The long version option is called --get and the short version uses the capital -G. Added in the curl 7.8.1 release, in August 2001. Not too many of you, my dear readers, had discovered curl by then.
The thinking behind it
Back in the early 2000s when we had added support for doing POSTs with -d, it become obvious that to many users the difference between a POST and a GET is rather vague. To many users, sending something with curl is something like “operating with a URL” and you can provide data to that URL.
You can send that data to an HTTP URL using POST by specifying the fields to submit with -d. If you specify multiple -d flags on the same command line, they will be concatenated with an ampersand (&) inserted in between. For example, you want to send both name and bike shed color in a POST to example.com:
Okay, so curl can merge -d data entries like that, which makes the command line pretty clean. What if you instead of POST want to submit your name and the shed color to the URL using the query part of the URL instead and you still would like to use curl’s fancy -d concatenation feature?
Enter -G. It converts what is setup to be a POST into a GET. The data set with -d to be part of the request body will instead be put after the question mark in the HTTP request! The example from above but with a GET:
GET /?name=Daniel&shed=green HTTP/1.1
Host: example.com
User-agent: curl/7.70.0
Accept: /
If you want to investigate exactly what HTTP requests your curl command lines produce, I recommend --trace-ascii if you want to see the HTTP request body as well.
-X is only for changing the actual method string in the HTTP request. It doesn’t change behavior and the change is mostly done without curl caring what the new string is. It will behave as if it used the original one it intended to use there.
If you use -d in a command line, and then add -X GET to it, curl will still send the request body like it does when -d is specified.
If you use -d plus -G in a command line, then as explained above, curl sends a GET in the command line and -X GET will not make any difference (unless you also follow a redirect, in which the -Xmay ruin the fun for you).
Other options
HTTP allows more kinds of requests than just POST or GET and curl also allows sending more complicated multipart POSTs. Those don’t mix well with -G; this option is really designed only to convert simple -d uses to a query string.
As tradition dictates, I do a “the state of curl” presentation every year. This year, as there’s no physical curl up conference happening, I have recorded the full presentation on my own in my solitude in my home.
This is an in-depth look into the curl project and where it’s at right now. The presentation is 1 hour 53 minutes.
We’ve done many curl releases over the years and this 191st one happens to be the 20th release ever done in the month of April, making it the leading release month in the project. (February is the month with the least number of releases with only 11 so far.)
Numbers
the 191st release 4 changes 49 days (total: 8,076) 135 bug fixes (total: 6,073) 262 commits (total: 25,667) 0 new public libcurl function (total: 82) 0 new curl_easy_setopt() option (total: 270) 1 new curl command line option (total: 231) 65 contributors, 36 new (total: 2,169) 40 authors, 19 new (total: 788) 0 security fixes (total: 92) 0 USD paid in Bug Bounties
Security
There’s no security advisory released this time. The release of curl 7.70.0 marks 231 days since the previous CVE regarding curl was announced. The longest CVE-free period in seven years in the project.
Changes
The curl tool got the new command line option --ssl-revoke-best-effort which is powered by the new libcurl bit CURLSSLOPT_REVOKE_BEST_EFFORT you can set in the CURLOPT_SSL_OPTIONS. They tell curl to ignore certificate revocation checks in case of missing or offline distribution points for those SSL backends where such behavior is present (read: Schannel).
We’ve introduced the first take on MQTT support. It is marked as experimental and needs to be explicitly enabled at build-time.
Bug-fixes to write home about
This is just an ordinary release cycle worth of fixes. Nothing particularly major but here’s a few I could add some extra blurb about…
gnutls: bump lowest supported version to 3.1.10
GnuTLS has been a supported TLS backend in curl since 2005 and we’ve supported a range of versions over the years. Starting now, we bumped the lowest supported GnuTLS version to 3.1.10 (released in March 2013). The reason we picked this particular version this time is that we landed a bug-fix for GnuTLS that wanted to use a function that was added to GnuTLS in that version. Then instead of making more conditional code, we cleaned up a lot of legacy and simplified the code significantly by simply removing support for everything older than this. I would presume that this shouldn’t hurt many users as I suspect it is a very bad idea to use older versions anyway, for security reasons if nothing else.
