The year is still young, and we’re here to really kick off 2020 with a brand new curl release! curl 7.68.0 is available at curl.haxx.se as always. Once again we’ve worked hard and pushed through another release cycle to bring you the very best we could do in the 63 days since 7.67.0.
(The previous release was said to be the 186th, but it turned out we’ve been off-by-one on the release counter for a while.)
Numbers
the 188th release
6 changes
63 days (total: 7,964)
124 bug fixes (total: 5,788)
193 commits (total: 25,124)
1 new public libcurl function (total: 82)
0 new curl_easy_setopt() option (total: 269)
3 new curl command line option (total: 229)
70 contributors, 32 new (total: 2,088)
31 authors, 13 new (total: 756)
1 security fixes (total: 93)
400 USD paid in Bug Bounties
Security Vulnerability
CVE-2019-15601: SMB access smuggling via FILE URL on Windows.
Simply put: you could provide a FILE:// URL to curl that could trick it to try to access a host name over SMB – on Windows machines. This could happen because Windows apparently always do this automatically if given the correct file name and curl had no specific filter to avoid it.
For this discovery and report, the curl Bug Bounty program has rewarded Fernando Muñoz 400 USD.
Changes
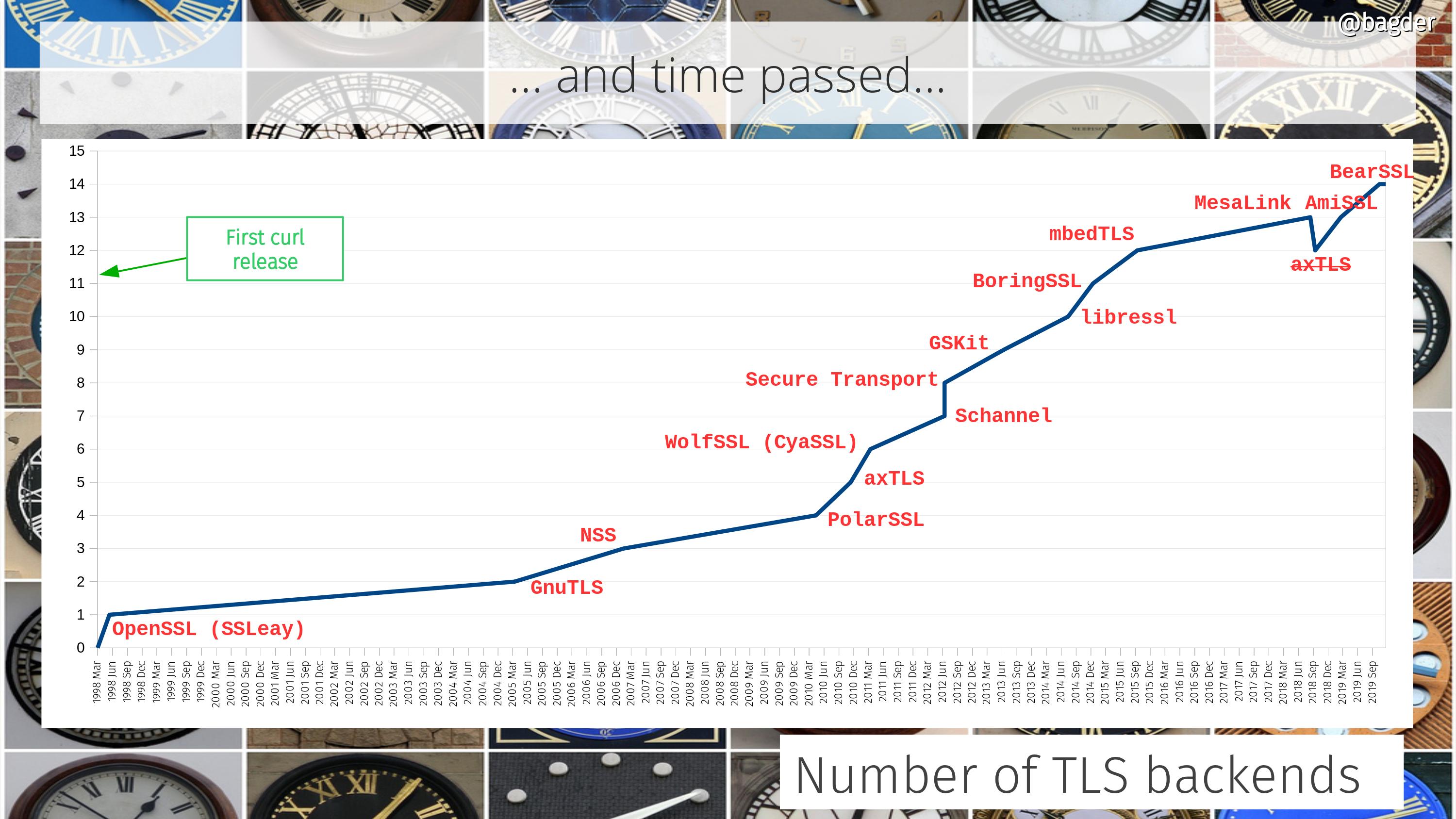
We ship a new TLS backend: BearSSL. The 14th.
We ship two new command line options for ETags.
We provide a new API call to wakeup “sleeping” libcurl poll calls.
We changed the default handling in libcurl with OpenSSL for verifying certificates. We now allow “partial chains” by default, meaning that you can use an intermediate cert to verify the server cert, not necessarily the whole chain to the root, like you did before. This brings the OpenSSL backend to work more similar to the other TLS backends, and we offer a new option for applications to switch back on the old behavior (CURLSSLOPT_NO_PARTIALCHAIN).
The progress callback has a new feature: if you return CURL_PROGRESSFUNC_CONTINUE from the callback, it will continue and call the internal progress meter.
