That’s why you know that leaning on curl for Internet transfers means going with a reliable solution.
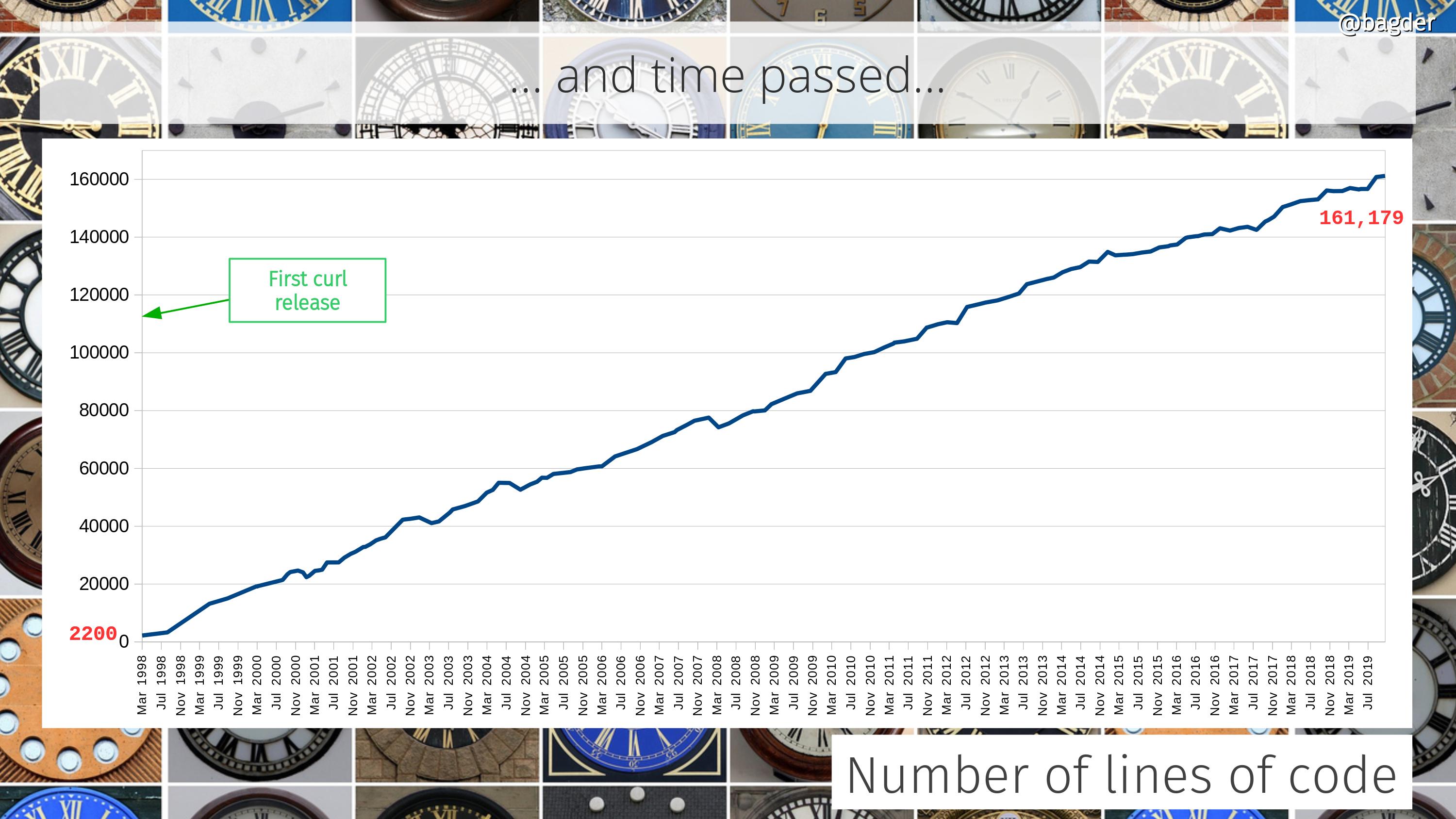
Number of lines of code
Counting only code in the tool and the library (and public headers) it still has grown 80 times since the initial release, but then again it also can do so much more.
At times people ask how a “simple HTTP tool” can be over 160,000 lines of code. That’s basically three wrong assumptions put next to each other:
curl is not simple. It features many protocols and fairly advanced APIs and super powers and it offers numerous build combinations and runs on just all imaginable operating systems
curl supports 24 transfer protocols and counting, not just HTTP(S)
curl is much more than “just” the tool. The underlying libcurl is an Internet transfer jet engine.
How much more is curl going to grow and can it really continue growing like this even for the next 22 years? I don’t know. I wouldn’t have expected it ten years ago and guessing the future is terribly hard. I think it will at least continue growing, but maybe the growth will slow down at some point?
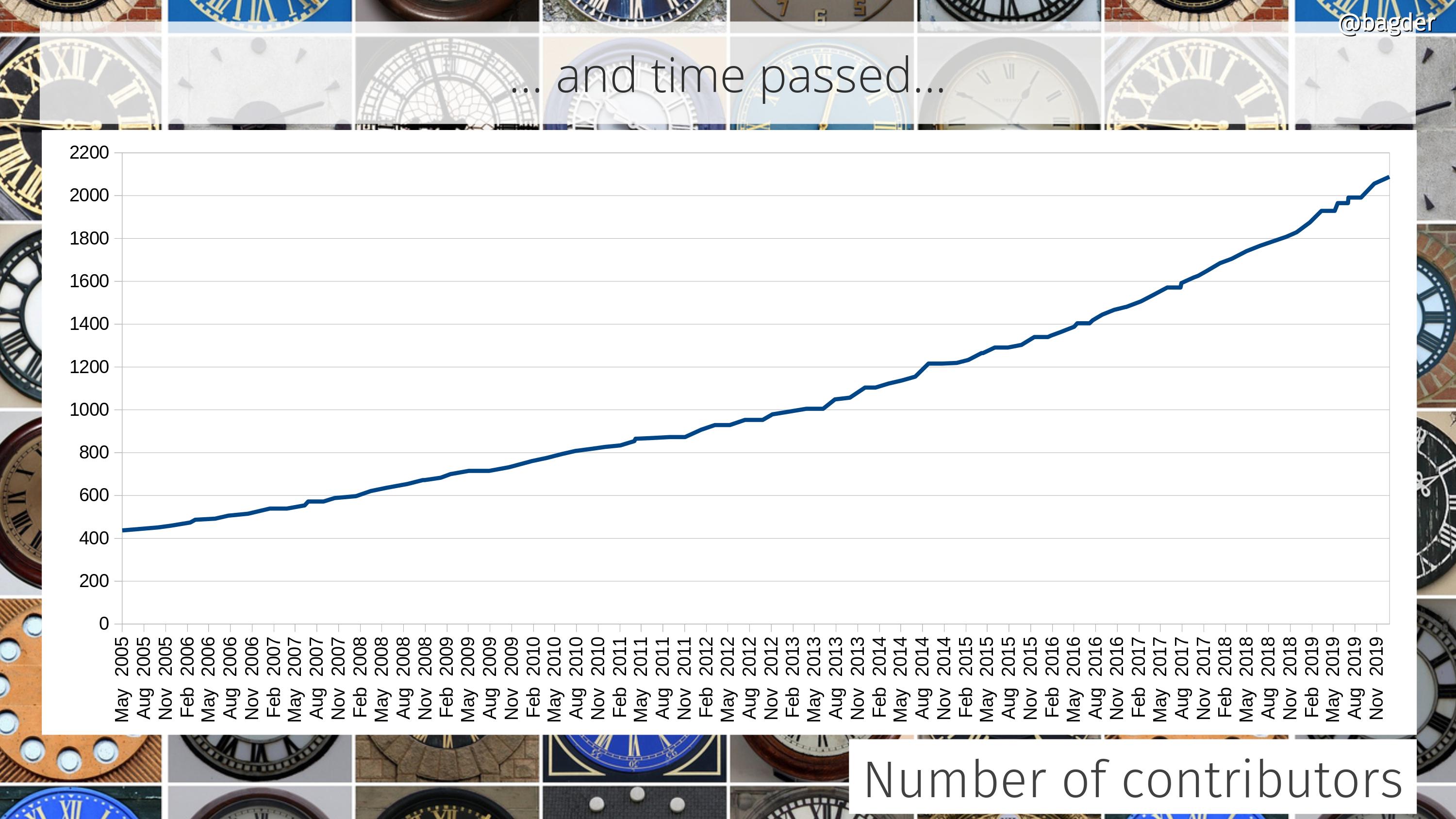
Number of contributors
Lots of people help out in the project. Everyone who reports bugs, brings code patches, improves the web site or corrects typos is a contributor. We want to thank everyone and give all helpers the credit they deserve. They’re all contributors. Here’s how fast our list of contributors is growing. We’re at over 2,130 names now.
When I wrote a blog post five years ago, we had 1,200 names in the list and the graph shows a small increase in growth over time…
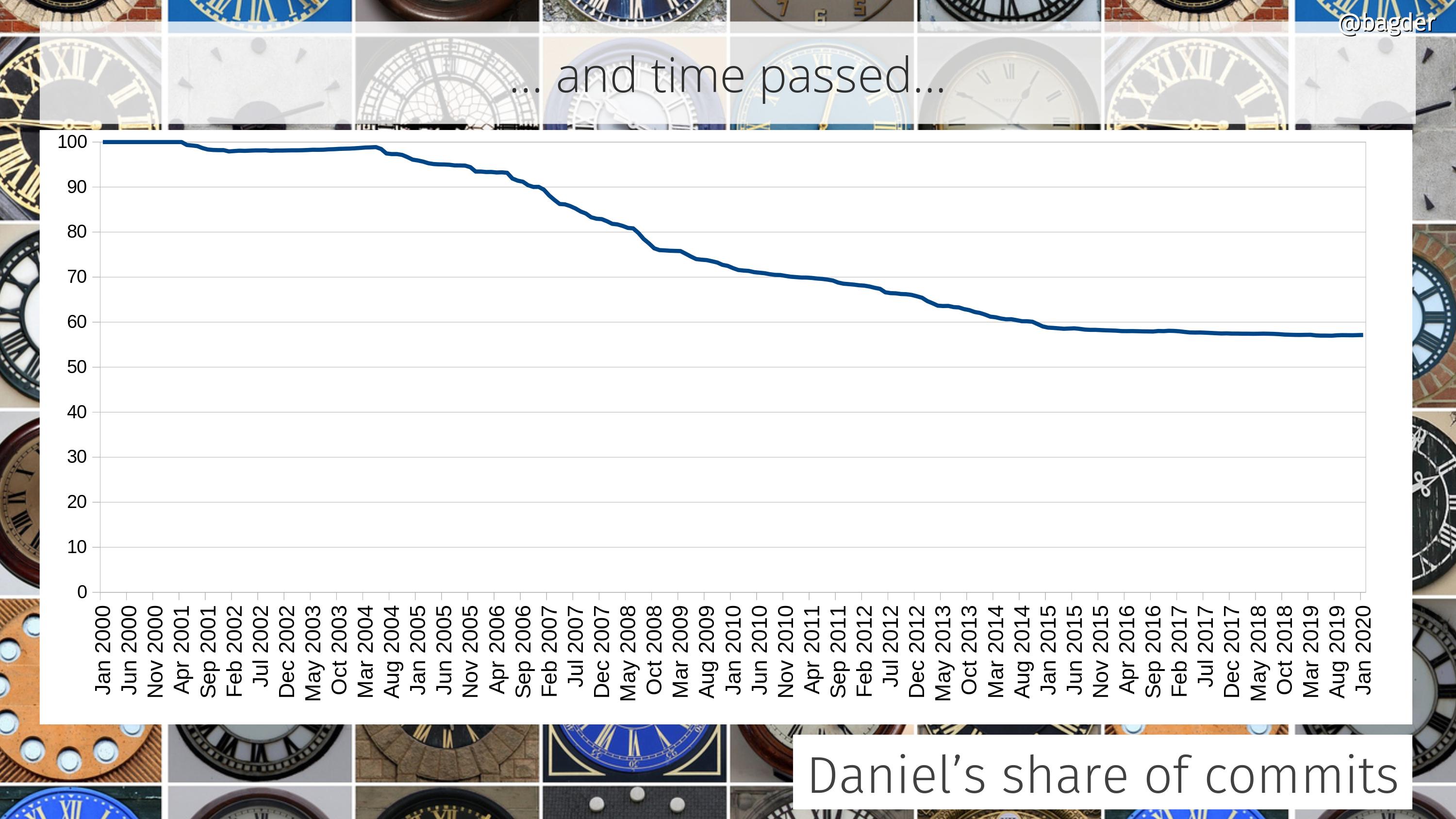
Daniel’s share of total commits
I started the project. I’m still very much involved and I spend a ridiculous amount of time and effort in driving this. We’re now over 770 commits authors and this graph shows how the share of commits I do to the project has developed over time. I’ve done about 57% of all commits in the source code repository right now.
