Earlier this year I was the recipient of a monetary Google patch grant with the expressed purpose of improving security in libcurl.
This was an upfront payout under this Google program describing itself as “an experimental program that rewards proactive security improvements to select open-source projects”.
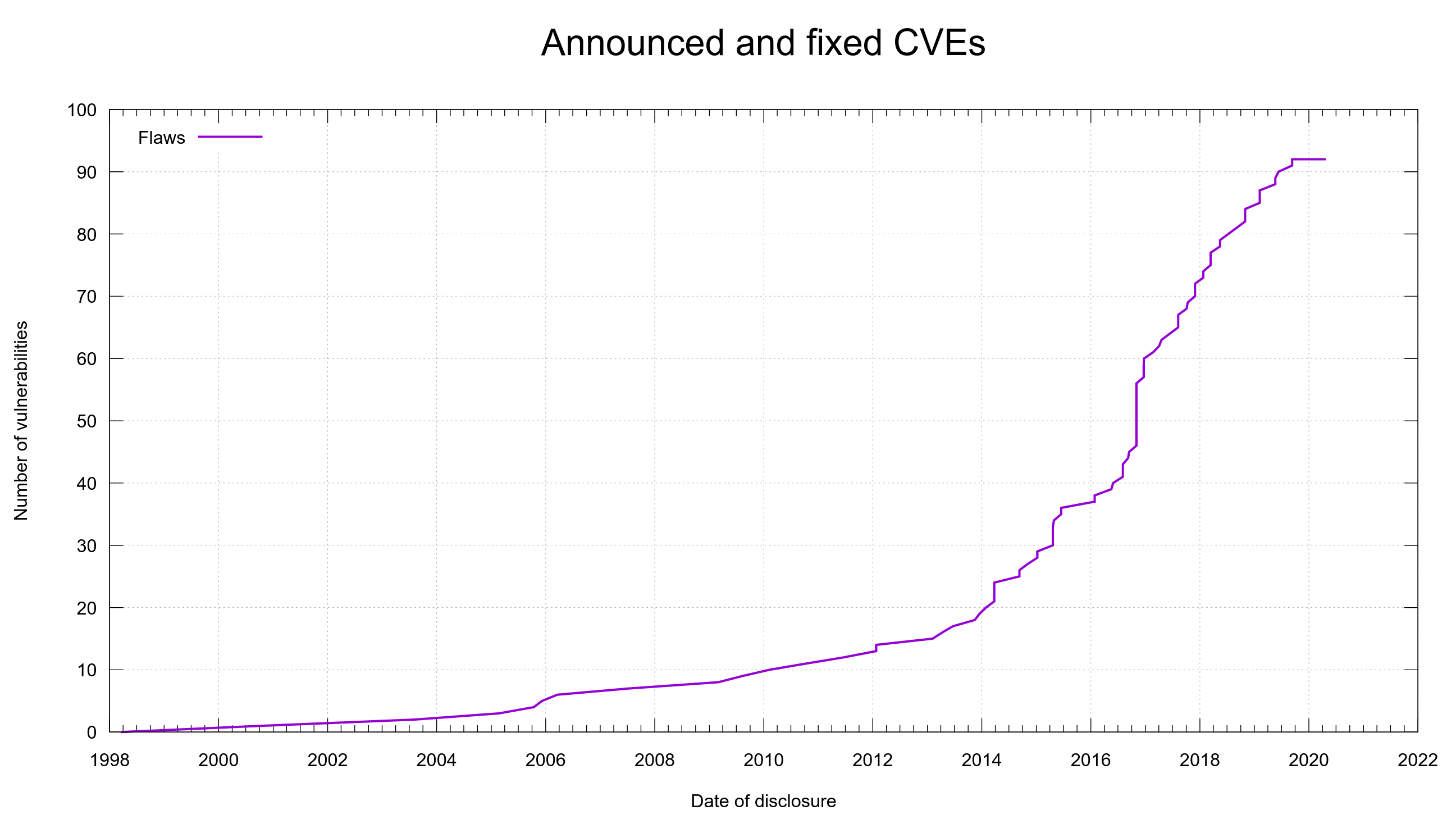
I accepted this grant for the curl project and I intend to keep working fiercely on securing curl. I recognize the importance of curl security as curl remains one of the most widely used software components in the world, and even one that is doing network data transfers which typically is a risky business. curl is responsible for a measurable share of all Internet transfers done over the Internet an average day. My job is to make sure those transfers are done as safe and secure as possible. It isn’t my only responsibility of course, as I have other tasks to attend to as well, but still.
