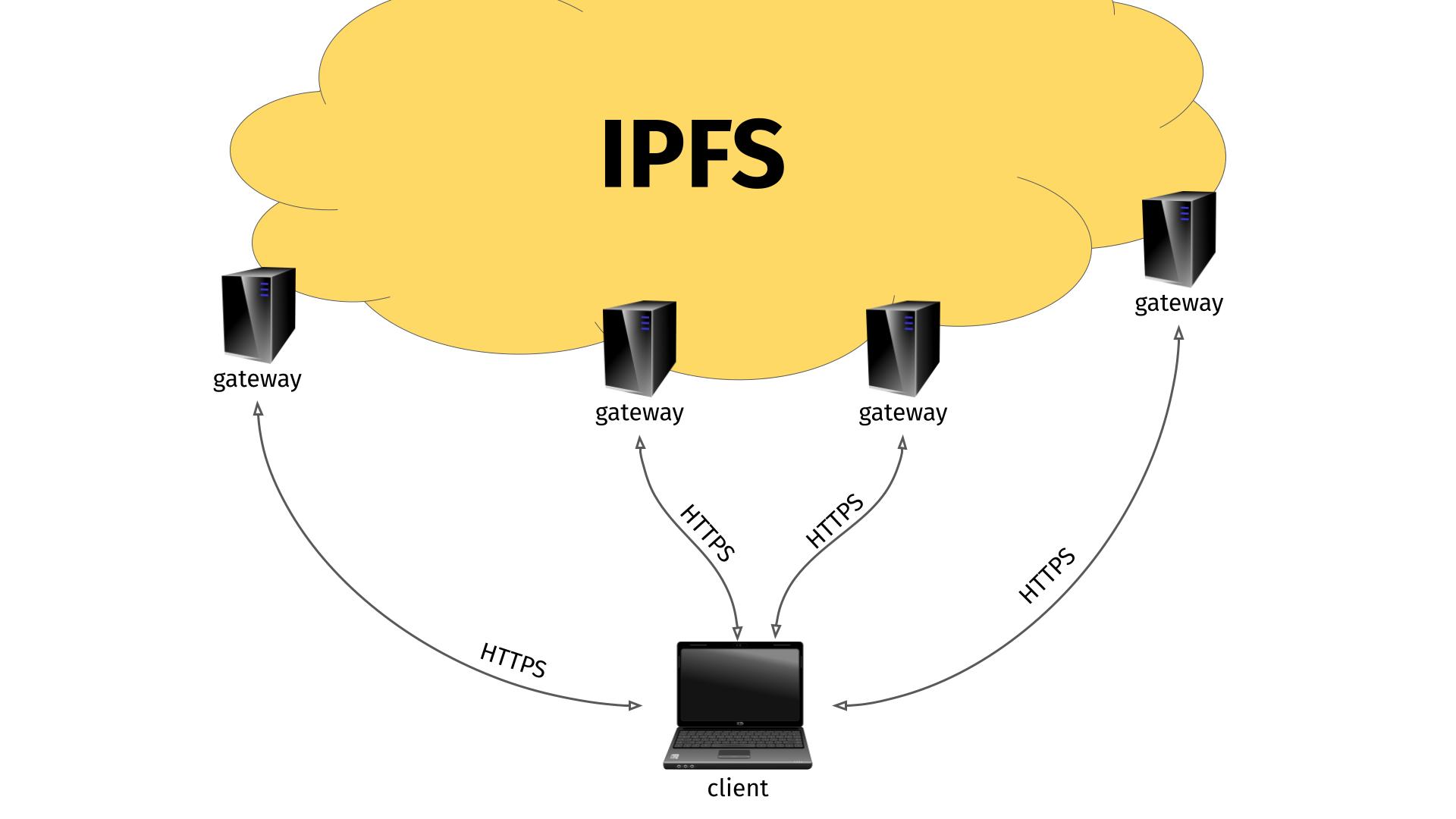
The InterPlanetary File System (IPFS) is according to the Wikipedia description: “a protocol, hypermedia and file sharing peer-to-peer network for storing and sharing data in a distributed file system.”. It works a little like bittorrent and you typically access content on it using a very long hash in an ipfs:// URL. Like this:
I guess partly because IPFS is a rather new protocol not widely supported by many clients yet, people came up with the concept of IPFS “gateways”. (Others might have called it a proxy, because that is what it really is.)
This gateway is an HTTP server that runs on a machine that also knows how to speak and access IPFS. By sending the right HTTP request to the gateway, that includes the IPFS hash you are interested in, the gateway can respond with the contents from the IPFS hash.
This way, you just need an ordinary HTTP client to access IPFS. I think it is pretty clever. But as always, the devil is in the details.
Rewrite ipfs:// into https://
The quest for IPFS aficionados have seemingly become to add support for IPFS using this gateway approach to multiple widely used applications that know how to speak HTTP(S). Just rewrite the URL internally from IPFS to HTTPS.
The IPFS “URL rewrite” is done in such so that the example IPFS URL is converted into “https://$gateway/$hash”. The transfer is done by the client as if it was a plain old HTTPS transfer.
What if the gateway is not local?
This approach has its biggest benefit of course when you can actually use a remote IPFS gateway. I presume most random ordinary users who want to access IPFS does not actually want to download, install and run an IPFS gateway on their machine to use this new power. They might very well appreciate the idea and convenience of accessing a remote IPFS gateway.
Remote IPFS gateways illustration
After all, the gateways are using HTTPS so at least the transfers are secure, right?
Leading people behind IPFS are even running public IPFS gateways for anyone to use. Both dweb.link and ipfs.io have been mentioned and suggested for default use. Possibly they are the same physical host as they appear to have the same IP addresses (owned by Protocol Labs, one of the big proponents behind IPFS).
In an attempt to make this even easier for users, ffmpeg is made to use a built-in default gateway if none is set by the user.
I would expect very few users to actually have an IPFS gateway set. And even fewer to actually specify a local one.
So, when users want to watch a video using ffmpeg and an ipfs:// URL what happens?
The gateway sees it all
The remote gateway, that is administered by someone, somewhere, gets to see the full incoming request, and all traffic (video, whatever) that is sent back to the client (ffmpeg in this example) goes via the gateway. Sure, the client accesses the gateway via HTTPS so nobody can tamper with the traffic along the way, but the gateway is in full control and can inspect and tamper with the data as much as it likes. And there is no way for the client to know or detect if it is happening.
I am not involved in ffmpeg, nor do I have any insights into how the discussions evolved and were done around this subject, but for curl I have put my foot down and said that we must not blindly use and trust any default remote gateway like this. I believe it is our responsibility to not lure users into this traffic-monitoring setup.
Make sure you trust the gateway you use.
The curl way
curl will probably output an error message if there was no gateway set when an ipfs:// URL is used, and inform the user that it needs a gateway set to function and probably also show a URL for a page that contains more information about what this means and how to specify a gateway.
Bouncing gateways!
During the work of making the IPFS support for curl (which I review and comment on, not written or authored myself) I have also learned that some of the IPFS gateways even do regular HTTP 30x redirects to bounce over the client to another gateway.
Meaning: not only do you use and rely a total rando’s gateway on the Internet for your traffic. That gateway might even, on its own discretion, redirect you over to another host. Possibly run somewhere else, monitored by a separate team.
I have insisted, in the PR for ipfs support to curl, that the IPFS URL handling code should not automatically follow such gateway redirects, as I believe that adds even more risk to the user so if a user wants to allow this operation, it should be opt-in.
Imagine rising use of this
I would imagine that the ones hosting a popular default gateway either becomes overloaded and slow, or they need to scale up. If they scale up, they risk to leak traffic even wider. Scaling up also makes the operation more expensive, leading to incentives to make money somehow to finance it. Will the cookie car in the form of a massive data trove perhaps then be used/sold?
Users of these gateways get no promises, no rights, no contracts.
Other IPFS privacy concerns
Brave, the browser, has actual native IPFS support (not using any gateway) and they have an informative page called How does IPFS Impact my Privacy?
Final verdict
I am not dissing the idea nor implementation of IPFS itself. I think using HTTP gateways to access IPFS is a good idea in general as it makes the network more accessible. It is just a fragile solution that easily misleads users to do things they maybe shouldn’t. So maybe a little too accessible?
I poked the ffmpeg project over Twitter, there was immediate reaction and there is already a proposed patch for ffmpeg that removes the use of a default IPFS gateway. “it’s a security risk”
The .netrc file is used to hold user names and passwords for specific host names and allows tools to login to those systems automatically without having to prompt the user for the credentials while avoiding having to use them in command lines. The .netrc file is typically set without group or world read permissions (0600) to reduce the risk of leaking those secrets.
History
Allegedly, the .netrc file format was invented and first used for Berknet in 1978 and it has been used continuously since by various tools and libraries. Incidentally, this was the same year Intel introduced the 8086 and DNS didn’t exist yet.
.netrc has been supported by curl (since the summer of 1998), wget, fetchmail, and a busload of other tools and networking libraries for decades. In many cases it is the only cross-tool way to provide credentials to remote systems.
The .netrc file use is perhaps most widely known from the “standard” ftp command line client. I remember learning to use this file when I wanted to do automatic transfers without any user interaction using the ftp command line tool on unix systems in the early 1990s.
Example
A .netrc file where we tell the tool to use the user name daniel and password 123456 for the host user.example.com is as simple as this:
machine user.example.com
login daniel
password 123456
Those different instructions can also be written on the same single line, they don’t need to be separated by newlines like above.
Specification
There is no and has never been any standard or specification for the file format. If you google .netrc now, the best you get is a few different takes on man pages describing the format in a high level. In general this covers our needs and for most simple use cases this is good enough, but as always the devil is in the details.
The lack of detailed descriptions on how long lines or fields to accept, how to handle special character or white space for example have left the implementers of the different code basis to decide by themselves how to handle those things.