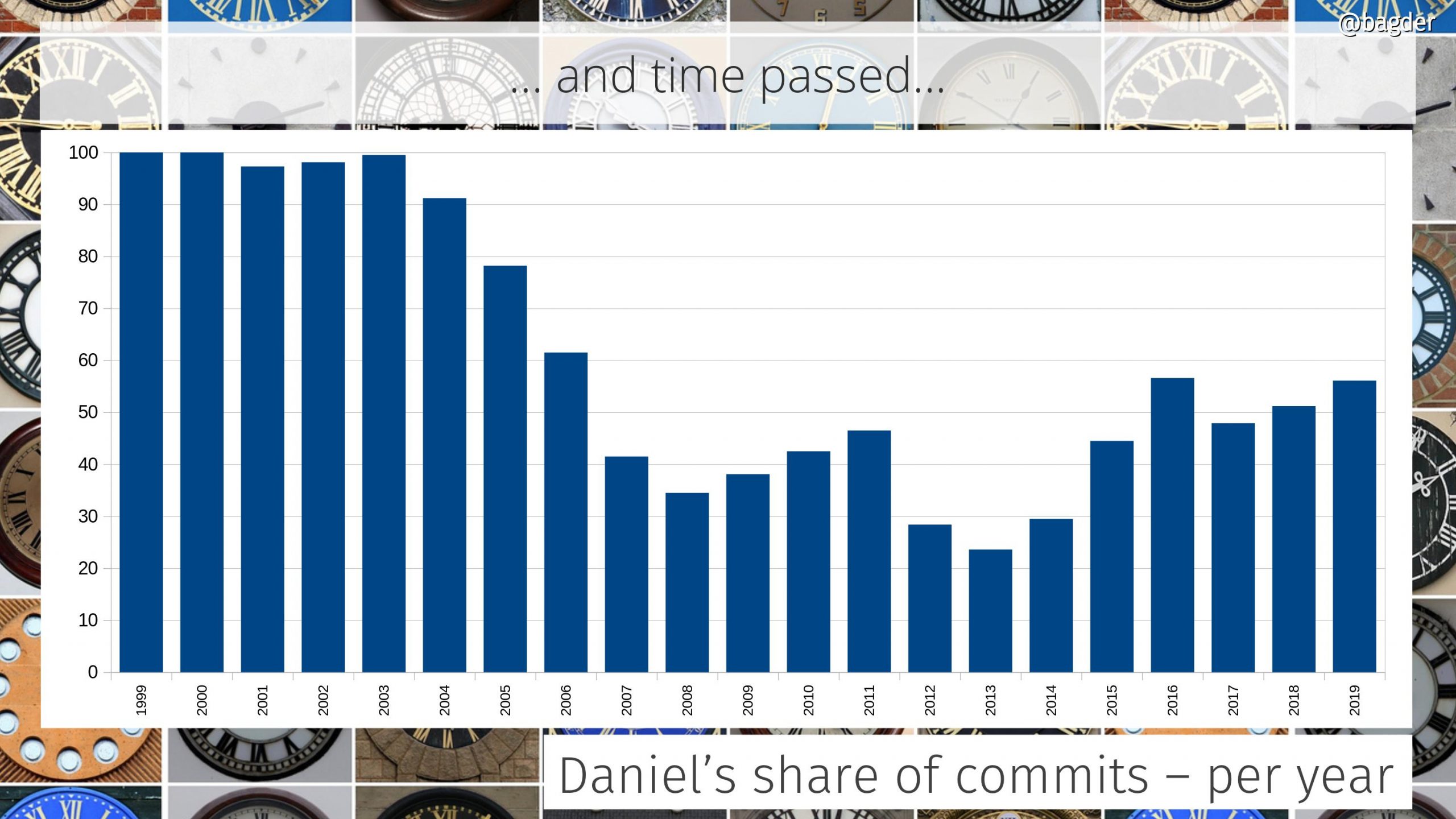
The graph is the accumulated amount. Some individual years I actually did far less than 50% of the commits, which the following graph shows
Daniel’s share of commits per year
In the early days I was the only one who committed code. Over time a few others were “promoted” to the maintainer role and in 2010 we switched to git and the tracking of authors since then is much more accurate.
In 2014 I joined Mozilla and we can see an uptake in my personal participation level again after having been sub 50% by then for several years straight.
There’s always this argument to be had if it is a good or a bad sign for the project that my individual share is this big. Is this just because I don’t let other people in or because curl is so hard to work on and only I know my ways around the secret passages? I think the ever-growing number of commit authors at least show that it isn’t the latter.
What happens the day I grow bored or get run over by a bus? I don’t think there’s anything to worry about. Everything is free, open, provided and well documented.
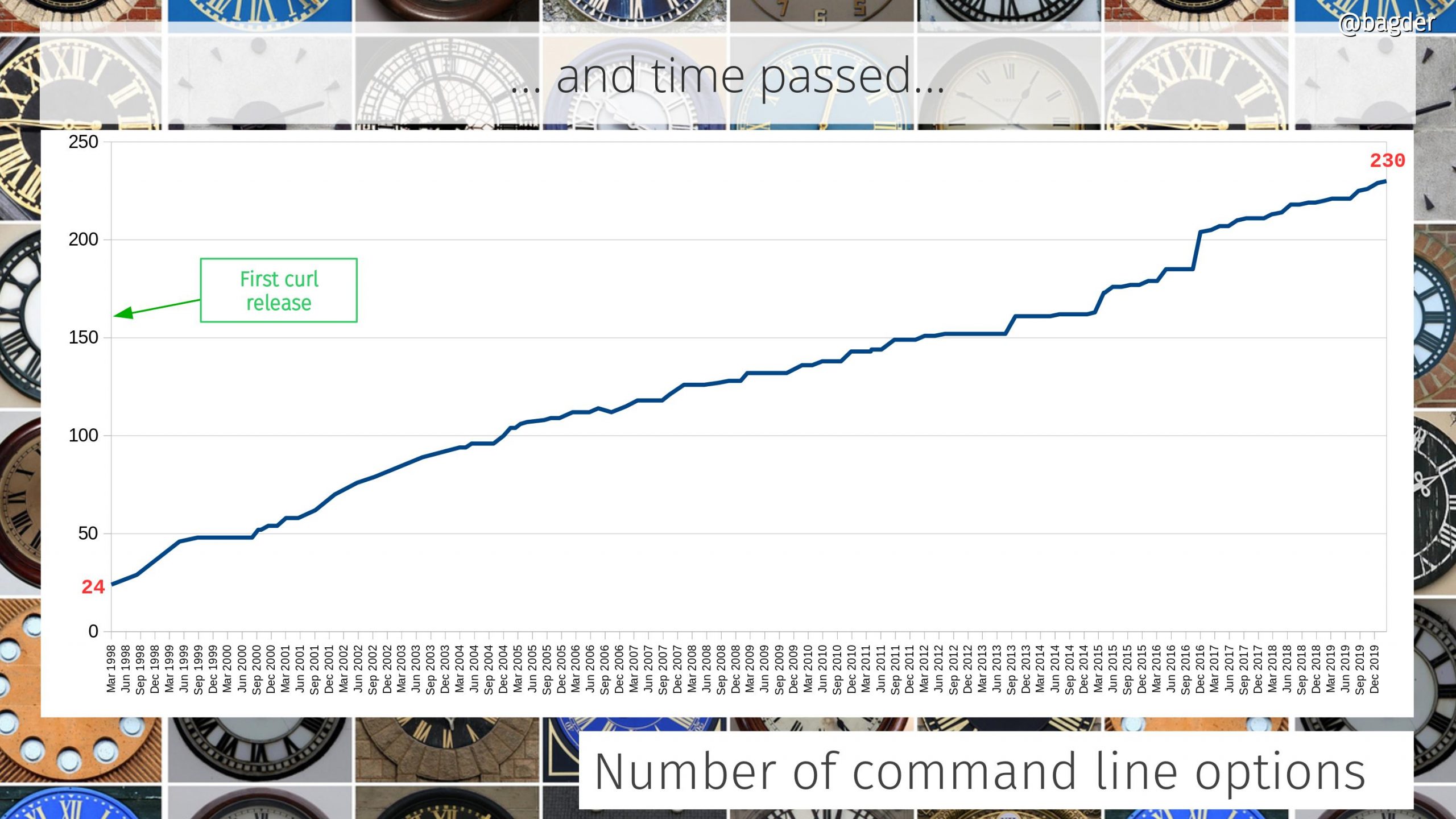
Number of command line options
The command line tool is really like a very elaborate Swiss army knife for Internet transfers and it provides many individual knobs and levers to control the powers. curl has a lot of command line options and they’ve grown in number like this.
Is curl growing too hard to use? Should we redo the “UI” ? Having this huge set of features like curl does, providing them all with a coherent and understandable interface is indeed a challenge…
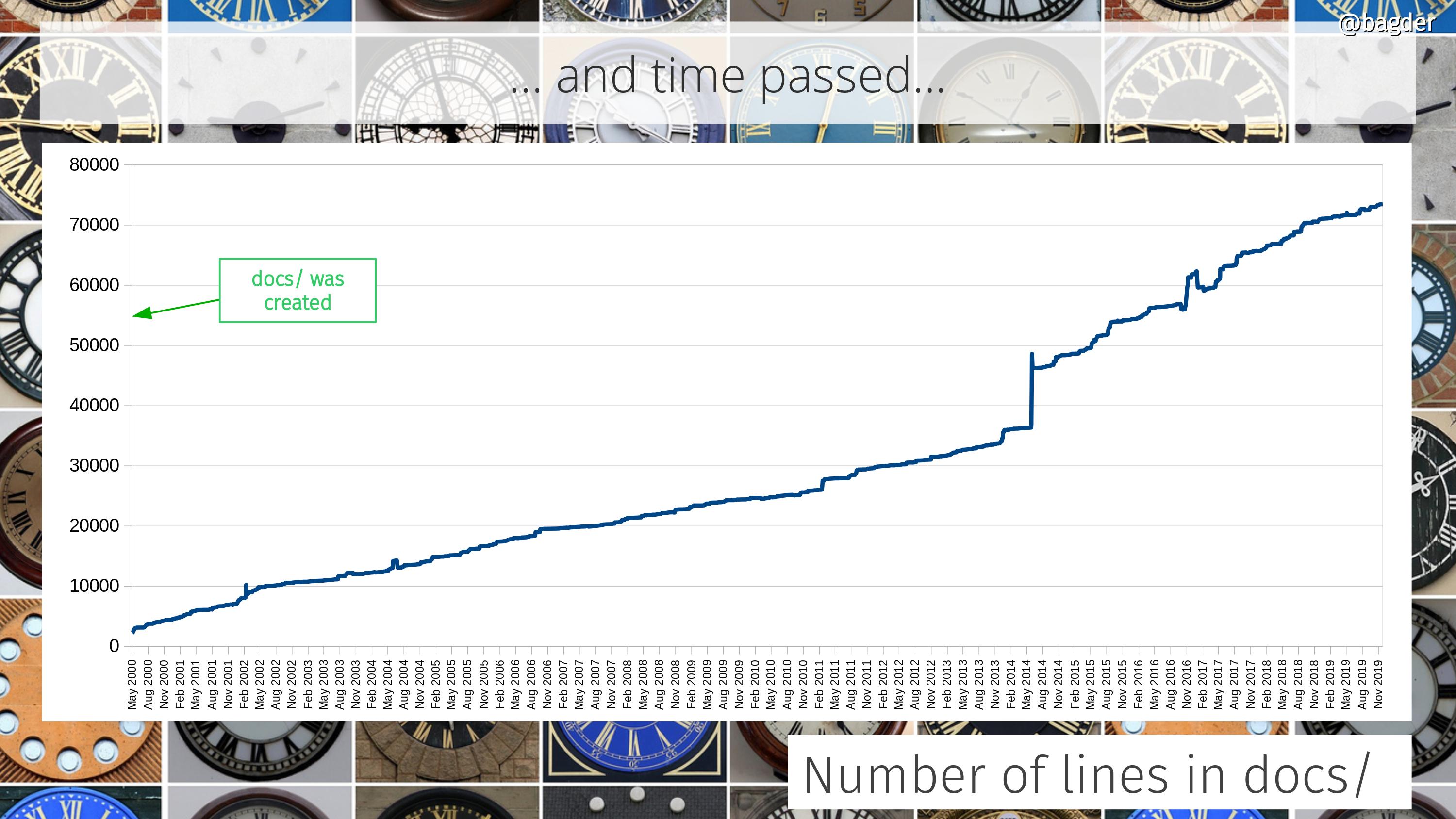
Number of lines in docs/
Documentation is crucial. It’s the foundation on which users can learn about the tool, the library and the entire project. Having plenty and good documentation is a project ambition. Unfortunately, we can’t easily measure the quality.