The new command line option --parallel-immediate is added, and if used will make curl do parallel transfers like before 7.68.0. Starting with 7.68.0, curl will default to defer new connections and rather try to multiplex new transfer over an existing connection if more than one transfer is specified to be done from the same host name.
Bug-fixes
Some of my favorite fixes done since the last release include…
Azure CI and torture
This cycle we started running a bunch of CI tests on Azure Pipelines, both Linux and macOS tests. We also managed to get torture tests running thanks to the new shallow mode.
Azure seem to run faster and more reliable than Travis CI, so moving a few jobs over has made a total build run often complete in less total time now.
prefer multiplexing to using new connections
A regression was found that made the connection reuse logic in libcurl to prefer new connections to multiplexing more than what was actually intended and once fixed we should see libcurl-using application do more and better HTTP/2 multiplexing.
support for ECDSA and ed25519 knownhost keys with libssh2
libssh2 is the primary SSH backend people use with curl. While the library itself has supported these new “knownhost” keys for a while, we hadn’t previously adjusted curl to play nicely with them. Until now.
openssl: Revert to less sensitivity for SYSCALL errors
Another regression in the OpenSSL backend code made curl overly sensitive to some totally benign TLS messages which would cause a curl error when they should just have been silently handled and closed the connection cleanly.
openssl: set X509_V_FLAG_PARTIAL_CHAIN by default
The OpenSSL backend now behaves more similar to other TLS backends in curl and now accepts “partial” certificate chains. That means you don’t need to have the entire chain locally all the way to the root in order to verify a server certificate. Unless you set CURLSSLOPT_NO_PARTIALCHAIN to enforce that behavior.
parsedate: offer a getdate_capped() alternative
The date parser was extended to make curl handle dates beyond 2038 better on 32 bit systems, which primarily seems to happen with cookies. Now the parser understands that they’re too big and will use the max time value it can hold instead of failing and using a zero, as that would make the cookies into “session cookies” which would have slightly different behavior.