tldr: the level of HTTP/3 support in servers is surprisingly high.
The specs
The specifications are all done. They’re now waiting in queues to get their final edits and approvals before they will get assigned RFC numbers and get published as such – they will not change any further. That’s a set of RFCs (six I believe) for various aspects of this new stack. The HTTP/3 spec is just one of those. Remember: HTTP/3 is the application protocol done over the new transport QUIC. (See http3 explained for a high-level description.)
The HTTP/3 spec was written to refer to, and thus depend on, two other HTTP specs that are in the works: httpbis-cache and https-semantics. Those two are mostly clarifications and cleanups of older HTTP specs, but this forces the HTTP/3 spec to have to get published after the other two, which might introduce a small delay compared to the other QUIC documents.
The working group has started to take on work on new specifications for extensions and improvements beyond QUIC version 1.
HTTP/3 Usage
In early April 2021, the usage of QUIC and HTTP/3 in the world is measured by a few different companies.
QUIC support
netray.io scans the IPv4 address space weekly and checks how many hosts that speak QUIC. Their latest scan found 2.1 million such hosts.
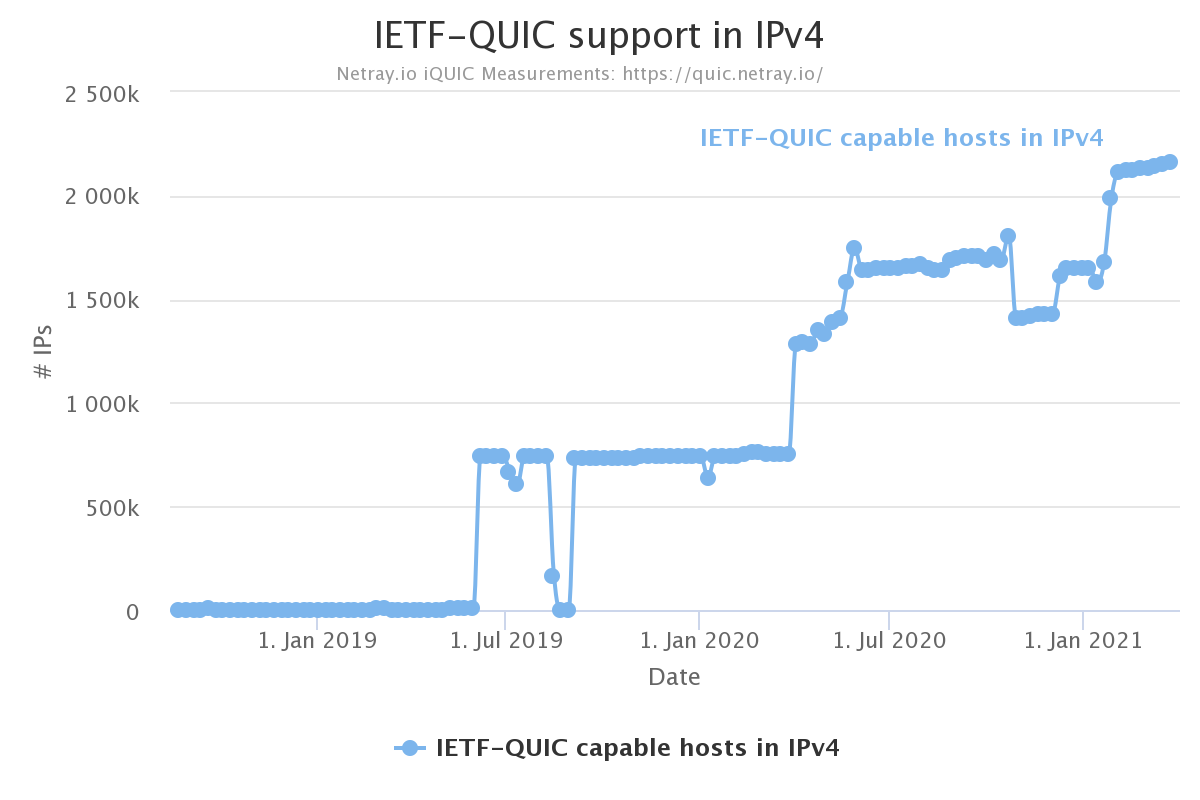
Arguably, the netray number doesn’t say much. Those two million hosts could be very well used or barely used machines.