All the documentation in curl sits in the docs/ directory or sub directories in there. This shows how the amount of docs for curl and libcurl has grown through the years, in number of lines of text. The majority of the docs is in the form of man pages.
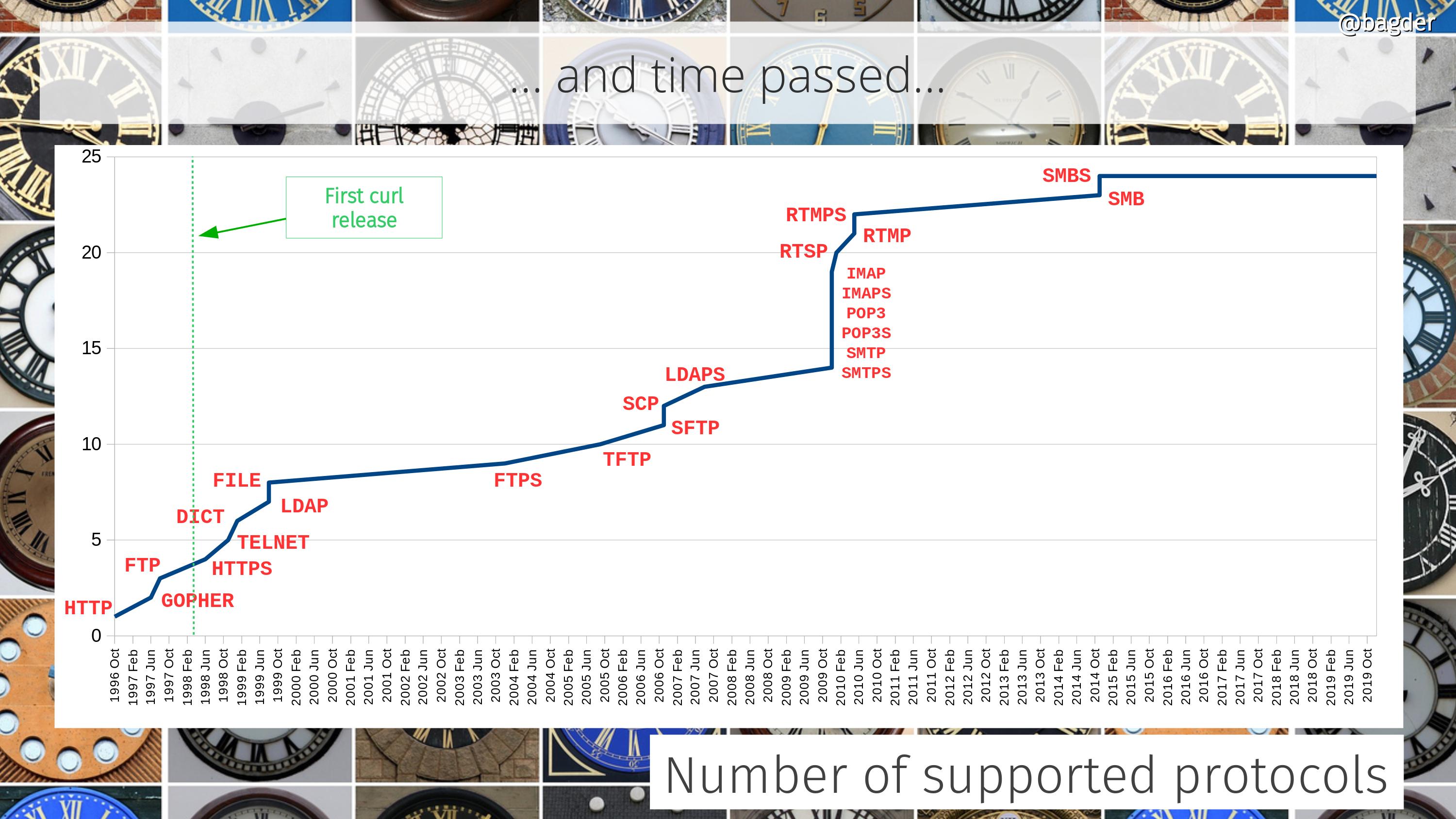
Number of supported protocols
This refers to protocols as in primary transfer protocols as in what you basically specify as a scheme in URLs (ie it doesn’t count “helper protocols” like TCP, IP, DNS, TLS etc). Did I tell you curl is much more than an HTTP client?
More protocols coming? Maybe. There are always discussions and ideas… But we want protocols to have a URL syntax and be transfer oriented to map with the curl mindset correctly.
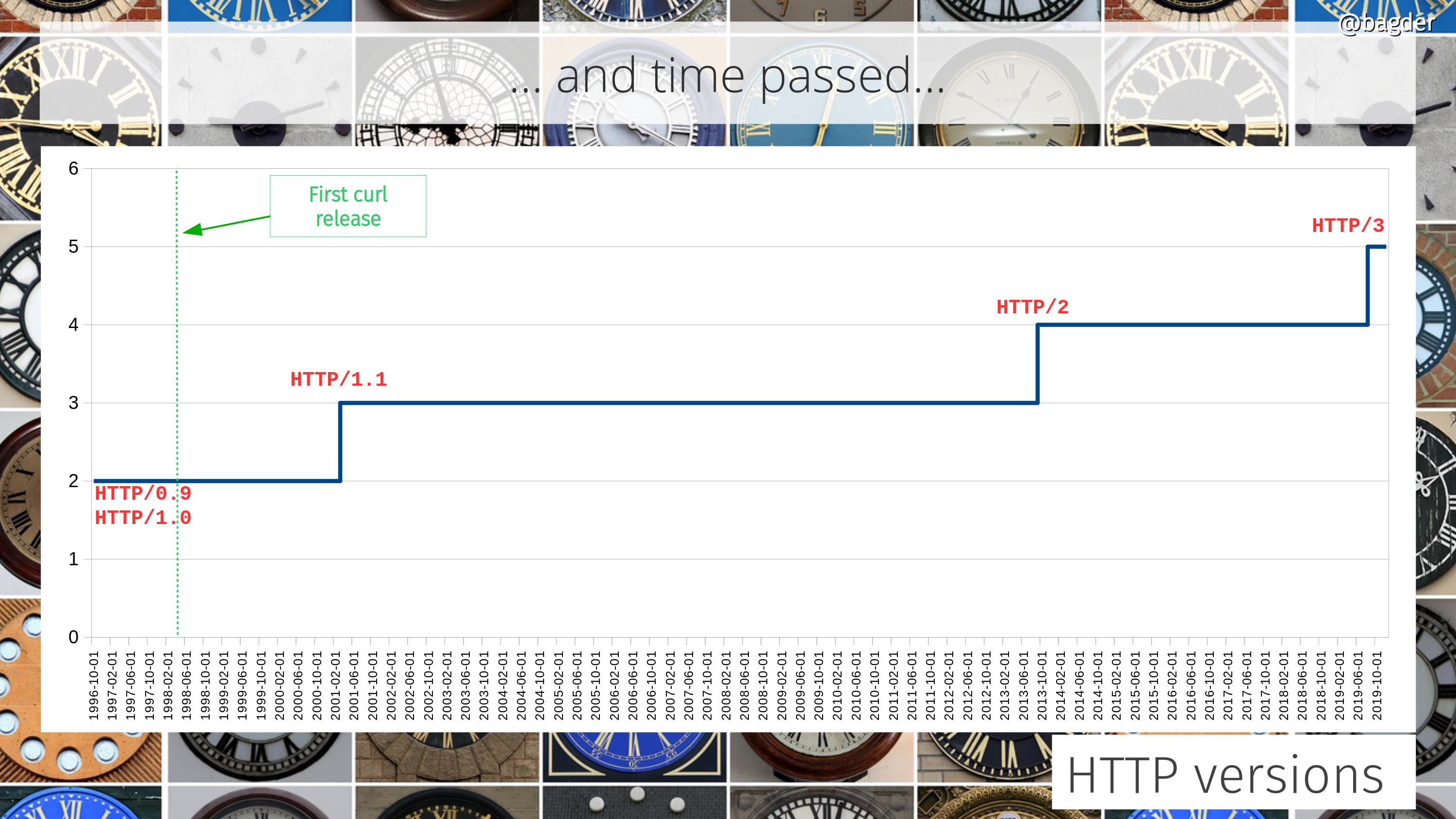
Number of HTTP versions
The support for different HTTP versions has also grown over the years. In the curl project we’re determined to support every HTTP version that is used, even if HTTP/0.9 support recently turned disabled by default and you need to use an option to ask for it.
