The first mention of QUIC on this blog was back when I posted about the HTTP workshop of July 2015. Today, this blog is readable over the protocol QUIC subsequently would turn into. (Strictly speaking, it turned into QUIC + HTTP/3 but let’s not be too literal now.)
The other day Fastly announced that all their customers now can enable HTTP/3, and since this blog and the curl site are graciously running on the Fastly network I went ahead and enabled the protocol.
Within minutes and with almost no mistakes, I could load content over HTTP/3 using curl or browsers. Wooosh.
The name HTTP/3 wasn’t adopted until late 2018, and the RFC has still not been published yet. Some of the specifications for QUIC have however.
– Everything I know and learned about running and maintaining Open Source projects for three decades.
For several years now, I have had a blog post series in mind to describe something about what people could expect to happen in Open Source projects. I had a few already half-started blog post drafts for some sub topics.
I couldn’t really make up my mind how to craft a series of blog posts about this wide topic in a sensible way so I kept postponing it for later. I did this for years.
A book, it has to be a book
It just dawned on my one day: the only way to get all this into a comprehensible way that also can hold all the thoughts I would like it to have, is to put it into a book. By book, I mean a document. An essay. A collection of pages. A booklet maybe. I don’t know how many words it might end up to become and I have no illusions of it ever ending up in print.
I mean to write the document in the open and provide it for free, online. Open Source style.
Day one
I grabbed my original draft for my blog series “You can expect this in your Open Source project”. I had worked on that document in the background for a long time, adding some little thing here and there over years – and it now had maybe twenty-five “lessons” listed with a short paragraph of text next to each.
I also had started three blog posts based on such lessons that were in pending state here on daniel.haxx.se in my queue of drafts.
I first copied the blog post content back into the text file from those potential blog posts, before I deleted them, and converted the entire file to markdown.
I then grouped the “lessons” I had listed in the markdown file and moved them into a few different sections. Like what to expect, code, money, people and project. I put subtitles into separate files for those five main areas.
How hard can it be?
I didn’t want to do a lot of work before I put the thing into git, and I didn’t want to run any private git repository so I had to make a new repo with a name. I went with “How hard can it be” as a working title and created the repo on GitHub. On April 6 I made the first git push with initial contents to that repository.
The first external contributor appeared after just a few minutes with the first pull-request fixing typos. Clearly people are following me on GitHub and spotted the creating of the repository and checked out what it was. I hadn’t told anyone or given any pointers.
I started expanding on subjects in the book.
Let’s get a real title
In the evening of April 7 I posted this question on Twitter:
I got a flood of replies. Lots of good ones and also lots of fun and sarcastic ones. The one that I think really talked to me the best was also the shortest: Uncurled.
It’s short and sweet
It includes a reference to curl without saying it is “a curl book” (it isn’t)
The topic is a bit about “untangling” and curl is a project that probably has taught me the most of what I include here
It sounds a little like “debriefed” from the curl project, and it is…
I can put it up on the domain name un.curl.dev
I figured I could possibly go with a longer subtitle that could explain the book more: “Everything I know and learned about running and maintaining Open Source projects”.
A name
I renamed the GitHub repository and added a description there. I created the URL (by adding the “un” CNAME entry in the “curl.dev” domain) and I setup gitbook.com to render the content to appear on un.curl.dev.
With a little more thoughts and then spilling some beans about my plans in my weekly report on April 8 (but not leaking the URL or repo to anyone yet) that made people provide some more ideas, I added more content.
10,000 words
By the evening of April 9, I surpassed 10,000 words of contents. Still having the contents and the order of everything pretty much in flux and not yet sorted out.
20,000 words
On April 25, I surpassed 20,000 words. It starts to look like something I can announce soon.
Getting there, but not done
The uncurled book is now in a state I think I can show off without feeling embarrassed. I believe I will still need to work on it more going forward to add and polish content and make it more coherent and less of a collection of snippets. I hope that I over time can settle down and gradually slow down the change pace. It will of course also depend a lot on the feedback I get.