The horse left the barn
Since numerous different implementations have been done and have been running in systems for several decades already, it might be too late to do a spec now.
This is also why you will find man pages out there with conflicting information about the support for space in passwords for example. Some of them explicitly say that the file format does not support space in passwords.
Passwords
Most fields in the .netrc work fine even when not supporting special characters or white space, but in this age we have hopefully learned that we need long and complicated passwords and thus having “special characters” in there is now probably more common than back in the 1970s.
Writing a .netrc file with for example a double-quote or a white space in the password unfortunately breaks tools and is not portable.
I have found at least three different ways existing tools do the parsing, and they are all incompatible with each other.
curl parser (before 7.84.0)
curl did not support spaces in passwords, period. The parser split all fields at the following space or newline and accepted whatever is in between. curl thus supported any characters you want, except spaceand newlines . It also did not “unquote” anything so if you wanted to provide a password like ""llo (with two leading double-quotes), you would use those five bytes verbatim in the file.
wget parser
This parser allows a space in the password if you provide it quoted within double-quotes and use a backslash in front of the space. To specify the same ""llo password mentioned above, you would have to write it as "\"\"llo".
fetchmail parser
Also supports spaces in passwords. Here the double-quote is a quote character itself so in order to provide a verbatim double-quote, it needs to be doubled. To specify the same ""llo password mentioned above, you would have to write it as """"llo – that is with four double-quotes.
What is the best way?
Changing any of these parsers in an effort to unify risk breaking existing use cases and scripts out in the wild with outraged users as a result. But a change could also generate a few happy users too who then could better share the same .netrc file between tools.
In my personal view, the wget parser approach seems to be the most user friendly one that works perhaps most closely to what I as a user would expect. So that’s how I went ahead and made curl work.
What to do
Users will of course be stuck with ancient versions for a long time and this incompatibility situation will remain for the foreseeable future. I can think of a few work-arounds users can do to cope:
Avoid space, tabs, newline and various quotes in passwords
Use separate .netrc files for separate tools
Provide passwords using other means than .netrc – with curl you can for example explore using –config instead
Future curl supports quoting
We are changing the curl parser somewhat in the name of compatibility with other tools (read wget) and curl will allow quoted strings in the way wget does it, starting in curl 7.84.0. While this change risks breaking a few command lines out there (for users who have leading double-quotes in their existing passwords), I think the change is worth doing in the name of compatibility and the new ability to use spaces in passwords.
A little polish after twenty-four years of not supporting spaces in user names or passwords.
The first mention of QUIC on this blog was back when I posted about the HTTP workshop of July 2015. Today, this blog is readable over the protocol QUIC subsequently would turn into. (Strictly speaking, it turned into QUIC + HTTP/3 but let’s not be too literal now.)
The other day Fastly announced that all their customers now can enable HTTP/3, and since this blog and the curl site are graciously running on the Fastly network I went ahead and enabled the protocol.
Within minutes and with almost no mistakes, I could load content over HTTP/3 using curl or browsers. Wooosh.
The name HTTP/3 wasn’t adopted until late 2018, and the RFC has still not been published yet. Some of the specifications for QUIC have however.
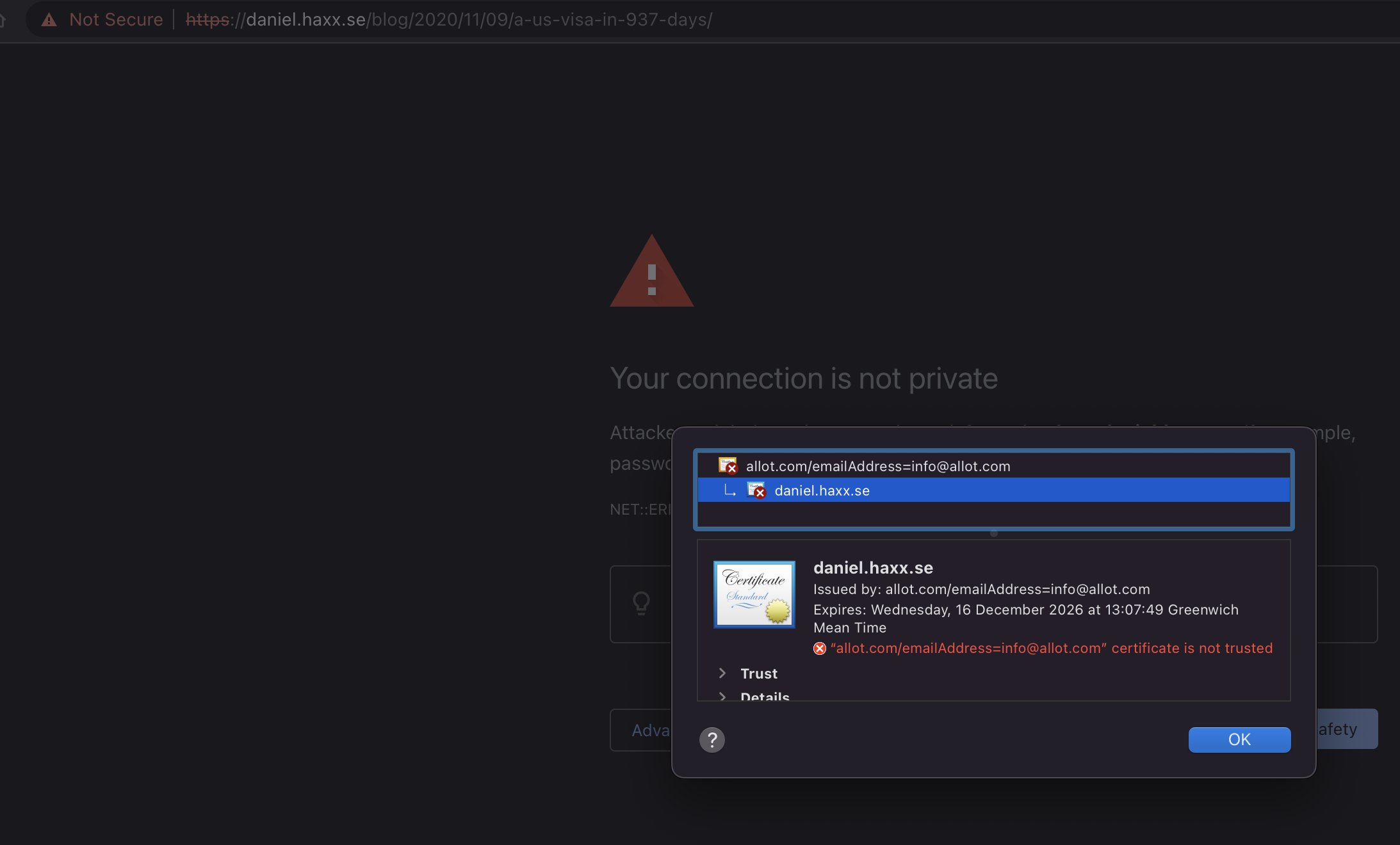
Vodafone UK has taken it on themselves to make the world better by marking this website (daniel.haxx.se) “adult content”. I suppose in order to protect the children.
It was first reported to me on May 2, with this screenshot from a Vodafone customer:
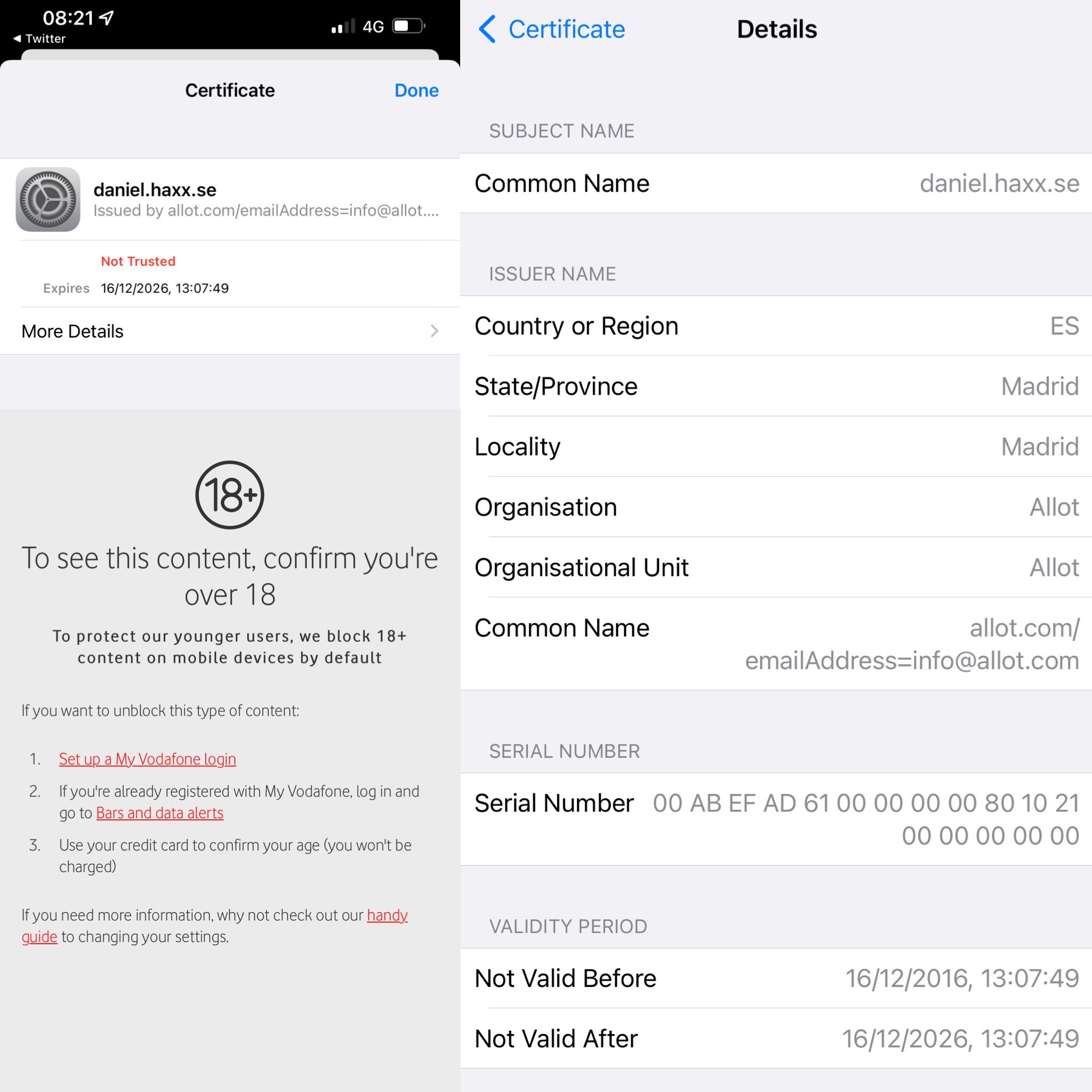
And later followed up with some more details from another user in this screenshot
Customers can opt out of this “protection” and then apparently Vodafone will no longer block my site.