libssh: Use new ECDSA key types to check known hosts
curl supports three different SSH backends, and one them is libssh. It turned out that the glue layer we have in curl between the core libcurl and the SSH library lacked proper mappings for some recent key types that have been added to the SSH known_hosts file. This file has been getting new key types added over time that OpenSSH is using by default these days and we need to make sure to keep up…
multi-ssl: reset the SSL backend on Curl_global_cleanup()
curl can get built to support multiple different TLS backends – which lets the application to select which backend to use at startup. Due to an oversight we didn’t properly support that the application can go back and cleanup everything and select a different TLS backend – without having to restart the application. Starting now, it is possible!
Revert “file: on Windows, refuse paths that start with \\”
Back in January 2020 when we released 7.68.0 we announced what we then perceived was a security problem: CVE-2019-15601.
Later, we found out more details and backpedaled on that issue. “It’s not a bug, it’s a feature” as the saying goes. Since it isn’t a bug (anymore) we’ve now also subsequently removed the “fix” that we introduced back then…
tests: introduce preprocessed test cases
This is actually just one out of several changes in the curl test suite that has happened as steps in a larger sub-project: move all test servers away from using fixed port numbers over to using dynamically assigned ones. Using dynamic port numbers makes it easier to run the tests on random users’ machines as the risk for port collisions go away.
Previously, users had the ability to ask the tests to run on different ports by using a command line option but since it was rarely used, new test were often written assuming the default port number hard-coded. With this new concept, such mistakes can’t slip through.
In order to correctly support all test servers running on any port, we’ve enhanced the main test “runner” (runtests) to preprocess the test case files correctly which allows all our test servers to work with such port numbers appearing anywhere in protocol details, headers or response bodies.
The work on switching to dynamic port numbers isn’t quite completed yet but there are still a few servers using fixed ports. I hope those will be addressed within shortly.
tool_operate: fix add_parallel_transfers when more are in queue
Parallel transfers in the curl tool is still a fairly new thing, clearly, as we can get a report on this kind of basic functionality flaw. In this case, you could have curl generate zero byte output files when using --parallel-max to limit the parallelism, instead of getting them all downloaded fine.
version: add ‘cainfo’ and ‘capath’ to version info struct
curl_version_info() in libcurl returns lots of build information from the libcurl that’s running right now. It includes version number of libcurl, enabled features and version info from used 3rd party dependencies. Starting now, assuming you run a new enough libcurl of course, the returned struct also contains information about the built-in CA store default paths that the TLS backends use.
The idea being that your application can easily extract and use this information either in information/debugging purposes but also in cases where other components are used that also want a CA store and the application author wants to make sure both/all use the same paths!
windows: enable UnixSockets with all build toolchains
Due to oversights, several Windows build didn’t enable support for unix domain sockets even when built for such Windows 10 versions where there’s support provided for it in the OS.
scripts: release-notes and copyright
During the release cycle, I regularly update the RELEASE-NOTES file to include recent changes and bug-fixes scheduled to be included in the coming release. I do this so that users can easily see what’s coming; in git, on the web site and in the daily snapshots. This used to be a fairly manual process but the repetitive process finally made me create a perl script for it that removes a lot of the manual work: release-notes.pl. Yeah, I realize I’m probably the only one who’s going to use this script…
Already back in December 2018, our code style tool checksrc got the powers to also verify the copyright year range in the top header (written by Daniel Gustafsson). This makes sure that we don’t forget to bump the copyright years when we update files. But because this was a bit annoying and surprising to pull-request authors on GitHub we disabled it by default – which only lead to lots of mistakes still being landed on the poor suckers (like me) who enabled it would get the errors instead. Additionally, the check is a bit slow. This finally drove me into disabling the check as well.
To combat the net effect of that, I’ve introduced the copyright.pl script which is similar in spirit but instead scans all files in the git repository and verifies that they A) have a header and B) that the copyright range end year seems right. It also has a whitelist for files that don’t need to fulfill these requirements for whatever reason. Now we can run this script one every release cycle instead and get the same end results. Without being annoying to users and without slowing down anyone’s everyday builds! Win-win!