HTTP/3 by w3techs
w3techs.com has been in the game of scanning web sites for stats purposes for a long time. They scan the top ten million sites and count how large share that runs/supports what technologies and they also check for HTTP/3. In their data they call the old Google QUIC for just “QUIC” which is confusing but that should be seen as the precursor to HTTP/3.
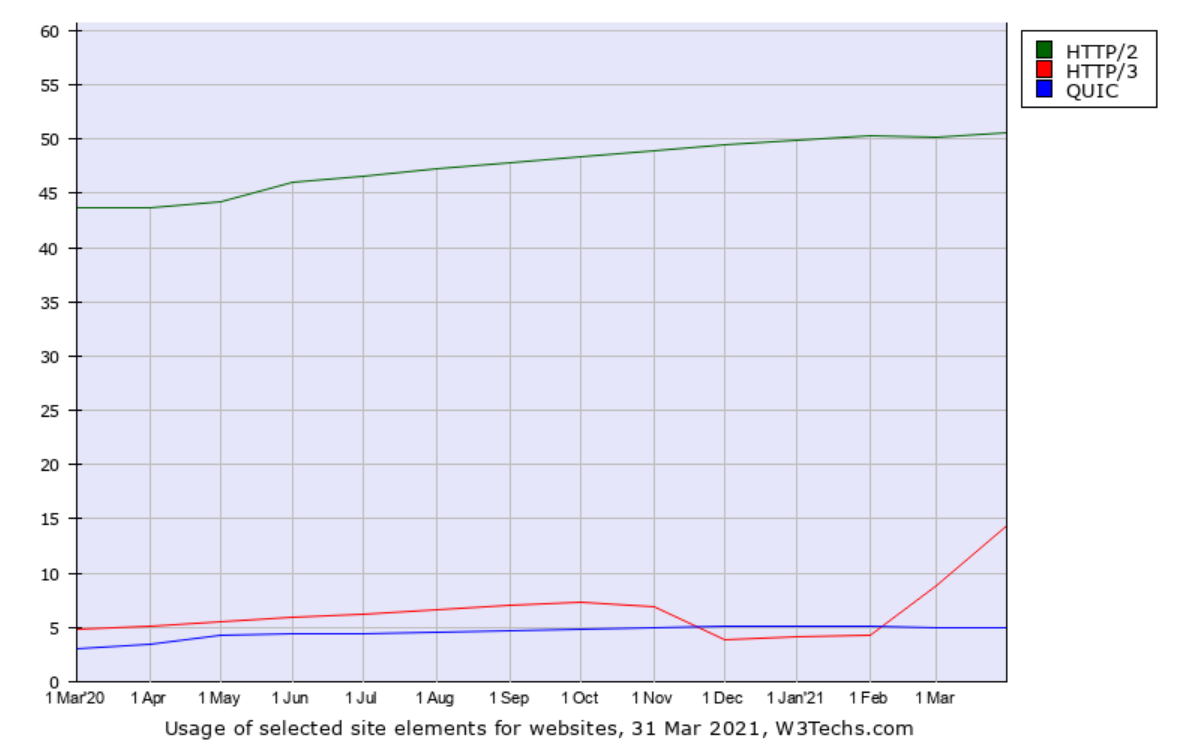
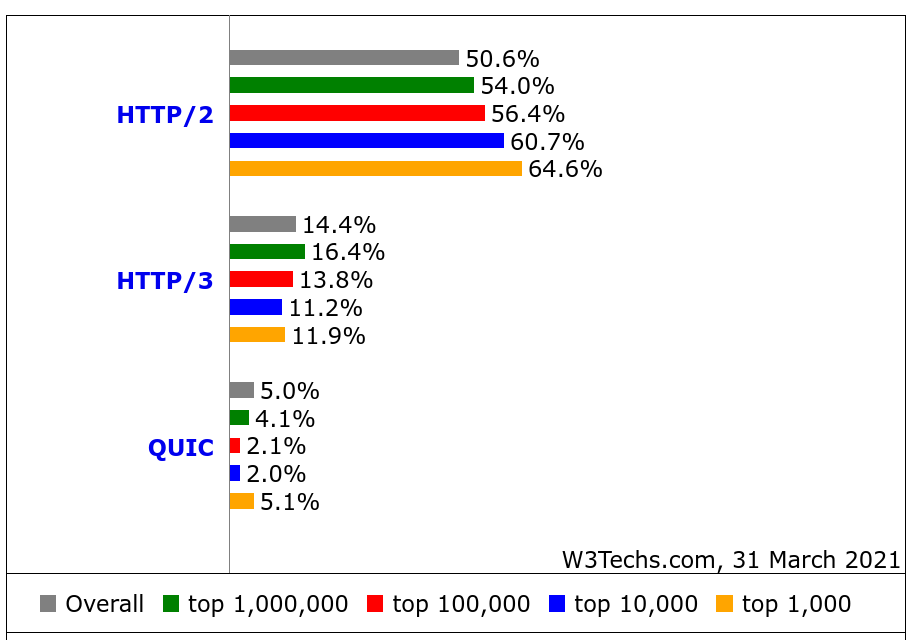
What stands out to me in this data except that the HTTP/3 usage seems very high: the top one-million sites are claimed to have a