How
I was graciously given more logs (my copy) showing DNS resolves and curl command line invokes.
It shows that this filter is for this specific host name only, not for the entire haxx.se domain.
It also shows that the DNS resolves are unaffected as they returned the expected Fastly IP addresses just fine. I suspect they have equipment that inspects outgoing traffic that catches this TLS connection based on the SNI field.
As the log shows, they then make their server do a TLS handshake in which they respond with a certificate that has daniel.haxx.se in the CN field.
The curl verbose output shows this:
* SSL connection using TLSv1.2 / ECDHE-ECDSA-CHACHA20-POLY1305
* ALPN, server did not agree to a protocol
* Server certificate:
* subject: CN=daniel.haxx.se
* start date: Dec 16 13:07:49 2016 GMT
* expire date: Dec 16 13:07:49 2026 GMT
* issuer: C=ES; ST=Madrid; L=Madrid; O=Allot; OU=Allot; CN=allot.com/emailAddress=info@allot.com
* SSL certificate verify result: self signed certificate in certificate chain (19), continuing anyway.
> HEAD / HTTP/1.1
> Host: daniel.haxx.se
> User-Agent: curl/7.79.1
> Accept: */*
>
The allot.com clue is the technology they use for this filtering. To quote their website, you can “protect citizens” with it.
I am not unique, clearly this has also hit other website owners. I have no idea if there is any way to appeal against this classification or something, but if you are a Vodafone UK customer, I would be happy if you did and maybe linked me to a public issue about it.
Update
I was pointed to the page where you can request to unblock specific sites so I have done that now (at 12:00 May 2).
Update on May 3
My unblock request for daniel.haxx.se is apparently “on hold” according to the web site.
I got an email from an anonymous (self-proclaimed) insider who says he works at Allot, the company doing this filtering for Vodafone. In this email, he says
Most likely, Vodafone is using their parental control a threat protection module which works based on a DNS resolving.
and then
After the business logic decides to block the website, it tells the DNS server to reply with a custom IP to a server that always shows a block page, because how HTTPS works, there is no way to trick it, either with Self-signed certificate, or using a signed certificate for a different domain, hence the warning.
What is weird here is that this explanation does not quite match what I have seen the logs provided to me. They showed this filtering clearly not being DNS based – since the DNS resolves got the exact same IP address a non-filtered resolver does.
Someone on Vodafone UK could of course easily test this by simply using a different DNS server, like 1.1.1.1 or 8.8.8.8.
Two years later the situation was the same and I wrote about it on Mastodon:
Just hours later I was emailed by a person who explained they are employed by Vodafone and they forwarded my post internally. The blocking should thereby be gone. The original block was wrongly applied and then my unblocking request from two years ago “never reached the responsible team”.
One of the toughest jobs I have, is to assess if a reported security problem is indeed an actual security vulnerability or “just” a bug. Let me take you through a recent case to give you an insight…
Some background
curl is 24 years old and so far in our history we have registered 111 security vulnerabilities in curl. I’ve sided with the “security vulnerability” side in reported issues 111 times. I’ve taken the opposite stance many more times.
Over the last two years, we have received 129 reports about suspected security problems and less than 15% of them (17) were eventually deemed actual security vulnerabilities. In the other 112 cases, we ended up concluding that the report was not pointing out a curl security problem. In many of those 112 cases, it was far from easy to end up with that decision and in several instances the reporter disagreed with us. (But sure, in the majority of the cases we could fairly quickly conclude that the reports were completely bonkers.)
The reporter’s view
Many times, the reporter that reports a security bug over on Hackerone has spent a significant amount of time and effort to find it, research it, reproduce it and report it. The reporter thinks it is a security problem and there’s a promised not totally insignificant monetary reward for such problems. Not to mention that a found and reported vulnerability in curl might count as something of a feat and a “feather in the hat” for a security researcher. The reporter has an investment in this work and a strong desire to have their reported issue classified as a security vulnerability.
The project’s view
If the reported problem is a security problem then we must consider it as that and immediately work on fixing the issue to reduce the risk of users getting hurt, and to inform all users about the risk and ask them to upgrade or otherwise mitigate and take precautions against the risks.
Most reported security issues are not immediately obvious. At least not in my eyes. I usually need to object, discuss, question and massage the data for a while in order to land on how we should best view the issue. I’m a skeptic by nature and I need to be convinced before I accept it.
Labeling something a “security vulnerability” if it indeed is not, is rather hurting users and the entire community rather than helping it. We must not cry wolf for a problem that cannot hurt users or that in practical terms is impossible to occur. Or maybe it is a problem that users are already expected to deal with. Or a result of an explicit or implicit application choice rather than a mistake done by us.
A bug in current libcurl makes it misbehave under certain conditions. When the MQTT connection gets closed mid message, libcurl refuses to acknowledge that and thinks the connection is still alive. Easily triggered by a malicious server.
libcurl considers the connection readable non-stop
Reading from the connection brings no more data
Busy-looping in the event-loop. Goto 2
The loop stops only once it reaches the set timeout, the progress callback can stop it and the speed-limit options will stop it if the right conditions are met.
By default, none of those options are set for a transfer and therefore, by default this makes an endless busy-loop.
At the same time…
A transfer can always stall and take a very long time to complete. A server can basically always just stop delivering more data, making the transfer take an infinite amount of time to complete. Applications that have not set any options to stop such a transfer risk doing a transfer that never ends. An endless transfer.
Also: if libcurl makes a transfer over a really fast network, such as localhost or using a super fast local network, then it might also reach the same level of busy-loop due to never having to wait for data. Albeit for a limited amount of time – until the transfer is complete. This busy-loop is highly unlikely to actually starve out any important threads in a system.
Yes, a closed connection is a much “cheaper” attack from server’s point of view than maintaining a long-living connection, but the cost of the attack is not a factor here.
Where in this grey area do we land?
This is difficult one.
I can see the point of the reporter, but I can also see how this flaw will basically not hurt any existing curl user. Where is our responsibility here?
I ended up concluding that this issue not a security vulnerability. The reporter disagreed.
It is a terribly annoying bug for sure. But the only applications that are seriously affected by it, are the ones that already allow an endless transfer.
The bug-fix was instead submitted as a normal pull-request: PR 8644, targeted to be fixed and included in the pending curl 7.83.0 release.
We publicize the reports after the fact
We make all (non-rubbish) previously reported hackerone issues public, whether they ended up being a vulnerability or not. To give everyone involved time to object or redact sensitive details, the publication date is usually within a month after the issue was closed.
By making the reports public, we allow everyone interested enough the ability and chance to check out and follow past discussions and deliberations for going the directions we did. The idea is primarily to be completely open about the reported issues and how we classify them, to show that we are not hiding anything and it also provides a chance for us to get more feedback from the surrounding and from security people who might disagree with previous analyses.
On March 16 2022, the curl security team received an email in which the reporter highlighted an Apple web page. What can you tell us about this?
I hadn’t seen it before. On this page with the title “About the security content of macOS Monterey 12.3”, said to have been published just two days prior, Apple mentions recent package upgrades and the page lists a bunch of products and what security fixes that were done for them in this update. Among the many products listed, curl is mentioned.
This is what the curl section of the page looked like:
Screenshot from March 17, 2022
In the curl project we always make all CVEs public with as much detail as we can possibly extract and provide about them. We take great pride in being the best in class in security flaw information and transparency.
Apple listed four CVE fixed. The three first IDs we immediately recognized from the curl security page. The last one however, was a surprise. What was that?
CVE-2022-22623
This is not a CVE published by the curl project. The curl project has in fact not shipped any CVE at all in 2022 (yet) so that’s easy to spot. When we looked at the MITRE registration for the ID, it also didn’t disclose any clues really. Not that it was expected to. It did show it was created on January 5 though, so it wasn’t completely new.
Was it a typo?
I compared this number to other recent CVE numbers announced from curl and I laid eyes on CVE-2021-22923 which had just two digits changed. Did they perhaps mean that CVE?
The only “problem” with that CVE is that it was in regards to Metalink and I don’t think Apple ever shipped their curl package with metalink support so therefore they wouldn’t have fixed a Metalink problem. So probably not a typo for that number at least!
I reached out to a friend at Apple as well with an email to Apple Product Security.
Security is our number one priority
In the curl project, we take security seriously. The news that there might be a security problem in curl that we haven’t been told about and that looks like it was about to get public sooner or later was of course somewhat alarming and something we just needed to get to the bottom of. It was also slightly disappointing that a large vendor and packager of curl since over 20 years would go about it this way and jab this into our back.