The release presentation video
Credits
The top image was painted by Dirck van Delen 1631. Found in the Swedish National Museum’s collection.
On May 7, 2020 I will present common mistakes when using libcurl (and how to fix them) as a webinar over Zoom. The presentation starts at 19:00 Swedish time, meaning 17:00 UTC and 10:00 PDT (US West coast).
libcurl is used in thousands of different applications and devices for client-side Internet transfer and powers a significant part of what flies across the wires of the world a normal day.
Over the years as the lead curl and libcurl developer I’ve answered many questions and I’ve seen every imaginable mistake done. Some of the mistakes seem to happen more frequently and some of the mistake seem easier than others to avoid.
I’m going to go over a list of things that users often get wrong with libcurl, perhaps why they do and of course I will talk about how to fix those errors.
Length
It should be done within 30-40 minutes, plus some additional time for questions at the end.
Audience
You’re interested in Internet transfer, preferably you already know what libcurl is and perhaps you have even written code that uses libcurl. Directly in C or using a binding in another language.
Material
The video and slides will of course be made available as well in case you can’t tune in live.
Sign up
If you sign up to attend, you can join, enjoy the talk and of course ask me whatever is unclear or you think needs clarification around this topic. See you next week!
This option only has a long version and it is --remote-name-all.
Shipped curl 7.19.0 for the first time – September 1 2008.
History of curl output options
I’m a great fan of the Unix philosophy for command line tools so for me there was never any deeper thoughts on what curl should do with the contents of the URL it gets already from the beginning: it should send it to stdout by default. Exactly like the command line tool cat does for files.
Of course I also realized that not everyone likes that so we provided the option to save the contents to a given file. Output to a named file. We selected -o for that option – if I remember correctly I think I picked it up from some other tools that used this letter for the same purpose: instead of sending the response body to stdout, save it to this file name.
Okay but when you selected “save as” in a browser, you don’t actually have to select the full name yourself. It’ll propose the default name to use based on the URL you’re viewing, probably because in many cases that makes sense for the user and is a convenient and quick way to get a sensible file name to save the content as.
It wasn’t hard to come with the idea that curl could offer something similar. Since the URL you give to curl has a file name part when you want to get a file name, having a dedicated option pick the name from the rightmost part of the URL for the local file name was easy. As different output option that -o,it felt natural to pick the uppercase O option for this slightly different save-the-output option: -O.
Enter more than URL
curl sends everything to stdout, unless to tell it to direct it somewhere else. Then (this is still before the year 2000, so very early days) we added support for multiple URLs on the command line and what would the command line options mean then?
The default would still be to send data to stdout and since the -o and -O options were about how to save a single URL we simply decided that they do exactly that: they instruct curl how to send a single URL. If you provide multiple URLs to curl, you subsequently need to provide multiple output flags. Easy!
It has the interesting effect that if you download three files from example.com and you want them all named according to their rightmost part from the URL, you need to provide multiple -O options:
Back in 2008 at some point, I think I took some critique about this maybe a little too hard and decided that if certain users really wanted to download multiple URLs to local file names in an easier manner, that perhaps other command line internet download tools do, I would provide an option that lets them to this!
--remote-name-all was born.
Specifying this option will make -O the default behavior for URLs on the command line! Now you can provide as many URLs as you like and you don’t need to provide an extra flag for each URL.
Get five different URLs on the command line and save them all locally using the file part form the URLs:
Then if you don’t want that behavior you need to provide additional -o flags…
.curlrc perhaps?
I think the primary idea was that users who really want -O by default like this would put --remote-name-all in their .curlrc files. I don’t this ever really materialized. I believe this remote name all option is one of the more obscure and least used options in curl’s huge selection of options.
On April 22nd 2019, we announced our current, this, incarnation of the curl bug bounty. In association with Hackerone we now run the program ourselves, primarily funded by gracious sponsors. Time to take a closer look at how the first year of bug bounty has been!