higher share of HTTP/3 support (16.4%) than the top one-thousand (11.9%)! That’s the reversed for HTTP/2 and not how stats like this tend to look.
It has been suggested that the growth starting at Feb 2021 might be explained by Cloudflare’s enabling of HTTP/3 for users also in their free plan.
HTTP/3 by Cloudflare
On radar.cloudflare.com we can see Cloudflare’s view of a lot of Internet and protocol trends over the world.
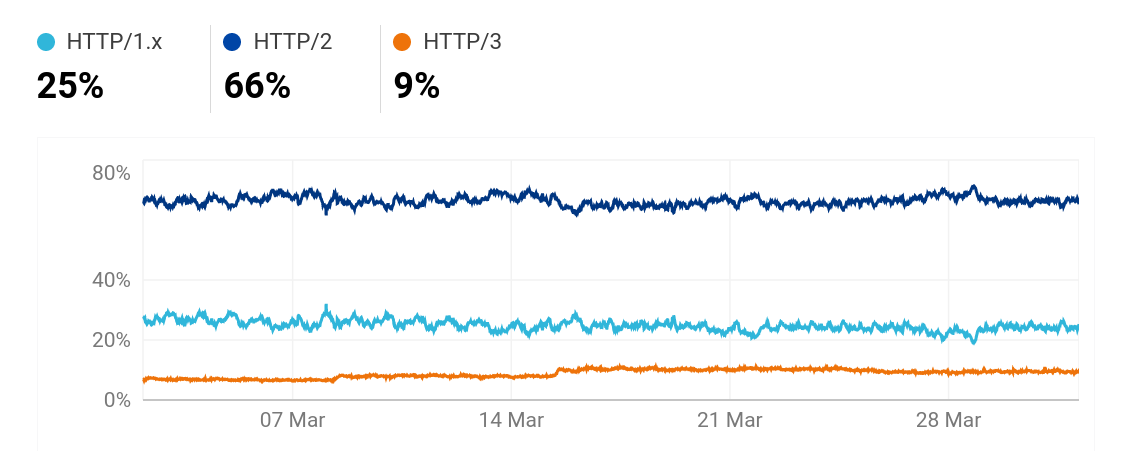
This HTTP/3 number is significantly lower than w3techs’. Presumably because of the differences in how they measure.
