

— “Have you ever detected anyone trying to add a backdoor to curl?”
— “Have you ever been pressured by an organization or a person to add suspicious code to curl that you wouldn’t otherwise accept?”
— “If a crime syndicate would kidnap your family to force you to comply, what backdoor would you be be able to insert into curl that is the least likely to get detected?” (The less grim version of this question would instead offer huge amounts of money.)

I’ve been asked these questions and variations of them when I’ve stood up in front of audiences around the world and talked about curl and how it is one of the most widely used software components in the world, counting way over three billion instances.
Back door (noun)
— a feature or defect of a computer system that allows surreptitious unauthorized access to data.
So how is it?
No. I’ve never seen a deliberate attempt to add a flaw, a vulnerability or a backdoor into curl. I’ve seen bad patches and I’ve seen patches that brought bugs that years later were reported as security problems, but I did not spot any deliberate attempt to do bad in any of them. But if done with skills, certainly I wouldn’t have noticed them being deliberate?
If I had cooperated in adding a backdoor or been threatened to, then I wouldn’t tell you anyway and I’d thus say no to questions about it.
How to be sure
There is only one way to be sure: review the code you download and intend to use. Or get it from a trusted source that did the review for you.
If you have a version you trust, you really only have to review the changes done since then.
Possibly there’s some degree of safety in numbers, and as thousands of applications and systems use curl and libcurl and at least some of them do reviews and extensive testing, one of those could discover mischievous activities if there are any and report them publicly.
Infected machines or owned users
The servers that host the curl releases could be targeted by attackers and the tarballs for download could be replaced by something that carries evil code. There’s no such thing as a fail-safe machine, especially not if someone really wants to and tries to target us. The safeguard there is the GPG signature with which I sign all official releases. No malicious user can (re-)produce them. They have to be made by me (since I package the curl releases). That comes back to trusting me again. There’s of course no safe-guard against me being forced to signed evil code with a knife to my throat…
If one of the curl project members with git push rights would get her account hacked and her SSH key password brute-forced, a very skilled hacker could possibly sneak in something, short-term. Although my hopes are that as we review and comment each others’ code to a very high degree, that would be really hard. And the hacked person herself would most likely react.
Downloading from somewhere
 I think the highest risk scenario is when users download pre-built curl or libcurl binaries from various places on the internet that isn’t the official curl web site. How can you know for sure what you’re getting then, as you couldn’t review the code or changes done. You just put your trust in a remote person or organization to do what’s right for you.
I think the highest risk scenario is when users download pre-built curl or libcurl binaries from various places on the internet that isn’t the official curl web site. How can you know for sure what you’re getting then, as you couldn’t review the code or changes done. You just put your trust in a remote person or organization to do what’s right for you.
Trusting other organizations can be totally fine, as when you download using Linux distro package management systems etc as then you can expect a certain level of checks and vouching have happened and there will be digital signatures and more involved to minimize the risk of external malicious interference.
Pledging there’s no backdoor
 Some people argue that projects could or should pledge for every release that there’s no deliberate backdoor planted so that if the day comes in the future when a three-letter secret organization forces us to insert a backdoor, the lack of such a pledge for the subsequent release would function as an alarm signal to people that something is wrong.
Some people argue that projects could or should pledge for every release that there’s no deliberate backdoor planted so that if the day comes in the future when a three-letter secret organization forces us to insert a backdoor, the lack of such a pledge for the subsequent release would function as an alarm signal to people that something is wrong.
That takes us back to trusting a single person again. A truly evil adversary can of course force such a pledge to be uttered no matter what, even if that then probably is more mafia level evilness and not mere three-letter organization shadiness anymore.
I would be a bit stressed out to have to do that pledge every single release as if I ever forgot or messed it up, it should lead to a lot of people getting up in arms and how would such a mistake be fixed? It’s little too irrevocable for me. And we do quite frequent releases so the risk for mistakes is not insignificant.
Also, if I would pledge that, is that then a promise regarding all my code only, or is that meant to be a pledge for the entire code base as done by all committers? It doesn’t scale very well…
Additionally, I’m a Swede living in Sweden. The American organizations cannot legally force me to backdoor anything, and the Swedish versions of those secret organizations don’t have the legal rights to do so either (caveat: I’m not a lawyer). So, the real threat is not by legal means.
What backdoor would be likely?
It would be very hard to add code, unnoticed, that sends off data to somewhere else. Too much code that would be too obvious.