No source code
Apple has not made the source code for their macOS 12.3 version and the packages they use in there public, so there was no way for us to run diffs or anything to check for the exact modifications that this claimed fix would’ve resulted in.
Apple said so
Several “security websites” (the quotes are there to indicate that clearly these sites are more security in the name than in reality) immediately posted details about this “vulnerability”. Some of them with CVSS scores and CWE numbers , explaining how this problem can hurt users. Obviously completely made up since none of that info was made available by any first party sources anywhere. Not from Apple and not from the curl project. If you now did a web search on that CVE number, several of the top search results linked to such sites providing details – obviously made up from thin air.
As I think these sites don’t add much value to humanity, I won’t link to them here but instead I will show you a screenshot from such an article to show you what a made up CVE number posted by Apple can make people claim:
Screenshot from exploitone.com
At 23:28 (my time zone) on the 17th, my Apple friend responded saying they had forwarded the issue to “the right team”.
The Apple Product Security team I also emailed about this issue, answered at 00:23 (still my time) on the 18th saying “we are looking into this and will provide an update soon when we have more information.”
The MITRE page got more details
The MITRE CVE page from March 21st
After the weekend passed with no response, I looked back again on the MITRE page for the CVE in question and it had then gotten populated with additional curl details; mentioning Apple as CNA and now featuring links back to the Apple page! Now it really started to look like the CVE was something real that Apple (or someone) had registered but not told us about. It included real curl related snippets like this:
Multiple issues were addressed by updating to curl version 7.79.1. This issue is fixed in macOS Monterey 12.3. Multiple issues in curl.
Please tell us more details
On Monday the 21st, I continued to get questions about this CVE. Among others, from a member of a major European ISP’s CERT team curious about this CVE as they couldn’t find any specific information about this issue either and they were concerned they might have this vulnerability in the curl versions they run. They of course (rightfully) assumed that I would know about curl CVEs.
It turns out that when a major company randomly mentions a new CVE, it actually has an impact on the world!
Gone!
At around 20:30 on March 21st, someone on Twitter spotted that the ghost CVE had been removed from Apple’s web page and it only listed three issues (and a mention that the section had been updated). At 21:39 I get an email response from Apple Product Security:
Thank you for reaching out to us about the error with this CVE on our security advisory. We’ve updated our site and requested that MITRE reject CVE-2022-22623 on their end.
Please let us know if you have any questions.
Screenshot from March 21, 2022
The reject request to MITRE is expected to be slow so that page will remains showing the outdated data for a while longer.
Exploit one
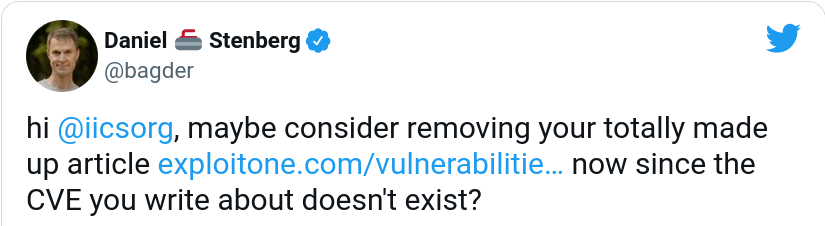
When Apple had retracted the wrong CVE, I figured I should maybe try to get exploitone.com to remove their “article” to maybe at least stop one avenue of further misinformation about this curl “issue”. I tweeted (in perhaps a tad bit inflammatory manner):
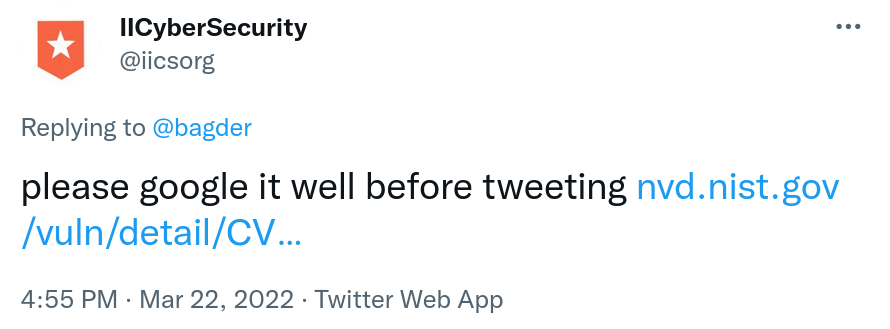
I get the feeling they didn’t quite understand my point. They replied:
What happened?
As I had questions about Apple’s mishap, I replied (sent off 22:28 on the 21st, still only early afternoon on the US west coast), asking for details on what exactly had happened here. If it was a typo, then how come it got registered with MITRE? It’s just so puzzling and mysterious!
When I’m posting this article on my blog (36 hours after I sent the question), I still haven’t gotten any response or explanation. I don’t expect to get any either, but if I do, I will update this post accordingly.
Update March 26
exploitone.com updated their page at some point after my tweet to remove the mention of the imaginary CVE, but the wording remains very odd:
I’ve talked on this topic before but I realized I never did a proper blog post on the topic. So here it is: how we develop curl to keep it safe. The topic of supply chain security is one that is discussed frequently these days and every so often there’s a very well used (open source) component that gets a terrible weakness revealed.
Don’t get me wrong. Proprietary packages have their share of issues as well, and probably even more so, but for obvious reasons we never get the same transparency, details and insight into those problems and solutions.
If we would find a critical vulnerability in curl, it could potentially exist in every internet-connected device on the globe. We don’t want that.
A critical security flaw in our products would be bad, but we also similarly need to make sure that we provide APIs and help users of our products to be safe and to use curl safely. To make sure users of libcurl don’t accidentally end up getting security problems, to the best of our ability.
In the curl project, we work hard to never have our own version of a “heartbleed moment“. How do we do this?
Always improving
Our method is not strange, weird or innovative. We simply apply all best practices, tools and methods that are available to us. In all areas. As we go along, we tighten the screws and improve our procedures, learning from past mistakes.
There are no short cuts or silver bullets. Just hard work and running tools.
Not a coincidence
Getting safe and secure code into your product is not something that happens by chance. We need to work on it and we need to make a concerned effort. We must care about it.
We all know this and we all know how to do it, we just need to make sure that we also actually do it.
The steps
Write code following the rules
Review written code and make sure it is clear and easy to read.
Test the code. Before and after merge
Verify the products and APIs to find cracks
Bug-bounty to reward outside helpers
Act on mistakes – because they will happen
Writing
For users of libcurl we provide an API with safe and secure defaults as we understand the power of the default. We also document everything with details and take great pride in having world-class documentation. To reduce the risk of applications becoming unsafe just because our API was unclear.
We also document internal APIs and functions to help contributors write better code when improving and changing curl.
We don’t allow compiler warnings to remain – on any platform. This is sometimes quite onerous since we build on such a ridiculous amount of systems.
We encourage use of source code comments and assert()s to make assumptions obvious. (curl is primarily written in C.)
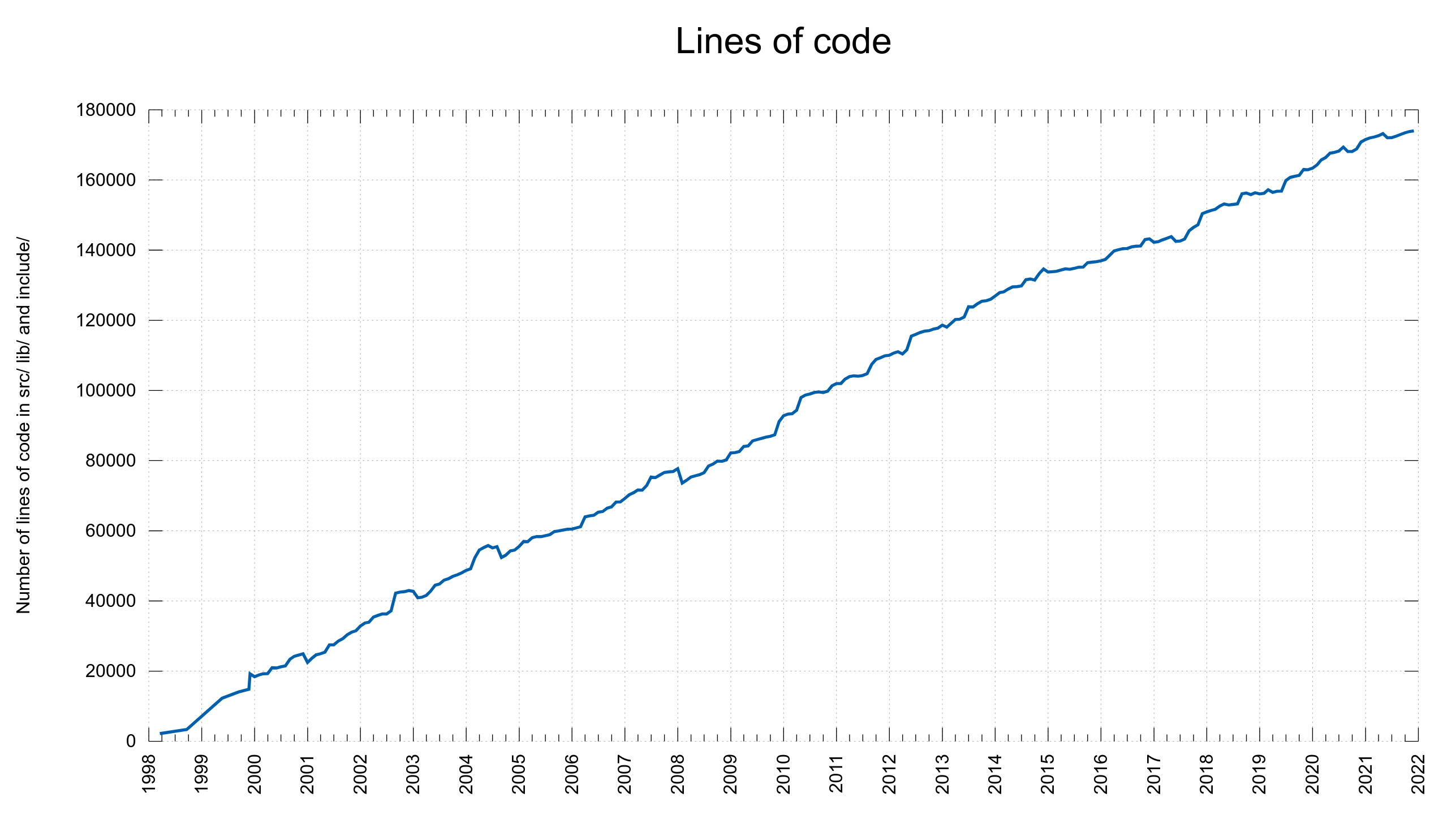
Number of lines of (product) code in the curl project over time.