Cover
Since it doesn’t exist physically and probably never will, I don’t think it actually needs a cover image, but it would probably be cool to still have one to use as an image and symbol for the book. If someone has a good idea or feels artistically inclined to make one, let me know!
the 207th release 6 changes 53 days (total: 8,804) 125 bug-fixes (total: 7,816) 185 commits (total: 28,507) 2 new public libcurl function (total: 88) 0 new curl_easy_setopt() option (total: 295) 2 new curl command line option (total: 247) 60 contributors, 29 new (total: 2,626) 35 authors, 13 new (total: 1,027) 4 security fixes (total: 115) 0 USD paid in Bug Bounties (total: 16,900 USD)
Security fixes
The reason the Bug Bounty amount above is still at zero dollars for this cycle is that the rewards have not been set yet. There will be money handed out for all of them.
CVE-2022-22576– OAUTH2 bearer bypass in connection re-use
curl might reuse wrong connections when OAUTH2 bearer tokens are used.
When curl follows a redirect to another protocol or to another port number, it could keep sending the credentials over the new connection and thus leak sensible information to the wrong party.
curl could reuse the wrong connection when asking to connect to an IPv6 address using zone id, as the zone id was not correctly checked when picking connection from the pool.
curl’s system to avoid sending custom auth and cookies to other hosts after redirects did not take port number or protocol into account, and could leak sensible information to the wrong party.
Changes
While the number of changes can be counted to six, I will group them under four subtitles.
Cherry-pick headers
(These features are all landed as experimental to start with so you need to make sure to enable these in the build if you want to play with them.)
Two new functions have been introduced, curl_easy_header() and curl_easy_nextheader(). They allow applications to get the contents of specific HTTP headers or iterate over all of them after a transfer has been done. Applications have been able to get access to headers already before, but these functions bring a new level of ease and flexibility.
The command line tool was also extended to use these functions to allow easy header output to the --write-out option, both individual headers and also all headers as a JSON object. Read further.
--no-clobber
Long time TODO listing was now made into reality. Using this option, you can ask curl to not overwrite a local file even if you have specified it as an output file name in curl a command line.
--remove-on-error
The second of the new command line options: tell curl to remove the possibly partial file that might have been downloaded when it detects and returns an error.
curl: error out if -T and -d are used for the same URL
One of them implies PUT and the other implies POST, they cannot both be used for the same target URL and starting now curl will error out properly with a message saying so.
system.h: ifdefs for MCST-LCC compiler
Yet another compiler is now supported by default when you build curl.
curl: fix segmentation fault for empty output file names
Also now generally behave better as in telling the user why it errors out because of this situation.
http2: RST the stream if we stop it on our own will
When an application stops a transfer that is being done over HTTP/2, it was not properly shut down from curl’s side and therefore could end up wasting data that the server kept sending but that the client wouldn’t receive anymore!
http: close the stream (not connection) on time condition abort
For a special kind of transfer abort due to a failed time condition, curl would always close the connection to stop the transfer, instead of just closing the stream. This of course made no different on HTTP/1 but for later HTTP versions the connection should be kept alive even for this condition.
http: streamclose “already downloaded”
Another case of curl deciding the connection shouldn’t continue when it for in fact should be kept alive for HTTP/2 and HTTP/3.
http: reject header contents with nul bytes
HTTP headers cannot legally contain these bytes as per the protocol specification and as hyper already rejects these response it made sense to unify the implementation and refuse them in native code as well. It might also save us from future badness.
http: return error on colon-less HTTP headers
Similar to the change above, HTTP/1 headers must have colons so curl now will consider it a broken transfer if a header arrives without. This makes curl much pickier of course, but should not affect any “real” HTTP transfers.
mqtt: better handling of TCP disconnect mid-message
A nasty busy-loop occurred if the connection was cut off at the wrong time for an MQTT transfer.
ngtcp2: numerous improvements
HTTP/3 with ngtcp2 was greatly enhanced during this cycle in several ways. Check out the changelog for the specific details and do try it out!
tls: make mbedtls and NSS check for h2, not nghttp2
In leftovers from the past we still checked if HTTP/2 support is present by the wrong #ifdef in a few places in the code. nghttp2 is no longer the only HTTP/2 library we can use.
curl: escape ‘?’ in code generated with --libcurl
It turns out you could sneakily insert and get fooled by trigraphs otherwise:
On June 6 2022, we will gather a bunch of curl aficionados in the Firehouse at the Fort Mason Centre in San Francisco, USA.