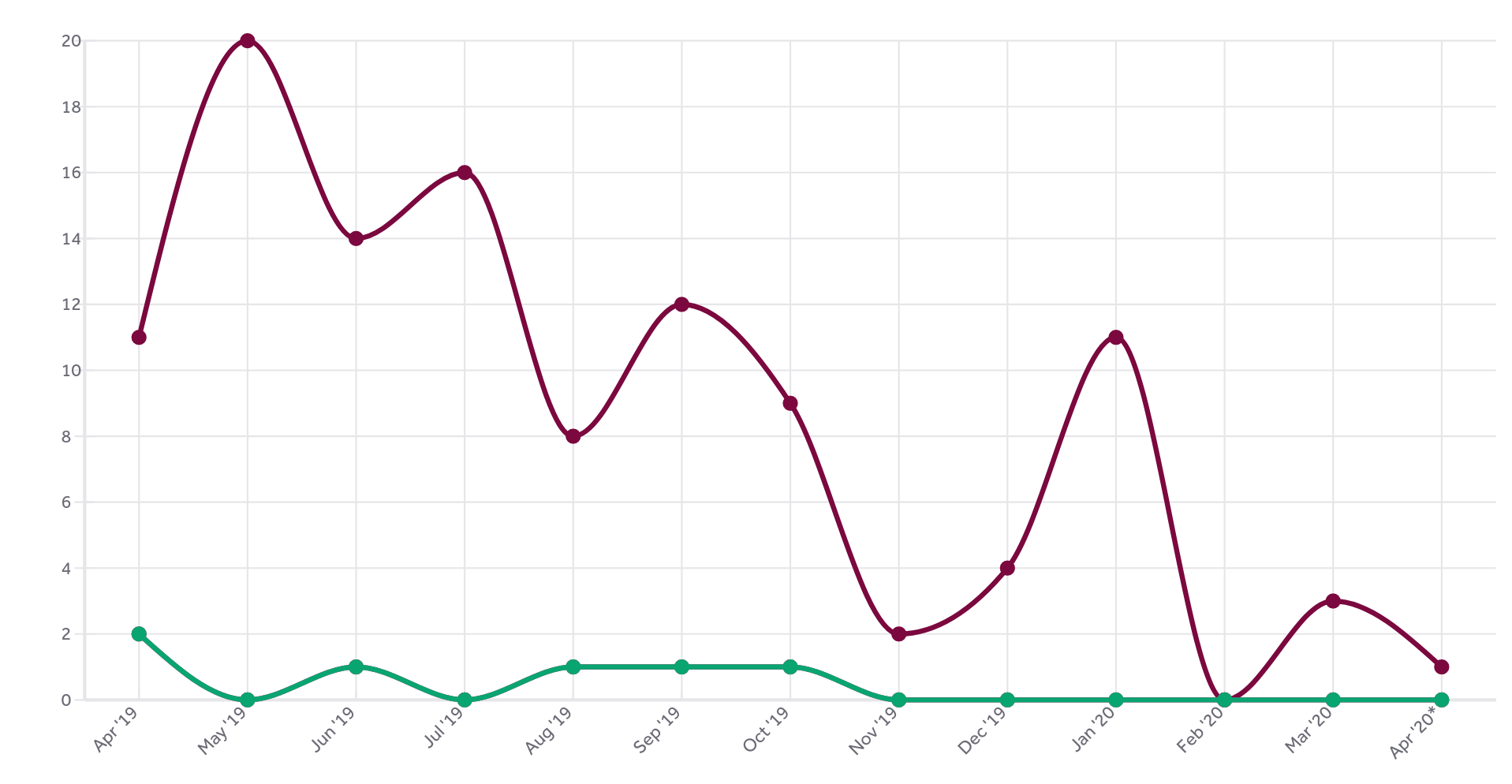
Number of reports
We’ve received a total of 112 reports during this period.
On average, we respond with a first comment to reports within the first hour and we triage them on average within the first day.
Out of the 112 reports, 6 were found actual security problems.
Total amount of reports vs actual security problems, per month during the first year of the curl hackerone bug bounty program.
Bounties
All confirmed security problems were rewarded a bounty. We started out a bit careful with the amounts but we are determined to raise them as we go along and we’ve seen that there’s not really a tsunami coming.