Review
All code should be reviewed. Maintainers are however allowed to review and merge their own pull-requests for practical reasons.
Code should be easy to read and understand. Our code style must be followed and encourages that: for example, no assignments in conditions, one statement per line, no lines longer than 80 columns and more.
Strict compliance with the code style also means that the code gets a flow and a consistent look, which makes it easier to read and manage. We have a tool that verifies most aspects of the code style, which takes away most of that duty away from humans. I find that PR authors generally take code style remarks better when pointed out by a tool than when humans do it.
A source code change is accompanied with a git commit message that need to follow the template. A consistent commit message style makes it easier to later come back and understand it proper when viewing source code history.
Test
We want everything tested.
Unit tests. We strive at writing more and more unit tests of internal functions to make sure they truly do what expected.
System tests. Do actual network transfers against test servers, and make sure different situations are handled.
Integration tests. Test libcurl and its APIs and verify that they handle what they are expected to.
Documentation tests. Check formats, check references and cross-reference with source code, check lists that they include all items, verify that all man pages have all sections, in the same order and that they all have examples.
“Fix a bug? Add a test!” is a mantra that we don’t always live up to, but we try.
curl runs on 80+ operating systems and 20+ CPU architectures, but we only run tests on a few platforms. This usually works out fine because most of the code is written to run on multiple platforms so if tested on one, it will also run fine on all the other.
curl has a flexible build system that offers many million different build combinations with over 30 different possible third-party libraries in countless version combinations. We cannot test all build combos, but we try to test all the popular ones and at least one for each config option enabled and disabled.
We have many tests, but there are unfortunately still gaps and details not tested by the test suite. For those things we simply have to rely on the code review and then that users report problems in the shipped products.
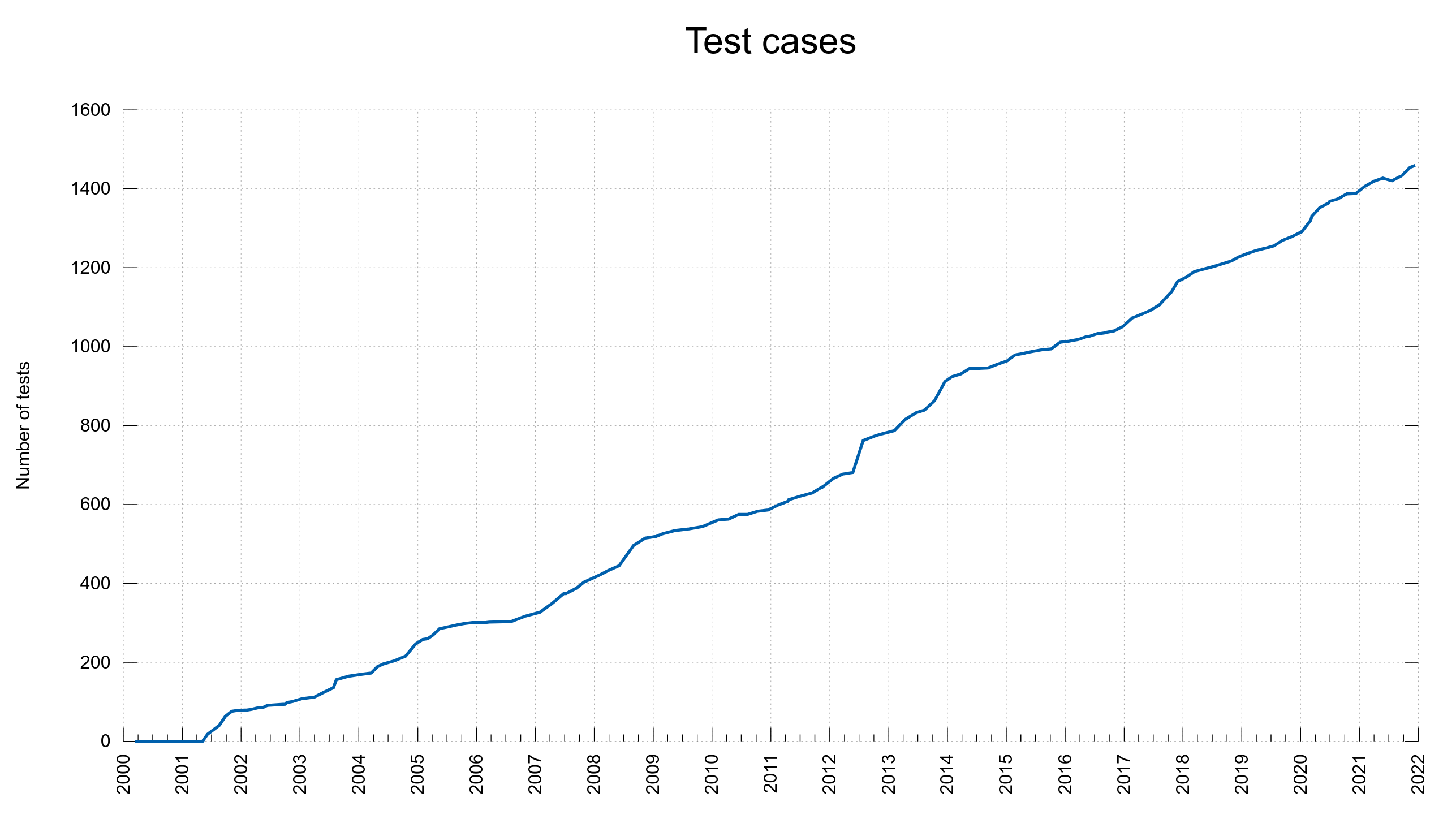
Number of test cases, test files really, over time.
Verify
We run all the tests using valgrind to make sure nothing leaks memory or do bad memory accesses.
We build and run with address, undefined behavior and integer overflow sanitizers.
We are part of the OSS-Fuzz project which fuzzes curl code non-stop, and we run CIFuzz in CI builds, which runs “a little” fuzzing on the curl code in the normal pull-request process.
We do “torture testing“: run a test case once and count the number of “fallible” function calls it makes. Those are calls to memory allocation, file operations, socket read/write etc. Then re-run the test that many times, and for each new iteration we make another one of the fallible functions fail and return error. Verify that no memory leaks or crashes occur. Do this on all tests.
We use several different static code analyzers to scan the code checking for flaws and we always fix or otherwise handle every reported defect. Many of them for each pull-request and commit, some are run regularly outside of that process:
scan-build
clang tidy
lgtm
CodeQL
Lift
Coverity
The exact set has varied and will continue to vary over time as services come and go.
Bug-bounty
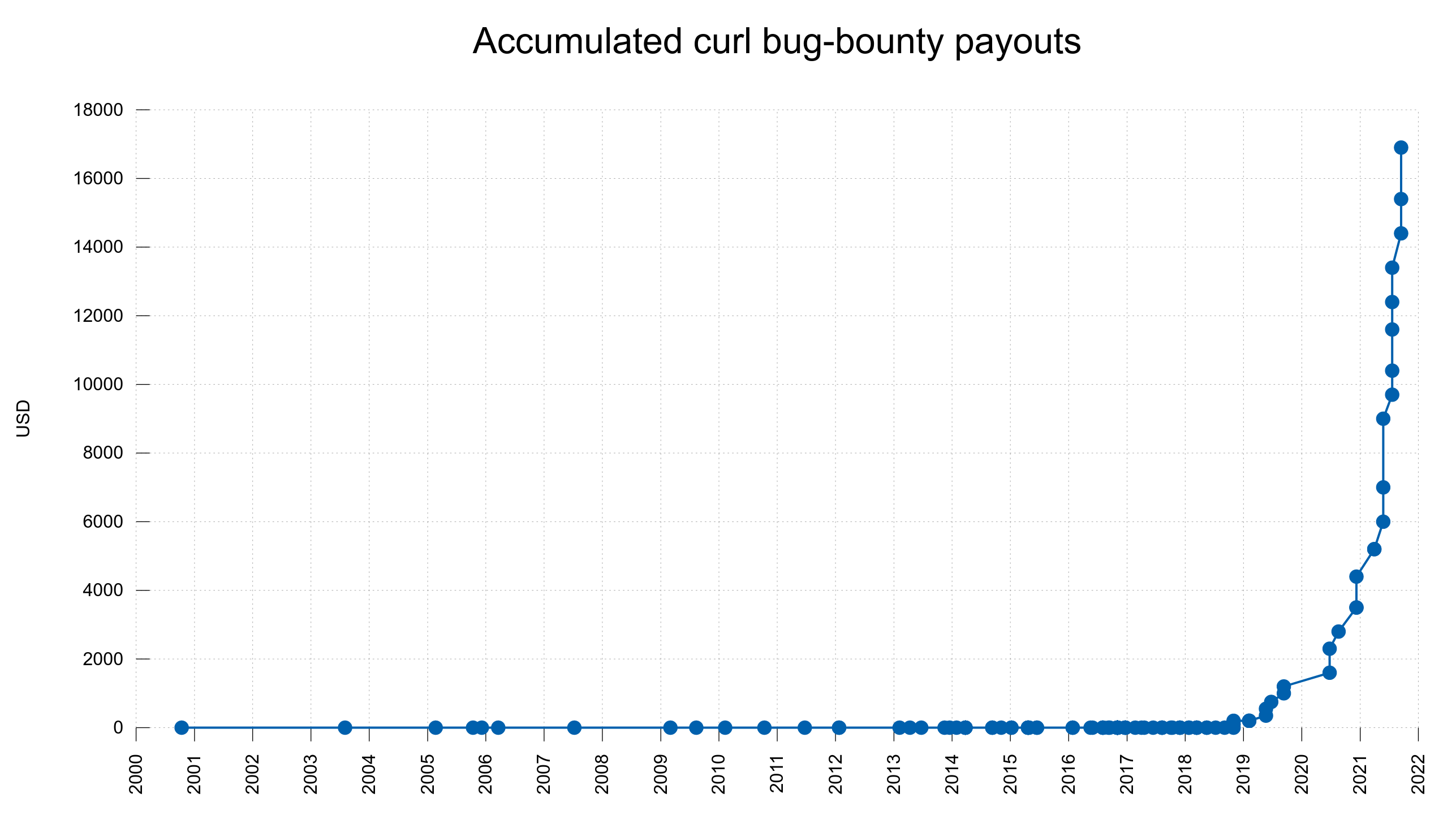
No matter how hard we try, we still ship bugs and mistakes. Most of them of course benign and harmless but some are not. We run a bug-bounty program to reward security searchers real money for reported security vulnerabilities found in curl. Until today, we have paid almost 17,000 USD in total and we keep upping the amounts for new findings.
