About four years ago I announced that curl was 100% compliant with the CII Best Practices criteria. curl was one of the first projects on that train to reach a 100% – primarily of course because we were early joiners and participants of the Best Practices project.
The point of that was just to highlight and underscore that we do everything we can in the curl project to act as a responsible open source project and citizen of the larger ecosystem. You should be able to trust curl, in every aspect.
Going above and beyond basic
Subsequently, the best practices project added higher levels of compliance. Basically adding a bunch of requirements so if you want to grade yourself at silver or even gold level there are a whole series of additional requirements to meet. At the time those were added, I felt they were asking for quite a lot of specifics that we didn’t provide in the curl project and with a bit of a sigh I felt I had to accept the fact that we would remain on “just” 100% compliance and only reaching a part of the way toward Silver and Gold. A little disheartened of course because I always want curl to be in the top.
So maybe Silver?
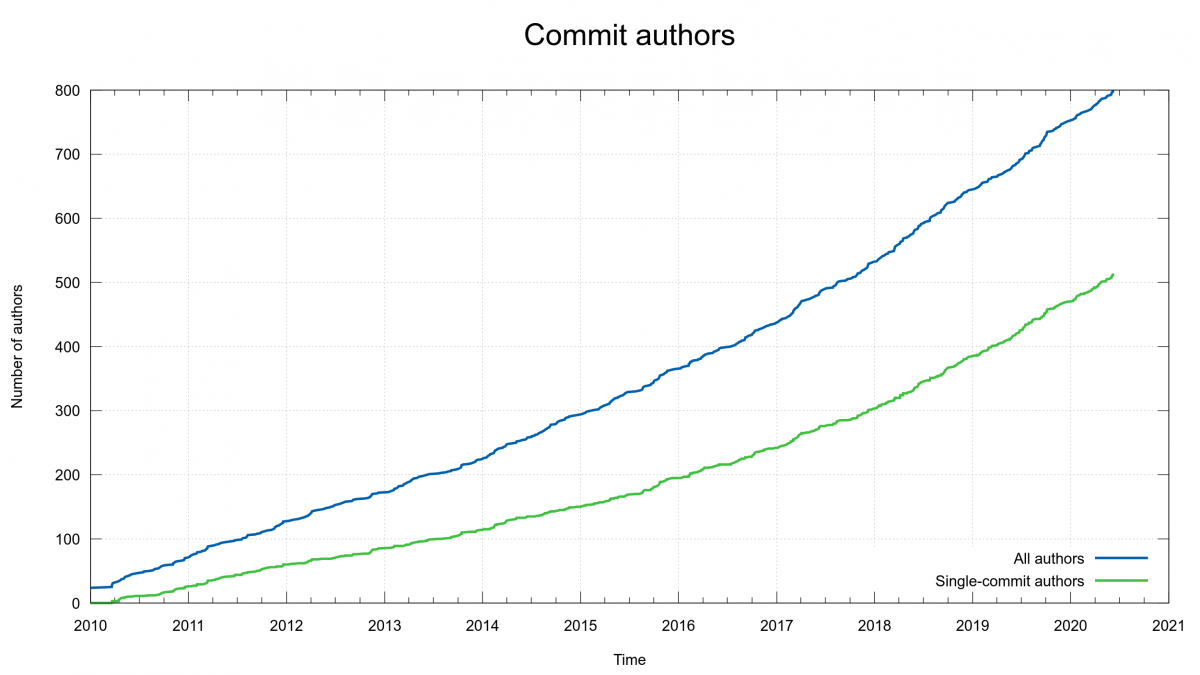
I had left the awareness of that entry listing in a dusty corner of my brain and hadn’t considered it much lately, when I noticed the other day that it was announced that the Linux kernel project reached gold level best practice.
That’s a project with around 50 times more developers and commits than curl for an average release (and even a greater multiplier for amount of code) so I’m not suggesting the two projects are comparable in any sense. But it made me remember our entry on CII Best Practices web site.
I came back, updated a few fields that seemed to not be entirely correct anymore and all of a sudden curl quite unexpectedly had a 100% compliance at Silver level!
Further?
If Silver was achievable, what’s actually left for gold?
Sure enough, soon there were only a few remaining criteria left “unmet” and after some focused efforts in the project, we had created the final set of documents with information that were previously missing. When we now finally could fill in links to those docs in the final few entries, project curl found itself also scoring a 100% at gold level.
Best Practices: Gold Level
What does it mean for us? What does it mean for you, our users?
For us, it is a double-check and verification that we’re doing the right things and that we are providing the right information in the project and we haven’t forgotten anything major. We already knew that we were doing everything open source in a pretty good way, but getting a bunch of criteria that insisted on a number of things also made us go the extra way and really provide information for everything in written form. Some of what previously really only was implied, discussed in IRC or read between lines in various pull requests.
I’m proud to lead the curl project and I’m proud of all our maintainers and contributors.
For users, having curl reach gold level makes it visible that we’re that kind of open source project. We’re part of this top clique of projects. We care about every little open source detail and this should instill trust and confidence in our users. You can trust curl. We’re a golden open source project. We’re with you all the way.
The final criteria we checked off
Which was the last criteria of them all for curl to fulfill to reach gold?
The project MUST document its code review requirements, including how code review is conducted, what must be checked, and what is required to be acceptable (link)
This criteria is now fulfilled by the brand new document CODE_REVIEW.md.
What’s next?
We’re working on the next release. We always do. Stop the slacking now and get back to work!
Credits
Gold image by Erik Stein from Pixabay