We’ve handed out 1,400 USD so far, which makes it an average of 233 USD per confirmed report. The top earner got two reports rewarded and received 450 USD from us. So far…
But again: our ambition is to significantly raise these amounts going forward.
Trends
The graph above speaks clearly: lots of people submitted reports when we opened up and the submission frequency has dropped significantly over the year.
A vast majority of the 112 reports we’ve received have were more or less rubbish and/or more or less automated reports. A large amount of users have reported that our wiki can be edited by anyone (which I consider to be a fundamental feature of a wiki) or other things that we’ve expressly said is not covered by the program: specific details about our web hosting, email setup or DNS config.
A rough estimate says that around 80% of the reports were quickly dismissed as “out of policy” – ie they reported stuff that we documented is not covered by the bug bounty (“Sirs, we can figure out what http server that’s running” etc). The curl bug bounty covers the products curl and libcurl, thus their source code and related specifics.
Bounty funds
curl has no ties to any organization. curl is not owned by any corporation. curl is developed by individuals. All the funds we have in the project are graciously provided to us by sponsors and donors. The curl funds are handled by the awesome Open Collective.
Security is of utmost importance to us. It trumps all other areas, goals and tasks. We aim to produce solid and secure products for the world and we act as swiftly and firmly as we can on all reported security problems.
Security vulnerability trends
We have not published a single CVE for curl yet this year (there was one announced, CVE-2019-15601 but after careful considerations we have backpedaled on that, we don’t consider it a flaw anymore and the CVE has been rejected in the records.)
As I write this, there’s been exactly 225 days since the latest curl CVE was published and we’re aiming at shipping curl 7.70.0 next week as the 6th release in a row without a security vulnerability to accompany it. We haven’t done 6 “clean” consecutive release like this since early 2013!
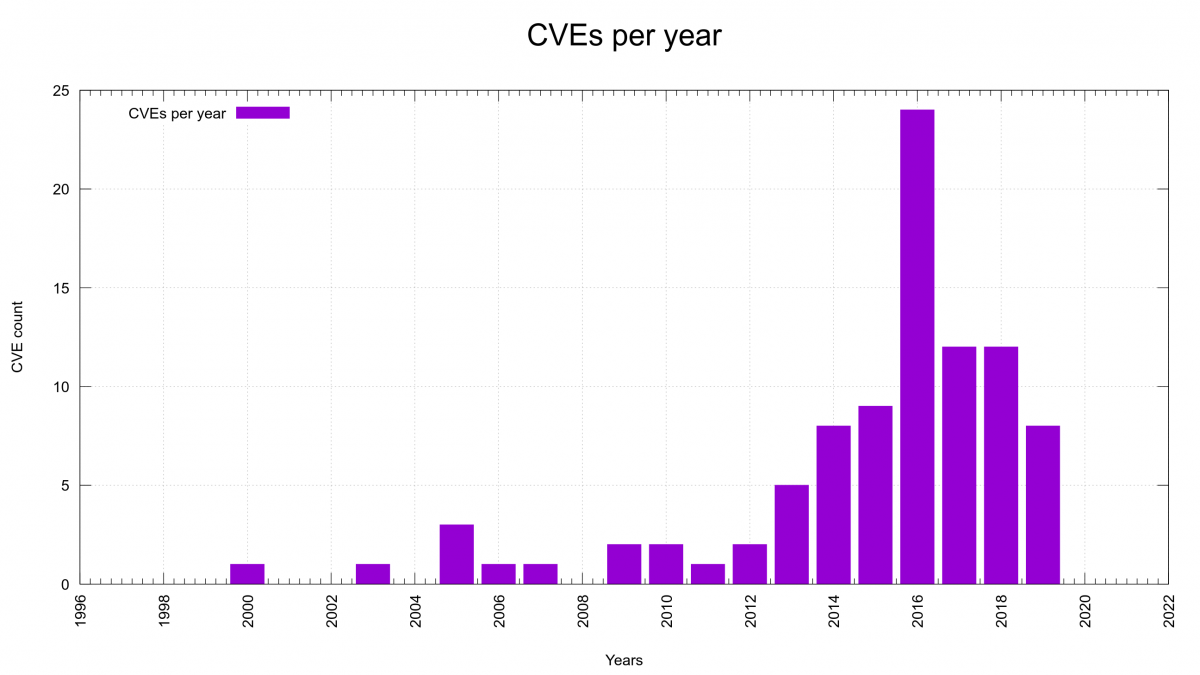
Looking at the number of CVEs reported in the curl project per year, we can of course see that 2016 stands out. That was the year of the security audit that ended up the release of curl 7.51.0 with no less than eleven security vulnerabilities announced and fixed. Better is of course the rightmost bar over the year 2020 label. It is still non-existent!