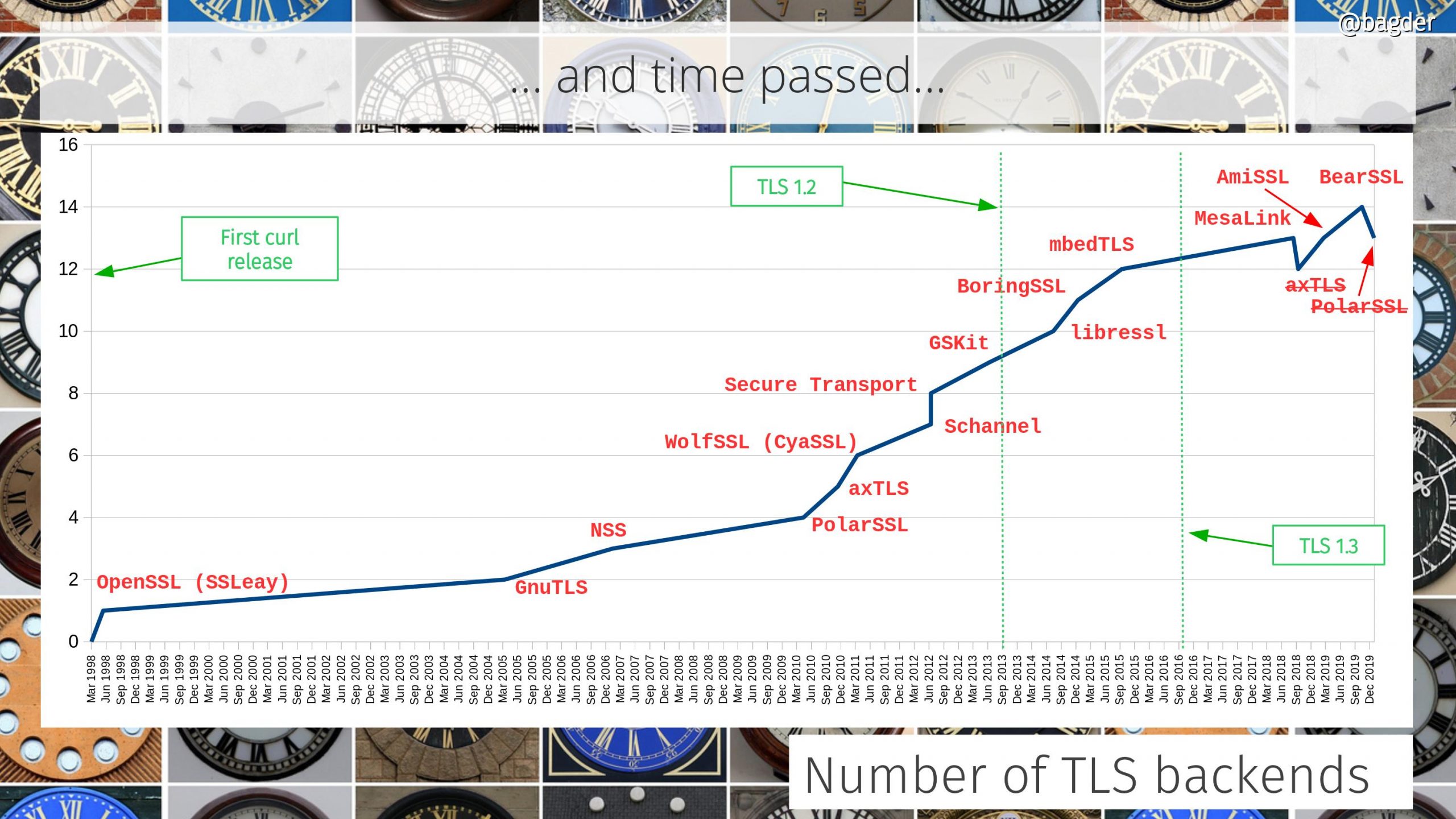
Number of TLS backends
The initial curl release didn’t even support HTTPS but since 2005 we’ve support customizable TLS backends and we’ve been adding support for many more ones since then. As we removed support for two libraries recently we’re now counting thirteen different supported TLS libraries.
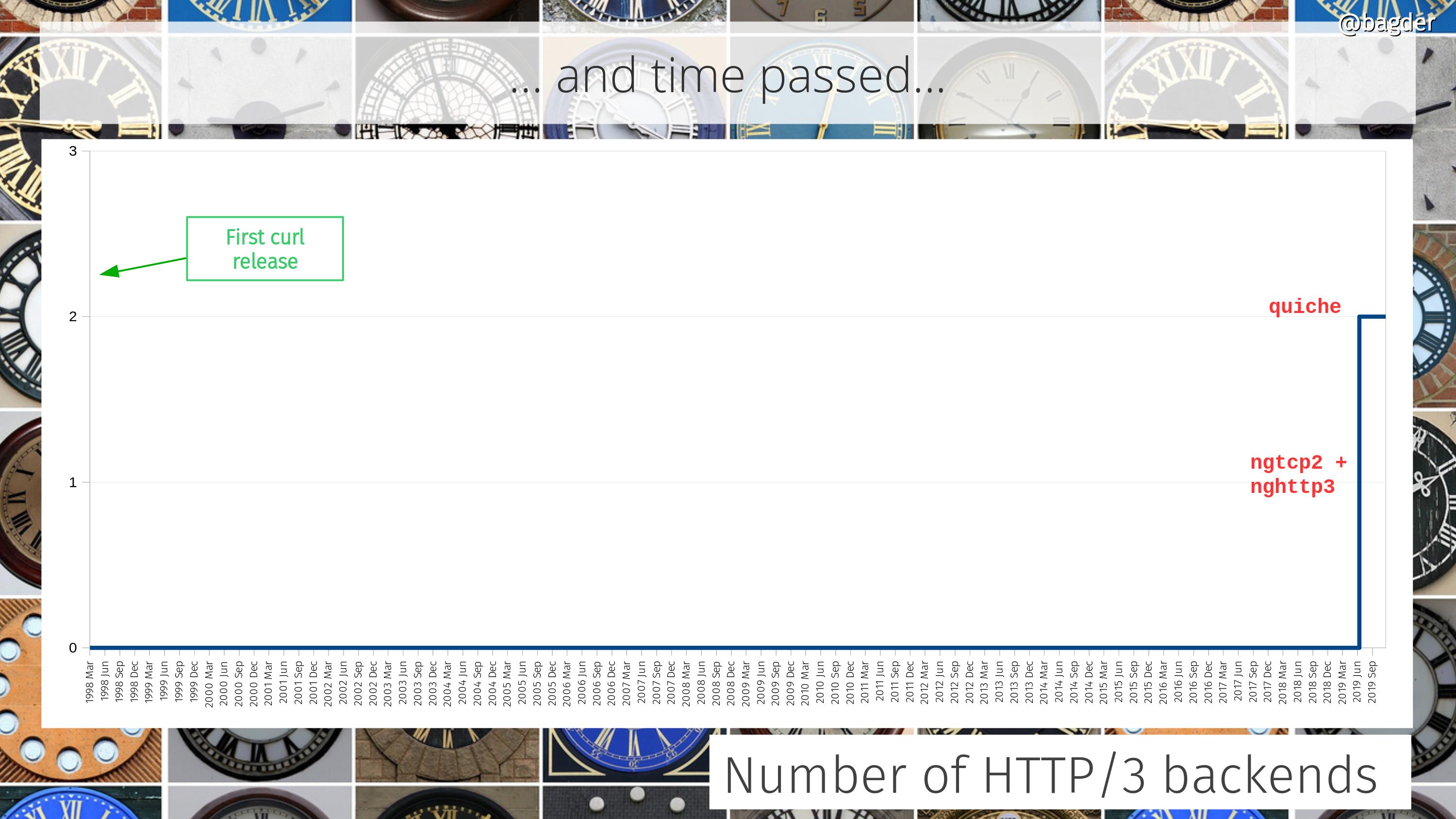
Number of HTTP/3 backends
Okay, this graph is mostly in jest but we recently added support for HTTP/3 and we instantly made that into a multi backend offering as well.
An added challenge that this graph doesn’t really show is how the choice of HTTP/3 backend is going to affect the choice of TLS backend and vice versa.
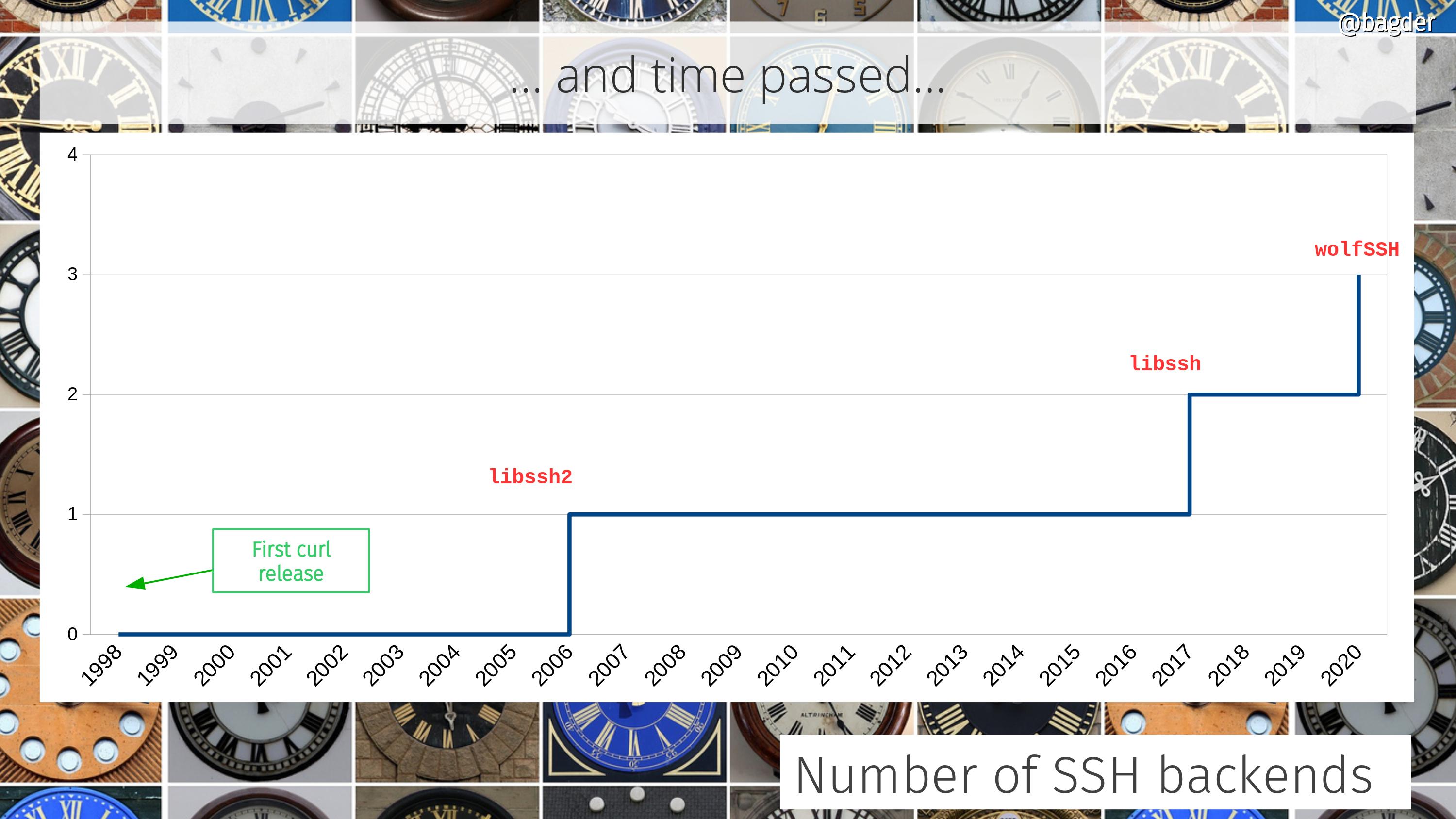
Number of SSH backends
For a long time we only supported a single SSH solution, but that was then and now we have three…
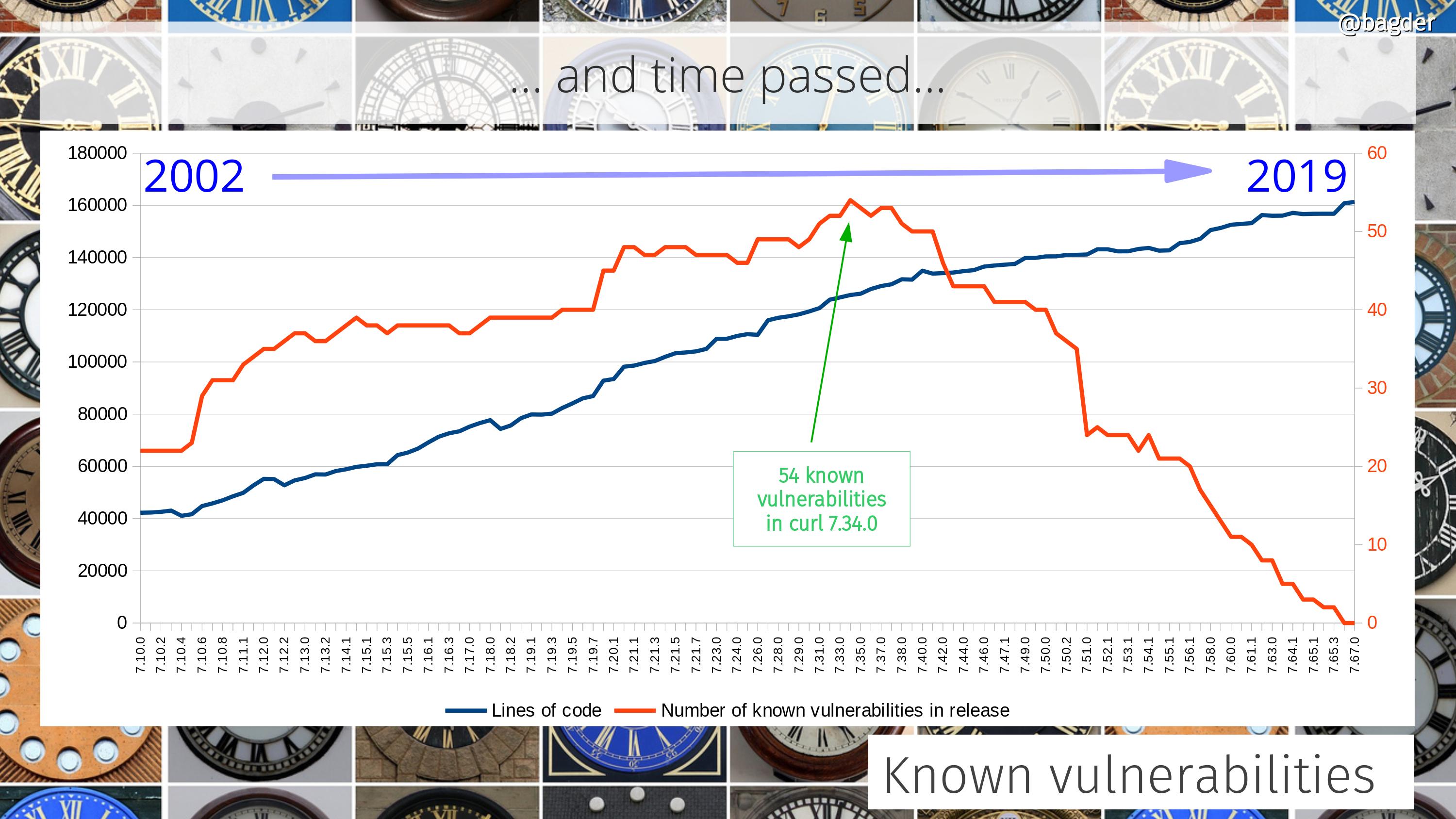
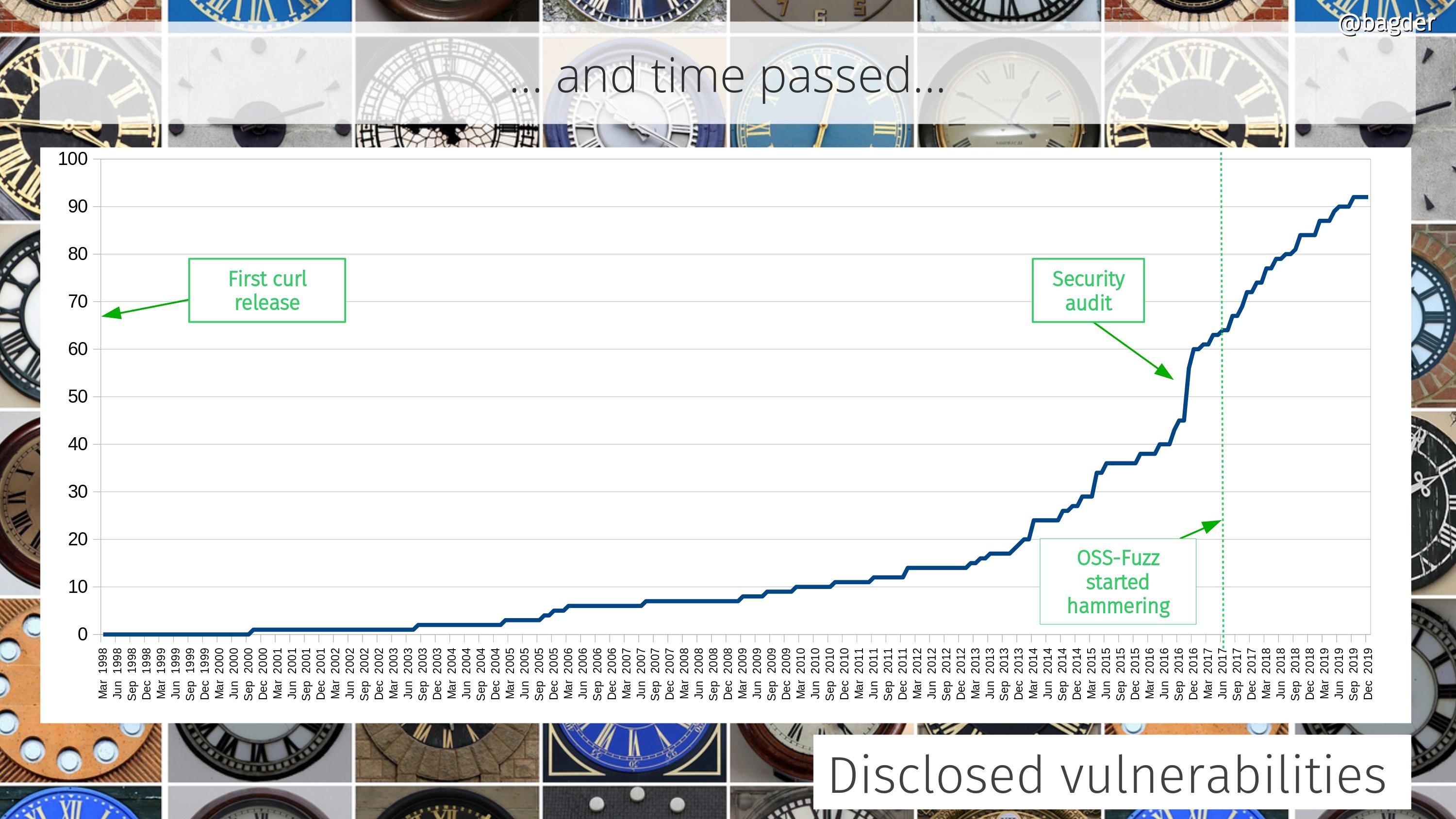
Number of disclosed vulnerabilities
We take security seriously and over time people have given us more attention and have spent more time digging deeper. These days we offer good monetary compensation for anyone who can find security flaws.
Number of known vulnerabilities