All details can be found here. We will add more info and details as we get closer to the event.
curl up is the annual curl developers and users “conference” where we meet up over a day and talk curl, curl related topics and share ideas about curl, its present and and its future. It is also really the only time of the year where we actually get to meet fellow curl hackers in person. The only day of the year that is completely devoted to curl. The best kind of day!
The last two years we have not run the conference for covid reasons but now we are back. The first time we arrange the event outside Europe.
I fully realize this geographic choice will prevent some of our European friends and contributors from attending, it will also allow North Americans to join the fun for the first time.
We help contributors attend
To better allow and encourage top curl contributors to attend this event, no matter where you live, we will help cover travel and lodging expenses for all and any top-100 curl committers who wants to come.
Sign up
Head over to the curl up 2022 page to find the link and details.
Agenda
Over the coming month I hope we can create an agenda with curl talks from several people. I need your ideas and your talks. We have started to collect some ideas for the 2022 agenda.
Tell us what you want to hear and what you want to share with us!
Who will be there?
I will of course be there and I hope we can attract a decent set of additional contributors, but also curl users and fans of all kinds and types.
Yes I can enter the country
Lots of you remember my struggles in the past to get permission to enter the US, but that was resolved a while ago. No problems remain.
With the brand new merged support for the msh3 library, curl now supports no less than three different HTTP/3 backends. It was merged into curl’s git repository on April 10.
When you build curl, you have the option to build it with HTTP/3 support enabled. The HTTP/3 support in curl is still considered experimental so it is still not enabled by default.
The HTTP/3 support in curl depends on the presence and support from third party libraries. You need to select and enable a specific HTTP/3 backend when you build curl. It has previously been doing HTTP/3 using either quiche or ngtcp2 + nghttp3. Starting now, there is yet another option to consider: the msh3 library.
The msh3 library itself uses msquic for doing QUIC. This is a multi platform library that uses Schannel for TLS when on Windows and OpenSSL/quictls for other platforms. The Schannel part probably makes solution this particularly interesting for curl users on Windows.
I didn’t expect this, and this year I wasn’t asked ahead of time if I wanted to receive this gift. It is however something of a collector’s item that I find very enjoyable.
I received my GitHub contribution matrix printed in steel. This is my 2021 contribution skyline. (Click the images for higher resolution.)
The thing is surprisingly heavy and sturdy. If I had papers lying around, this would an awesome paper press.
You might remember that I got a similar gift last year, so it felt natural to do a comparison shot of 2021 and 2020.
For 2020, GitHub counted 2,466 contributions, while I reached 2,543 in 2021. Very similar numbers, but clearly distributed very differently. The two matrix images look like this.
2020
2021
Letter
Enclosed with this gift was also a friendly and encouraging letter.
I was invited to the podcast and talked to host Gavin Henry for over on hour.
What it’s been like to look after the curl project for the past 25 years. We talked about the history of cURL, libcurl, whether C was the right choice, portability, some key events in those 25 years, implementing protocols, why HTTP is not so simple, rust libs, the Polhem Prize, security issues, feature requests, random support requests, code on Mars, Apple OS adoption, cars stuck in production lines, Android OS, 8 week release cycles, release cycle joy, breakdown of bug types, 1000 committers, 250 command line options, user bases, determination, json, libSSH2, c-ares, HTTPbis, HTTP/2, QUIC, Mozilla, OpenSSL, wolfSSL, DNS, FTP, the cURL book, testing, CI/CD, favorite command line options that you might not know about, and making sure that you don’t give up on that idea or project you are working on.