The most recent CVEs per year graph is always found: here.
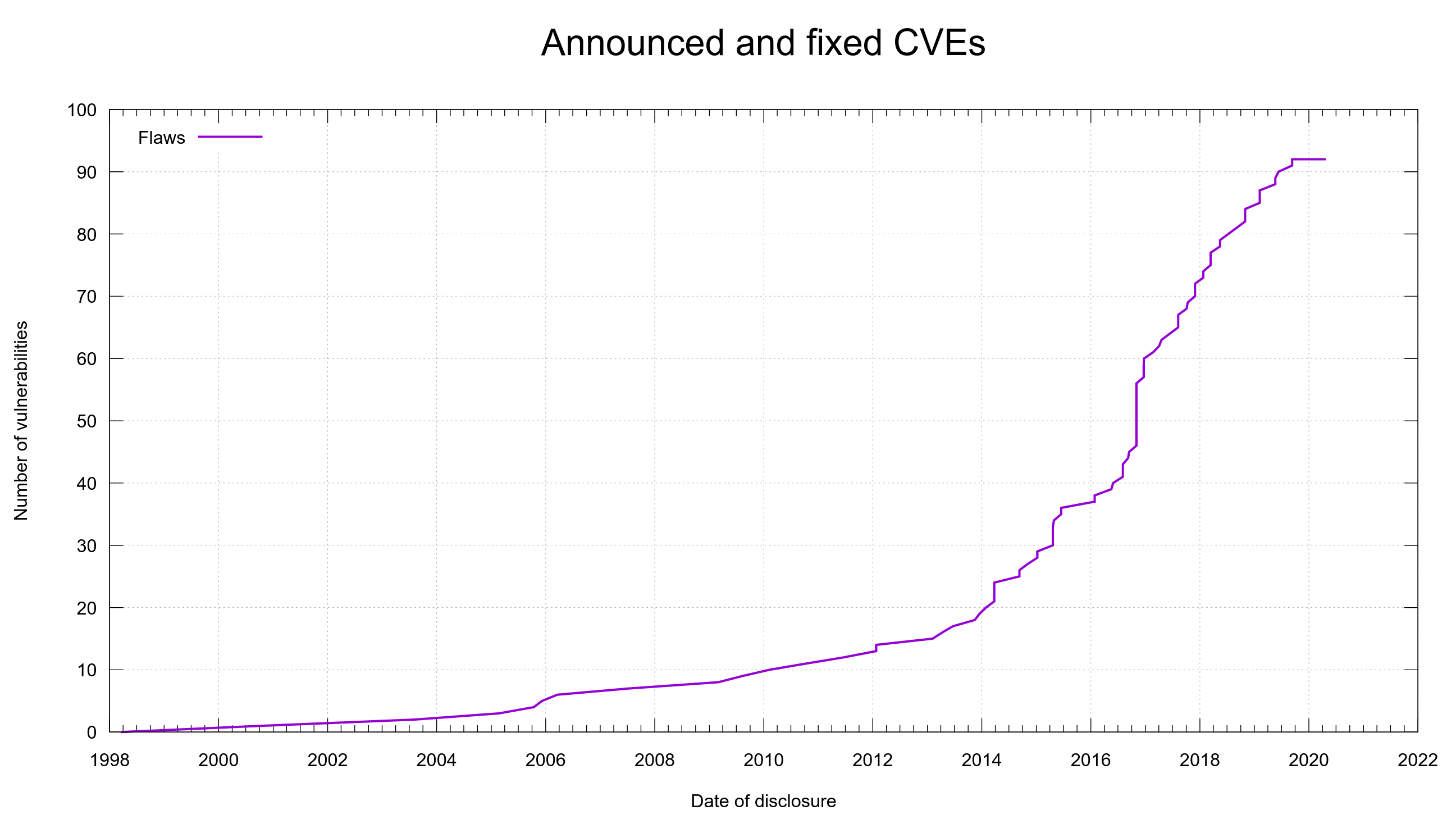
As you can see in the graph below, the “plateau” in the top right is at 92 published CVEs. The previous record holder for longest period in the project without a CVE ended in February 2013 (with CVE-2013-0249) at 379 days.