An attempt to visualize how many known vulnerabilities previous curl versions contain. Note that most of these problems are still fairly minor and some for very specific use cases or surroundings. As a reference, this graph also includes the number of lines of code in the corresponding versions.
More recent releases have less problems partly because we have better testing in general but also of course because they’ve been around for a shorter time and thus have had less time for people to find problems in them.
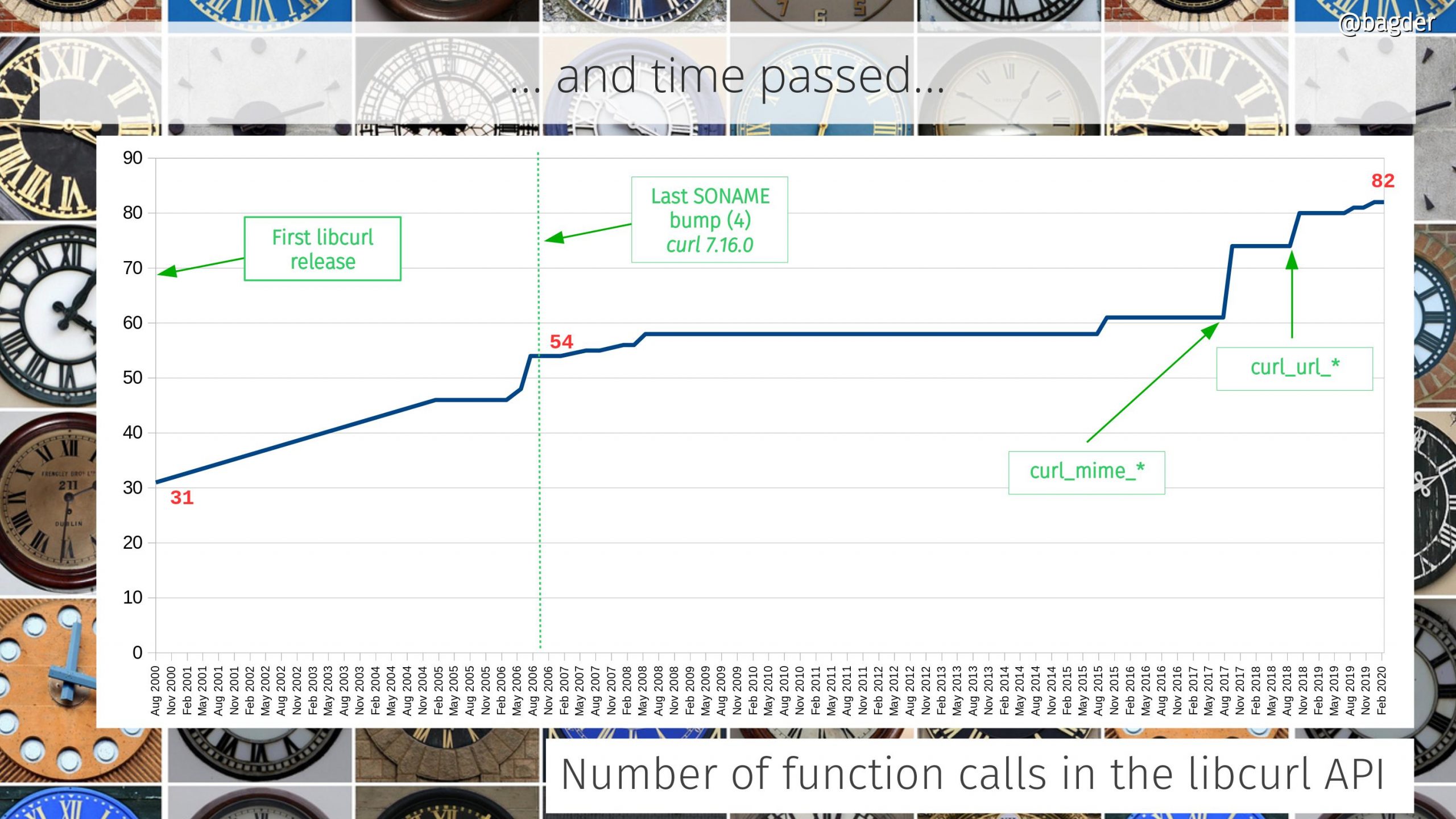
Number of function calls in the API
libcurl is an Internet transfer library and the number of provided function calls in the API has grown over time as we’ve learned what users want and need.
Anything that has been built with libcurl 7.16.0 or later you can always upgrade to a later libcurl and there should be no functionality change and the API and ABI are compatible. We put great efforts into make sure this remains true.
The largest API additions over the last few year are marked in the graph: when we added the curl_mime_* and the curl_url_* families. We now offer 82 function calls. We’ve added 27 calls over the last 14 years while maintaining the same soname (ABI version).