Do more
Security is already and always a top priority in the curl project and for myself personally. This grant will of course further my efforts to strengthen curl and by association, all the many users of it.
What I will not do
When security comes up in relation to curl, some people like to mention and propagate for other programming languages, But curl will not be rewritten in another language. Instead we will increase our efforts in writing good C and detecting problems in our code earlier and better.
Proactive counter-measures
Things we have done lately and working on to enforce everywhere:
String and buffer size limits – all string inputs and all buffers in libcurl that are allowed to grow now have a maximum allowed size, that makes sense. This stops malicious uses that could make things grow out of control and it helps detecting programming mistakes that would lead to the same problems. Also, by making sure strings and buffers are never ridiculously large, we avoid a whole class of integer overflow risks better.
Unified dynamic buffer functions – by reducing the number of different implementations that handle “growing buffers” we reduce the risk of a bug in one of them, even if it is used rarely or the spot is hard to reach with and “exercise” by the fuzzers. The “dynbuf” internal API first shipped in curl 7.71.0 (June 2020).
Realloc buffer growth unification – pretty much the same point as the previous, but we have earlier in our history had several issues when we had silly realloc() treatment that could lead to bad things. By limiting string sizes and unifying the buffer functions, we have reduced the number of places we use realloc and thus we reduce the number of places risking new realloc mistakes. The realloc mistakes were usually in combination with integer overflows.
Code style – we’ve gradually improved our code style checker (checksrc.pl) over time and we’ve also gradually made our code style more strict, leading to less variations in code, in white spacing and in naming. I’m a firm believer this makes the code look more coherent and therefore become more readable which leads to fewer bugs and easier to debug code. It also makes it easier to grep and search for code as you have fewer variations to scan for.
More code analyzers – we run every commit and PR through a large number of code analyzers to help us catch mistakes early, and we always remove detected problems. Analyzers used at the time of this writing: lgtm.com, Codacy, Deepcode AI, Monocle AI, clang tidy, scan-build, CodeQL, Muse and Coverity. That’s of course in addition to the regular run-time tools such as valgrind and sanitizer builds that run the entire test suite.
Memory-safe components – curl already supports getting built with a plethora of different libraries and “backends” to cater for users’ needs and desires. By properly supporting and offering users to build with components that are written in for example rust – or other languages that help developers avoid pitfalls – future curl and libcurl builds could potentially avoid a whole section of risks. (Stay tuned for more on this topic in a near future.)
Reactive measures
Recognizing that whatever we do and however tight ship we run, we will continue to slip every once in a while, is important and we should make sure we find and fix such slip-ups as good and early as possible.
Raising bounty rewards. While not directly fixing things, offering more money in our bug-bounty program helps us get more attention from security researchers. Our ambition is to gently drive up the reward amounts progressively to perhaps multi-thousand dollars per flaw, as long as we have funds to pay for them and we mange keep the security vulnerabilities at a reasonably low frequency.
More fuzzing. I’ve said it before but let me say it again: fuzzing is really the top method to find problems in curl once we’ve fixed all flaws that the static analyzers we use have pointed out. The primary fuzzing for curl is done by OSS-Fuzz, that tirelessly keeps hammering on the most recent curl code.
Good fuzzing needs a certain degree of “hand-holding” to allow it to really test all the APIs and dig into the dustiest corners, and we should work on adding more “probes” and entry-points into libcurl for the fuzzer to make it exercise more code paths to potentially detect more mistakes.
See also my presentation testing curl for security.