2013 was however quite a different era for curl. Less code, much less scrutinizing, no bug bounty, lesser tools, no CI jobs etc.
Number of published CVEs in the curl project over time. The updated graph is always found: here.
Are we improving?
Is curl getting more secure?
We have more code and support more protocols than ever. We have a constant influx of new authors and contributors. We probably have more users than ever before in history.
At the same time we offer better incentives than ever before for people to report security bugs. We run more CI jobs than ever that run more and more test cases while code analyzers and memory debugging are making it easier to detect problems earlier. There are also more people looking for security bugs in curl than ever before.
Jinx?
I’m under no illusion that there aren’t more flaws to find, report and fix. We’re all humans and curl is still being developed at a fairly high pace.
This option is -4 as the short option and --ipv4 as the long, added in curl 7.10.8.
IP version
So why would anyone ever need this option?
Remember that when you ask curl to do a transfer with a host, that host name will typically be resolved to a list of IP addresses and that list will contain both IPv4 and IPv6 addresses. When curl then connects to the host, it will iterate over that list and it will attempt to connect to both IPv6 and IPv4 addresses, even at the same time in the style we call happy eyeballs.
The first connect attempt to succeed will be the one curl sticks to and will perform the transfer over.
When IPv6 acts up
In rare occasions or even in some setups, you may find yourself in a situation where you get back problematic IPv6 addresses in the name resolve, or the server’s IPv6 behavior seems erratic, your local config simply makes IPv6 flaky or things like that. Reasons you may want to ask curl to stick to IPv4-only to avoid a headache.
Then --ipv4 is here to help you.
--ipv4
First, this option will make the name resolving only ask for IPv4 addresses so there will be no IPv6 addresses returned to curl to try to connect to.
Then, due to the disabled IPv6, there won’t be any happy eyeballs procedure when connecting since there are now only addresses from a single family in the list.
It could perhaps be worth to stress that if the host name you target then doesn’t have any IPv4 addresses associated with it, the operation will instead fail when this option is used.
Example
curl --ipv4 https://example.org/
Related options
The reversed request, ask for IPv6 only is done with the --ipv6 option.
There are also options for specifying other protocol versions, in particular for example HTTP with --http1.0, --http1.1, --http2 and --http3 or for TLS with --tslv1, --tlsv1.2, --tlsv1.3 and more.
As so many other events in these mysterious times, the foss-north conference went online-only and on March 30, 2020 I was honored to be included among the champion speakers at this lovely conference and I talked about how to “curl better” there.
The talk is a condensed run-through of how curl works and why, and then a look into how some of the more important HTTP oriented command line options work and how they’re supposed to be used.
As someone pointed out: I don’t do a lot of presentations about the curl tool. Maybe I should do more of these.
curl is widely used but still most users only use a very small subset of options or even just copy their command line from somewhere else. I think more users could learn to curl better. Below is the video of this talk.
Doing a talk to a potentially large audience in front of your laptop in completely silence and not seeing a single audience member is a challenge. No “contact” with the audience and no feel for if they’re all going to sleep or seem interested etc. Still I have the feeling that this is the year we all are going to do this many times and hopefully get better at it over time…
Both browsers have paused or conditioned their efforts to not take the final steps during the Covid-19 outbreak, but they will continue and the outcome is given: FTP support in browsers is going away. Soon.
curl
curl supported both uploads and downloads with FTP already in its first release in March 1998. Which of course was many years before either of those browsers mentioned above even existed!