Accumulated bug-bounty payouts over time
When we report security problems, we produce detailed and elaborate advisories to help users understand every subtle detail about the problem and we provide overview information that shows exactly what versions are vulnerable to which problems. The curl project aims to also be a world-leader in security advisories and related info.
Act on mistakes
We are not immune, no matter how hard we try. Bad things will happen. When they do, we:
Act immediately.
Own the problem, responsibly
Fix it and announce it – as soon as possible
Learn from it
Make it harder to do the same or similar mistakes again
Does it work? Do we actually learn from our history of mistakes? Maybe. Having our product in ten billion installations is not a proof of this. There are some signs that might show we are doing things right:
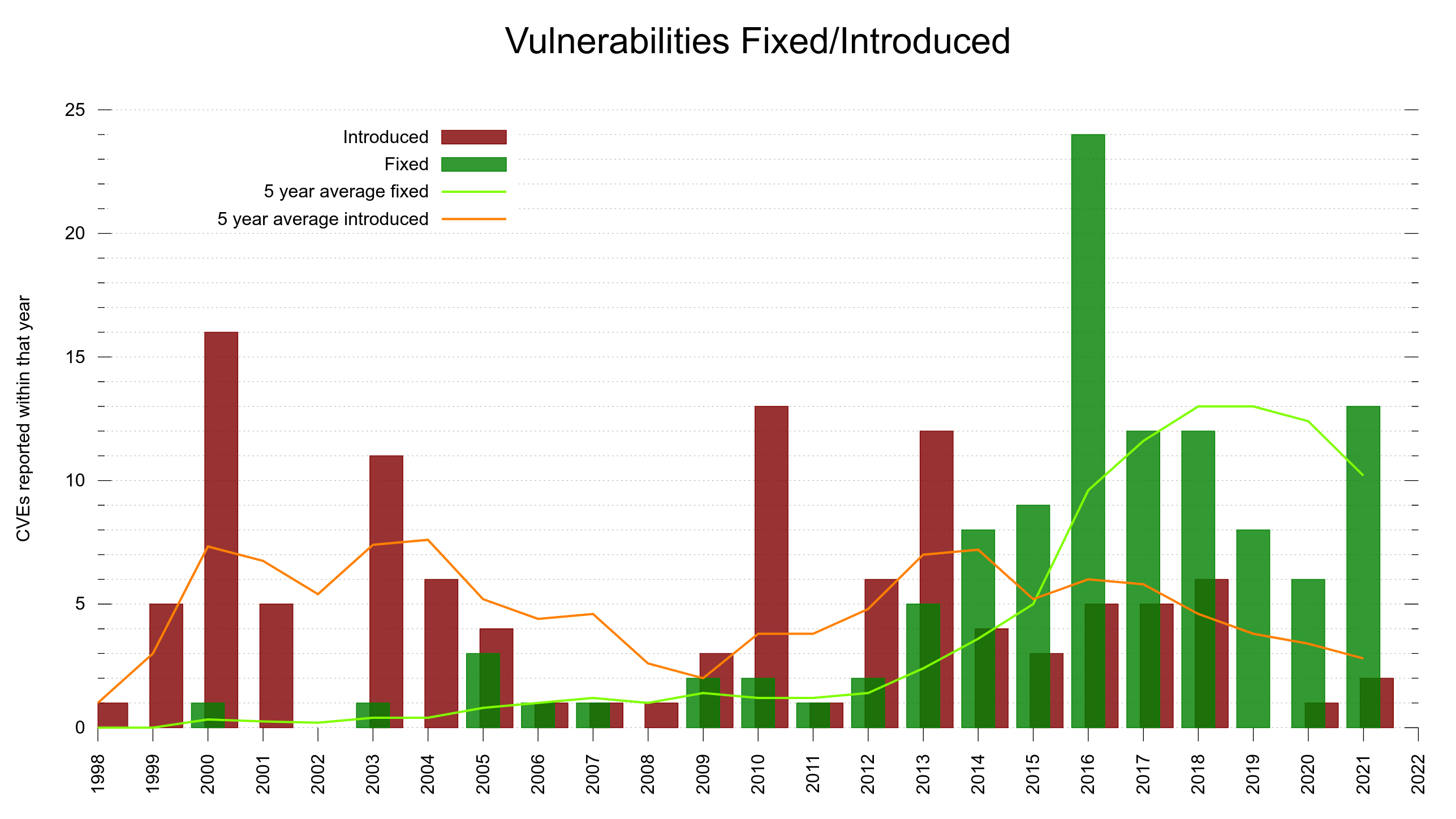
We were reporting fewer CVEs/year the last few years but in 2021 we went back up. It could also be the result of more people looking, thanks to the higher monetary rewards offered. At the same time the number of lines of code have kept growing at a rate of around 6,000 lines per year.
We get almost no issues reported by OSS-Fuzz anymore. The first few years it ran it found many problems.
We are able to increase our bug-bounty payouts significantly and now pay more than one thousand USD almost every time. We know people are looking hard for security bugs.
Security vulnerabilities. Fixed vs Introduced over the years.
Continuous Integration
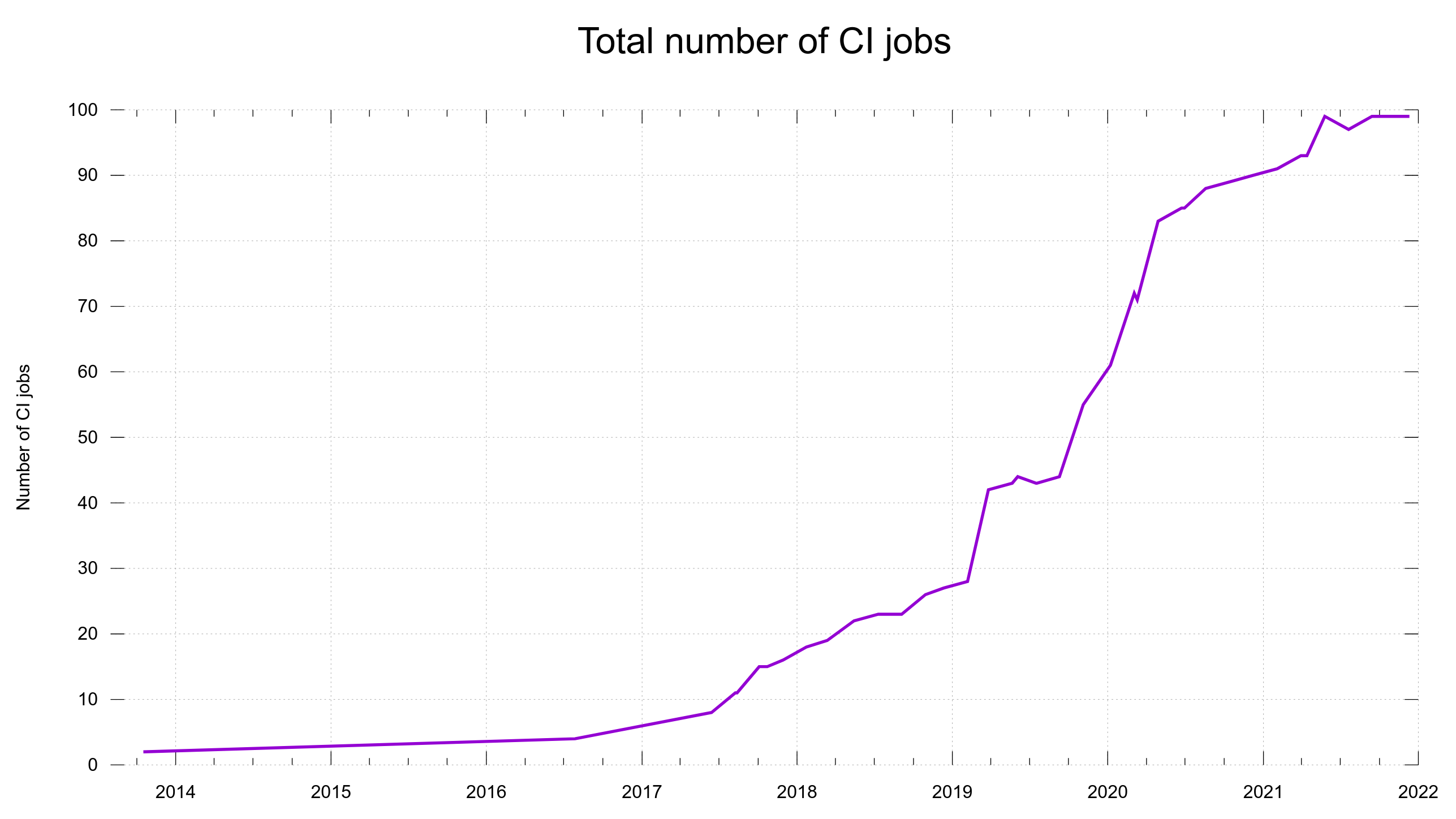
For every pull-request and commit done in the project, we run about 100 different builds + test rounds.