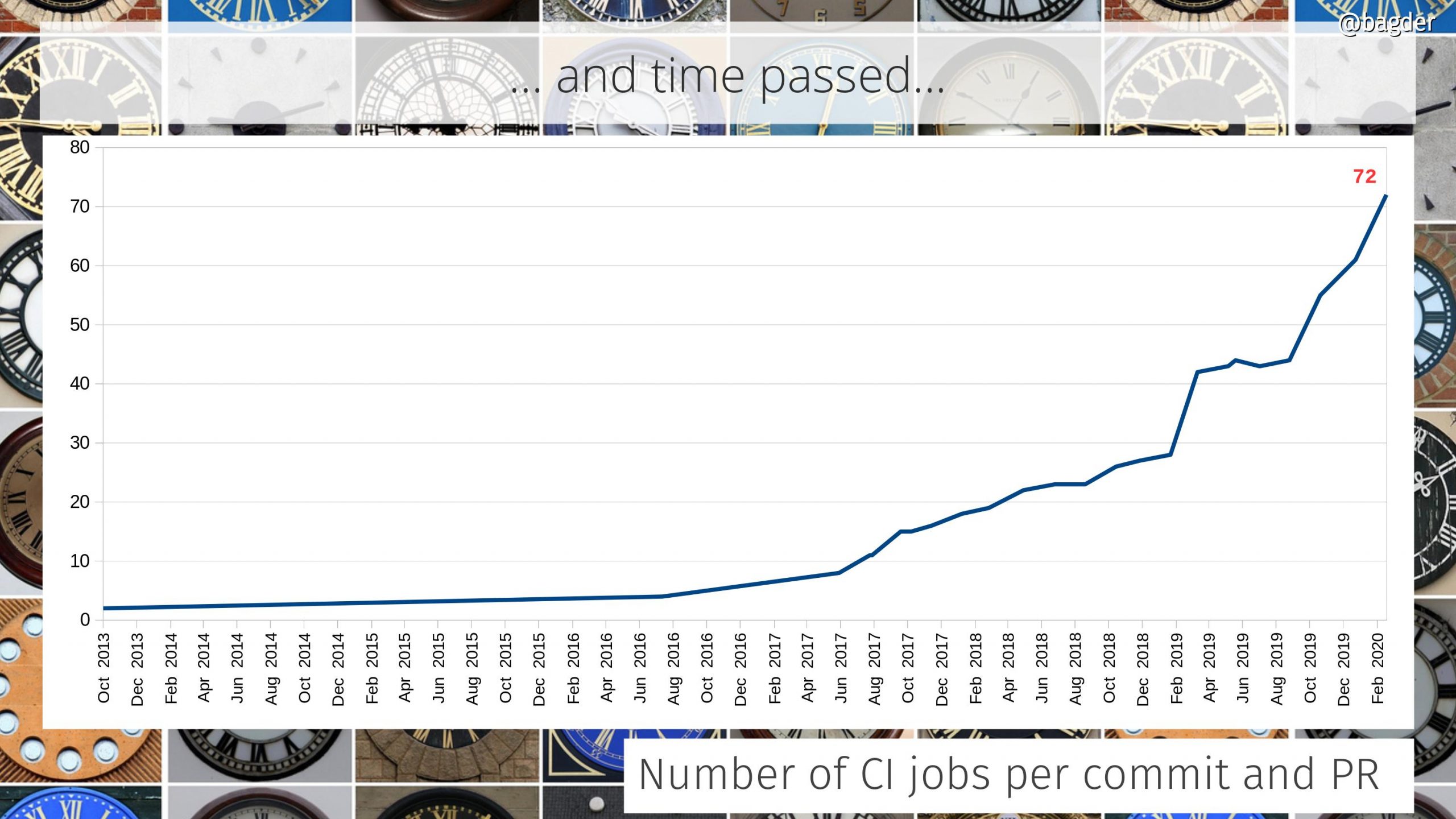
Number of CI jobs per commit and PR
We’ve had automatic testing in the curl project since the year 2000. But for many years that testing was done by volunteers who ran tests in cronjobs in their local machines a few times per day and sent the logs back to the curl web site that displayed their status.
The automatic tests are still running and they still provide value, but I think we all agree that getting the feedback up front in pull-requests is a more direct way that also better prevent bad code from ever landing.
The first CI builds were added in 2013 but it took a few more years until we really adopted the CI lifestyle and today we have 72, spread over 5 different CI services (travis CI, Appveyor, Cirrus CI, Azure Pipelines and Github actions). These builds run for every commit and all submitted pull requests on Github. (We actually have a few more that aren’t easily counted since they aren’t mentioned in files in the git repo but controlled directly from github settings.)
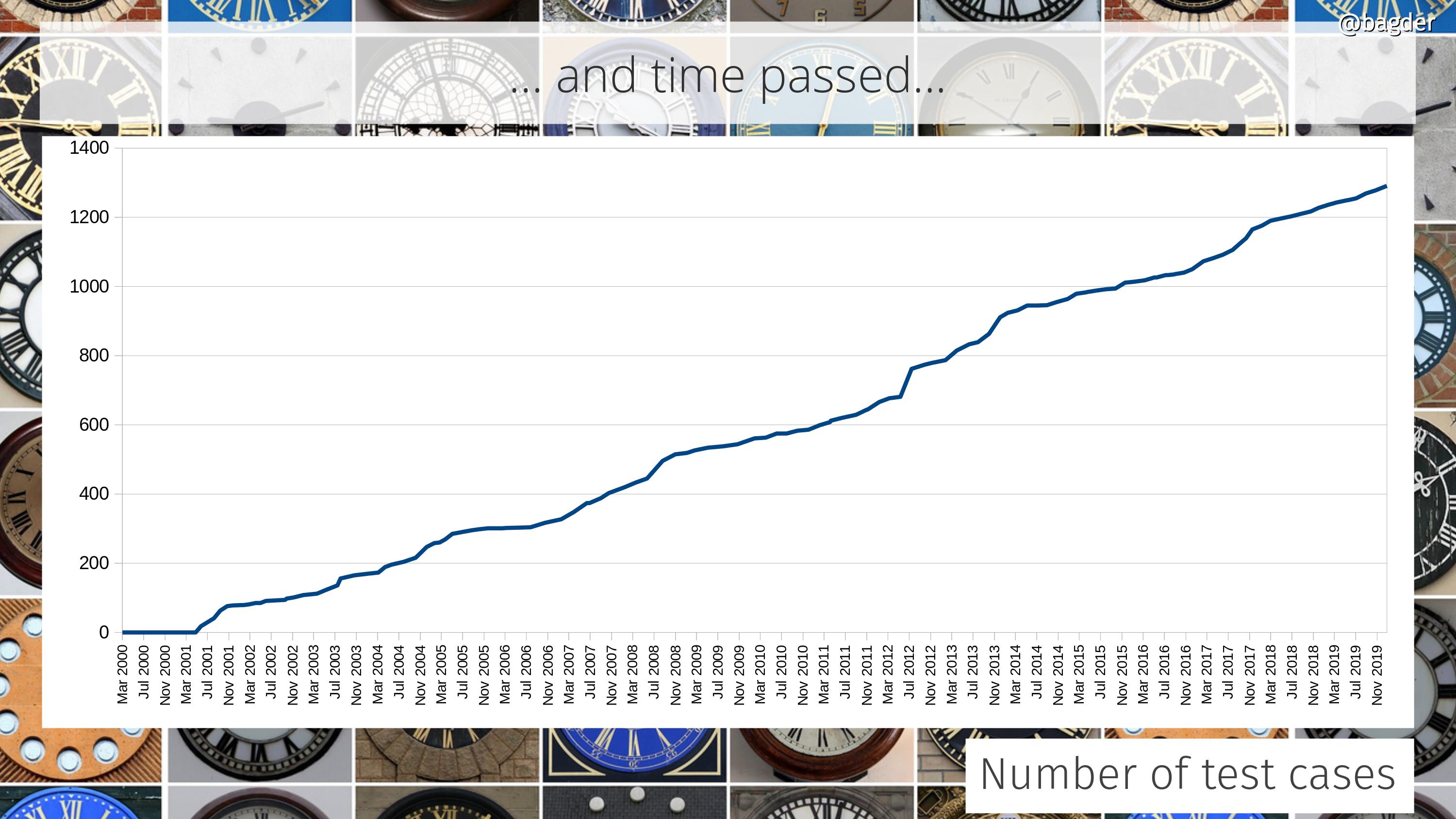
Number of test cases
A single test case can test a simple little thing or it can be a really big elaborate setup that tests a large number of functions and combinations. Counting test cases is in itself not really saying much, but taken together and looking at the change over time we can at least see that we continue to put efforts into expanding and increasing our tests. It should also be considered that this can be combined with the previous graph showing the CI builds, as most CI jobs also run all tests (that they can).
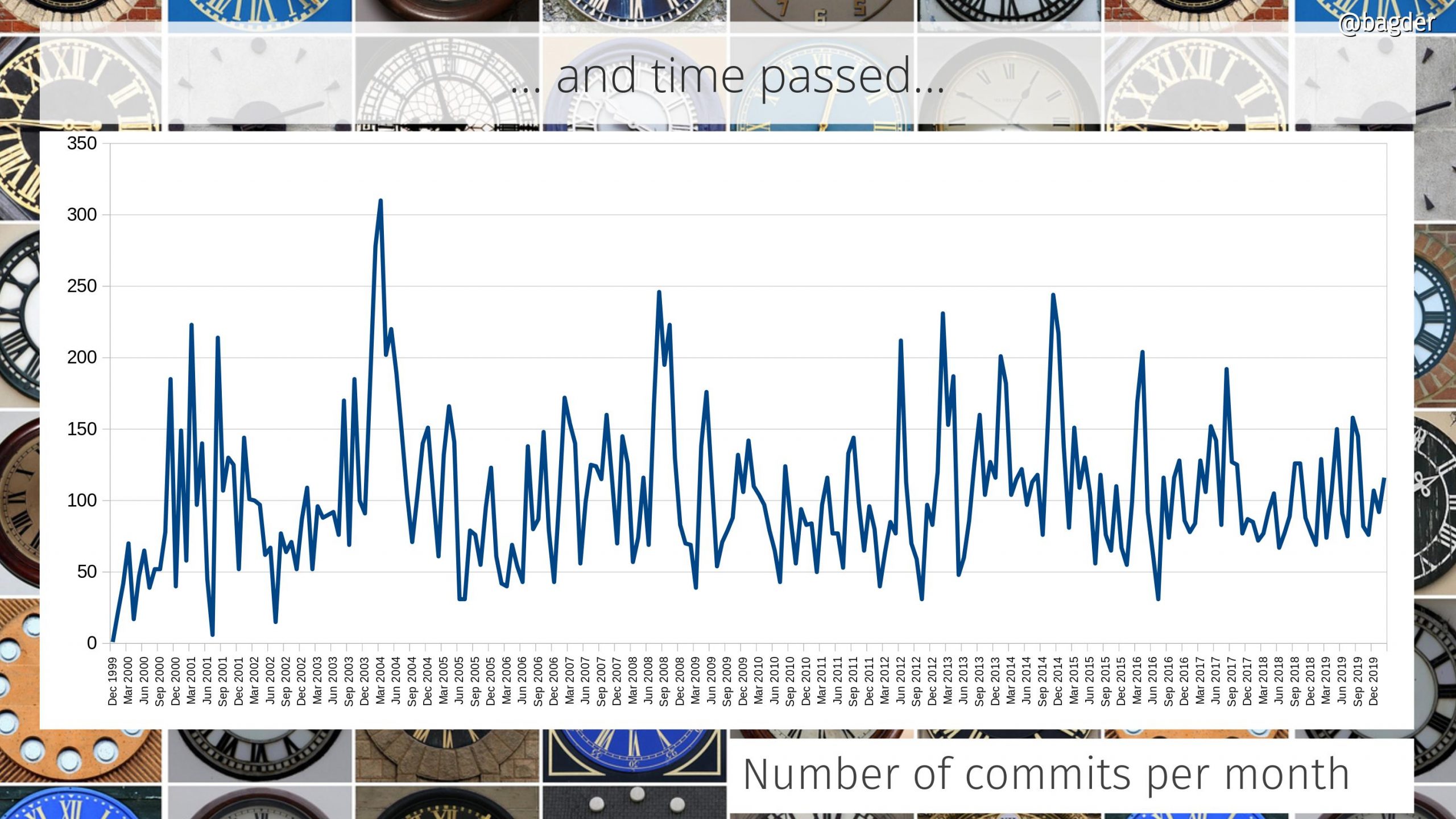
Number of commits per month
A commit can be tiny and it can be big. Counting a commit might not say a lot more than it is a sign of some sort of activity and change in the project. I find it almost strange how the number of commits per months over time hasn’t changed more than this!