Clients
The browsers
All the major browsers have HTTP/3 implementations and most of them allow you to manually enable it if it isn’t already done so. Chrome and Edge have it enabled by default and Firefox will so very soon. The caniuse.com site shows it like this (updated on April 4):

(Earlier versions of this blog post showed the previous and inaccurate data from caniuse.com. Not anymore.)
curl

curl supports HTTP/3 since a while back, but you need to explicitly enable it at build-time. It needs to use third party libraries for the HTTP/3 layer and it needs a QUIC capable TLS library. The QUIC/h3 libraries are still beta versions. See below for the TLS library situation.
curl’s HTTP/3 support is not even complete. There are still unsupported areas and it’s not considered stable yet.
Other clients
Facebook has previously talked about how they use HTTP/3 in their app, and presumably others do as well. There are of course also other implementations available.
TLS libraries
curl supports 14 different TLS libraries at this time. Two of them have QUIC support landed: BoringSSL and GnuTLS. And a third would be the quictls OpenSSL fork. (There are also a few other smaller TLS libraries that support QUIC.)
OpenSSL
The by far most popular TLS library to use with curl, OpenSSL, has postponed their QUIC work:
At the same time they have delayed the OpenSSL 3.0 release significantly. Their release schedule page still today speaks of a planned release of 3.0.0 in “early Q4 2020”. That plan expects a few months from the beta to final release and we have not yet seen a beta release, only alphas.
Realistically, this makes QUIC in OpenSSL many months off until it can appear even in a first alpha. Maybe even 2022 material?
BoringSSL
The Google powered OpenSSL fork BoringSSL has supported QUIC for a long time and provides the OpenSSL API, but they don’t do releases and mostly focus on getting a library done for Google. People outside the company are generally reluctant to use and depend on this library for those reasons.
The quiche QUIC/h3 library from Cloudflare uses BoringSSL and curl can be built to use quiche (as well as BoringSSL).
quictls
Microsoft and Akamai have made a fork of OpenSSL available that is based on OpenSSL 1.1.1 and has the QUIC pull-request applied in order to offer a QUIC capable OpenSSL flavor to the world before the official OpenSSL gets their act together. This fork is called quictls. This should be compatible with OpenSSL in all other regards and provide QUIC with an API that is similar to BoringSSL’s.
The ngtcp2 QUIC library uses quictls. curl can be built to use ngtcp2 as well as with quictls,
Is HTTP/3 faster?
I realize I can’t blog about this topic without at least touching this question. The main reason for adding support for HTTP/3 on your site is probably that it makes it faster for users, so does it?
According to cloudflare’s tests, it does, but the difference is not huge.
We’ve seen other numbers say h3 is faster shown before but it’s hard to find up-to-date performance measurements published for the current version of HTTP/3 vs HTTP/2 in real world scenarios. Partly of course because people have hesitated to compare before there are proper implementations to compare with, and not just development versions not really made and tweaked to perform optimally.
I think there are reasons to expect h3 to be faster in several situations, but for people with high bandwidth low latency connections in the western world, maybe the difference won’t be noticeable?
Future
I’ve previously shown the slide below to illustrate what needs to be done for curl to ship with HTTP/3 support enabled in distros and “widely” and I think the same works for a lot of other projects and clients who don’t control their TLS implementation and don’t write their own QUIC/h3 layer code.
This house of cards of h3 is slowly getting some stable components, but there are still too many moving parts for most of us to ship.

I assume that the rest of the browsers will also enable HTTP/3 by default soon, and the specs will be released not too long into the future. That will make HTTP/3 traffic on the web increase significantly.
The QUIC and h3 libraries will ship their first non-beta versions once the specs are out.
The TLS library situation will continue to hamper wider adoption among non-browsers and smaller players.
The big players already deploy HTTP/3.
Updates
I’ve updated this post after the initial publication, and the biggest corrections are in the Chrome/Edge details. Thanks to immediate feedback from Eric Lawrence. Remaining errors are still all mine! Thanks also to Barry Pollard who filed the PR to update the previously flawed caniuse.com data.