In the curl project, we work super hard and tirelessly to maintain backwards compatibility and not break existing scripts and behaviors.
For these reasons, curl will not drop FTP support. If you have legacy systems running FTP, curl will continue to have your back and perform as snappy and as reliably as ever.
FTP the protocol
FTP is a protocol that is quirky to use over the modern Internet mostly due to its use of two separate TCP connections. It is unencrypted in its default version and the secured version, FTPS, was never supported by browsers. Not to mention that the encrypted version has its own slew of issues when used through NATs etc.
To put it short: FTP has its issues and quirks.
FTP use in general is decreasing and that is also why the browsers feel that they can take this move: it will only negatively affect a very minuscule portion of their users.
Legacy
FTP is however still used in places. In the 2019 curl user survey, more than 29% of the users said they’d use curl to transfer FTP within the last two years. There’s clearly a long tail of legacy FTP systems out there. Maybe not so much on the public Internet anymore – but in use nevertheless.
Alternative protocols?
SFTP could have become a viable replacement for FTP in these cases, but in practice we’ve moved into a world where HTTPS replaces everything where browsers are used.
This is the 25th transfer protocol added to curl. The first new addition since we added SMB and SMBS back in November 2014.
Background
Back in early 2019, my brother Björn Stenberg brought a pull request to the curl project that added support for MQTT. I tweeted about it and it seemed people were interested in seeing this happen.
Time passed and Björn unfortunately didn’t manage to push his work forward and instead it grew stale and the PR eventually was closed due to that inactivity later the same year.
Roadmap 2020
In my work trying to go over and figure out what I want to see in curl the coming year and what we (wolfSSL) as a company would like to see being done, MQTT qualified as a contender for the list. See my curl roadmap 2020 video.
It’s happening again
I grabbed Björn’s old pull-request and rebased it onto git master, fixed a few minor conflicts and small cleanups necessary and then brought it further. I documented two of my early sessions on this, live-streamed on twitch. See MQTT in curl and MQTT part two below:
Polish
Björn’s code was an excellent start but didn’t take us all the way.
I wrote an MQTT test server, created a set of test cases, made sure the code worked for those test cases, made it more solid and more. It is still early days and the MQTT support is basic and comes with several caveats, but it’s slowly getting there.
MQTT – really?
When I say that MQTT almost fits the curl concepts and paradigms, I mean that you can consider what an MQTT client does to be “sending” and “receiving” and you can specify that with a URL.
Fetching an MQTT URL with curl means doing SUSCRIBE on a topic and waiting for that to arrive and get the payload sent to the output.
Doing the equivalent of a HTTP POST with curl, like with the command line’s -d option makes an MQTT PUBLISH and sends a payload to a topic.
Rough corners and wrong assumptions
I’m an MQTT rookie. I’m sure there will be mistakes and I will have misunderstood things. The MQTT will be considered experimental for a time forward so that people will get a chance to verify the functionality and we have a chance to change and correct the worst decisions and fatal mistakes. Remember that for experimental features in curl, we reserve ourselves the right to change behavior, API and ABI so nobody should ship such features enabled anywhere without first thinking it through very carefully!
If you’re a person who think MQTT in curl would be useful, good or just fun and you have use cases or ideas where you’d want to use this. Please join in and try and let us know how it works and what you think we should polish or fix to make it truly stellar!
The code is landed in the master branch since PR 5173 was merged. The code will be present in the coming 7.70.0 release, due to ship on April 29 2020.
TODO
As I write this, the MQTT support is still very basic. I want a first version out to users as early as possible as I want to get feedback and comments to help verify that we’re in the right direction and then work on making the support of the protocol more complete. TLS, authentication, QoS and more will come as we proceed. Of course, if you let me know what we must support for MQTT to make it interesting for you, I’ll listen! Preferably, you do the discussions on the curl-library mailing list.
We’ve only just started.
Credits
The initial MQTT patch that kicked us off was written by Björn Stenberg. I brought it forward from there, bug-fixed it, extended it, added a test server and test cases and landed the lot in the master branch.