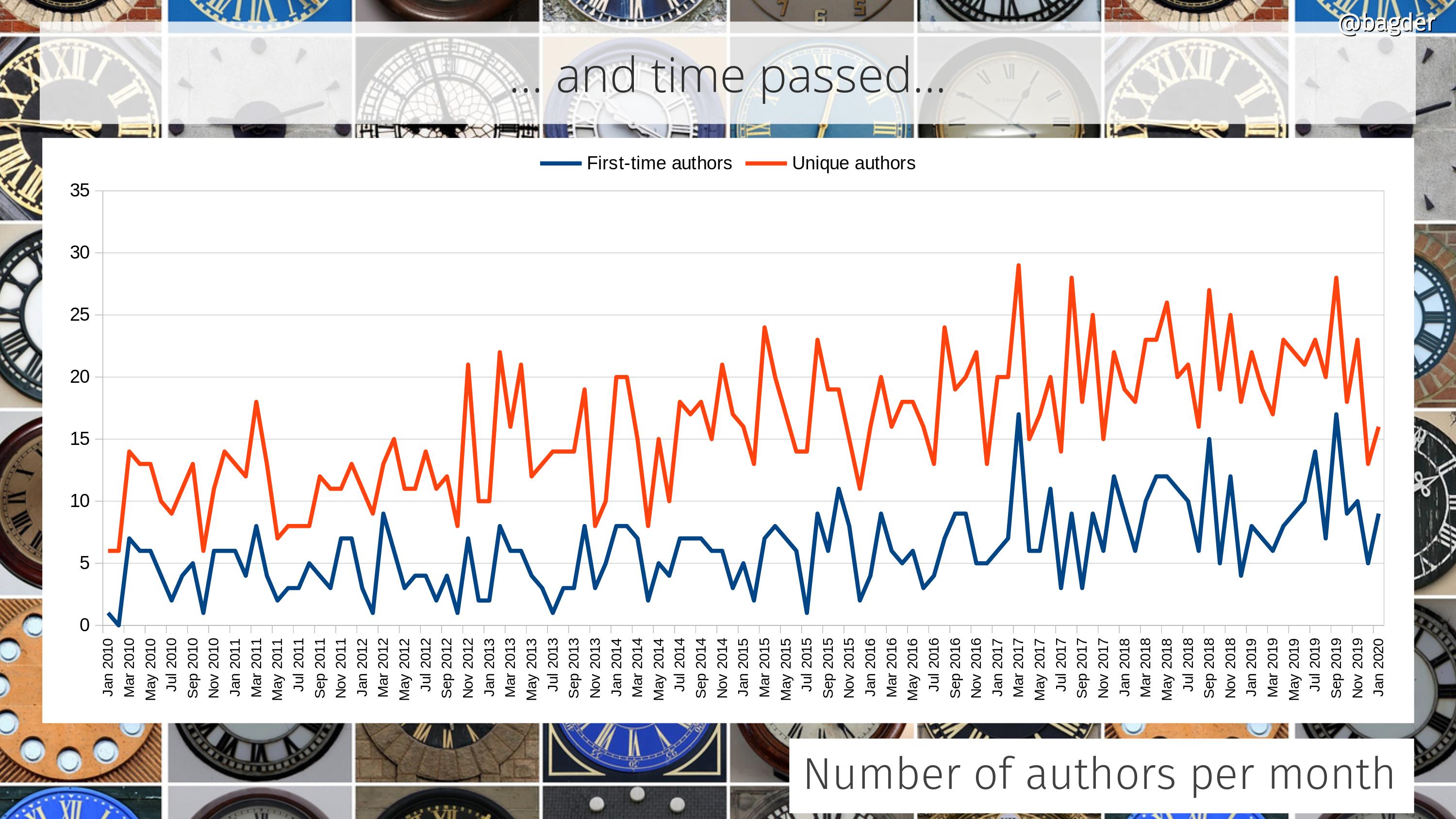
Number of authors per month
This shows number of unique authors per month (in red) together with the number of first-time authors (in blue) and how the amounts have changed over time. In the last few years we see that we are rarely below fifteen authors per month and we almost always have more than five first-time commit authors per month.
I think I’m especially happy with the retained high rate of newcomers as it is at least some indication that entering the project isn’t overly hard or complicated and that we manage to absorb these contributions. Of course, what we can’t see in here is the amount of users or efforts people have put in that never result in a merged commit. How often do we miss out on changes because of project inabilities to receive or accept them?
72 operating systems
Operating systems on which you can build and run curl for right now, or that we know people have ran curl on before. Most mortals cannot even list this many OSes off the top of their heads. If you know of any additional OS that curl has run on, please let me know!
20 CPU architectures
CPU architectures on which we know people have run curl. It basically runs on any CPU that is 32 bit or larger. If you know of any additional CPU architecture that curl has run on, please let me know!
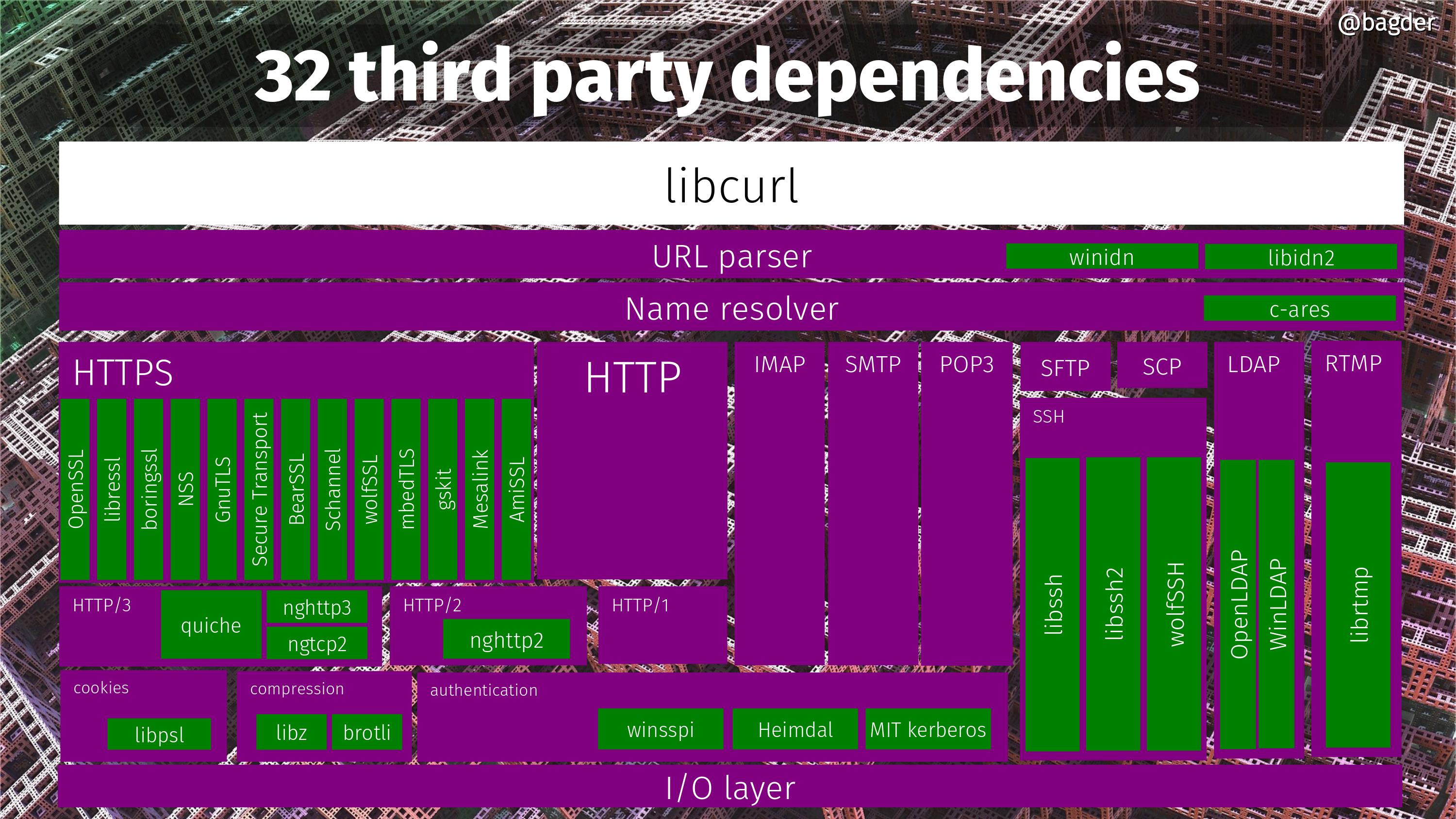
32 third party dependencies
Did I mention you can build curl in millions of combinations? That’s partly because of the multitude of different third party dependencies you can tell it to use. curl support no less than 32 different third party dependencies right now. The picture below is an attempt to some sort of block diagram and all the green boxes are third party libraries curl can potentially be built to use. Many of them can be used simultaneously, but a bunch are also mutually exclusive so no single build can actually use all 32.
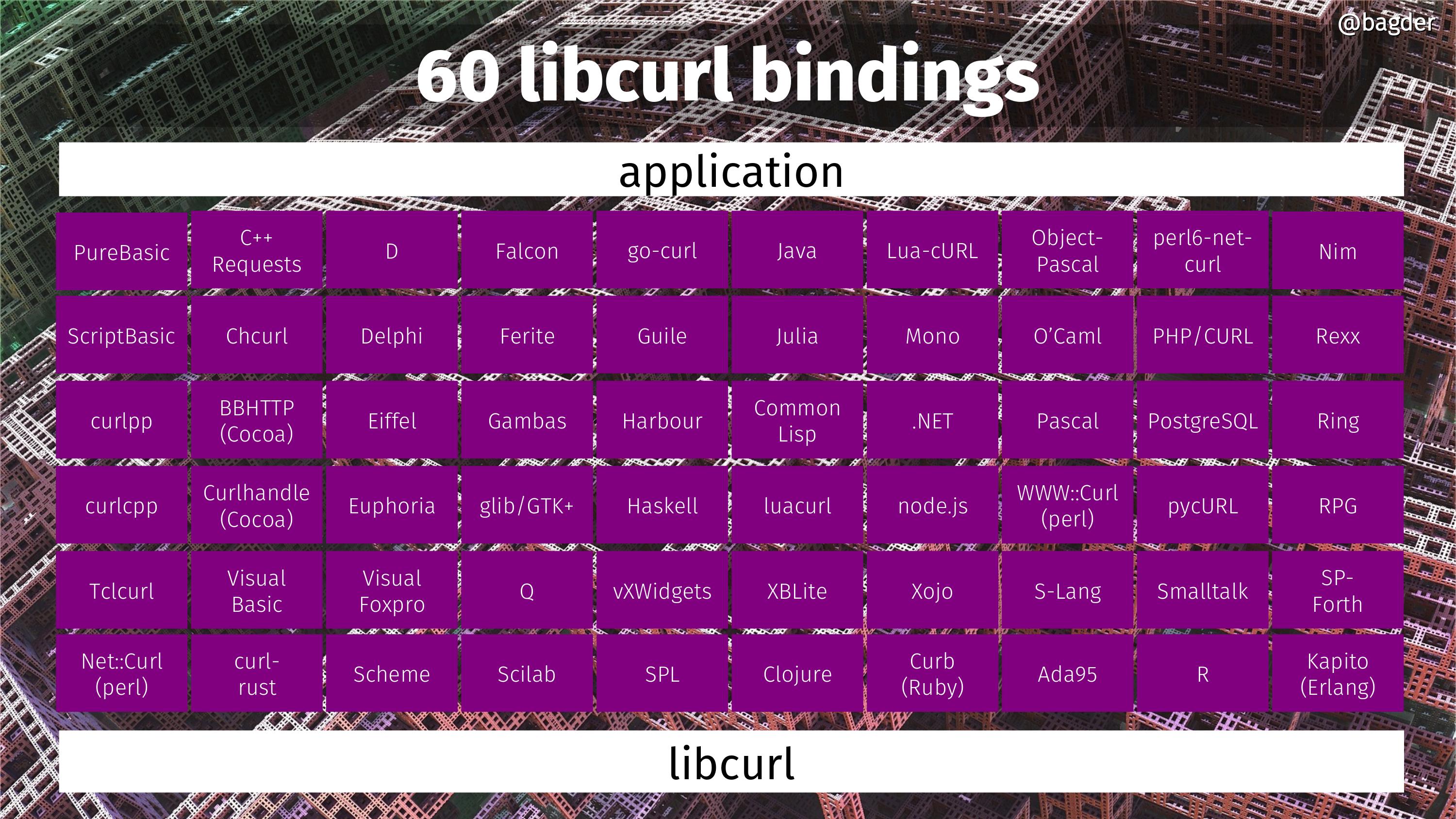
60 libcurl bindings
If you’re looking for more explanations how libcurl ends up being used in so many places, here are 60 more. Languages and environments that sport a “binding” that lets users of these languages use libcurl for Internet transfers.