One of the toughest jobs I have, is to assess if a reported security problem is indeed an actual security vulnerability or “just” a bug. Let me take you through a recent case to give you an insight…
Some background
curl is 24 years old and so far in our history we have registered 111 security vulnerabilities in curl. I’ve sided with the “security vulnerability” side in reported issues 111 times. I’ve taken the opposite stance many more times.
Over the last two years, we have received 129 reports about suspected security problems and less than 15% of them (17) were eventually deemed actual security vulnerabilities. In the other 112 cases, we ended up concluding that the report was not pointing out a curl security problem. In many of those 112 cases, it was far from easy to end up with that decision and in several instances the reporter disagreed with us. (But sure, in the majority of the cases we could fairly quickly conclude that the reports were completely bonkers.)
The reporter’s view
Many times, the reporter that reports a security bug over on Hackerone has spent a significant amount of time and effort to find it, research it, reproduce it and report it. The reporter thinks it is a security problem and there’s a promised not totally insignificant monetary reward for such problems. Not to mention that a found and reported vulnerability in curl might count as something of a feat and a “feather in the hat” for a security researcher. The reporter has an investment in this work and a strong desire to have their reported issue classified as a security vulnerability.
The project’s view
If the reported problem is a security problem then we must consider it as that and immediately work on fixing the issue to reduce the risk of users getting hurt, and to inform all users about the risk and ask them to upgrade or otherwise mitigate and take precautions against the risks.
Most reported security issues are not immediately obvious. At least not in my eyes. I usually need to object, discuss, question and massage the data for a while in order to land on how we should best view the issue. I’m a skeptic by nature and I need to be convinced before I accept it.
Labeling something a “security vulnerability” if it indeed is not, is rather hurting users and the entire community rather than helping it. We must not cry wolf for a problem that cannot hurt users or that in practical terms is impossible to occur. Or maybe it is a problem that users are already expected to deal with. Or a result of an explicit or implicit application choice rather than a mistake done by us.
A bug in current libcurl makes it misbehave under certain conditions. When the MQTT connection gets closed mid message, libcurl refuses to acknowledge that and thinks the connection is still alive. Easily triggered by a malicious server.
libcurl considers the connection readable non-stop
Reading from the connection brings no more data
Busy-looping in the event-loop. Goto 2
The loop stops only once it reaches the set timeout, the progress callback can stop it and the speed-limit options will stop it if the right conditions are met.
By default, none of those options are set for a transfer and therefore, by default this makes an endless busy-loop.
At the same time…
A transfer can always stall and take a very long time to complete. A server can basically always just stop delivering more data, making the transfer take an infinite amount of time to complete. Applications that have not set any options to stop such a transfer risk doing a transfer that never ends. An endless transfer.
Also: if libcurl makes a transfer over a really fast network, such as localhost or using a super fast local network, then it might also reach the same level of busy-loop due to never having to wait for data. Albeit for a limited amount of time – until the transfer is complete. This busy-loop is highly unlikely to actually starve out any important threads in a system.
Yes, a closed connection is a much “cheaper” attack from server’s point of view than maintaining a long-living connection, but the cost of the attack is not a factor here.
Where in this grey area do we land?
This is difficult one.
I can see the point of the reporter, but I can also see how this flaw will basically not hurt any existing curl user. Where is our responsibility here?
I ended up concluding that this issue not a security vulnerability. The reporter disagreed.
It is a terribly annoying bug for sure. But the only applications that are seriously affected by it, are the ones that already allow an endless transfer.
The bug-fix was instead submitted as a normal pull-request: PR 8644, targeted to be fixed and included in the pending curl 7.83.0 release.
We publicize the reports after the fact
We make all (non-rubbish) previously reported hackerone issues public, whether they ended up being a vulnerability or not. To give everyone involved time to object or redact sensitive details, the publication date is usually within a month after the issue was closed.
By making the reports public, we allow everyone interested enough the ability and chance to check out and follow past discussions and deliberations for going the directions we did. The idea is primarily to be completely open about the reported issues and how we classify them, to show that we are not hiding anything and it also provides a chance for us to get more feedback from the surrounding and from security people who might disagree with previous analyses.