A backdoor similarly couldn’t really be made to split off data from the transfer pipe and store it locally for other systems to read, as that too is probably too much code that is too different than the current code and would be detected instantly.
No, I’m convinced the most likely backdoor code in curl is a deliberate but hard-to-detect security vulnerability that let’s the attacker exploit the program using libcurl/curl by some sort of specific usage pattern. So when triggered it can trick the program to send off memory contents or perhaps overwrite the local stack or the heap. Quite possibly only one step out of several steps necessary for a successful attack, much like how a single-byte-overwrite can lead to root access.
Any past security problems on purpose?
We’ve had almost 70 security vulnerabilities reported through the project’s almost twenty years of existence. Since most of them were triggered by mistakes in code I wrote myself, I can be certain that none of those problems were introduced on purpose. I can’t completely rule out that someone else’s patch modified curl along the way and then by extension maybe made a vulnerability worse or easier to trigger, could have been made on purpose. None of the security problems that were introduced by others have shown any sign of “deliberateness”. (Or were written cleverly enough to not make me see that!)
Maybe backdoors have been planted that we just haven’t discovered yet?
Discussion
Follow-up discussion/comments on hacker news.
 I decided to look closer at security problems and the age of the reported issues in
I decided to look closer at security problems and the age of the reported issues in 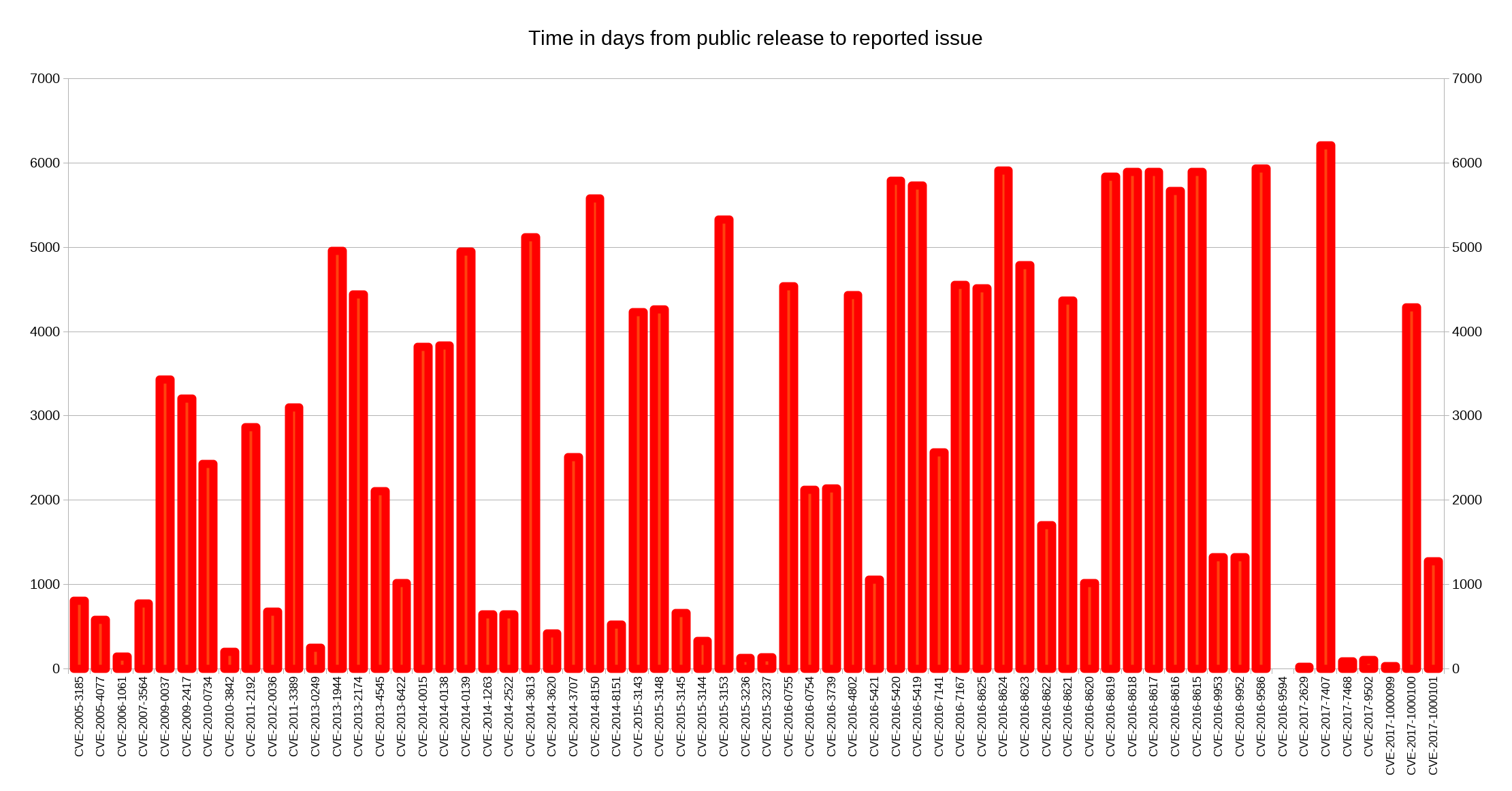
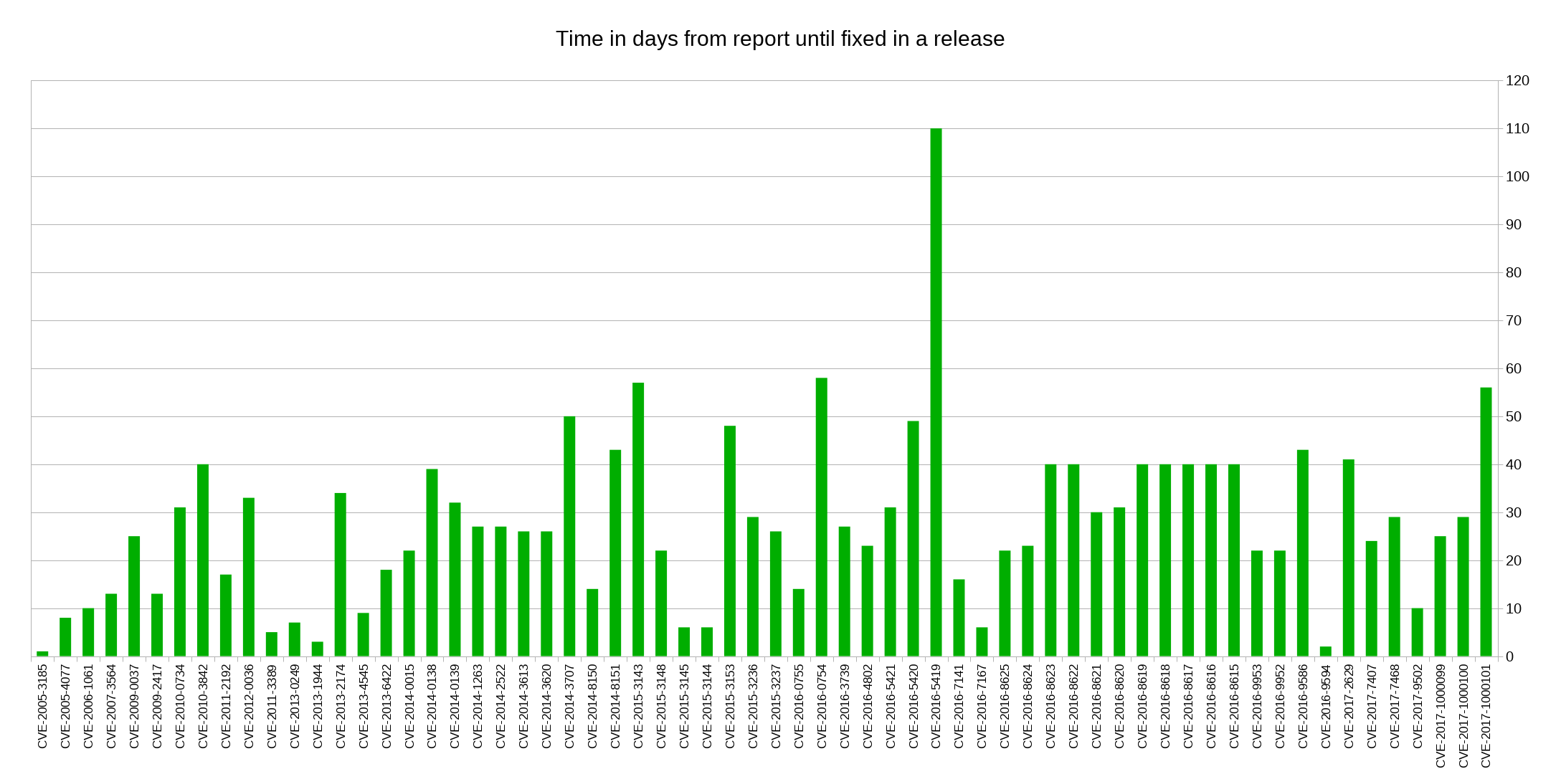
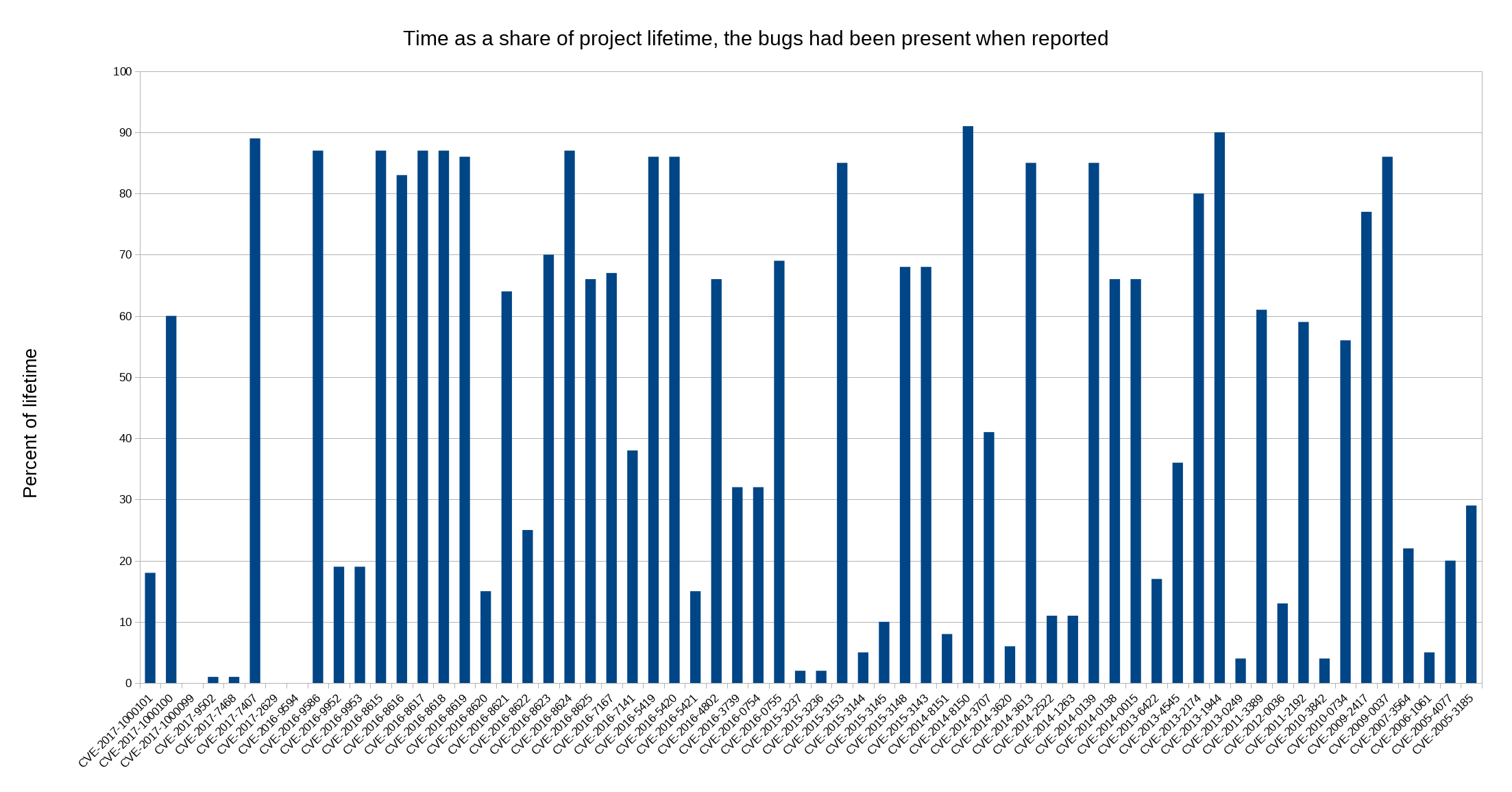

 I think more flaws in libcurl could’ve met the criteria, but I suspect more people than me haven’t been aware of this possibility for bounties.
I think more flaws in libcurl could’ve met the criteria, but I suspect more people than me haven’t been aware of this possibility for bounties.



 shed at the end of October 2016.
shed at the end of October 2016.
{kind=link}