Total number of CI builds per pull-request and commit, over time
Done using several different CI services for maximum performance, widest possible coverage and shortest time to completion.
We currently use the following CI services: Cirrus CI, AppVeyor, Azure Pipelines, GitHub Actions, Circle CI and Zuul CI.
We also have a separate autobuild system with systems run by volunteers that checkout the latest code, build, run all the tests and report back in a continuous manner a few times or maybe once per day.
New habits past mistakes have taught us
We have done several changes to curl internals as direct reactions to past security vulnerabilities and their root causes. Lessons learned.
Unified dynamic buffer functions
These days we have a family of functions for working with dynamically sized buffers. Be using the same set for this functionality we have it well tested and we reduce the risk that new code messes up. Again, nothing revolutionary or strange, but as curl had grown organically over the decades, we found ourselves in need of cleaning this up one day. So we did.
Maximum string sizes
Several past mistakes came from possible integer overflows due to libcurl accepting input string sizes of unrestricted lengths and after doing operations on such string sizes, they would sometimes lead to overflows.
Since a few years back now, no string passed to curl is allowed to be larger than eight megabytes. This limit is somewhat arbitrarily set but is meant to be way larger than the largest user names and passwords ever used etc. We could also update the limit in a future, should we want. It’s not a limit that is exposed in the API or even mentioned. It is there to trap mistakes and malicious use.
Avoid reallocs
Thanks to the previous points we now avoid realloc as far as possible outside of those functions. History shows that realloc in combination with integer overflows have been troublesome for us. Now, both reallocs and integer overflows should be much harder to mess up.
Code coverage
A few years ago we ran code coverage reports for one build combo on one platform. This generated a number that really didn’t mean a lot to anyone but instead rather mislead users to drawing funny conclusions based on the report. We stopped that. Getting a “complete” and representative number for code coverage for curl is difficult and nobody has yet gone back to attempt this.
The impact of security problems
Every once in a while someone discovers a security problem in curl. To date, those security vulnerabilities have been limited to certain protocols and features that are not used by everyone and in many cases even disabled at build-time among many users. The issues also often rely on either a malicious user to be involved, either locally or remotely and for a lot of curl users, the environments it runs in limit that risk.
To date, I’m not aware of any curl user, ever, having been seriously impacted by a curl security problem.
This is not a guarantee that it will not ever happen. I’m only stating facts about the history so far. Security is super hard and I can only promise that we will keep working hard on shipping secure products.
Is it scary?
Changes done to curl code today will end up in billions of devices within a few years. That’s an intimidating fact that could truly make you paralyzed by fear of the risk that the world will “burn” due to a mistake of mine.
Rather than instilling fear by this outlook, I think the proper way to think it about it, is respecting the challenge and “shouldering the responsibility”. Make the changes we deem necessary, but make them according to the guidelines, follow the rules and trust that the system we have setup is likely to detect almost every imaginable mistake before it ever reaches a release tarball. Of course we plug holes in the test suite that we spot or suspect along the way.
The back-door threat
I blogged about that recently. I think a mistake is much more likely to slip-in and get shipped to the world than a deliberate back-door is.
Memory safe components might help
By rewriting parts of curl to use memory safe components, such as hyper for HTTP, we might be able to further reduce the risk of future vulnerabilities. That’s a long game to make reality. It will also be hard in the future to actually measure and tell for sure if it truly made an impact.
How can you help out?
Pay for a curl support contract. This is what enables me to work full time on curl.
Help out with reviews and adding new tests to curl
Help out with fixing issues and improving the code
An unexpected or undocumented feature in a piece of computer software, included as a joke or a bonus.
There are no Easter eggs in curl. For the good.
I’ve been asked about this many times. Among the enthusiast community, people seem to generally like the concept of Easter eggs and hidden treasures, features and jokes in software and devices. Having such an embedded surprise is considered fun and curl being a cool and interesting project should be fun too!
With the risk of completely ruining my chances of ever being considered a fun person, I’ll take you through my thought process on why curl does not feature any such Easter eggs and why it will not have any in the future either.
Trust
The primary and main reason is the question of trust.
We deliver products with known and documented functionality. Everything is known and documented. There’s nothing secret or hidden. The users see it all, can learn it all and it all is documented. We are always 100% transparent.
curl is installed in some ten billion installations to date and we are doing everything we can to be responsible and professional to make sure curl can and will be installed in many more places going forward.
Having an Easter egg in curl would violate several of the “commandments” we live by. If we could hide an Easter egg, what else is there that we haven’t shown or talked about?
Security
Everything in curl needs to be scrutinized, poked at, “tortured” and reviewed for security. An Easter egg would as well, as otherwise it would be an insecure component and therefor a security risk. This makes it impossible to maintain an Easter egg even almost secret.
Adding code to perform an Easter egg would mean adding code that potentially could cause problems to users by the plain unexpected nature of an Easter egg. Unexpected behavior is not a good foundation for security and secure procedures.
Boring is good
curl is not meant to be “fun” (on that fun scale). curl is here to perform its job, exactly as documented and expected and it is not meant to be fun. Boring is good and completely predictable. Boring is to deliver nothing else than the expected.
Even more security
If we would add an Easter egg, which by definition would be a secret or surprise to many, it would need to be hidden or sneaked in somehow and remain undocumented. We cannot allow code or features to get “snuck in” or remain undocumented.
If we would allow some features to get added like that, where would we draw the line? What other functionality and code do we merge into curl without properly disclosing and documenting it?
Useless work
If we would allow an Easter egg to get merged, we would soon start getting improvements to the egg code and people would like to add more eggs and to change the existing one. We would spend time and effort on the silly parts and we would need to spend testing and energy on these jokes instead of the real thing. We already have enough work without adding irrelevant work to the pile.
“Unintended Easter eggs”
We frequently ship bugs and features that go wrong. Due to fluke or random accidents, some of those mistakes can perhaps at times almost appear as Easter eggs, if you try hard. Still, when they are not done on purpose they are just bugs – not Easter eggs – and we will fix them as soon as we get them reported and have the chance.
A cover-up?
Yes, some readers will take this denial as a sign that there actually exists an Easter egg in curl and I am just doing my best to hide it. My advice to you, if you are one of those thinking this, is to read the code. We all benefit if more people read and carefully investigate the code so we will just be happy if you do and then ask us about whatever you think is unclear or “suspicious”.
I am not judging
This is not a judgement on projects that ship Easter eggs. I respect and acknowledge that different projects and people resonate differently on these topics.
In a world that is now gradually adopting HTTP/3 (which, as you know, is implemented over QUIC), the problem with the missing API for QUIC is still a key problem.
There are a number of existing QUIC library implementation now since a few years back, and they are slowly maturing. The QUIC protocol became RFC 9000 and friends, but the most popular TLS libraries still don’t provide the necessary APIs to make QUIC libraries possible to use them.
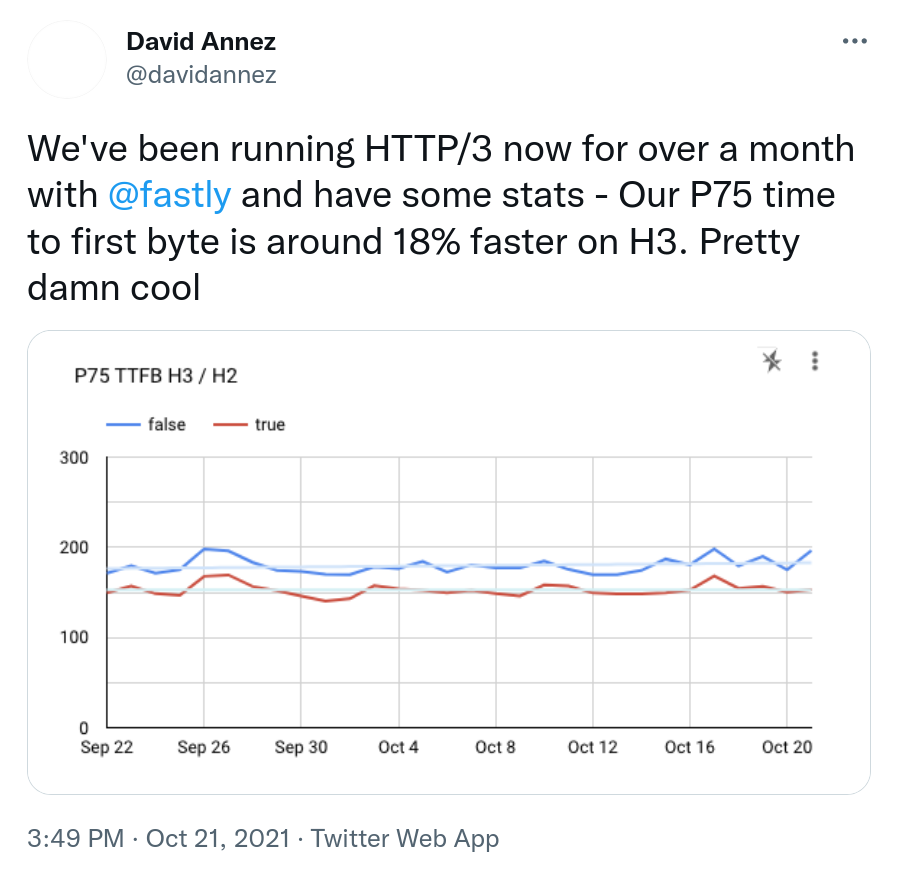
Example that makes people want HTTP/3
Example tweet of what makes people keen on experimenting and deploying HTTP/3.