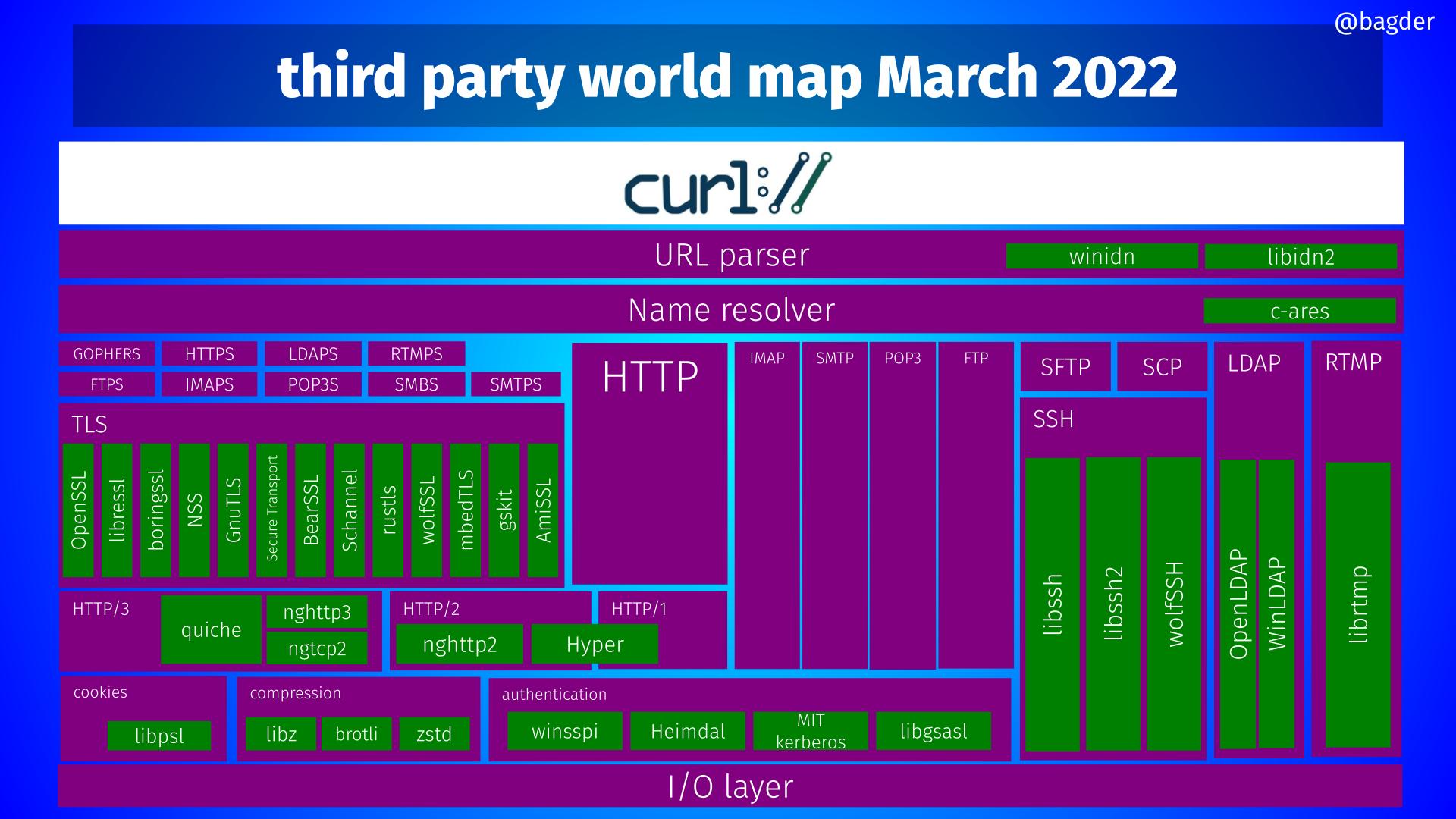
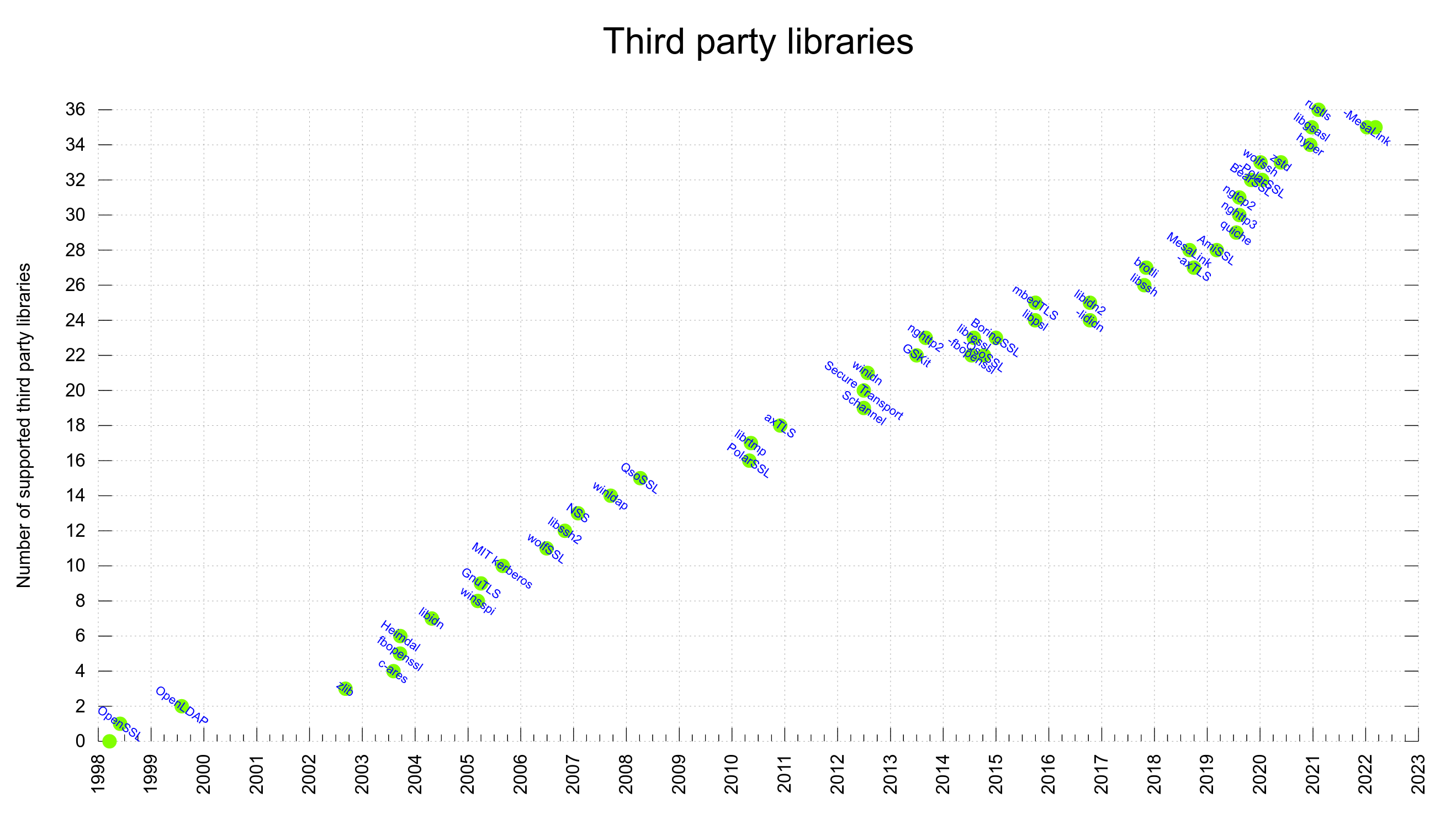
curl supports a large number of third party libraries. In a build, those libraries become “dependencies”. These components offer functionality and features that we don’t implement ourselves but still have been deemed interesting or even crucial to support to do Internet transfers the way we want.