Missing pictures
“number of downloads” could’ve been fun, but we don’t collect the data and most users don’t download curl from our site anyway so it wouldn’t really say a lot.
“number of users” is impossible to tell and while I’ve come up with estimates every now and then, making that as a graph would be doing too much out of my blind guesses.
“number of graphs in anniversary blog posts” was a contender, but in the end I decided against it, partly since I have too little data.
Every anniversary is an opportunity to reflect on what’s next.
In the curl project we don’t have any grand scheme or roadmap for the coming years. We work much more short-term. We stick to the scope: Internet transfers specified as URLs. The products should be rock solid and secure. The should be high performant. We should offer the features, knobs and levers our users need to keep doing internet transfers now and in the future.
curl is never done. The development pace doesn’t slow down and the list of things to work on doesn’t shrink.
curl up 2020 will not take place in Berlin as previously planned. The corona times are desperate times and we don’t expect things to have improved soon enough to make a physical conference possible at this date.
curl up 2020 will still take place, and at the same date as planned (May 9-10), but we will change the event to a pure online and video-heavy occasion. This way we can of course also even easier welcome audience and participants from even furher away who previously would have had a hard time to participate.
We have not worked out the details yet. What tools to use, how to schedule, how to participate, how to ask questions or how to say cheers with your local favorite beer. If you have ideas, suggestions or even experiences to share regarding this, please join the curl-meet mailing list and help!
This option takes a format string in which there are a number of different “variables” available that let’s a user output information from the previous transfer. For example, you can get the HTTP response code from a transfer like this:
That command line will spew some 800 bytes to the terminal and it won’t be very human readable. You will rather take care of that output with some kind of script/program, or if you want an eye pleasing version you can pipe it into jq and then it can look like this:
It always outputs the entire object and the object may of course differ over time, as I expect that we might add more fields into it in the future.
The names are the same as the write-out variables, so you can read the --write-out section in the man page to learn more.
Ships?
The feature landed in this commit. This new functionality will debut in the next pending release, likely to be called 7.70.0, scheduled to happen on April 29, 2020.
Credits
This is the result of fine coding work by Mathias Gumz.
This option was added to curl 7.59.0, March 2018 and is very rarely actually needed.
To understand this command line option, I think I should make a quick recap of what “happy eyeballs” is exactly and what timeout in there that this command line option is referring to!
Happy Eyeballs
This is the name of a standard way of connecting to a host (a server really in curl’s case) that has both IPv4 and IPv6 addresses.
When curl resolves the host name and gets a list of IP addresses back for it, it will try to connect to the host over both IPv4 and IPv6 in parallel, concurrently. The first of these connects that completes its handshake is considered the winner and the other connection attempt then gets ditched and is forgotten. To complicate matters a little more, a host name can resolve to a list of addresses of both IP versions and if a connect to one of the addresses fails, curl will attempt the next in a way so that IPv4 addresses and IPv6 addresses will be attempted, simultaneously, until one succeeds.
curl races connection attempts against each other. IPv6 vs IPv4.
Of course, if a host name only has addresses in one IP version, curl will only use that specific version.
Happy Eyeballs Timeout
For hosts having both IPv6 and IPv4 addresses, curl will first fire off the IPv6 attempt and then after a timeout, start the first IPv4 attempt. This makes curl prefer a quick IPv6 connect.
The default timeout from the moment the first IPv6 connect is issued until the first IPv4 starts, is 200 milliseconds. (The Happy Eyeballs RFC 6555 claims Firefox and Chrome both use a 300 millisecond delay, but I’m not convinced this is actually true in current versions.)
By altering this timeout, you can shift the likeliness of one or the other connect to “win”.
Example: change the happy eyeballs timeout to the same value said to be used by some browsers (300 milliseconds):
There’s a Happy Eyeballs version two, defined in RFC 8305. It takes the concept a step further and suggests that a client such as curl should start the first connection already when the first name resolve answers come in and not wait for all the responses to arrive before it starts the racing.
curl does not do that level “extreme” Happy Eyeballing because of two simple reasons:
1. there’s no portable name resolving function that gives us data in that manner. curl won’t start the actual connection procedure until the name resolution phase is completed, in its entirety.
2. getaddrinfo() returns addresses in a defined order that is hard to follow if we would side-step that function as described in RFC 8305.
Taken together, my guess is that very few internet clients today actually implement Happy Eyeballs v2, but there’s little to no reason for anyone to not implement the original algorithm.
Curios extra
curl has done Happy Eyeballs connections since 7.34.0 (December 2013) and yet we had this lingering bug in the code that made it misbehave at times, only just now fixed and not shipped in a release yet. This bug makes curl sometimes retry the same failing IPv6 address multiple times while the IPv4 connection is slow.
Related options
--connect-timeout limits how long to spend trying to connect and --max-time limits the entire curl operation to a fixed time.
The Windows operating system will automatically, and without any way for applications to disable it, try to establish a connection to another host over the network and access it (over SMB or other protocols), if only the correct file path is accessed.
When first realizing this, the curl team tried to filter out such attempts in order to protect applications for inadvertent probes of for example internal networks etc. This resulted in CVE-2019-15601 and the associated security fix.
However, we’ve since been made aware of the fact that the previous fix was far from adequate as there are several other ways to accomplish more or less the same thing: accessing a remote host over the network instead of the local file system.
The conclusion we have come to is that this is a weakness or feature in the Windows operating system itself, that we as an application and library cannot protect users against. It would just be a whack-a-mole race we don’t want to participate in. There are too many ways to do it and there’s no knob we can use to turn off the practice.
We no longer consider this to be a curl security flaw!
If you use curl or libcurl on Windows (any version), disable the use of the FILE protocol in curl or be prepared that accesses to a range of “magic paths” will potentially make your system try to access other hosts on your network. curl cannot protect you against this.
This was previously considered a curl security problem, as reported in CVE-2019-15601. We no longer consider that a security flaw and have updated that web page with information matching our new findings. I don’t expect any other CVE database to update since there’s no established mechanism for updating CVEs!
Credits
Many thanks to Tim Sedlmeyer who highlighted the extent of this issue for us.
This release comes but 7 days since the previous and is a patch release only, hence called 7.69.1.
Numbers
the 190th release 0 changes 7 days (total: 8,027) 27 bug fixes (total: 5,938) 48 commits (total: 25,405 0 new public libcurl function (total: 82) 0 new curl_easy_setopt() option (total: 270) 0 new curl command line option (total: 230) 19 contributors, 6 new (total: 2,133) 7 authors, 1 new (total: 772) 0 security fixes (total: 93) 0 USD paid in Bug Bounties
Unplanned patch release
Quite obviously this release was not shipped aligned with our standard 8-week cycle. The reason is that we had too many semi-serious or at least annoying bugs that were reported early on after the 7.69.0 release last week. They made me think our users will appreciate a quick follow-up that addresses them. See below for more details on some of those flaws.
How can this happen in a project that soon is 22 years old, that has thousands of tests, dozens of developers and 70+ CI jobs for every single commit?
The short answer is that we don’t have enough tests that cover enough use cases and transfer scenarios, or put another way: curl and libcurl are very capable tools that can deal with a nearly infinite number of different combinations of protocols, transfers and bytes over the wire. It is really hard to cover all cases.
Also, an old wisdom that we learned already many years ago is that our code is always only properly widely used and tested the moment we do a release and not before. Everything can look good in pre-releases among all the involved developers, but only once the entire world gets its hands on the new release it really gets to show what it can or cannot do.
This time, a few of the changes we had landed for 7.69.0 were not good enough. We then go back, fix issues, land updates and we try again. So here comes 7.69.1 – better patch than sorry!
Bug-fixes
As the numbers above show, we managed to land an amazing number of bug-fixes in this very short time. Here are seven of the more important ones, from my point of view! Not all of them were regressions or even reported in 7.69.0, some of them were just ripe enough to get landed in this release.
unpausing HTTP/2 transfers
When I fixed the pausing and unpausing of HTTP/2 streams for 7.69.0, the fix was inadequate for several of the more advanced use cases and unfortunately we don’t have good enough tests to detect those. At least two browsers built to use libcurl for their HTTP engines reported stalled HTTP/2 transfers due to this.
I reverted the previous change and I’ve landed a different take that seems to be a more appropriate one, based on early reports.
pause: cleanups
After I had modified the curl_easy_pause function for 7.69.0, we also got reports about crashes with uses of this function.
It made me do some additional cleanups to make it more resilient to bad uses from applications, both when called without a correct handle or when it is called to just set the same pause state it is already in
socks: connection regressions
I was so happy with my overhauled SOCKS connection code in 7.69.0 where it was made entirely non-blocking. But again it turned out that our test cases for this weren’t entirely mimicking the real world so both SOCKS4 and SOCKS5 connections where curl does the name resolving could easily break. The test cases probably worked fine there because they always resolve the host name really quick and locally.
SOCKS4 connections are now also forced to be done over IPv4 only, as that was also something that could trigger a funny error – the protocol doesn’t support IPv6, you need to go to SOCKS5 for that!
Both version 4 and 5 of the SOCKS proxy protocol have options to allow the proxy to resolve the server name or you can have the client (curl) do it. (Somewhat described in the CURLOPT_PROXY man page.) These problems were found for the cases when curl resolves the server name.
libssh: MD5 hex comparison
For application users of the libcurl CURLOPT_SSH_HOST_PUBLIC_KEY_MD5 option, which is used to verify that curl connects to the right server, this change makes sure that the libssh backend does the right thing and acts exactly like the libssh2 backend does and how the documentation says it works…
libssh2: known hosts crash
In a recent change, libcurl will try to set a preferred method for the knownhost matching libssh2 provides when connecting to a SSH server, but the code unfortunately contained an easily triggered NULL pointer dereference that no review caught and obviously no test either!
c-ares: duphandle copies DNS servers too
curl_easy_duphandle() duplicates a libcurl easy handle and is frequently used by applications. It turns out we broke a little piece of the function back in 7.63.0 as a few DNS server options haven’t been duplicated properly since then. Fixed now!
This was an out-of-schedule release but the plan is to stick to the established release schedule, which will have the effect that the coming release window will be one week shorter than usual and the full cycle will complete in 7 weeks instead of 8.