OpenSSL PR8797
For a long time, many people and projects (including yours truly) in the QUIC community were eagerly following the OpenSSL Pull Request 8797, which introduced the necessary QUIC APIs into OpenSSL. This change brought the same API to OpenSSL that BoringSSL already provides and as such the API has already been used and tested out by several independent implementations.
Implementations have a problem to ship to the world based on BoringSSL since that’s a TLS library without versions and proper releases, so it is not a good choice for the big wide world. OpenSSL is already the most widely used TLS library out there and lots of applications are already made to use that.
Delays made quictls happen
The OpenSSL PR8797 was delayed back in February 2020 on when the OpenSSL management committee (OMC) decreed that they would not deal with that PR until after their pending 3.0.0 release had shipped.
“It is our expectation that once the 3.0 release is done, QUIC will become a significant focus of our effort.”
OpenSSL then proceeded and their 3.0.0 release was delayed significantly compared to their initial time schedule.
In March 2021, Microsoft and Akamai announcedquictls, an OpenSSL fork with the express idea to ship OpenSSL + the QUIC API. They didn’t want to wait for OpenSSL to do it.
Several QUIC libraries can now use quictls. quictls has kept their fork up to date and now offers the equivalent of OpenSSL 3.0.0 + the QUIC API.
While we’ve been waiting for OpenSSL to adopt the API.
OpenSSL makes a turn instead
Then came the next blow to everyone’s expectations. An autumn surprise. On October 13, the OpenSSL OMC announces:
The focus for the next releases is QUIC, with the objective of providing a fully functional QUIC implementation over a series of releases (2-3).
OpenSSL has decided to implement a complete QUIC stack on their own and with the given time line it sounds like it will take them a few years (?) to ship. And instead of providing the API lots of implementers have been been waiting for so long, they explicitly say that it is a non-goal at the start:
The MVP will not contain a library API for an HTTP/3 implementation (it is a non-goal of the initial release).
I didn’t write my own QUIC implementation but I’ve followed the work of several of the implementations fairly closely and it is fairly complicated journey they set out for themselves – for very unclear reasons. There already exist several high quality QUIC libraries, why does OpenSSL think they need to make yet another one? They seem to be overloaded with work already before, which the long delays of the 3.0.0 release seemed to show, how are they going to be able to add a complete new stack implementation of top of this? The future will tell.
PR8797 closed
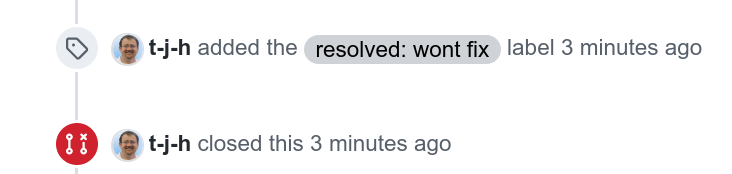
On October 20 2021, the pull request that was created in April 2019, is finally closed for real as a “won’t fix”.
Screenshot of the actual closing of the PR
Where are we now?
The lack of a QUIC API in OpenSSL has held us back and with this move from OpenSSL, it will continue to hold us back for an uncertain amount of time going forward.
QUIC stacks will have to stick to using or switching to other libraries.
I’m disappointed.
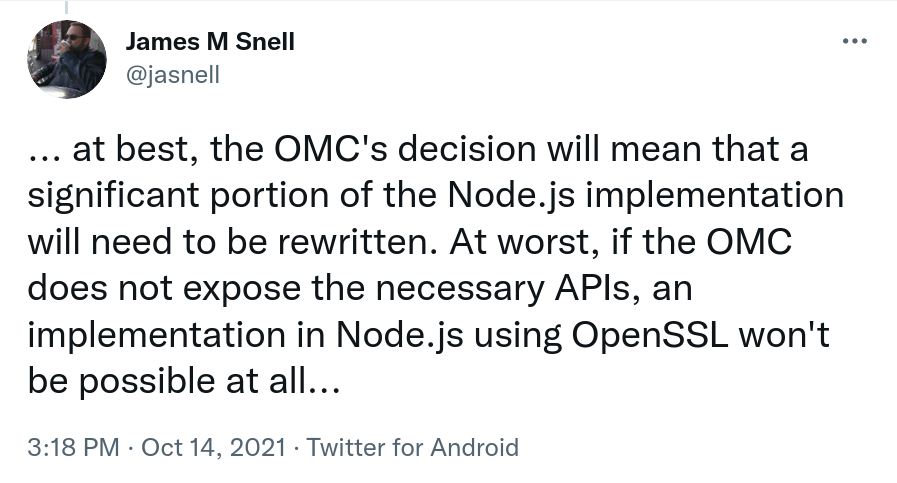
James Snell, one of the key contributors on the QUIC and HTTP/3 work in nodejs tweeted:
Back in February of this year, I received one of the most chilling emails in my life when someone threatened my life: “I will slaughter you“.
That email penetrated something deep into my soul and heart and I was not quite myself for a few days.
Almost six month later (a few days ago), I received another email from a person who claims to be this “Al Nocai” from that first threat. I read the beginning of this email several times before I actually could make myself continue past the opening paragraphs. Slightly worried what to find, with the memories from the last time coming back.
This email however, says “an apology” in the subject. I believe this email is written by the same guy.
The long and full apology is inserted below. The gist of it is: he claims to have been the victim of all sorts of bad stuff by several people named “Dan” and I got lumped in there because of my first name. He (?) also says he suffers from schizophrenia.
I’m publishing this partly because I got a lot of attention when I made the initial threat public so I figure it could be interesting for some to learn about this development. I can of course not verify that this is in fact the same person nor will I even attempt to verify any of his many claims of wrongdoings against him.
I’m happy for “Al” that he’s getting help and tries to move on. For me, this apology at least finally proves that this threat is over and in fact never was intended literally. I hope I will never receive anything close to that again.
The apology in full
I am Al Nocai. When I contacted you initially, I believed you to be a Dan E., from texas, or a Dan S from delaware or a Dan from Minneapolis. I didn’t do my research, and when I found it was actually you and you had nothing to do with my situation, I became indignant and even more of an asshole. You had every right to be mad, and publish as you did. I’m not trying to justify what I did, there is none, I should have been a lot more cordial. I just want to provide context around what was happening, I believe I at least owe you why.
I had to retire from my career do to schizophrenia. Again, I should have not let my delusions go to the point they did nor should I have acted the way it does. My illness doesn’t detract from the rashness of my actions.
I, at the time, lost my defense project after getting hacked through the Department of Veterans Affairs in the US. It was a few years into development, and it was meant to be a pathway to get homeless veterans off the streets. I was trying to develop a “trade-route” in tech. At the time I was very lucid. I was volunteering regularly in my community and I had a great family life. In October 2020, there was an attempt on my life which left me bludgeoned and near death with 2 orbital fractures. These event led me to uncover a massive money laundering operation and then had ties elsewhere. I then got hacked. When I say hacked, I lost every device. They rooted my charge arbitrator, I was bios bonded and I basically lost every document and all my software.
The people who did it gloated to me about it to me through linkedin. Trying to take my computers back, I ended up QAing a lot of their malware. This led to be being whaled for months. People attempted to blackmail me, they stole my identity and I was lied to about what I was doing as the people approaching me hid their relations to the people who initially hacked me.
These stressors where the predicates to my psychotic break. My federal correspondence about the hacking was re-routed. I had people impersonating microsoft employees. I even had a $50 billion dollar mortgage servicer trying to sue me over tweets. I also had firms like outpost 24 doing MiTM attacks on me, which is also a factor as I didnt realize at first where all my EU Certs were coming from in my Active directory.
Last, just to give you a clearer picture at how much I was monitored: I ended up not being able to take anything back in Windows. They were in my Windows Registry directly from install. Finding what I did, I believe I misattributed a good amount of sloppy programming to malicious behavior due to stress and paranoia.
So why did I believe you to be someone else? All the people responsible for these actions, well most of them were named Dan. They were mostly ex-google employees. Which is why my results changed and I ended up with about 19k various porn accounts in my name. This, they were also posing as random people named Dan (i.e. when IO tried telling Convercent, Microsoft’s auditor) about the issues. They were named Dan, and they were fraudulent.
So when I found what I did, and as well maintained as I did, I jumped the gun and assumed you were, again, one of the individuals I had whaling me. And at that point, after going to every agency I could, state and local, about the issue, I was a vicious dog backed into a corner. And I also at the time didn’t mean I’d physically harm you. I meant I was going to keep taking out your site.
Again, this doesn’t excuse my behavior. And in the end after all I tried to do to report everything that was happening. I ended up making the people who whaled me a lot of money. And I ended up still losing everything, but I also hurt and was a real asshole to a lot of people that had nothing to do with anything.
In the end, I had a hard time realizing what I did and the curl reason was a piss poor one. Again, I was just being an indignant ass. Especially to someone who actually reported security issues.
Sorry it took me a long time to write this. I should have apologized right after I knew I was wrong. I apologize for that mistake as well.
This amends is also a part of my getting better. So I apologize if this angered you. I just needed to make sure I tell you that I was wrong and I should have had betterjudgement.