A curl build done today can use one or more out of 35 different libraries. No build can actually use all of them at once as many are mutually exclusive and most of them only work on one or a subset of platforms.
The green boxes illustrate the third party dependencies curl can use as direct dependencies.
Keeping our backyard tidy
Every now and then we learn that one of the 3rd party libraries we can build curl to use has ceased development or has in some other way started to decay into a state where we feel is no longer healthy to the level that we can no longer recommend our users to use it.
We do this as a service to our users. If users build curl with a dependency we support, I think we should at least have some rudimentary knowledge that the dependencies we help users to use are not terrible. It’s not a guarantee, but we try. To help strengthen the ecosystem. To sweep our own backyard.
The different third party direct dependencies supported by curl by the time of the initial added support. A minus prefix means the support was dropped.
Indirect dependencies
There are of course also indirect dependencies in the form of libraries our direct dependencies use (or even libraries the indirect used libraries use), and we try to also include them in the “package” when we consider dependencies, but especially if they are optional we need to put less attention on them.
What is a healthy dependency?
We have no automatic checks or even fixed set of rules or conditions to help us make this distinction. It would of course be cool to have that, but we don’t.
Ideally, it would be awesome if all dependencies would be top-rated on bestpractices, as that would greatly help us figure this out. But unfortunately too many projects are still not even added to that effort so this doesn’t work – plus we also support a number of proprietary dependencies that can’t be rated there.
Instead, we need to rely on old-fashioned human checks and asking users and maintainers.
Maybe not add it to begin with
We have declined to add functionality to curl in the past just because the proposed 3rd party dependency it would use just didn’t live up to our standards. I don’t mean that we need to raise the bar to ridiculous levels, but if a casual browsing of the 3rd party library found issues and there were not satisfying answers in a reasonable time on how those should be addressed, then that library is probably not ready to be used by curl. There’s no need to “lure” curl users into a possibly bad situation if we can save them from it.
Abandoned
Sometimes work officially stops on a library we support. That’s a strong sign we should also stop.
curl users actually using it
Since curl is being developed, extended and bug-fixed at a fairly high pace, we can be fairly sure that if a dependency is actually being used, it needs to get fixed every now and then to keep up. If support code for a dependency hasn’t been updated or touched for many years, there’s a strong suspicion that there aren’t many users of it in modern curl.
Sometimes that can be verified to be the case when we notice a blatant bug that’s been present in the code for a good while without anyone noticing, but more often we need to ask users. Anyone using this anymore? (Which also is complicated because we often lack connections to users who don’t read any of our mailing lists and generally only upgrade curl once every decade so it might take a while until those users notice changes…)
Releases
A dependency that has stopped making new releases can be a signal that it on its way downwards. It could also be a sign that it has matured and doesn’t need much more to be done to it.
How do we even know they stopped? Maybe they just take forever from the previous release…
Developer activity
A library that is used by curl is almost required to have some level of developer activity over time. Nobody writes bug-free code unless its scope is razor-sharp-narrow and the project spent a lot of time perfecting it. No commits or developer activity for a long time means that clearly nobody takes care of the bug reports.
Slowly deteriorating projects are probably the hardest to handle. Are they still good enough?
Maintainers ultimately decide
But we just ship source code.
In the end of the day, the people who package curl or libcurl decide what third party libraries to actually get used. They are the ones who decide what dependencies users of their build rely on. In many cases this means the maintainers of the curl packages in Linux distros and other operating systems. Manufacturers of devices and tools that use libcurl often build their own and then they can decide and cherry-pick individually between all provided choices.
This makes it possible for such maintainers to add extra conditions and checks and only go with the dependencies they like.
The only binary packages the curl project itself provides, are the ones for Windows, and we try to go with only solid, reliable and conservative choices for those.
This is a recorded online presentation about curl that I did today, March 24 2022. How it started, grew, where it is today, how we make it and where it perhaps might go in the future.